
In this article, we explore the Azure Data Lake Analytics and query data using the U-SQL.
Introduction to Azure Data Lake Analytics (ADLA)
Microsoft Azure platform supports big data such as Hadoop, HDInsight, Data lakes. Usually, a traditional data warehouse stores data from various data sources, transform data into a single format and analyze for decision making. Developers use complex queries that might take longer hours for data retrieval. Organizations are increasing their footprints in the Cloud infrastructure. It leverages cloud infrastructure warehouse solutions such as Amazon RedShift, Azure Synapse Analytics (Azure SQL data warehouse), or AWS snowflake. The cloud solutions are highly scalable and reliable to support your data and query processing and storage requirements.
The data warehouse follows the Extract-Transform-Load mechanism for data transfer.
- Extract: Extract data from different data sources
- Transform: Transform data into a specific format
- Load: Load data into predefined data warehouse schema, tables
The data lake does not require a rigorous schema and converts data into a single format before analysis. It stores data in its original format such as binary, video, image, text, document, PDF, JSON. It transforms data only when needed. The data can be in structured, semi-structured and unstructured format.
A few useful features of a data lake are:
- It stores raw data ( original data format)
- It does not have any predefined schema
- You can store Unstructured, semi-structured and structured in it
- It can handle PBs or even hundreds of PBs data volumes
- Data lake follows schema on the reading method in which data is transformed as per requirement basis
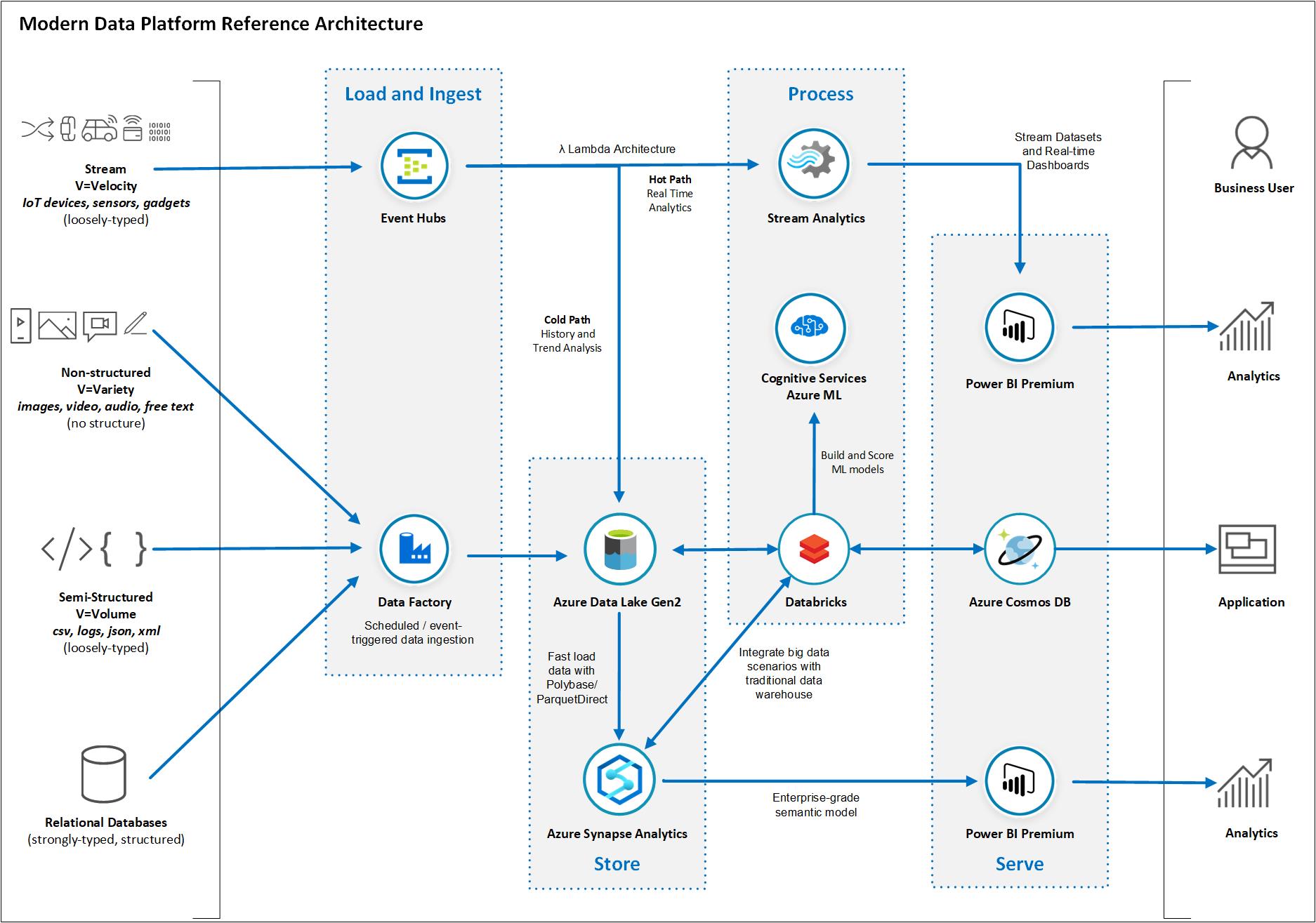
At a high-level, the Azure data platform architecture looks like below. Image reference: Microsoft docs
- Ingestion: Data collection from various data sources and store into the Azure Data lake in its original format
- Storage: Store data into Azure Data Lake Storage, AWS S3 or Google cloud storage
- Processing: Process data from the raw storage into a compatible format
- Analytics: Perform data analysis using stored and processed data. You can use Azure Data Lake Analytics(ADLA), HDInsight or Azure Databricks
Creating an Azure Data Lake Analytics (ADLA) Account
We need to create an ADLA account with your subscription to process data with it. Login to the Azure portal using your credentials. In the Azure Services, click on Data Lake Analytics.

In the New Data Lake Analytics account, enter the following information.
