
Introduction
In our chapter about PolyBase, we presented this new SQL Server 2016 feature to query CSV files stored in Azure Storage accounts. We mentioned that in PolyBase you can query data in Hadoop (HDInsight) using SQL Server. HDInsight is a very popular system in Azure that eventually you will need to interact with if you use SQL Server. That is why we will give an explanation for newbies about it.
In this article, we will learn the following:
- What is Hadoop?
- What is HDInsight?
- Create your first HDInsight system in Azure
- Learn how to query HDInsight information using HIVE (your first query in Hive)
What is Hadoop?
It is a highly scalable Distributed File System (HDFS) used to handle big data. There are several scenarios when a traditional database like SQL Server or Oracle is not the best way to store data. For example, to store YouTube or Facebook information, it would be extremely expensive to store all the images and videos in a traditional database. That is why Hadoop was created. Hadoop can handle Petabytes of information easily using several distributed computers. With Hadoop you can easily handle SQL and NoSQL Data and it is easy to distribute the information in several servers.
SQL Server these days needs the help of HDInsight for Big Data (Petabytes of information and NoSQL data.
What is HDInsight?
HDInsight is a Hadoop system created by Microsoft and Hortonworks. They worked together to improve Hadoop and create this solution in the cloud.
Requirements
- An Azure Account
- A local machine or a cell to create a CSV file
- MASE Installed
Getting started
We will learn how to create an HDInsight clusters, upload a CSV file and query the file using HIVE (a query language in Hadoop)
We will use a file named customers.csv with the following content:
Name,Lastname,email
john,Rambo,jrambo@hotmail.com
john,connor,jconnor@hotmail.com
elvis,presley,epresley@hotmail.com
elmer,hermosa,ehermosa@gmail.com
In the Azure Portal, go to Add>Intelligence + Analytics>HDInsight
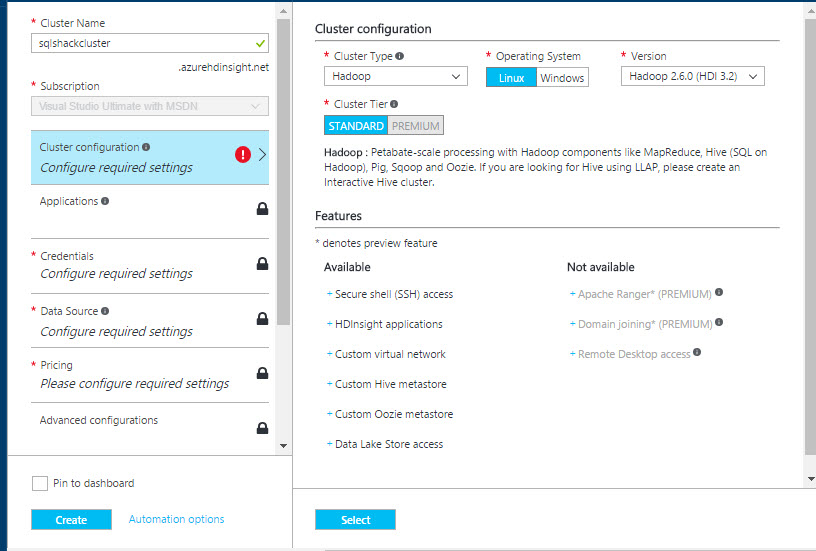
You can have different cluster types like Hadoop, Hbase and Storm. We will select Hadoop for this example. You can use Linux or Windows as the Hadoop OS. You can also select the Hadoop versions.
In Cluster Tier, you can select the Standard and Premium tiers. Premium Tier is more expensive and includes AD Integration and secure Hadoop (Ranger).
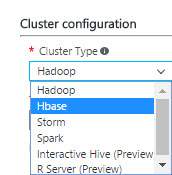
You can create different configurations. Hadoop is the traditional cluster. Hbase is used for Columnar NoSQL data, Storm is used for stream Analytics for real time processing. Spark is for In-memory interactive queries and micro batch stream processing. Interactive Hive is used for queries In-memory and caching. R Server is mainly used for machine learning tasks.
