
In this 3rd article of the Azure Data Lake Analytics series, we will explore deploying a database, tables using U-SQL scripts.
Introduction
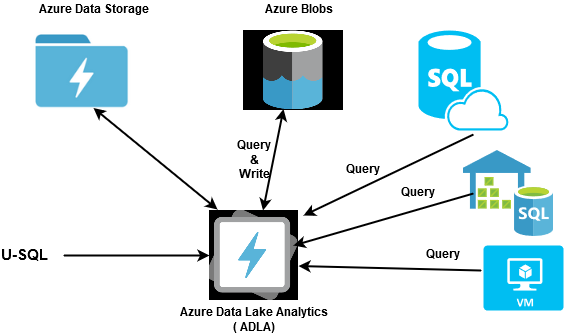
In the earlier articles of the series, we explored the U-SQL language for Azure Data Lake Analytics. It is a similar language having syntax similar to T-SQL, and it combines the power of C# language. You can develop the script locally in the Visual Studio and deploy it later in the ADLA. As shown below, the ADLA script works with Azure Data Lake Storage, Blob Storage, Azure SQL, Azure Data Warehouse and SQL Server on Azure VMs. U-SQL language query data without copying data from various data sources without copying them in one place. For external systems such as Azure SQL Database, SQL Server in Azure, it uses the pushed down approach that processes data at the data source and returns the results.
In a SQL Server instance, the database is like a container that has objects such as tables, views, stored procedures, functions. Database professionals are familiar with the database terms. Therefore, Microsoft uses a similar structure for U-SQL or Azure Data Lake Analytics as well.
For my lab environment, I have [adlademosqlshack] Azure Data Lake Analytics account. In the previous article, Execute the U-SQL Script Using Visual Studio, we explored the integration of the Visual Studio environment with the Azure account.
By default, Azure Data Lake Analytics uses the master database for its execution. This built-in database master provides the ability to create and drop additional databases as well.
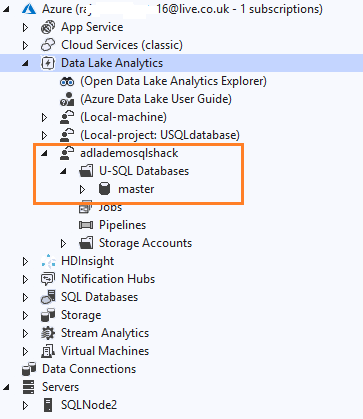
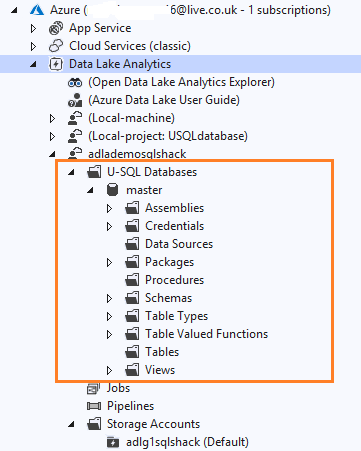
If you expand the master database, it has various folders for tables, views, schemas, procedures, credentials, data sources, packages, table types, table-valued functions.
Create a user-defined database in Azure Data Lake Analytics
In the SQL Server, we use the CREATE DATABASE statement for new database creation. The U-SQL language also uses the same CREATE DATABASE for a new database.
In the below script, we create a database [SQLShackDemo] if it does not exist. Submit the job to your ADLA account.
|
1 |
CREATE DATABASE IF NOT EXISTS SQLShackDemo; |

It submits the job and quickly finishes it successfully. In the metadata operations, you see the entities it creates for you.
