
In this article, we will explore joining database tables using U-SQL scripts for Azure Data Lake Analytics.
Introduction
Azure Data Lake Analytics enables you to configure on-demand jobs using U-SQL scripts. These scripts can transform data and extract information without a predefined schema. You can extract data in any format stored in Azure data lake storage, Azure blob storage, Azure SQL database, or Azure SQL on virtual machines. In the article, Deploy Azure Data Lake database using the U-SQL scripts, we explored that ADLA uses a database structure similar to a SQL Server database. It is a container having folders for various objects such as tables, schema, procedures, packages, credentials, data sources. By default, it uses a master database and DBO schema for creating tables.
We can also design schema, tables in the ADLA database similar to the SQL Server database using the T-SQL script. We use SQL joins to fetch data from multiple tables. It also supports the join operations in the Azure data lake analytics database similar to a SQL database.
We will explore these joins in this article.
Prerequisites
You can follow articles (see TOC at the bottom) to prepare the following environment:
- Create the Azure Web portal credentials and configure the Azure Data Lake account
- Install Visual Studio with Azure Data Lake and Stream Analytics Tools
- Connect Visual Studio with your Azure subscriptions
Joins in U-SQL scripts for Azure Data Lake Analytics (ADLA)
The ADLA database supports the following joins:
- Inner Join
- Full | Left | Outer Join
- Cross Join