In the credential section, you will need a login to access and administer the cluster and another account to use SSH. SSH is a secure shell to administer remote Servers from a local file using the command line:
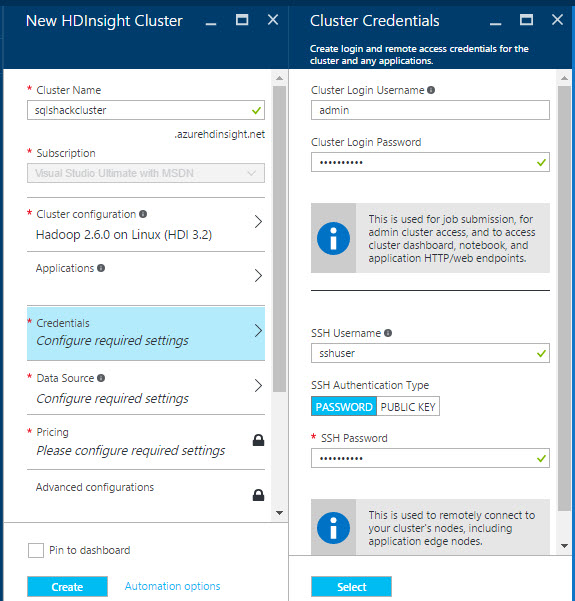
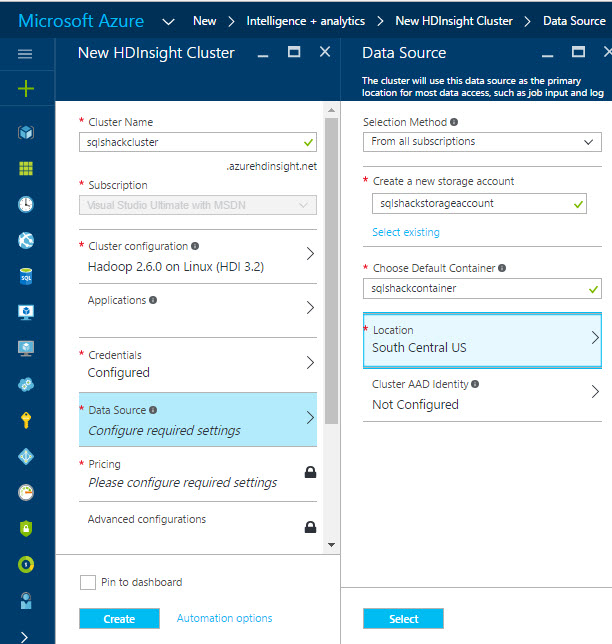
In the Data Source isection you specify where to store the information of the HDInsight nodes in Azure.