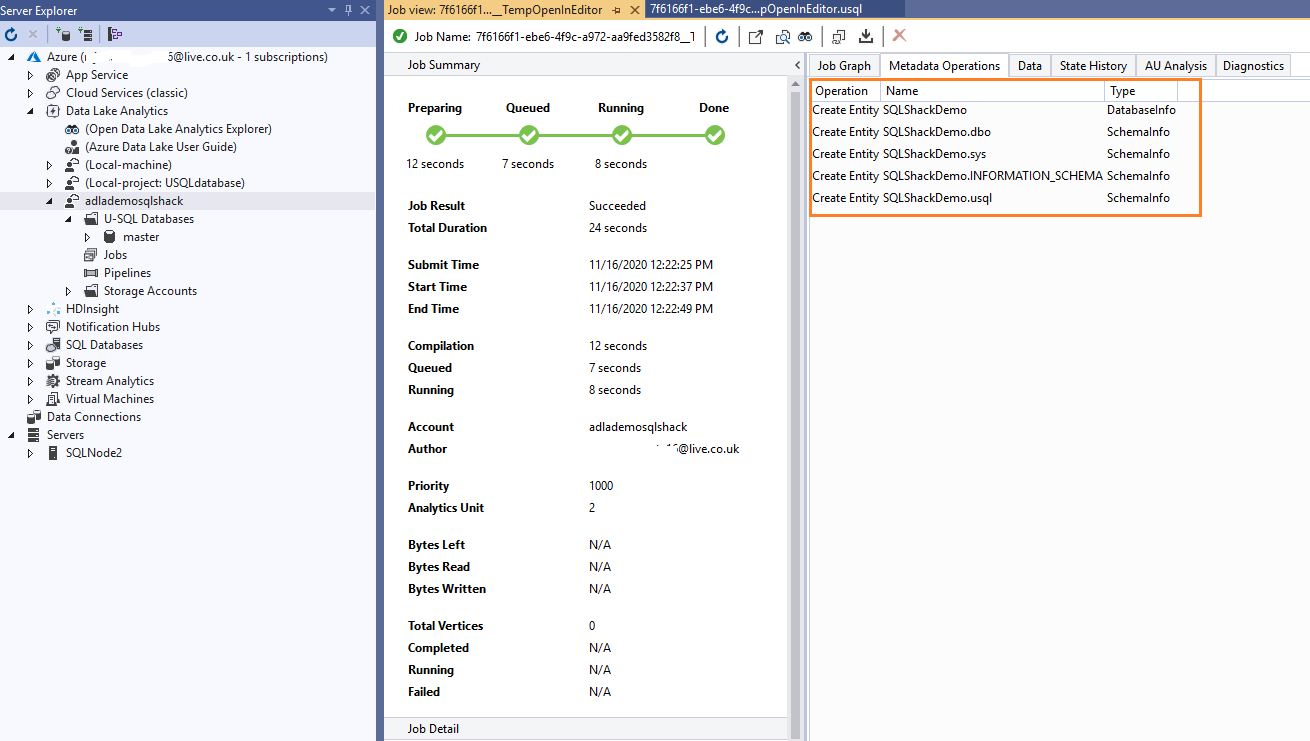
If we click on the Job Graph, it does not show any details because the graph is available for DDL while we performed the metadata operations.
Refresh the Azure Data Lake Analytica account, and you can view the [SQLShackDemo] database along with the prebuilt master database.
![view the [SQLShackDemo] database](/wp-content/uploads/2021/02/view-the-sqlshackdemo-database.png)
Database schema
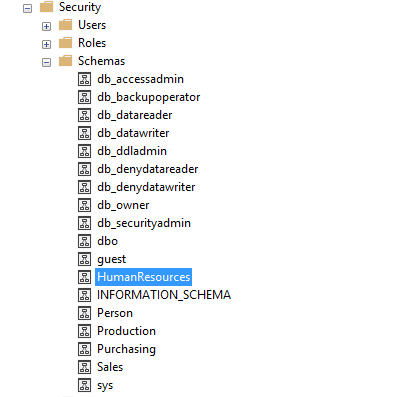
The database schema is a collection of similar objects within a database. For example, in SQL Server, if we expand the sample database [AdventureWorks], we see both system-defined and user-defined schemas. It uses DBO as the default database system schema while it has Person, Production, Purchasing, Sales, [HumanResources] user-defined schemas.
