
In this article, I am going to introduce AWS Athena, a service offered by Amazon which allows users to query data from S3 using standard SQL syntax. AWS is considered to be a leader in the cloud computing world. Almost more than a hundred services are being offered by Amazon which offers competitive performance and cost-effective solutions to run workloads as compared to on-premise architectures. The services offered by Amazon range widely from compute, storage, databases, analytics, IoT, security, and a lot more. One of the popular areas of these services in the Analytics domain. This allows the customer to build architectures that answer key questions to their business decisions.
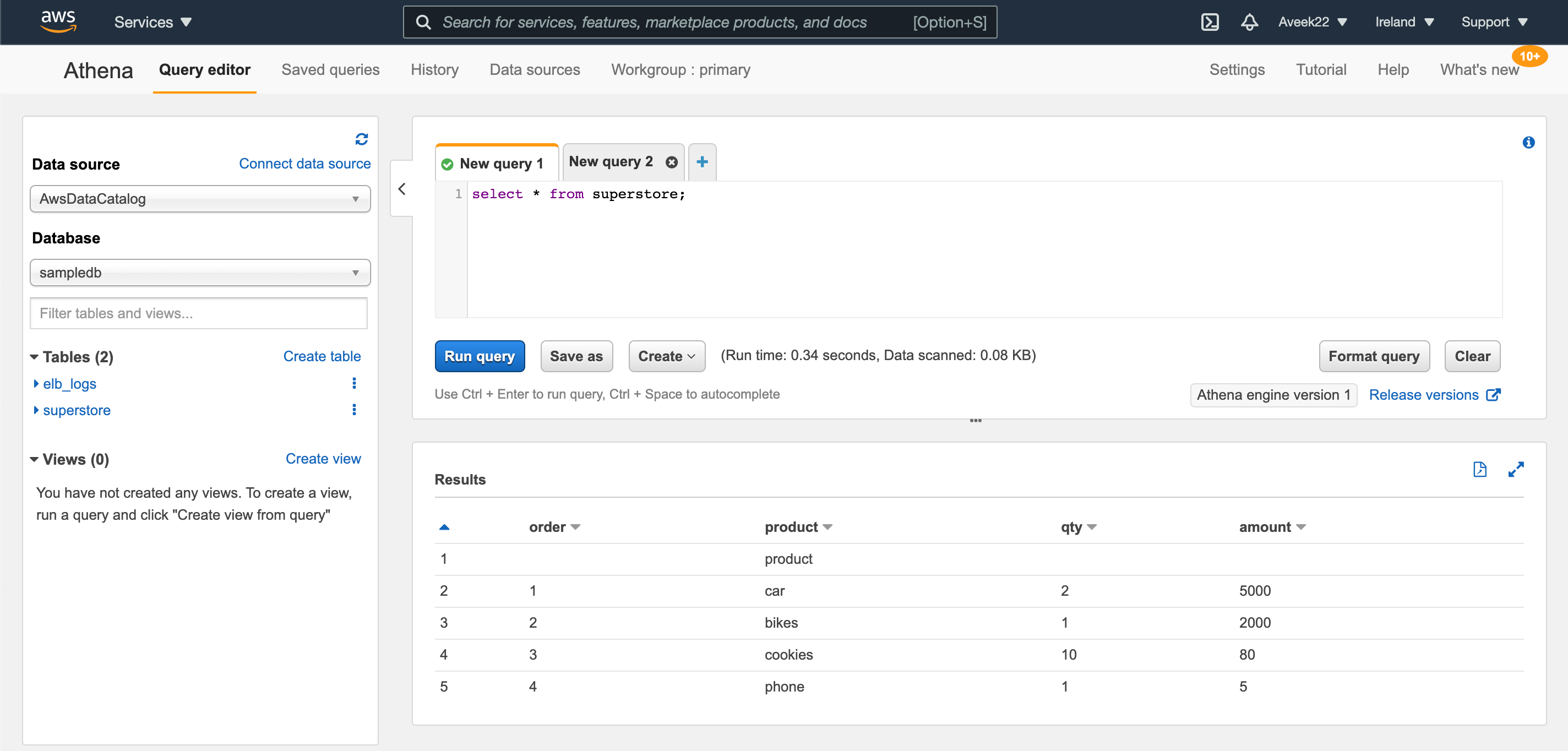
Figure 1 – Amazon Athena Query Editor
This article talks about AWS Athena, a service from the analytics domain of Amazon that focuses on the retrieval of static data stored in S3 buckets using standard SQL statements. It is a robust tool that can help customers quickly gain insights on their data stored on S3 as this is serverless and there is no infrastructure to manage.
What is AWS Athena
AWS Athena is a serverless interactive analytics service offered by Amazon that can be readily used to gain insights on data residing in S3. Under to hood, Athena used a distributed SQL engine called Presto, which is used to run the SQL queries. Presto is based on the popular open-source technology Hive, to store structured, semi-structured and unstructured data. By the official definition of Apache Hive – “The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL”. You can read more about Apache Hive and Presto from the official documentation.