HDInsight is stored in an Azure Storage Account and then stored in a container. A container is like a folder to store information in Azure. You can also specify the location to store. Usually, the location should be close to your local location:
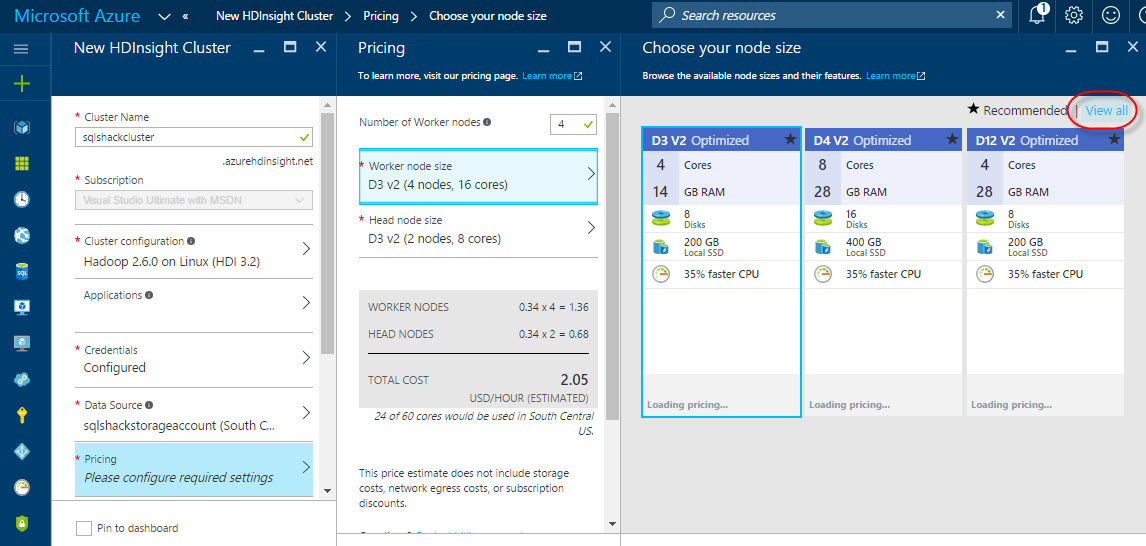
Pricing is very important. More cores and RAM will increase the price. You have working nodes, which contains the data and information and the head nodes, which are used to host the services.
Press View all to see all the different options:
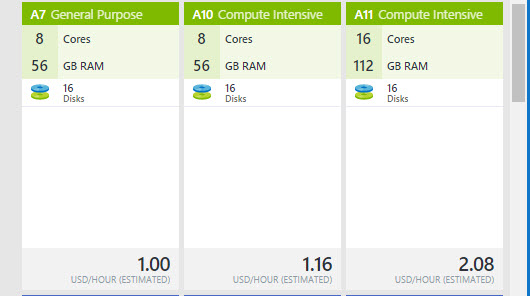
A11 is one of the most expensive options. 2.08 USD/Hour approximately with 16 cores and 112 GB RAM:
Finally, you need to create a resource group or create a new one. The groups are used to group resources to make the administration easier and press create:
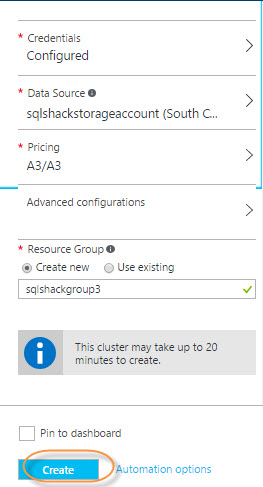