Similar to the SQL Server, U-SQL also has a default schema dbo in every database. Let’s add a new user-defined schema [Sales] in the [SQLShackDemo] analytics database. Similar to the t-SQL language, we specify the database name with the USE statement. For example, here, we want to create the schema in the [SQLShackDemo] database.
|
1 2 |
USE SQLShackDemo; CREATE SCHEMA IF NOT EXISTS Sales; |
It creates the entity SQLShackDemo.Sales, as shown below:
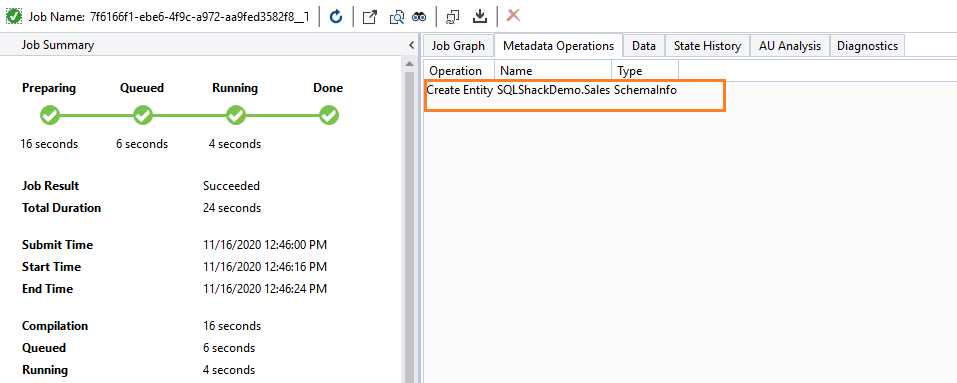
Refresh schemas for the [SQLShackDemo] database in the Azure Data Lake Analytics account and you have a new [Sales] schema as shown below:
![new [Sales] schema](/wp-content/uploads/2021/02/new-sales-schema.png)
Database tables in ADLA
We can create the tables in the Azure Data Lake Analytics, similar to the SQL Server tables. It requires table schema, columns and their data types in the script.
- Managed tables: The managed tables have both table definition as well as table data. U-SQL maintains data consistency between table schema and data. If you delete the table, its data is also deleted
- External tables: In the external table, we define a table schema, but its reference data exists externally. Data can exist in the Azure SQL database, SQL on Azure VM. In this case, Azure Data Analytics does not manage data consistency. You might remove the external data without the external table. Similarly, you can drop an external table without affecting the underlying data
Create a managed table
You can create a table in ADLA similar to a SQL Server table. However, it has a few mandatory requirements:
- Table Name
- Table columns
- Clustered Index
- Partitioning scheme
In this article, we use the CSV file downloaded from the URL. It uses the CREATE TABLE IF NOT EXISTS statements for creating a new table. We define the table structure that contains the column names and their data types.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Use SQLShackDemo; Use Sales; CREATE TABLE IF NOT EXISTS SalesRecords ( Region] string, [Country] string, [Item Type] string, [Sales Channel] string, [Order Priority] string, [Order Date] DateTime, [Order ID] int, [Ship Date] DateTime, [Units Sold] int, [Unit Price] decimal, [Unit Cost] decimal, [Total Revenue] decimal, [Total Cost] decimal, [Total Profit] decimal ); |
Index: U-SQL supports the clustered index. In the table statement, we need to define the index name and the column for the index. For example, let’s create the clustered index on the [Order ID] column. Similar to a Clustered index in SQL Server, it determines the physical data storage in the U-SQL table.