- Subscription and Resource group: Select your Azure subscription and resource group, if it already exists. You can create a new resource group from the data lake analytics page as well
- Data Lake Analytics Name: Specify a suitable name for the analytic service
- Location: Select the Azure region from the drop-down
- Storage subscription: Select the storage subscription from the drop-down list
- Azure Data Lake Storage Gen1: Create a new Azure Data Lake Storage Gen1 account
- Pricing package: You can select a pay-as-you model or monthly commitment as per your requirement
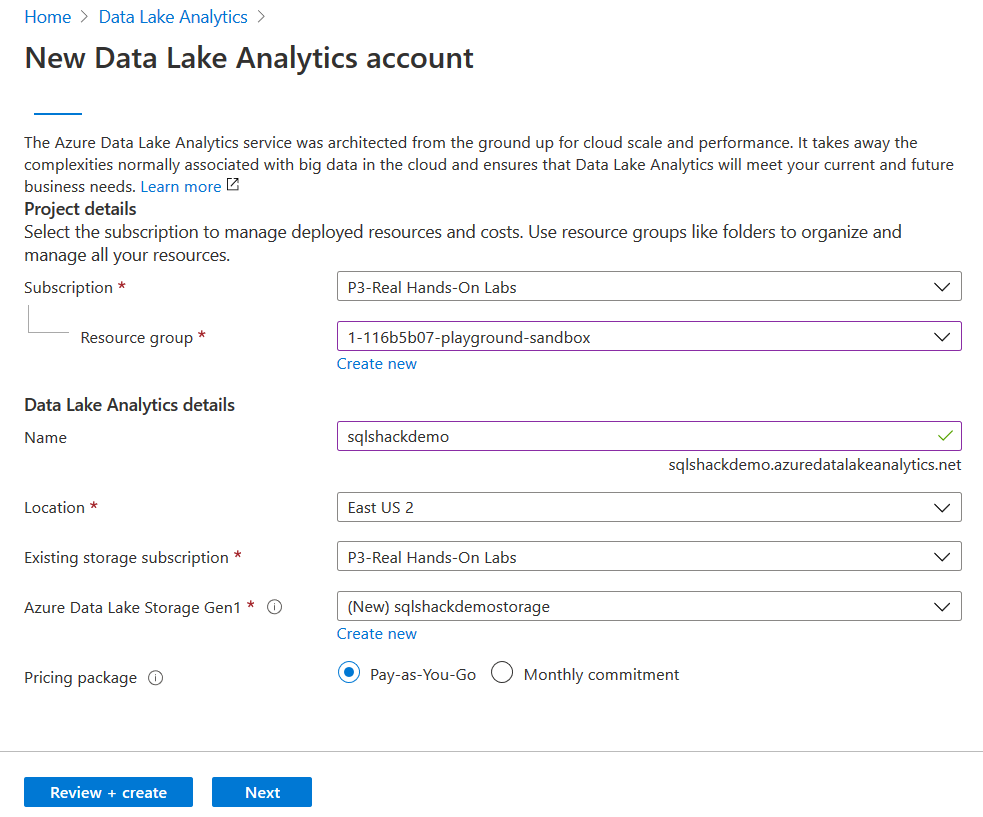
Click on Review+Create. You can review your configurations and create the Azure Data Lake Analytics Account.
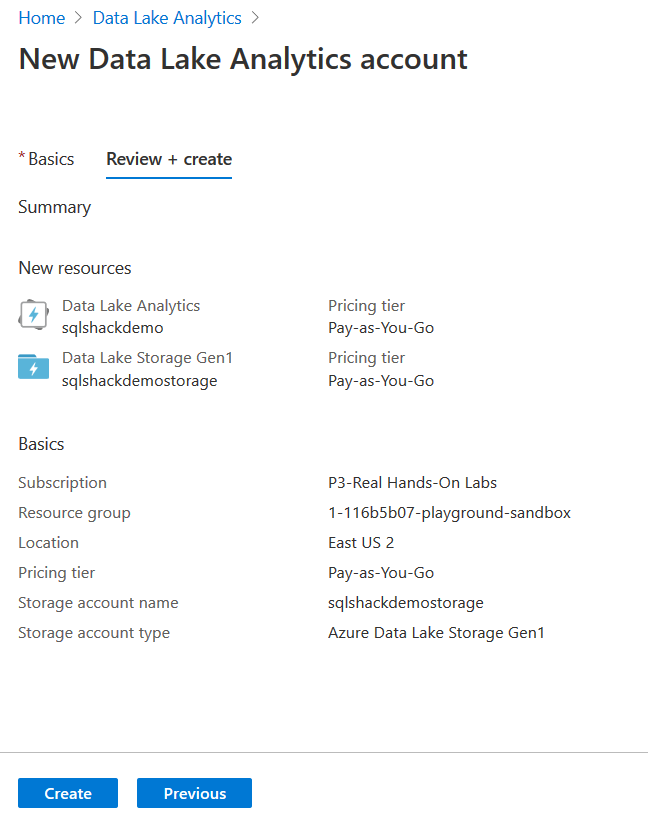
It starts deploying the Azure resources, as shown below.
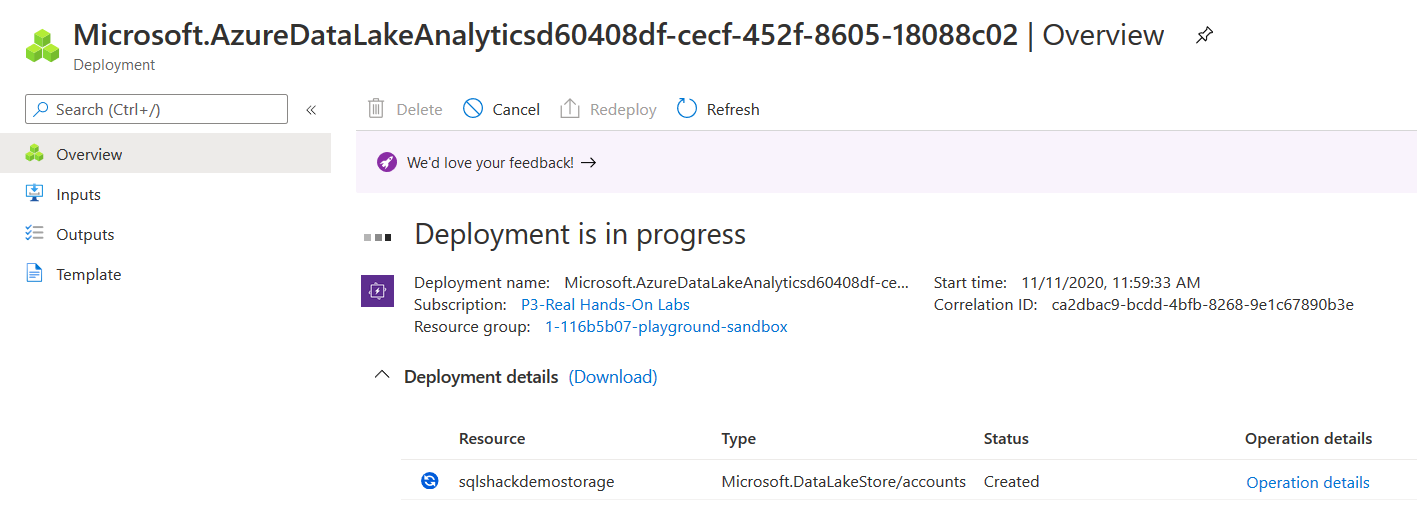
As shown below, it created the Azure Data Lake Analytics Account and data lake storage during the deployment.

Click on Go to Resource, and it opens the analytics account dashboard, as shown below.