You may need to wait 6-20 minutes for the deployment. Once that the clusters are created, in Azure Portal press the > icon and select HDInsight Clusters:
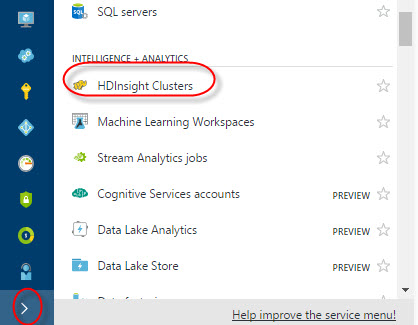
Click the cluster just created:

In the Overview section, you have the option to access to the Cluster Dashboard in Quick links:
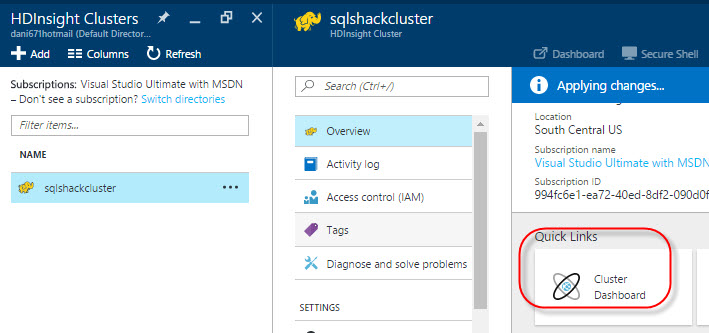
The Cluster will be used to administer the HDInsight clusters:
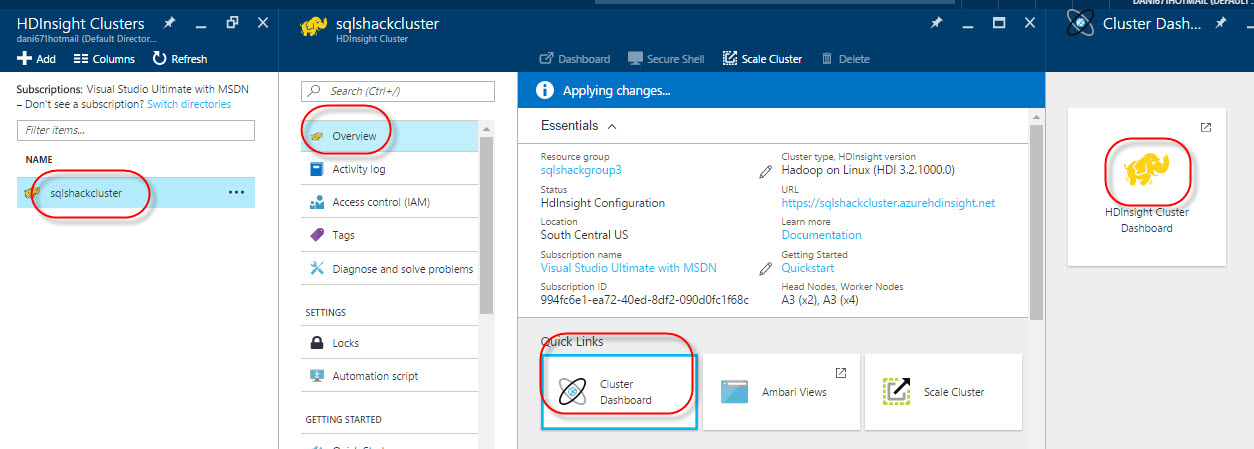
Login with the credentials created in figure 4 and press Log In:
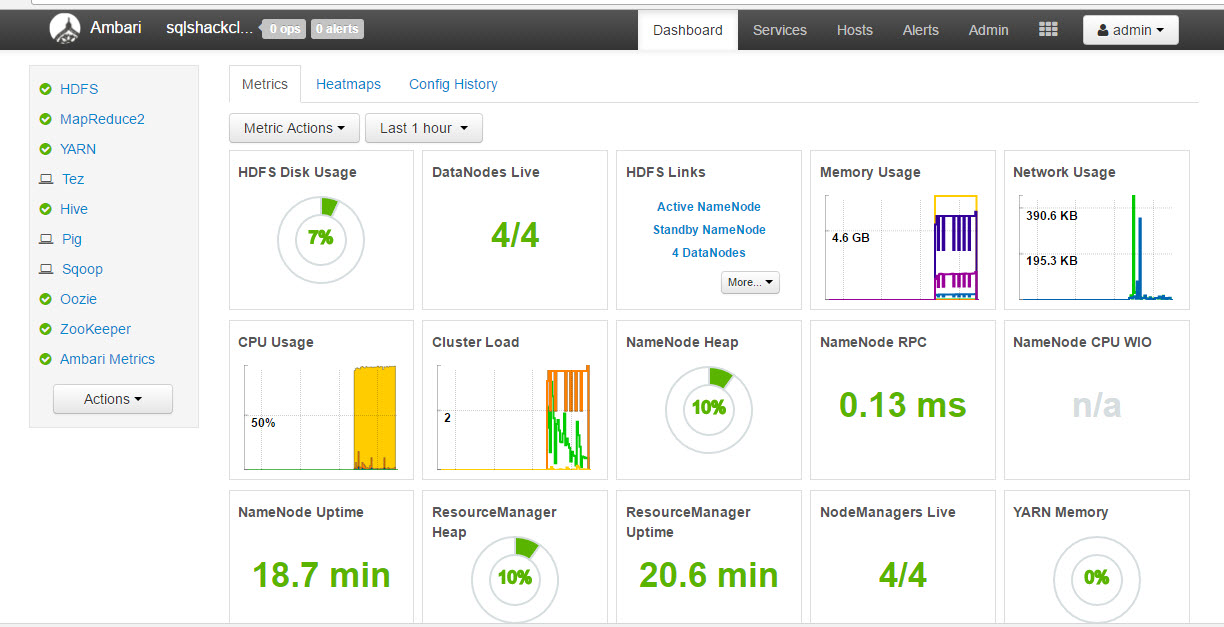
The Dashboard shows hardware information like the disk usage, node time, number of live nodes, memory and network usage:
In the menu, select Hive View:

Hive is a Data Warehouse system of Hadoop. It treats data like tables using HiveQL, which is similar to SQL.