Table Partitions and Distributions
Each table must have a distribution scheme to partition data inside the table. It supports four partitioning schemes:
- Hash: In this partitioning scheme, we specify the column ( for example [Order ID]) and its values are hashed for fast lookups. We can use a single key or multiple keys as per our requirements
- Range: In the range keys, the system determines the boundaries for data distributions
- Direct hash: In the direct hash, we provide the hashing key as part of the key in the table. You can use an integral type column for this purpose
- Round Robin: It uses round-robin fashion for data distribution and keeps the same number of rows( approximate) across each distribution
You can refer to Microsoft docs for more details on the partitioning scheme. We will also cover in detail in further articles for this series.
In the below script, we added the clustered index and distribution using the HASH on the [Order ID] column.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
USE DATABASE SQLShackDemo; USE SCHEMA Sales; CREATE TABLE IF NOT EXISTS SalesRecords ( [Region] string, [Country] string, [Item Type] string, [Sales Channel] string, [Order Priority] string, [Order Date] DateTime, [Order ID] int, [Ship Date] DateTime, [Units Sold] int, [Unit Price] decimal, [Unit Cost] decimal, [Total Revenue] decimal, [Total Cost] decimal, [Total Profit] decimal, INDEX idx_SalesRecords CLUSTERED ([Order ID]) DISTRIBUTED BY HASH ([Order ID]) ); |
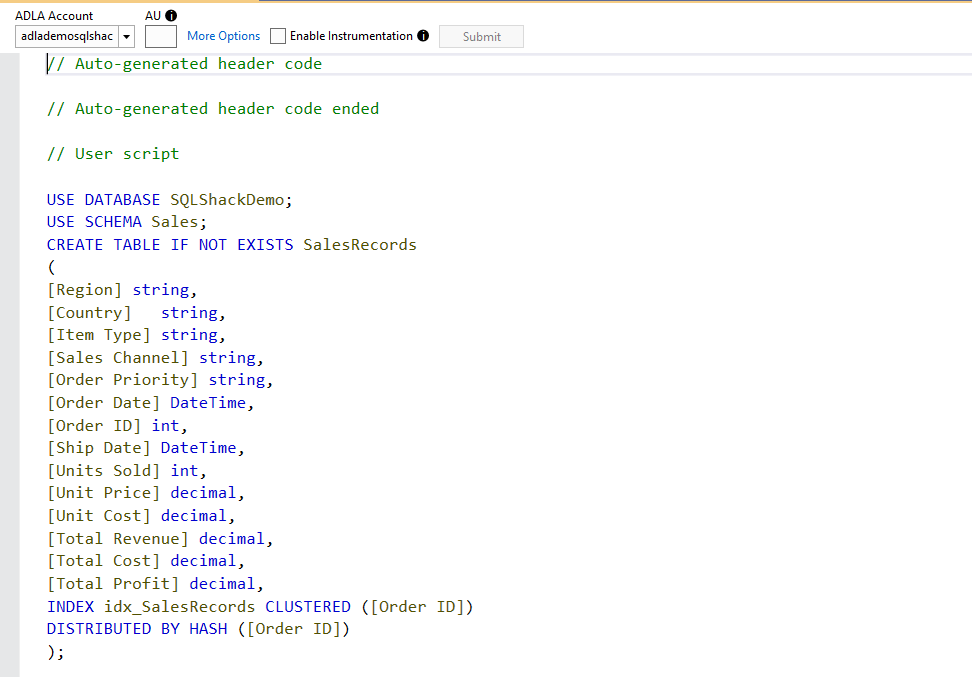
Submit the job and view the status in the job summary.