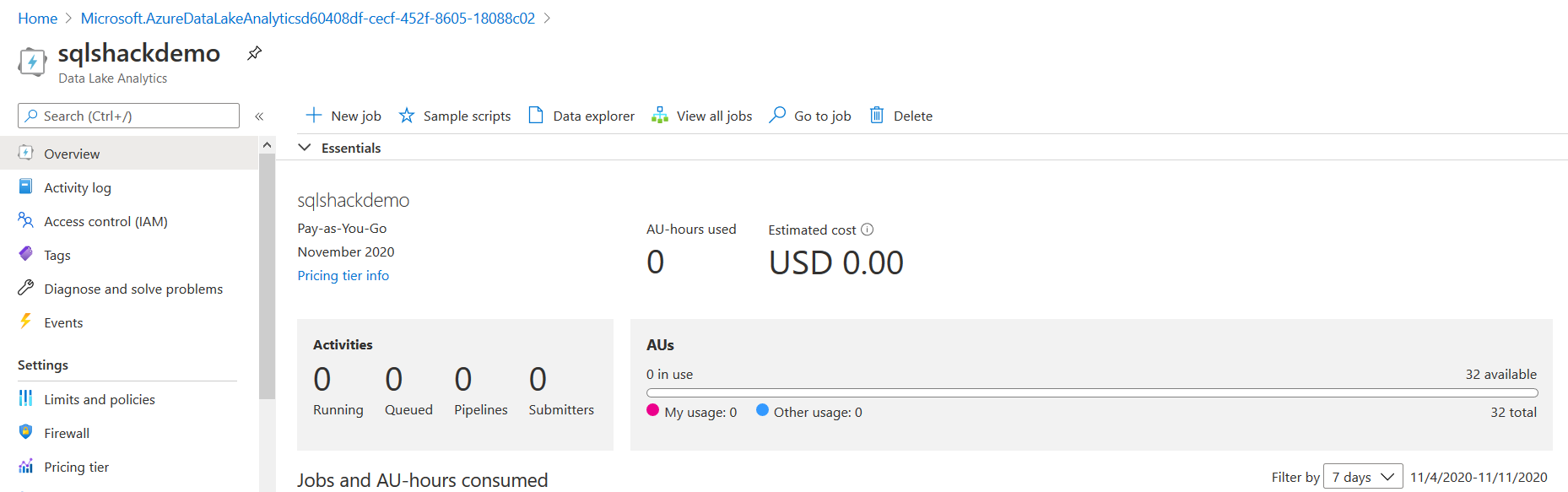
Create a sample job for Azure Data Analytics
Azure Data Lake Analytics uses the U-SQL for query and processing language. The U-SQL language has a combination of SQL and programming language C#. The SQL Server database professionals can quickly become familiar with the U-SQL language.
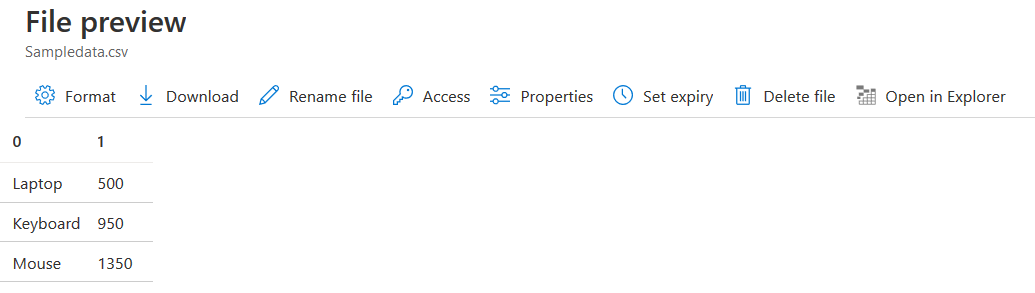
In the example, we use the U-SQL script to define a dataset with few rows and store the Output into the Azure Data Lake Storage Gen1 account. It writes the output in a CSV format file Sampledata.CSV
|
1 2 3 4 5 6 7 8 9 10 11 |
@a = SELECT * FROM (VALUES ("Laptop", 500.0), ("Keyboard", 950.0), ("Mouse", 1350.0) ) AS D( Product, Amount ); OUTPUT @a TO "/Sampledata.csv" USING Outputters.Csv(); |
Click on New Job in the analytics dashboard. Specify a job name and paste your U-SQL script.