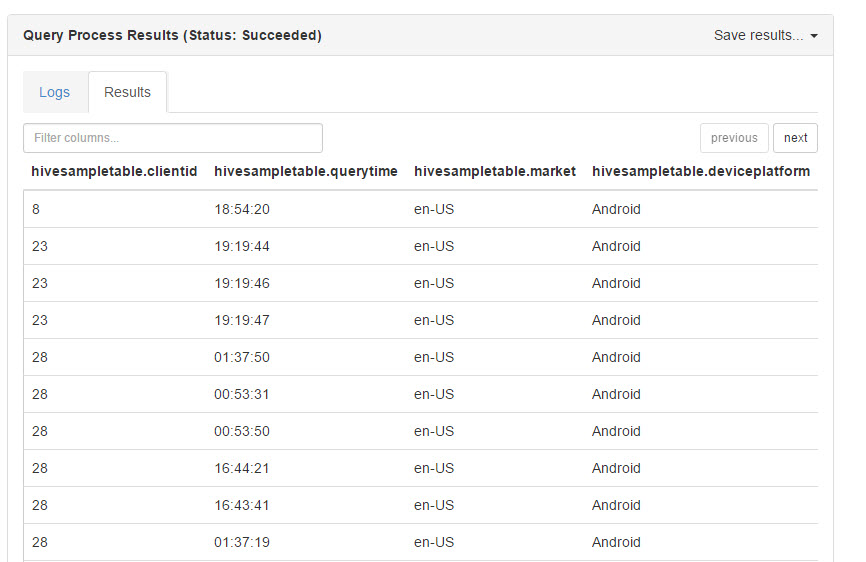
Go to Query Tab and click Default. The table created by default is hivesampletable:
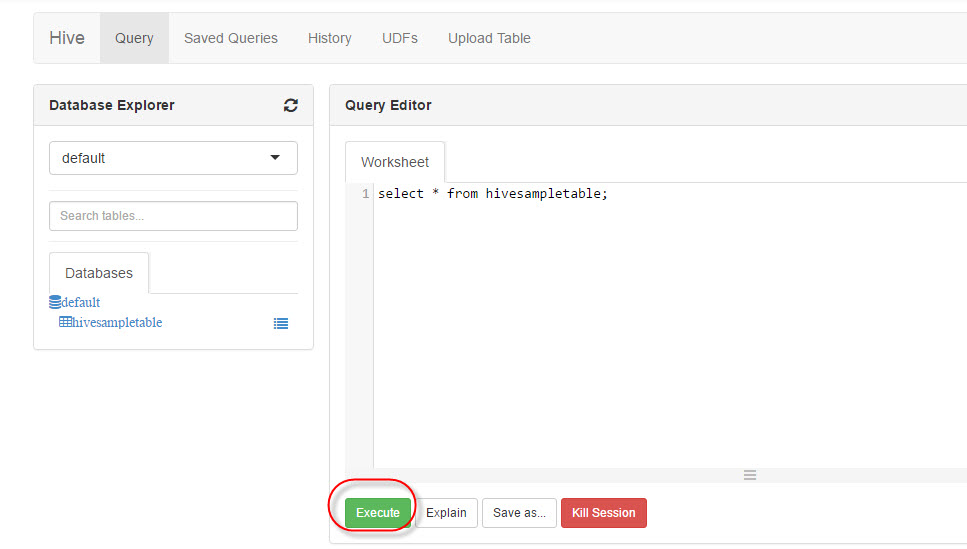
Write the following query:
Select * from hivesampletable;
Press Execute:
You can see the results by pressing Results. As you can see, HiveQL is similar to SQL. Hivesampletable is a text file and we are accessing to the data like if it were a table:
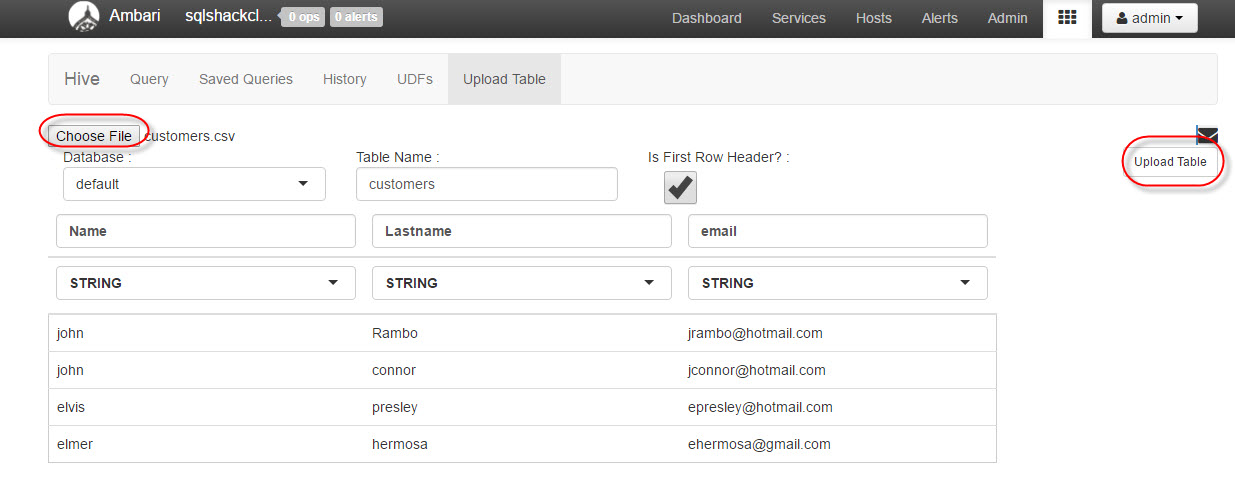