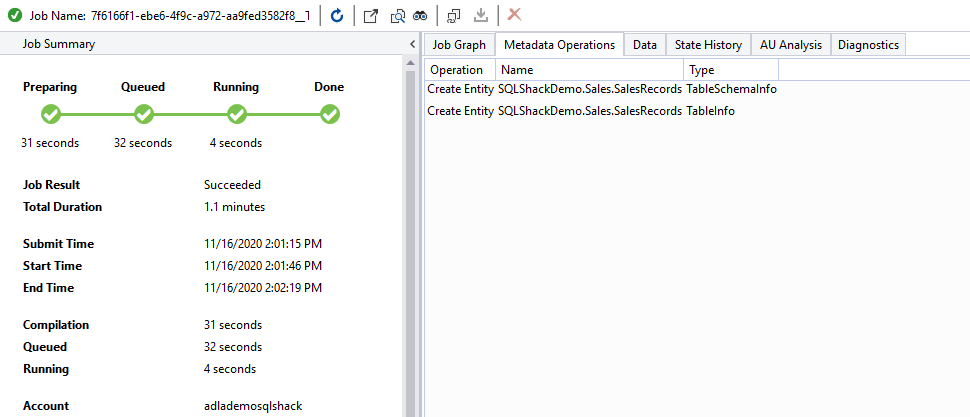
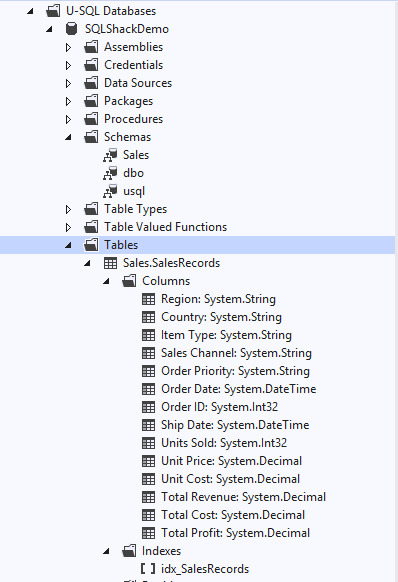
Refresh the user-defined database, refresh the tables and validate the table. You can note the table name has schema name in the prefix. In the Visual Studio console, the table name is [Sales].[SalesRecords]. It also has an index [idx_SalesRecords] as shown in the below image:
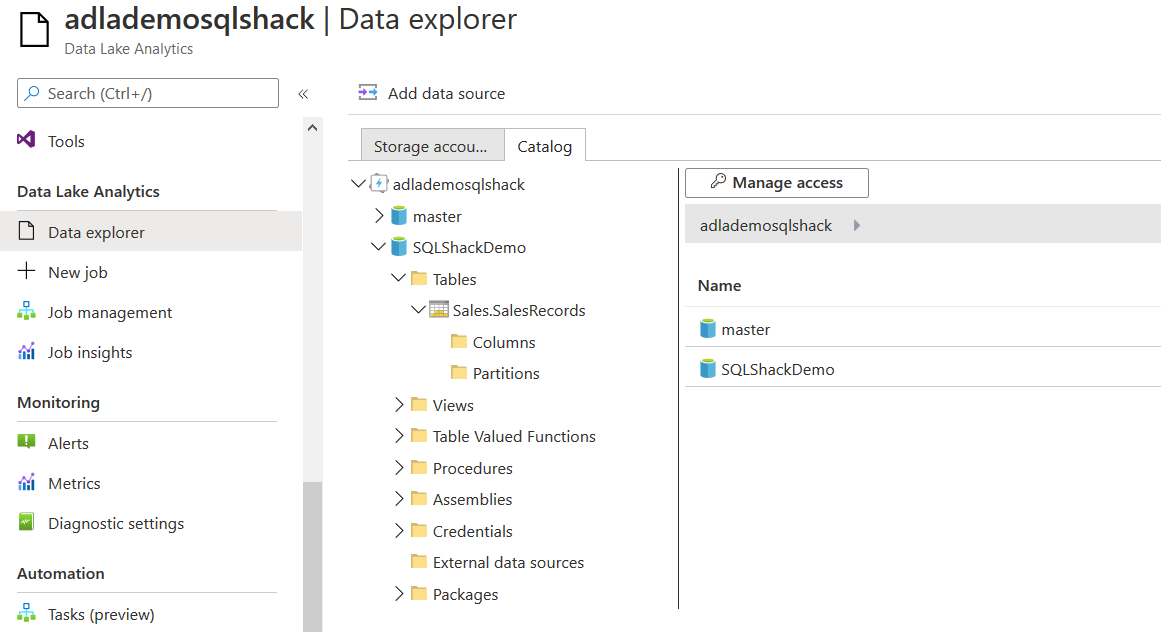
You can also view the database, table, schema in the Azure Web Portal. Connect with your Azure Data Analytics account and navigate to Data explorer. In the data explorer, you get both databases and their folders.