In the job configuration, you can choose the minimum Azure Data Lake Analytics Unit (AU) that defines the compute units for the job. It also shows the estimated cost per minute execution. For example, here, it shows the USD 0.03/minutes.
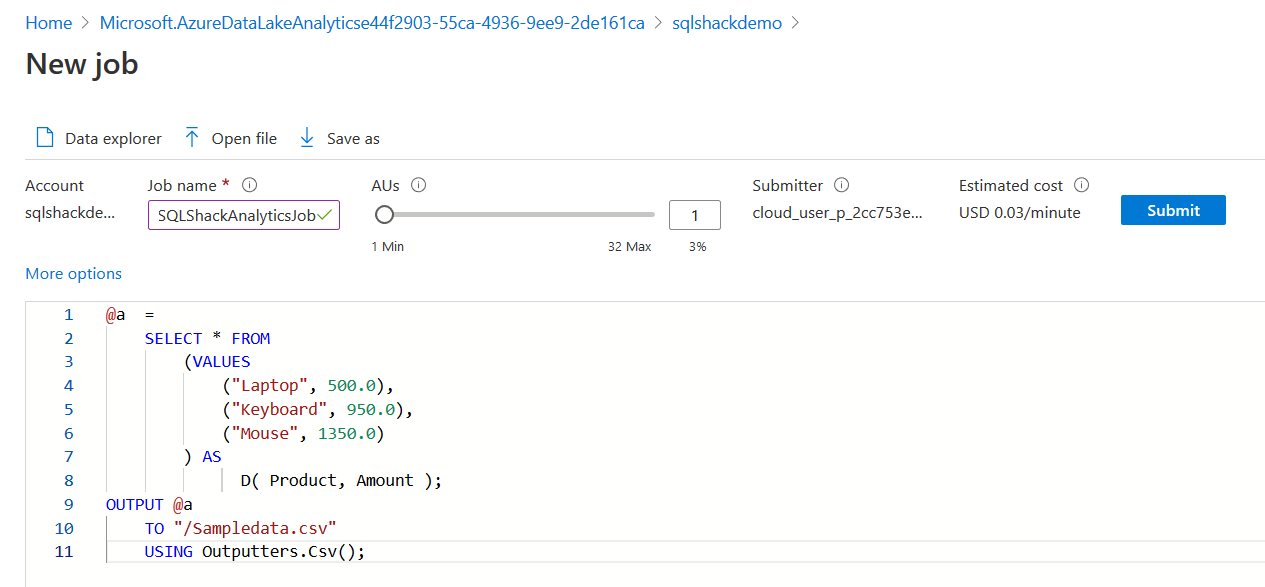
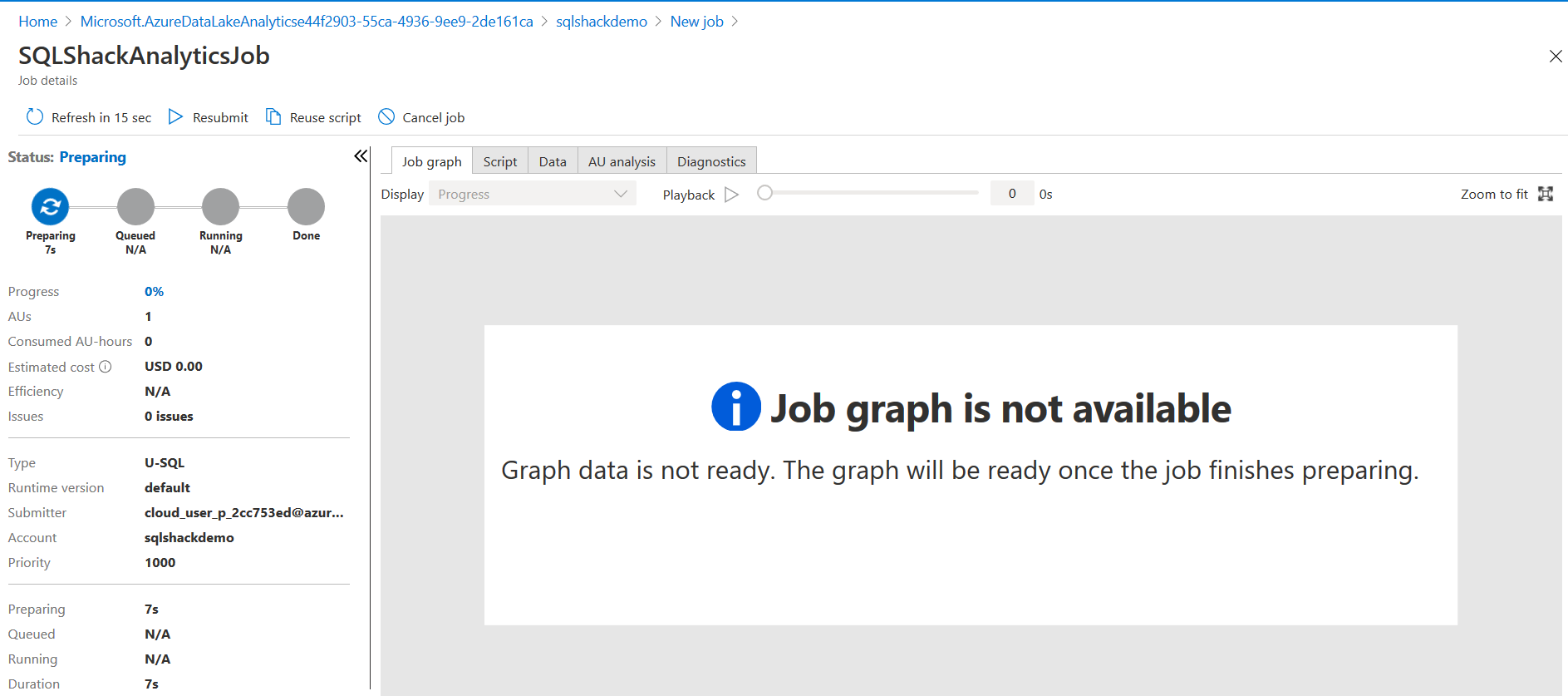
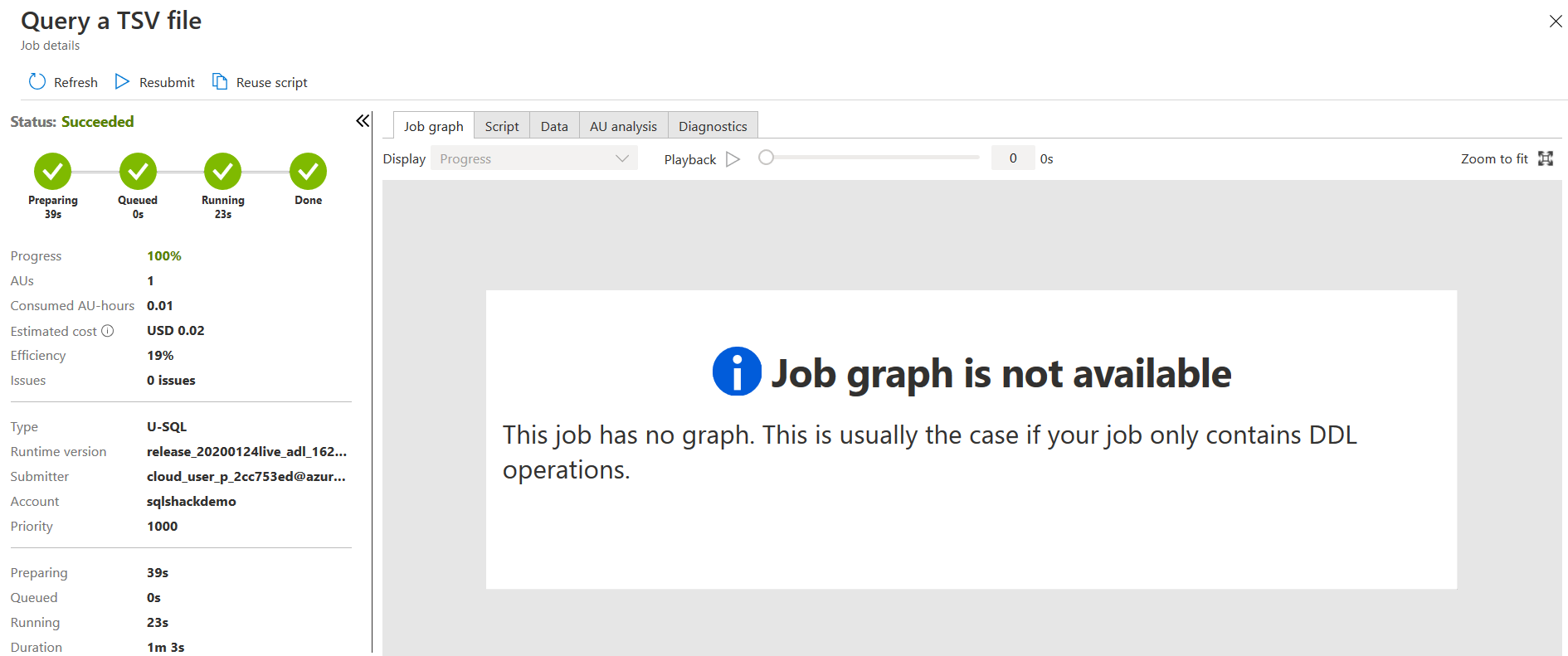
Click on Submit. The job has four phases:
- Preparing: It uploads script in the Azure cloud, compiles and optimize it for execution
- Queued: if the job is waiting for the resources, it shows the status. Usually, if the resources are available, then it does not spend time on the Queued phase
- Running: It starts job execution in the Azure Data Lake Analytics account
- Done: Job execution finished
Once the job execution finishes, you see a job graph with various steps. Azure data lake analytics divides the jobs into multiple pieces of work, and each piece is known as Vertex. The below image highlights the Vertex and Job graph. Reference: Microsoft docs.