- Left | Right semijoin
- Left | Right antisemijoin
Before we move forward and explore these joins, we need to prepare a database environment for demonstration purposes. In this article, I use the [Local-Machine] environment for script execution.
Create a new project in the Visual Studio for U-SQL script and do the following:
-
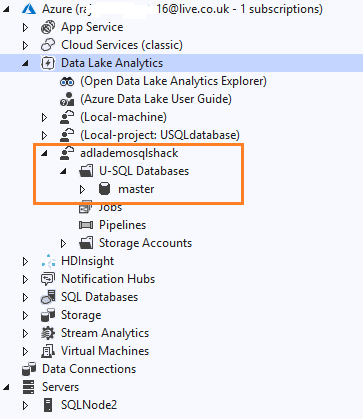
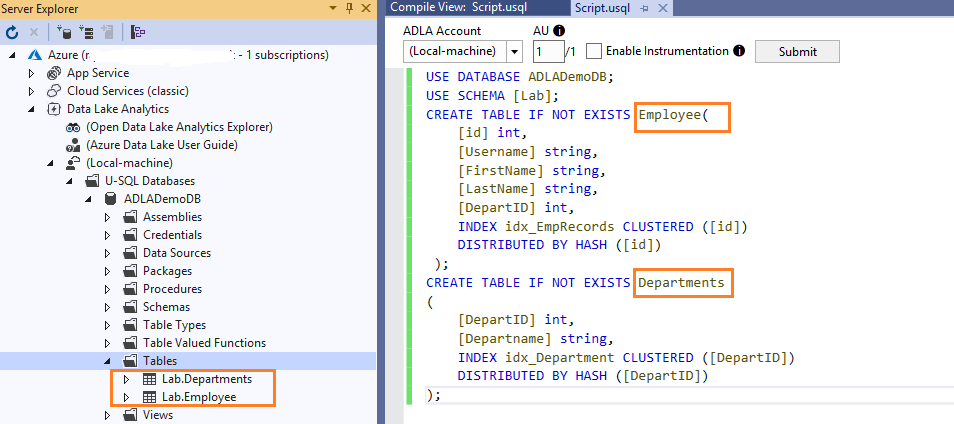
Create a database [ADLADEMODB]
1CREATE DATABASE IF NOT EXISTS [ADLADemoDB];Submit the Job, and it creates a new database, as shown below

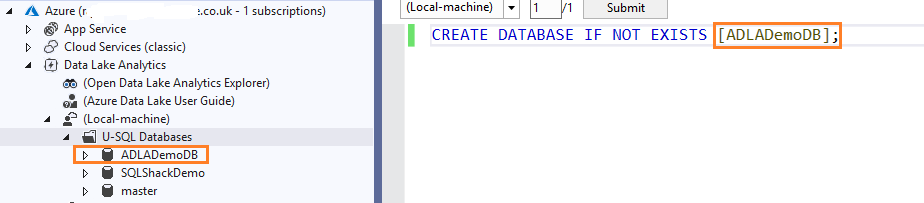
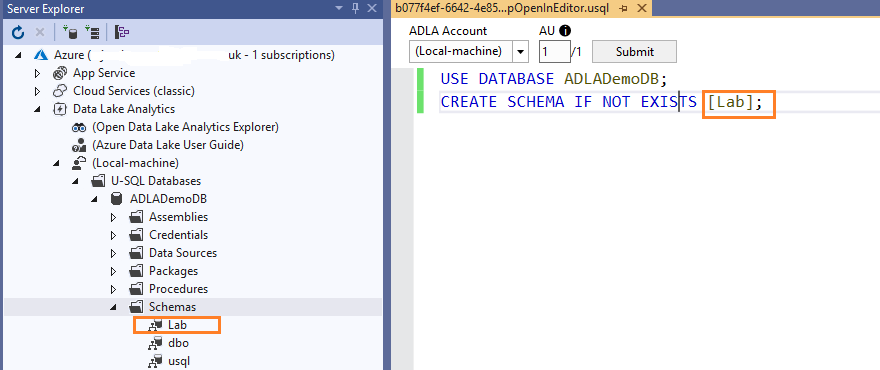
Create a database schema [Lab] in the [ADLADemoDB]
12USE DATABASE ADLADemoDB;CREATE SCHEMA IF NOT EXISTS [Lab];Create the tables [Lab].[Employee] and [Lab].[Departments] in the [ADLADemoDB]
The table structure looks familiar to the SQL table. You can explore syntax for Azure Data lake Analytics in this article, Deploy Azure Data Lake database using the U-SQL scripts
123456789101112131415161718USE DATABASE ADLADemoDB;USE SCHEMA [Lab];CREATE TABLE IF NOT EXISTS Employee([id] int,[Username] string,[FirstName] string,[LastName] string,[DepartID] int,INDEX idx_EmpRecords CLUSTERED ([id])DISTRIBUTED BY HASH ([id]));CREATE TABLE IF NOT EXISTS Departments([DepartID] int,[Departname] string,INDEX idx_Department CLUSTERED ([DepartID])DISTRIBUTED BY HASH ([DepartID]));We have tables, as shown in the below image
Insert sample data into the [Lab].[Employee] and [Lab].[Departments]
- For inserting sample data, we extract data from the CSV file stored in the local file system. The high-level steps for the below script are:
- Define a row variable and extract data into it using the EXTRACTOR.CSV() function
- Insert data into a SQL table from stored the row-level variable
To be familiar with the below U-SQL script, refer to Table of contents at the bottom
1234567891011121314151617181920212223242526USE DATABASE ADLADemoDB;USE SCHEMA [Lab];@employee = EXTRACT[id] int,[Username] string,[FirstName] string,[LastName] string,[DepartID] intFROM "/Input/First/employee.csv"USING Extractors.Csv();INSERT INTO Employee([id],[Username] ,[FirstName] ,[LastName] ,[DepartID])SELECT [id],[Username] ,[FirstName] ,[LastName] ,[DepartID]FROM @employee;The job graph for the above insert statement is as below:
Right-click on the table in Visual Studio and choose Preview
Similarly, insert data in the [Lab].[Departments] table
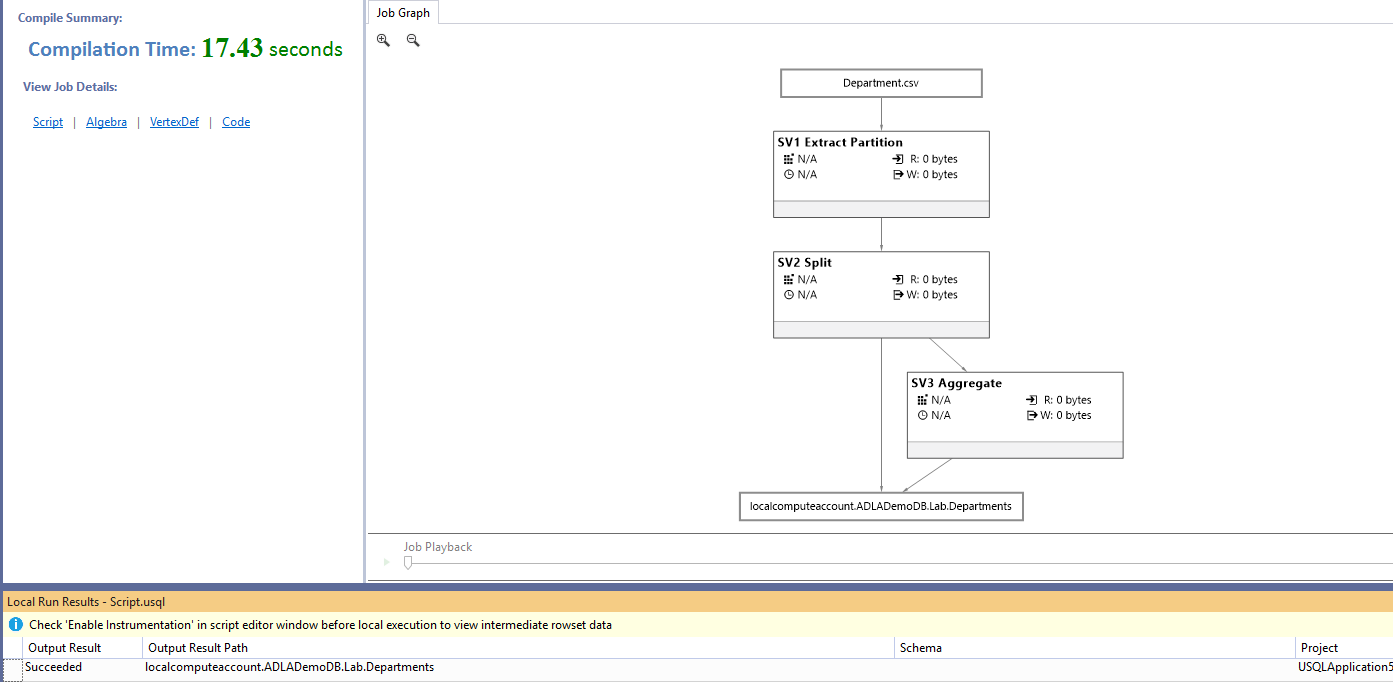
1234567891011121314151617USE DATABASE ADLADemoDB;USE SCHEMA [Lab];@department = EXTRACT[DepartID] int,[Departname] stringFROM "/Input/First/Department.csv"USING Extractors.Csv();INSERT INTO Departments([DepartID],[Departname])SELECT [DepartID],[Departname]FROM @department;The job graph for the above insert script is as below:
You can preview the records to validate the records in the table

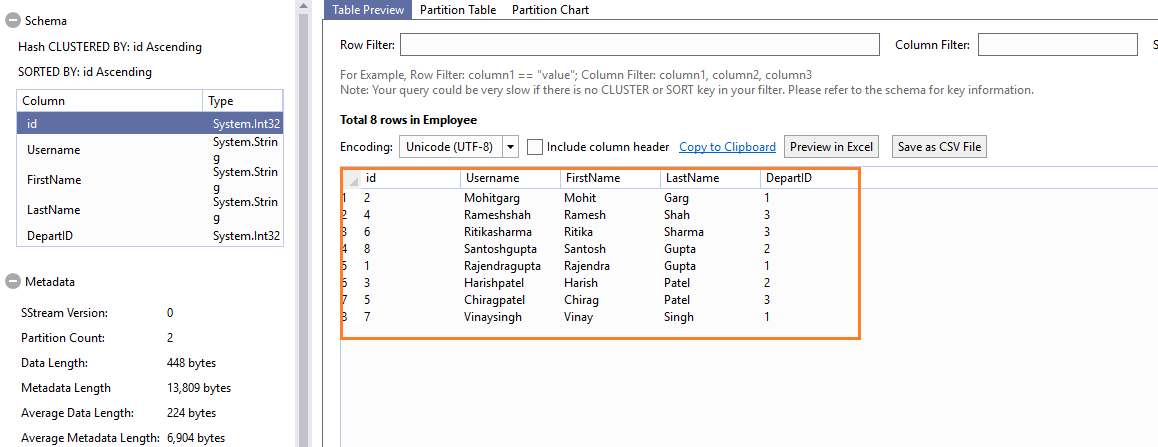
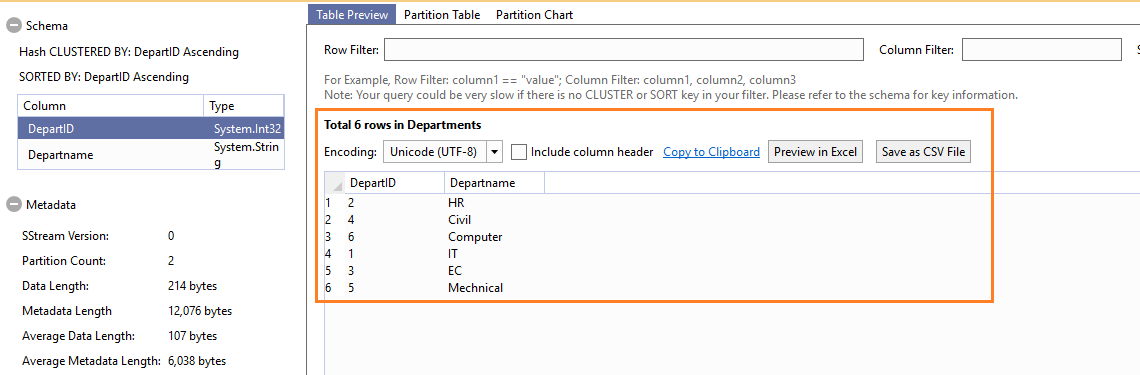
Explore Joins in U-SQL scripts
The inner join, Outer join ( Left\Right\Full) and Cross join works similar to the SQL Server joins. You can understand and explore them in the article, SQL Join types overview and tutorial.