Allow NULL values in a table column for the
In SQL Server, we use NULL or NOT NULL clauses in the T-SQL script for defining the properties of the NULL value. Similar to that, we can define NULL properties in the below script as well.
- String data type allows NULL values
- By default, an integer data type does not allow NULL values. To define the NULL values, we use a question mark (int?) to avoid the job failure. In the below table, we define the NULL values in the [Alternatenumber] column name with the int data type
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE IF NOT EXISTS SQLShackDemo.Sales.Employees ( [EmpID] int, [FirstName] string, [LastName] string, [MobileNumber] int, Alternatenumber int?, INDEX idx_Employee CLUSTERED (EmpID) DISTRIBUTED BY HASH (EmpID) ); |
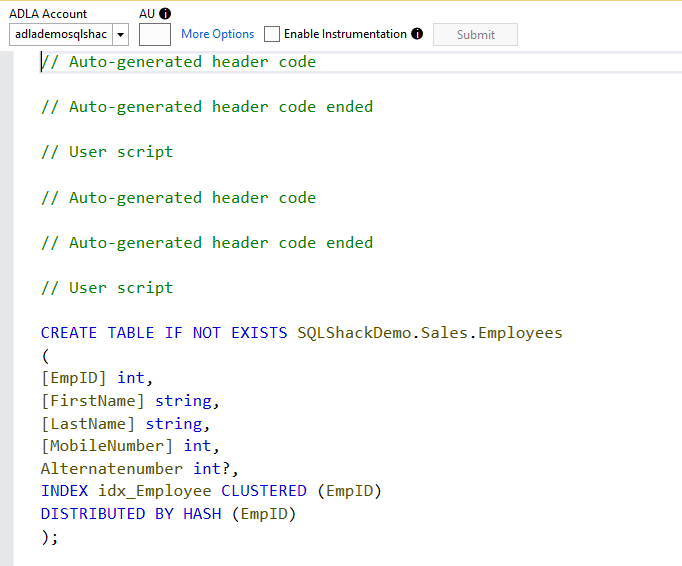
The analytics job is completed successfully.
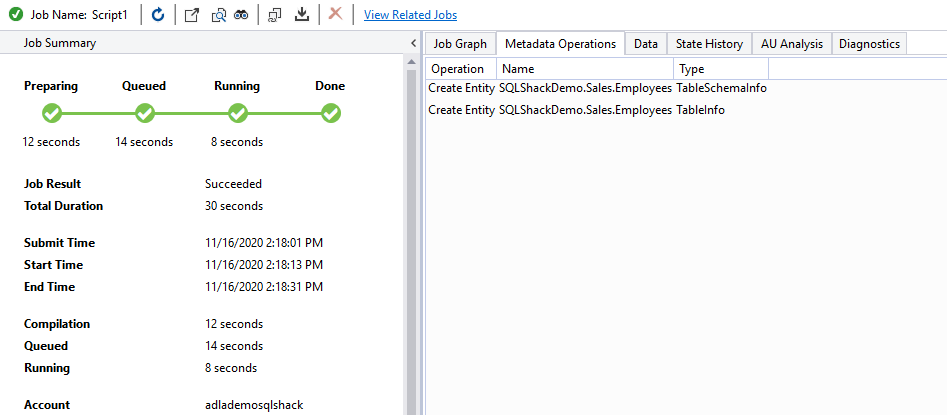
In the below screenshot, view the table (with NULL int column) in Visual Studio.