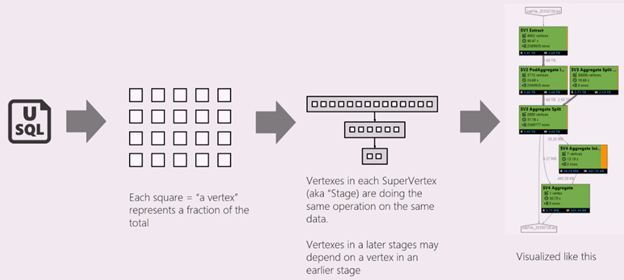
In the Vertex, it gives information about the number of vertices, average execution time, number of rows written. The green color of the Vertex shows a successful status. You might get different colors Orange (Retired), Red(failed), Blue(running), White(waiting).
We will cover more about these job status, Vertex in the upcoming article. However, you can refer to this Microsoft documentation, Job View for Azure Data Lake Analytics for more details.
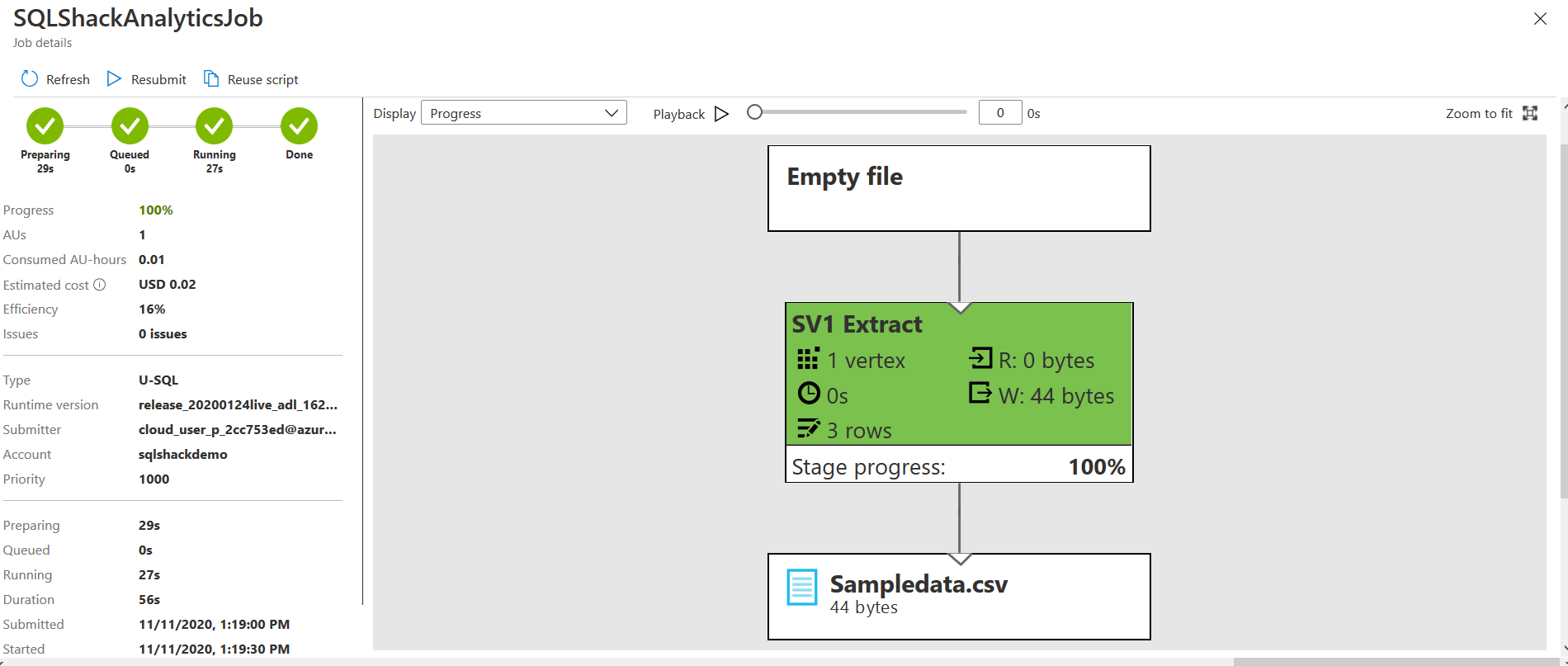
Once the process completes, click on the Data tab and navigate to output. Here, it shows the output CSV file.

You can have an output file preview here or download it or open it in Storage Explorer. As shown below, the CSV file has the data set we specified in the U-SQL script.
Sample Scripts in Azure Data Lake Analytics
Azure portal contains several examples for understanding the Azure Data Lake Analytics, the U-SQL script for the specific task. Click on the Sample scripts in the portal. At first, it asks your permission to download the sample data in the Azure storage.
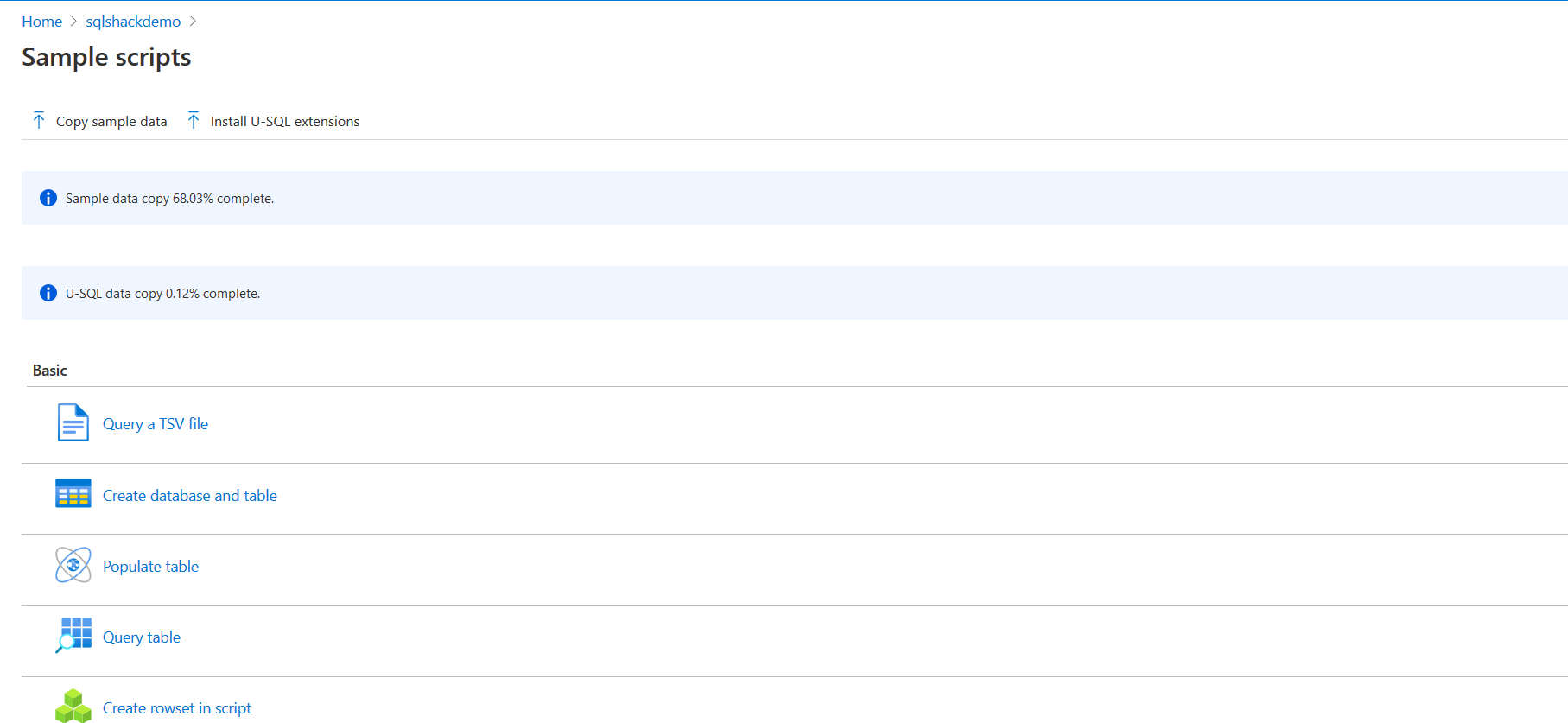
We have several basic tasks such as Query a TSV file, Create database and table, Populate table, Query table, Create rowset in a script.