However, there is a small difference in the way you write join for the Azure Data Lake Analytics job. For example, let’s say we want to perform an inner join that returns the matching rows between both tables.
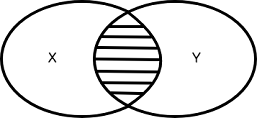
The inner join script looks like the below for ADLA:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE DATABASE ADLADemoDB; USE SCHEMA [Lab]; @output = SELECT E1.Username, E1.FirstName, E1.LastName, D1.Departname FROM Lab.Employee AS E1 INNER JOIN Lab.Departments AS D1 ON D1.DepartID == E1.DepartID; OUTPUT @output TO "/Input/First/SQLJOIN1.csv" USING Outputters.Csv(); |
Important points regarding the above script are:
- The AS keyword is mandatory for table alias. For example, in the script, we used the alias using the Lab.Employee AS E1
-
For the table alias:
- Either use a single letter such as Lab.Employee AS E
- Use a numeric value after the first letter, such as Lab.Employee AS E1
- If you use multiple characters, make sure the only first letter of an alias to be in capital else your script would fail. For example, Lab.Employee AS Ey
- In the t-SQL script, we use the equality operator (=) in the join condition. Here, we use the C# equality symbol (==). For example, ON D1.DepartID == E1.DepartID;
-
It is a case-sensitive language
- Use the keywords such as SELECT, FROM, AS, OUTPUT, USING in capital letters
- Use the column names and table names similar to what you define while creating the table structure. For example, if you defined the table name as [Employee], you cannot refer to it as [EMPLOYEE]
Submit the script to perform the inner join between ADLA tables and write the output in a CSV file. Browse to your directory and open the CSV file to verify the join output.
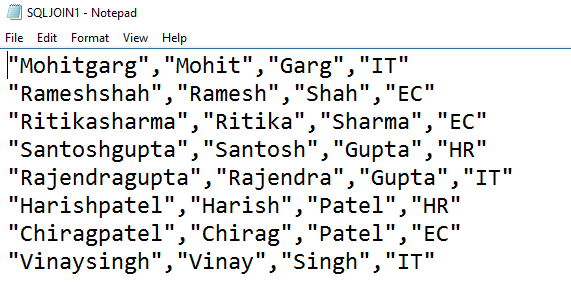
In the job graph, it shows the input of 2 streams ( Employee and Department) table and output to the SQLJoin1.CSV file.
Semijoins
Semijoins does not perform a complete join. It filters data based on the rows in another row set. For example, in the t-SQL scripts, we write the semijoin script like below.
|
1 |
SELECT * FROM TableA WHERE A.ID IN (SELECT B.ID FROM TableB) |
We have two types of semijoin: left or right semijoin.
- Left semijoin: A left semijoin returns rows in the left rowset having a matching row in the right rowset. If we specify only semijoin keyword, it also refers to the left semijoin
- Right semijoin: A right semijoin returns rows in the right rowset having a matching row in the left rowset
In the below U-SQL script, we define a left semijoin between @Product and @Category row variable.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
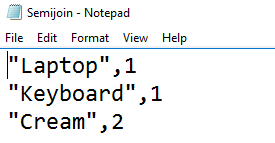
@Product = SELECT * FROM (VALUES ("Laptop", (int?) 1) , ("Keyboard", (int?) 1) , ("Cream", (int?) 2) , ("Ring", (int?) null)) AS P(ProductName, ProductID); @Category = SELECT * FROM (VALUES ((int) 1, "Electronics") , ((int) 2, "Consumer items")) AS C(ProductID, CategoryName); @output = SELECT pe.ProductName, pe.ProductID FROM @Product AS pe LEFT SEMIJOIN (SELECT (int?) ProductID AS ProductID , CategoryName AS CategoryName FROM @Category) AS ce ON pe.ProductID == ce.ProductID; OUTPUT @output TO "/Input/First/Semijoin.csv" USING Outputters.Csv(); |
Data in the output CSV file is as below. We do not have a row for the Ring product because it does not have any matching row in the @Category variable.