Import data from a CSV file to the Azure Data Analytics database table using the U-SQL script
Once we have set up a database, schema and table, we can insert data using the script. For this demo, I use the sample CSV file with 2 data rows.

Upload this CSV file into the Azure Data Lake Storage account associated with the ADLA account.

In the previous examples, we extract data from a CSV file, apply transformations and save it to the Azure blob storage. For this purpose, we use a variable and use the EXTRACT command to fetch data from CSV.
The initial part of the script remains the same to insert data into the ADLA database table. In the below table, we used a variable @employee and extracted data into it.
Later, we insert data into the [Sales].[Employees] from the row variable. If you are familiar with the SQL commands, you can quickly write these scripts.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
USE DATABASE SQLShackDemo; USE SCHEMA Sales; @employees = EXTRACT [EmpID] int, [FirstName] string, [LastName] string, [MobileNumber] int, Alternatenumber int? FROM "/Input/employee.csv" USING Extractors.Csv(); INSERT INTO Sales.Employees ( [EmpID], [FirstName] , [LastName] , [MobileNumber], Alternatenumber ) SELECT [EmpID], [FirstName] , [LastName] , [MobileNumber], Alternatenumber FROM @employees; |
It displays the following job graph with a successful status. It took overall 1.7 minutes for 2 ALU’s. In the job graph, you can note down the vertex, read, write bytes.
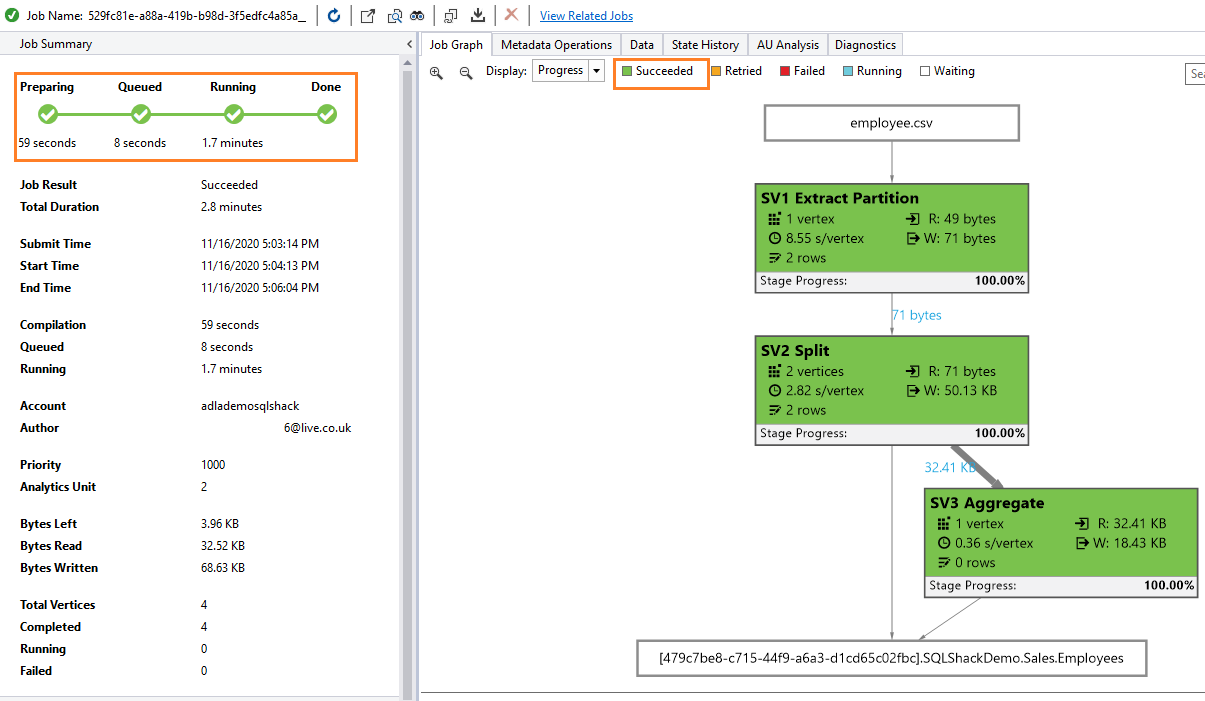
If you want to have detailed information on these vertexes, click on the green box and it takes you at detailed steps overview. For example, the SV1 Extract partition gives the following detailed job graph.