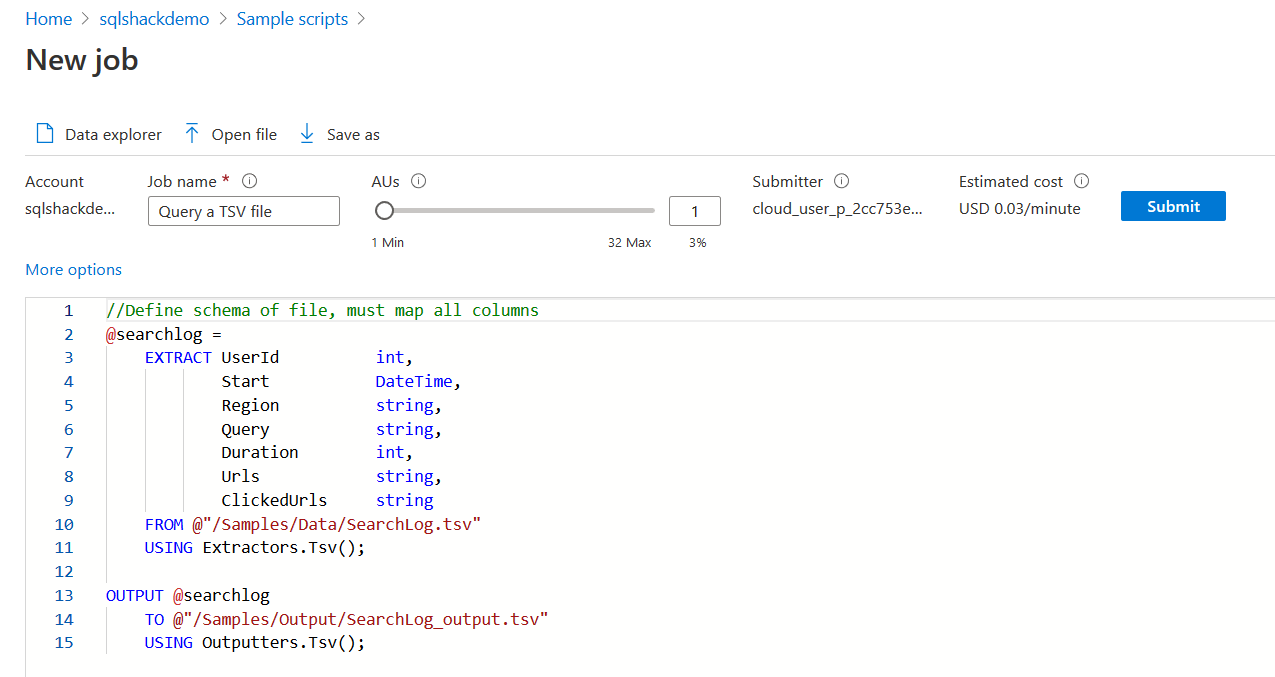
Let’s click on the Query a TSV file. It shows the analytics job and the U-script for the job.
Submit the analytics job, and once it completes, you can preview data in the Azure portal.
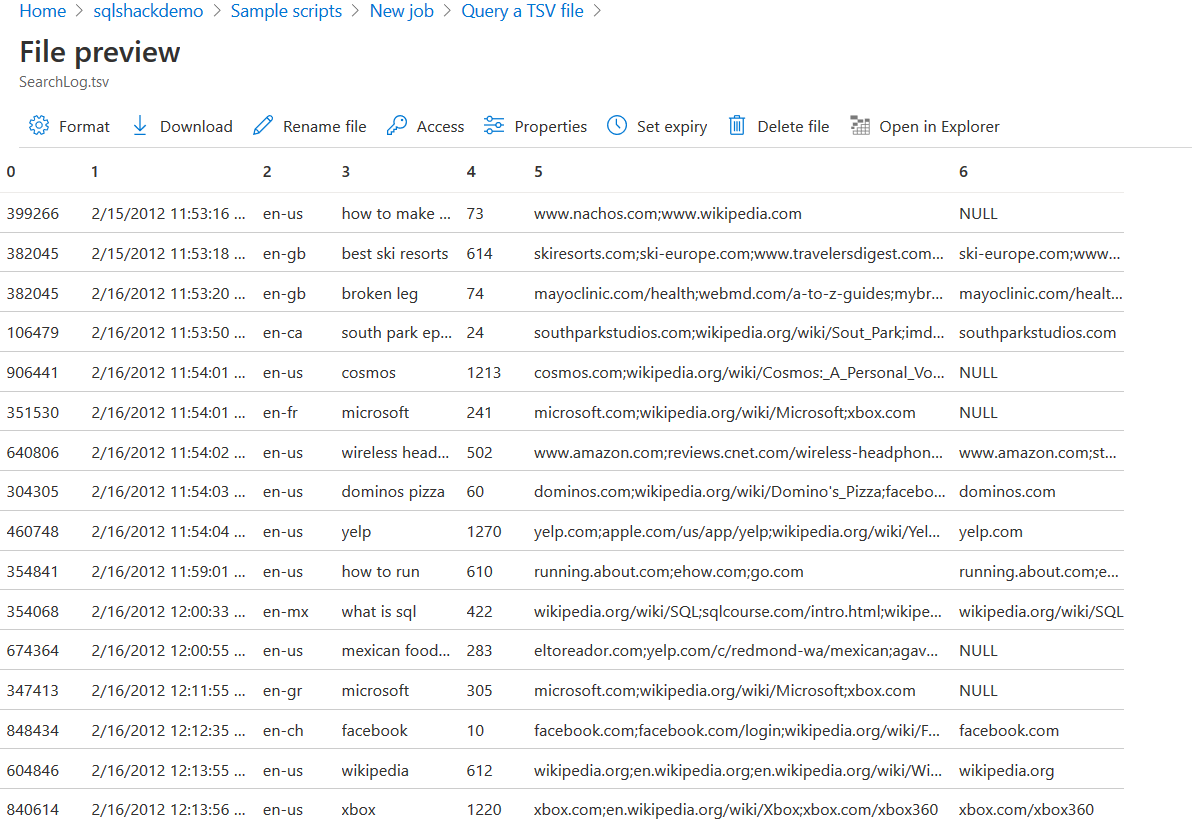
Create a data lake analytics job for query CSV file stored in the Azure data storage
In the previous example, we did not perform any data transformation. We read the source data and prepared an output in the CSV format.