Similarly, we use the below U-SQL script for the right semijoin.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
@Product = SELECT * FROM (VALUES ("Laptop", (int?) 1) , ("Keyboard", (int?) 1) , ("Cream", (int?) 2) , ("Ring", (int?) null)) AS P(ProductName, ProductID); @Category = SELECT * FROM (VALUES ((int) 1, "Electronics") , ((int) 2, "Consumer items") ,((int) 3, "Building Material")) AS C(ProductID, CategoryName); @output = SELECT ce.ProductID, ce.CategoryName FROM @Product AS pe RIGHT SEMIJOIN ( SELECT (int?) ProductID AS ProductID, CategoryName AS CategoryName FROM @Category ) AS ce ON pe.ProductID == ce.ProductID; OUTPUT @output TO "/Input/First/Semijoin.csv" USING Outputters.Csv(); |
It returns the product id 1, 2 in the output because it has a matching row in the left rowset.

Anti-Semijoin
As its name suggests, Anti-semijoin works opposite to semijoin. I
In the t-SQL terms, we saw semijoin returns data from Table A that is available in Table B.
|
1 |
SELECT * FROM TableA WHERE A.ID IN (SELECT B.ID FROM TableB) |
The anti-semijoin, return data from Table A that is not available in table B. Similar to the semijoin, it has two variants left anti-semijoin (antisemijoin keyword) and right anti-semijoin.
|
1 |
SELECT * FROM TableA WHERE A.ID <strong>NOT</strong> IN (SELECT B.ID FROM TableB) |
The below query performs Left anti-semijoin between the @Product and @category row variable:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
@Product = SELECT * FROM (VALUES ("Laptop", (int?) 1) , ("Keyboard", (int?) 1) , ("Cream", (int?) 2) , ("Ring", (int?) null)) AS P(ProductName, ProductID); @Category = SELECT * FROM (VALUES ((int) 1, "Electronics") , ((int) 2, "Consumer items")) AS C(ProductID, CategoryName); @output = SELECT pe.ProductName, pe.ProductID FROM @Product AS pe LEFT ANTISEMIJOIN (SELECT (int?) ProductID AS ProductID , CategoryName AS CategoryName FROM @Category) AS ce ON pe.ProductID == ce.ProductID; OUTPUT @output TO "/Input/First/Semijoin.csv" USING Outputters.Csv(); |
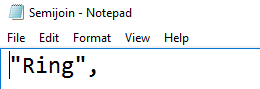
It returns the row from the @Product variable that is not available in the @Category variable. It returns the unmatched row – Ring as shown below.
Joins using Rowsets and Azure Data Lake Analytics tables
In the previous examples, we joined two tables in the ADLA database. Suppose you have another data in the CSV file, and you want to join it with the ADLA database tables. You do not require a predefined schema, the table in the U-SQL script. You can use the row set variable and join it directly with the table.
For example, in the below script, we do the following tasks.