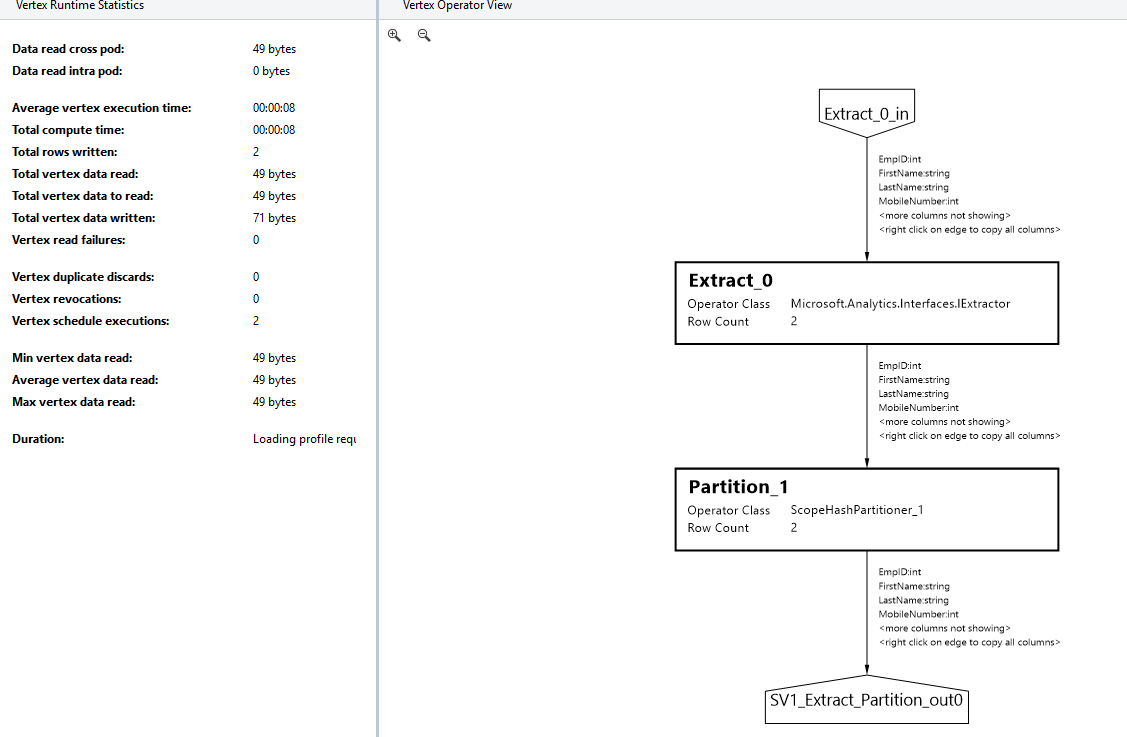
To validate data in the [Sales].[Employees] table, right-click on the table name and preview data. We can validate table has 2 rows, and it matches with the sample CSV file.

Conclusion
In this article, we explored the Azure Data Lake Analytics database, schema, tables using U-SQL scripts. Further, we inserted data into the ADLA database table using an analytical job that gets data from a CSV file. Further, it inserts data into a table similar to a relational table. Stay tuned for the next article on this!
Table of contents
| An overview of Azure Data Lake Analytics and U-SQL |
| Writing U-SQL scripts using Visual Studio for Azure Data Lake Analytics |
| Deploy Azure Data Lake Analytics database using the U-SQL scripts |
| Join database tables using U-SQL scripts for Azure Data Lake Analytics |

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023