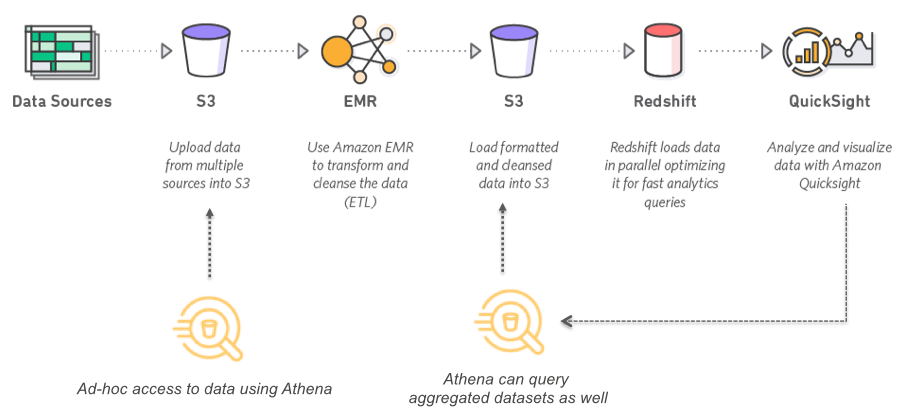
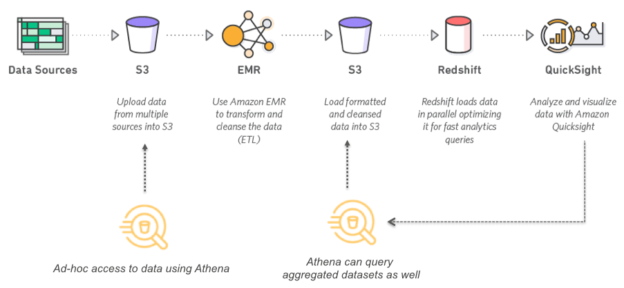
Figure 2 – Amazon Athena use case (Source)
As you can see in the figure above, it represents a simple data pipeline in which data from various multiple sources are being fetched and dumped into S3 buckets. These are raw data which means there are no transformations applied to the data yet. At this stage, you can use Amazon Athena to connect to these data in S3 and start analyzing them. This is a very simple process as you do not need to set up any database or external tools to query the raw data. Once you are done with your analysis and you have found out your desired results, you can use an EMR cluster to run your complex analytical data transformations, and clean and process your raw data, and then store it back to S3.
At this stage, you can again use Amazon Athena to query your processed data for further analysis. An important point worth mentioning here is that Amazon QuickSight can directly be used to connect to Athena and create stunning visuals of your data which resides on S3. Alternatively, you can also move your data to Redshift, which is an MPP Data warehouse for fast data analysis and then visualize your data from Redshift using QuickSight.
How AWS Athena is priced
Amazon Athena is a serverless data query tool which means it is scalable and cost-effective at the same time. Usually, customers are charged on a pay per query basis which translates to the number of queries that are executed on a given time period. The normal charge for scanning 1TB of data from S3 is 5 USD. Although it looks quite a small amount at a first glance, when you have multiple queries running on hundreds and thousands of GB of data, the price might get out of control at times. In the later part of this article, I am going to talk about some optimization techniques that will save us some costs while using Amazon Athena.
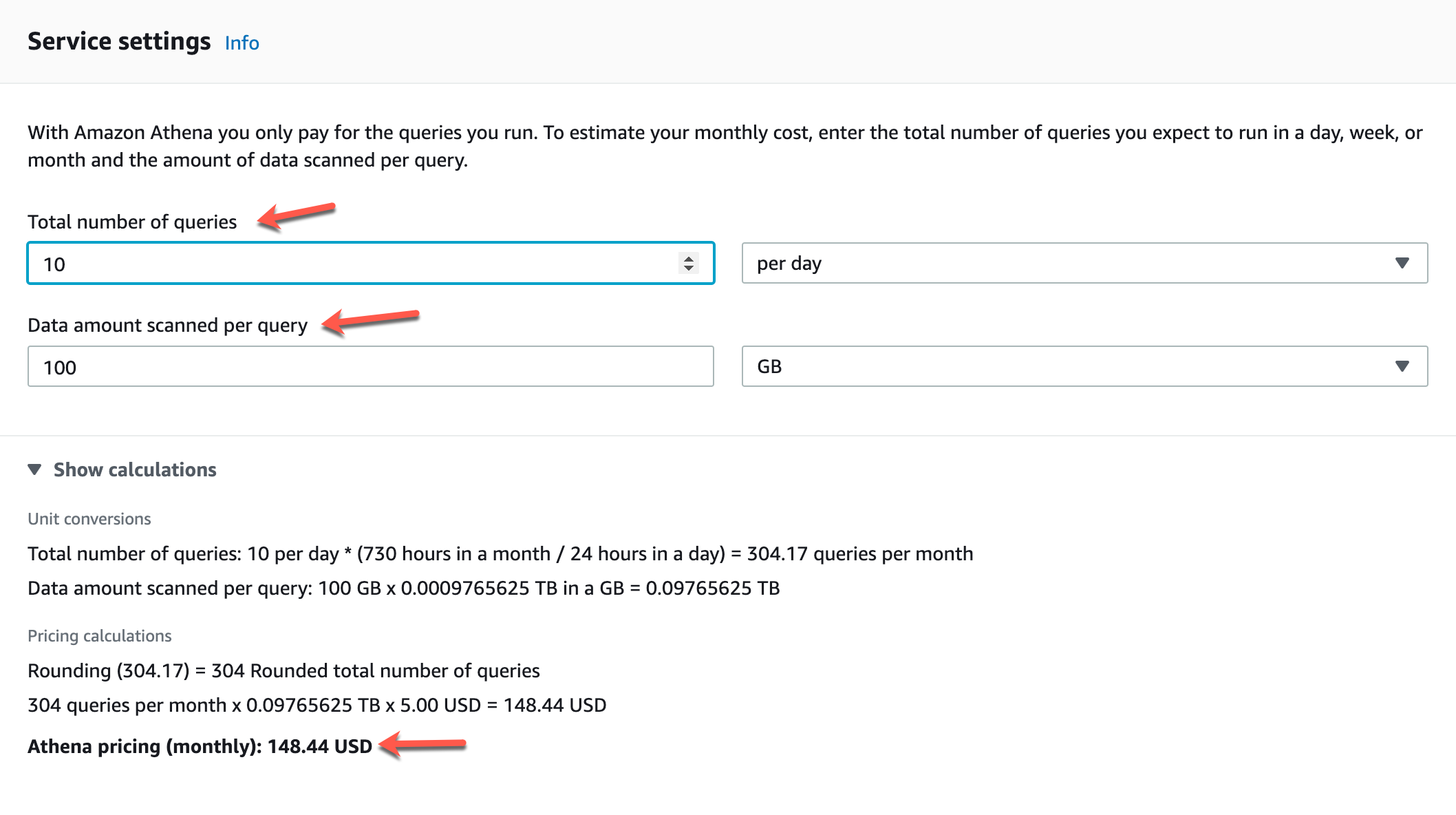
Figure 3 – AWS Athena Pricing Calculator (Source)
You can understand the pricing model of AWS Athena by using the calculator available on the official website. Let us assume that a customer has approximately 100 GB of data stored on S3 in plain CSV files. We have configured AWS Athena to query this data daily and run around 10 queries on an average to yield the analyses. This translates to roughly approximately 304 queries executed each month. Since the default pricing is based on per TB of data, we need to calculate the pricing based on GB.
So, the final calculation comes out to be somewhere around 150 USD approximately per month to query 100 GB of data, daily if 10 queries are executed on an average.
Optimization Techniques for AWS Athena
When working with cloud services, we need to take care of the services that we use the least possible resources and yield the best results out in a cost-effective manner. There are several measures that we can take in order to optimize our queries within AWS Athena so that we can boost our performance as well as keep the cost in check. I will discuss a few of the optimization techniques below.