- Extract data into @employee rowset variable from the CSV file stored locally
- Join the @employee rowset variable with the [Lab].[Departments] table
- Apply transformation and save the join query output in a TSV format
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
USE DATABASE ADLADemoDB; USE SCHEMA [Lab]; @employee = EXTRACT [id] int, [Username] string, [FirstName] string, [LastName] string, [DepartID] int FROM "/Input/First/employee.csv" USING Extractors.Csv(); @output = SELECT E1.Username, E1.FirstName, E1.LastName, D1.Departname FROM @employee AS E1 INNER JOIN Lab.Departments AS D1 ON D1.DepartID == E1.DepartID; OUTPUT @output TO "/Input/First/SQLJOIN1.Tsv" USING Outputters.Tsv(); |
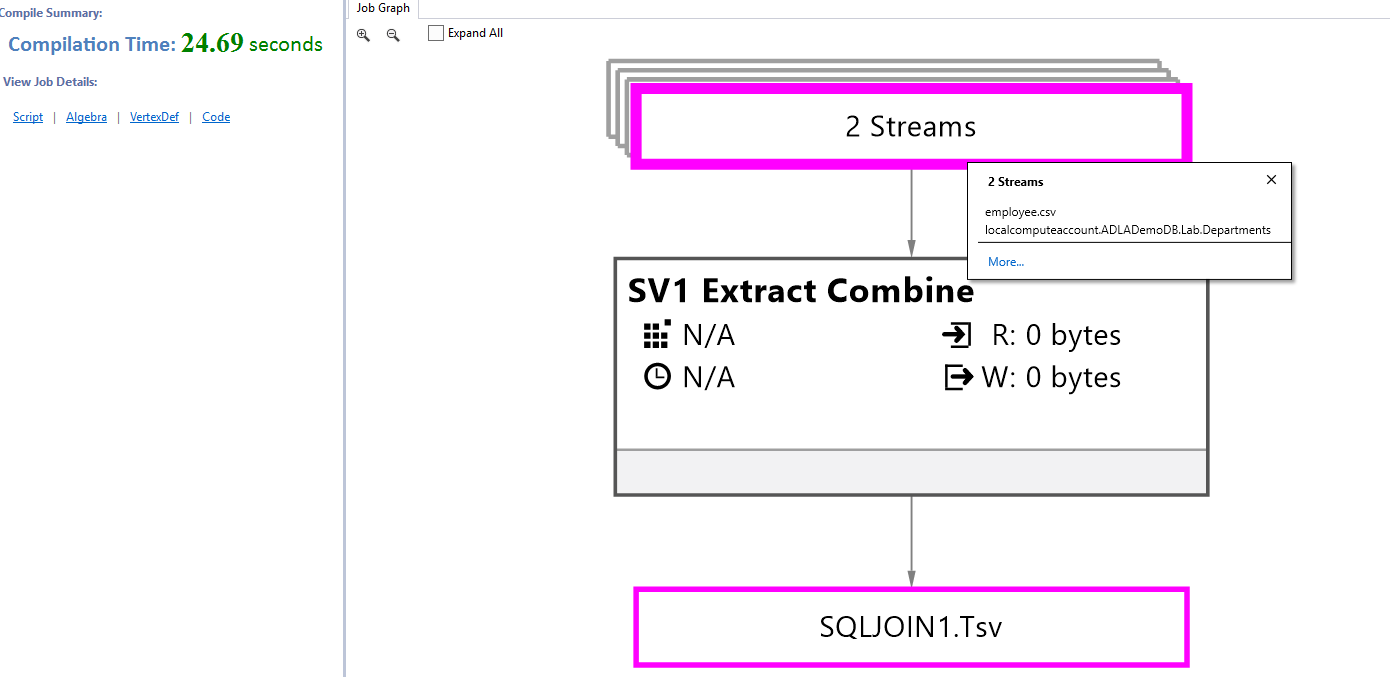
In the job graph, you can validate the two input data streams.
- employee.csv file
- Database table [Lab].[Departments]
Output data stored in the SQLJoin1.TSV format
Alternatively, you can write the EXTRACT statement directly in the FROM clause. For example, previously, we extract data into the row variable @employee and then used it in the JOIN clause.
Now, in the below script, we did not use the row variable and directly used the EXTRACT statement in the FROM clause.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
USE DATABASE ADLADemoDB; USE SCHEMA [Lab]; @output = SELECT E1.Username, E1.FirstName, E1.LastName, D1.Departname FROM (EXTRACT [id] int, [Username] string, [FirstName] string, [LastName] string, [DepartID] int FROM "/Input/First/employee.csv" USING Extractors.Csv()) AS E1 INNER JOIN Lab.Departments AS D1 ON D1.DepartID == E1.DepartID; OUTPUT @output TO "/Input/First/SQLJOIN1.Tsv" USING Outputters.Tsv(); |
Conclusion
In this article, we performed a U-SQL script join between Azure Data Lake Analytics tables, rowset variables. The query syntax for joins looks similar to T-SQL SQL Server joins. Therefore, you can quickly learn these joins and apply them data extraction, transformations for ADLA.
Table of contents
| An overview of Azure Data Lake Analytics and U-SQL |
| Writing U-SQL scripts using Visual Studio for Azure Data Lake Analytics |
| Deploy Azure Data Lake Analytics database using the U-SQL scripts |
| Join database tables using U-SQL scripts for Azure Data Lake Analytics |

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023