For this example, download a sample CSV file from the URL
Upload the files in the Azure storage associated with the data lake analytics account.
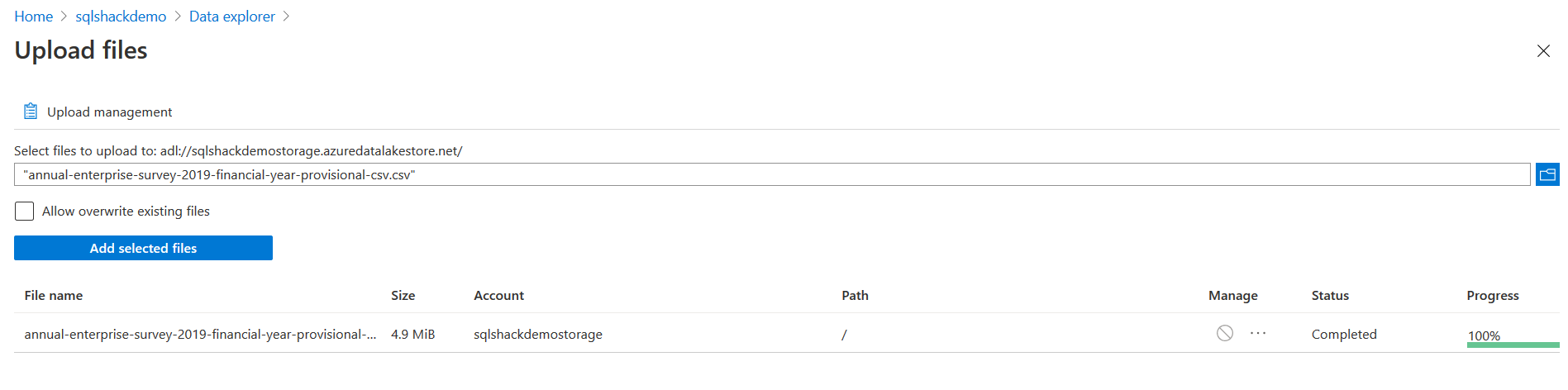
Create a new analytics job and specify the U-SQL script.
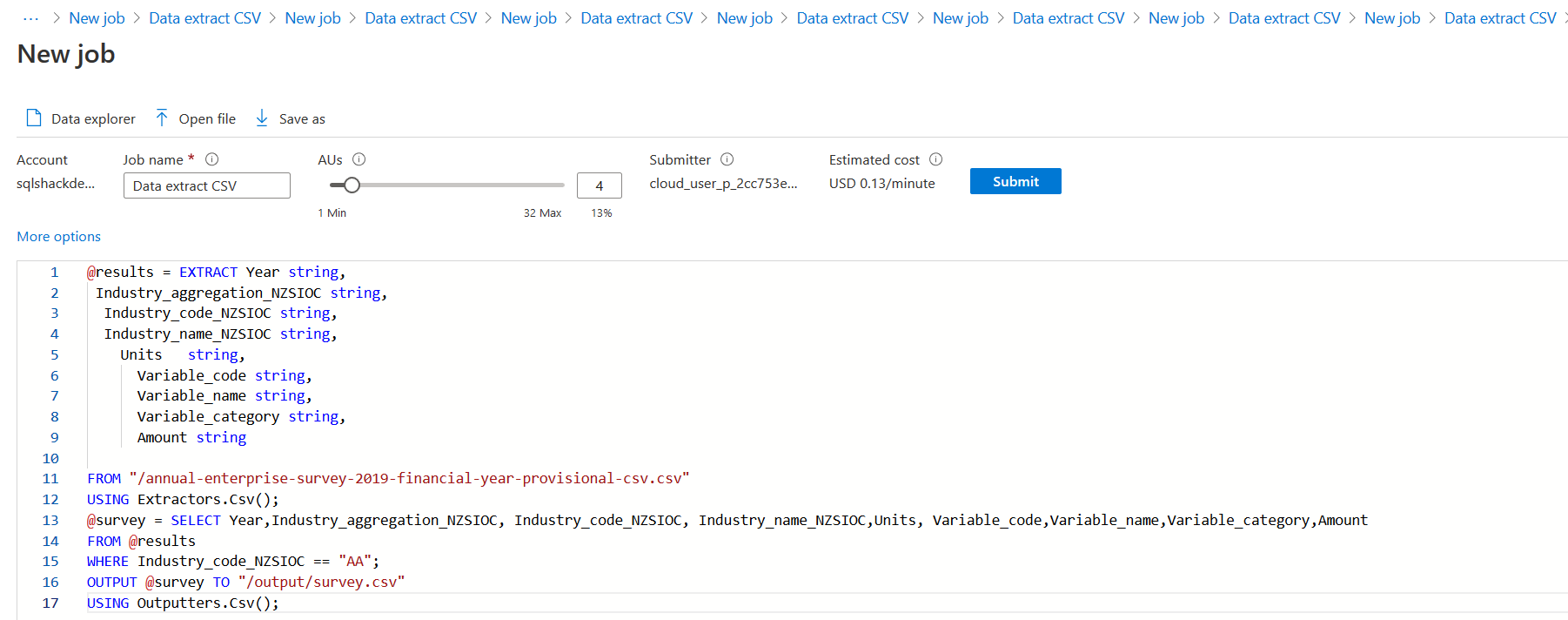
In this example, we apply a quick transformation in the extracted data. It uses a where clause to filter the records in the input CSV and writes the output in the CSV format file.
We can divide the overall query into three sections.
Extract process: It uses the EXTRACT statement. It is similar to a declare statement the t-SQL where we define the column and data types. For simplicity, I use string type for all columns. It uses the predefined extractor for CSV using the Extractors.Csv()
123456789101112@results = EXTRACT Year string,Industry_aggregation_NZSIOC string,Industry_code_NZSIOC string,Industry_name_NZSIOC string,Units string,Variable_code string,Variable_name string,Variable_category string,Amount stringFROM "/annual-enterprise-survey-2019-financial-year-provisional-csv.csv"USING Extractors.Csv();Transforming Data: In this step, we access the columns and do the transformation. In the below command, we filter the records satisfying a specific condition in the Where clause
123@survey = SELECT Year,Industry_aggregation_NZSIOC, Industry_code_NZSIOC, Industry_name_NZSIOC,Units, Variable_code,Variable_name,Variable_category,AmountFROM @resultsWHERE Industry_code_NZSIOC == "AA";Output Transformed Data in CSV format: Next, we save the output in the CSV format and specify the directory and file name. It uses the OUTPUT statement in the U-SQL. The Using statement specifies the extractor function for a CSV file in the U-SQL
12OUTPUT @survey TO "/output/survey.csv"USING Outputters.Csv();
Submit the job and view the progress. You can view the job graph on completion.