We will upload the customers.csv file to Hive. Go to upload table and press the choose file. Select the customers.csv file and press Upload Table:
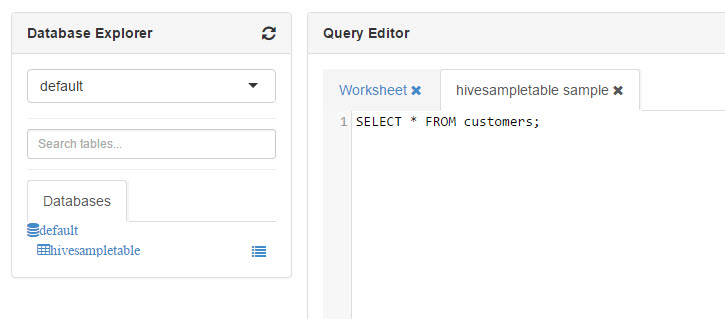
You can query the customers.csv file using the following query:
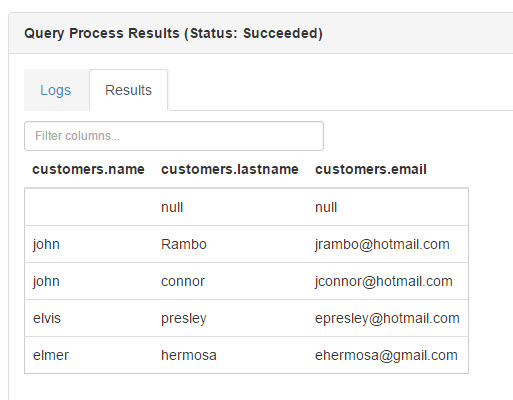
In results, you can see the values of the csv file like if it were a table:
You can check the HDInsight files using the Microsoft Azure Storage Explorer (MASE). If you do not have MASE installed and you do not know what it is, please read our article about MASE.