Partitioning your data in S3
This is one of the most common practices being followed to store data in S3. Partitioning can be done by creating separate directories based on major dimensions, mostly the date dimension or the region dimension. You can use it to partition by year, month and day and then store the files under each day’s directory. Alternatively, you can also partition by region, where you can store data for similar regions under one directory.
Partitioning helps Athena to scan less amount of data per query and hence is both faster and cost-effective.
Using data compression techniques
When you compress your data, it needs a CPU to compress and decompress it back while querying. Although there are many compressing techniques available, the most popular ones to use with Athena are Apache Parquet or Apache ORC. These techniques compress the data by using the default algorithms for columnar databases and as such are splittable.
Optimize JOIN conditions in queries
While querying data across multiple dimensions, it is often required to join data from two different tables to perform the analysis. While joining looks like a very simple process, the actual way the processing takes place is quite complex. It is always recommended to keep the tables with larger data on the left and with less data on the right. In this way, the data processing engine, Presto, distributes the smaller table on the right to the worker nodes and then data from the left table is streamed to perform the join between the two.
Use selected columns in your query
This is another important yet mandatory optimization technique that significantly reduces the amount of time and memory that is taken by Athena to run queries. It is advised that we should explicitly mention the name of the columns on which we are performing the analysis in the select query rather than specifying a select * from table_name.
Optimize the pattern matching technique in your query
Many times, it is required to query data based on some pattern in the data, rather than a specific keyword. In SQL, an easy way to implement this is by using the LIKE operator where you can mention the pattern and the query will fetch you the data which matches the pattern. In Athena, you should use REGEX to match patterns instead of the LIKE operator as it is much faster.
Conclusion
In this article, we have understood the benefits of using cloud computing tools like AWS Athena and the underlying concepts of using the tool. Athena is serverless which means it is easily scalable depending on the load of the system. As a backend, Athena uses the open-source Presto, a distributed SQL engine for querying and analyzing big data workloads. In my next article, I am going to explain in detail how to get started with Amazon Athena and start querying and analyzing your data stored in S3.

He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021