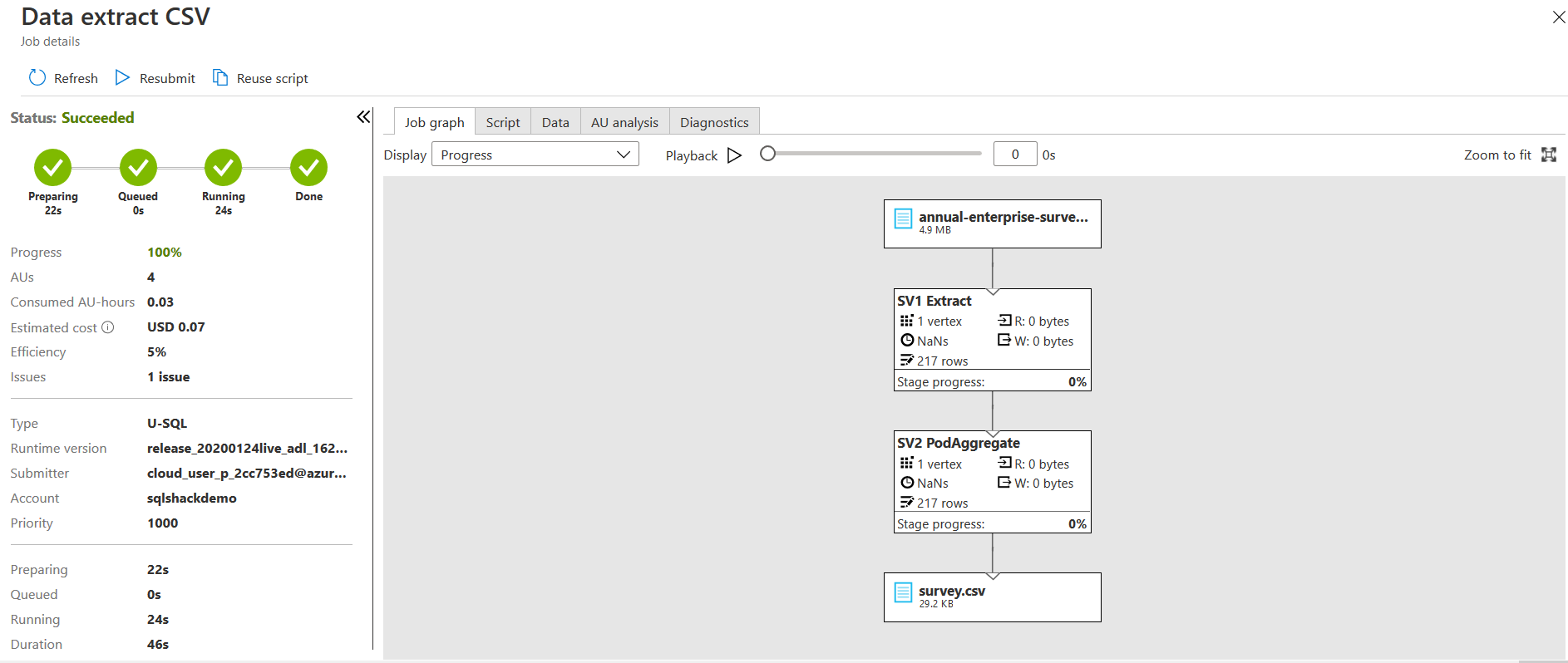
It creates the output file, as shown in the data tab.

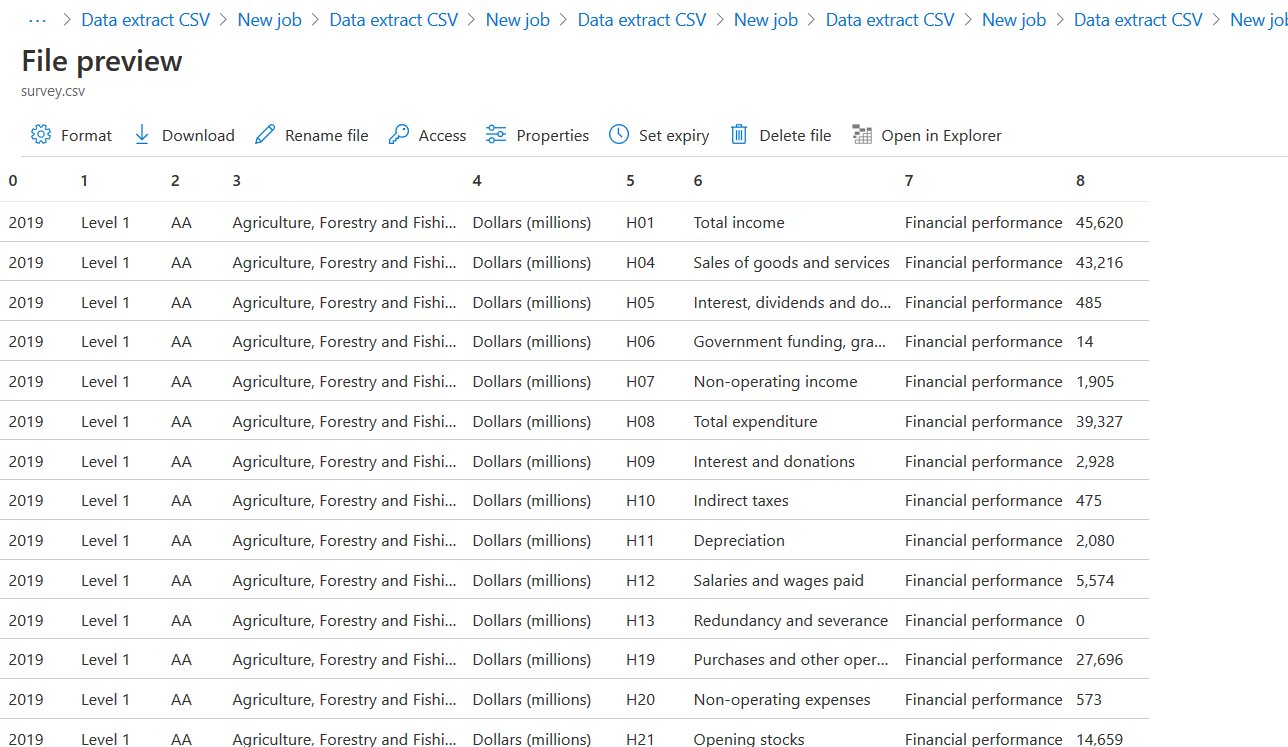
Below is the file preview and you can see it filters records for category defined in the where clause ( column 2).
Conclusion
In this article, we explored Azure Data Analytics and U-SQL scripts for external query data stored in the Azure data lake. The next articles in this series will explore more features of U-SQL for Data Analytics.
Table of contents
| An overview of Azure Data Lake Analytics and U-SQL |
| Writing U-SQL scripts using Visual Studio for Azure Data Lake Analytics |
| Deploy Azure Data Lake Analytics database using the U-SQL scripts |
| Join database tables using U-SQL scripts for Azure Data Lake Analytics |

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023