Once that MASE is installed, connect to the Azure Storage Account and blob container created in figure 5 and go to the hive folder:
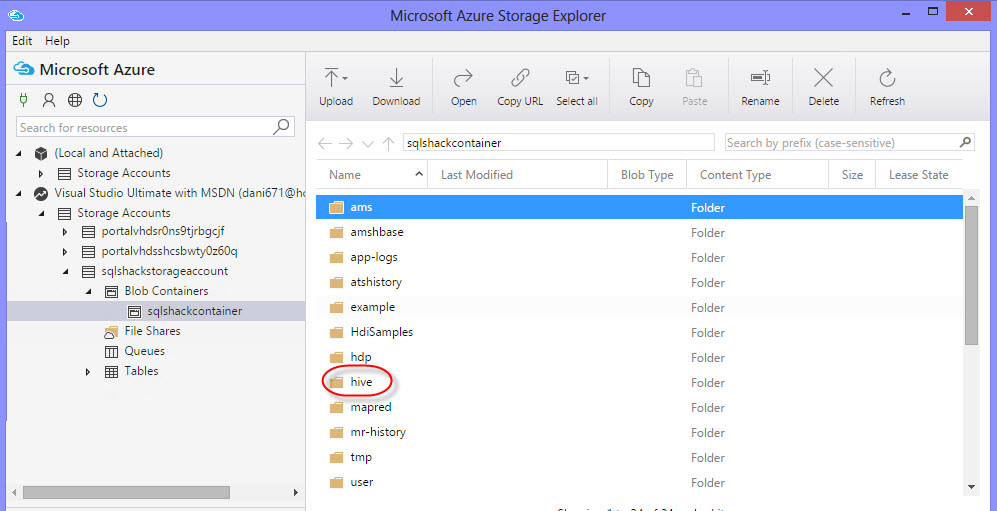
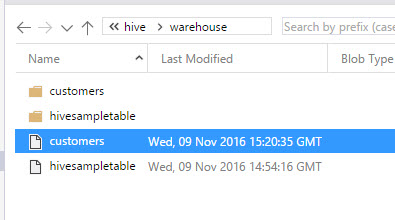
In Hive, you will be able to see the customer and hivesampletable. As you can see, all the information in HDInsight is stored here.
Conclusions
HDInsight is a Highly Scalable Distributed System. It is very easy to create and configure and it takes only a few minutes to install.
We learned how to query TXT and CSV files using HiveQL, which is similar to SQL. It is very intuitive and simple.
Once that you have your HDInisght clusters, you are ready to query on SQL Server 2016 using PolyBase.

He has worked for the government, oil companies, web sites, magazines and universities around the world. Daniel also regularly speaks at SQL Servers conferences and blogs. He writes SQL Server training materials for certification exams.
He also helps with translating SQLShack articles to Spanish
View all posts by Daniel Calbimonte
- PostgreSQL tutorial to create a user - November 12, 2023
- PostgreSQL Tutorial for beginners - April 6, 2023
- PSQL stored procedures overview and examples - February 14, 2023