
This article serves as a complete guide to Azure Databricks for the beginners. Here, you will walk through the basics of Databricks in Azure, how to create it on the Azure portal and various components & internals related to it.
Systems are working with massive amounts of data in petabytes or even more and it is still growing at an exponential rate. Big data is present everywhere around us and comes in from different sources like social media sites, sales, customer data, transactional data, etc. And I firmly believe, this data holds its value only if we can process it both interactively and faster.
Apache Spark is an open-source, fast cluster computing system and a highly popular framework for big data analysis. This framework processes the data in parallel that helps to boost the performance. It is written in Scala, a high-level language, and also supports APIs for Python, SQL, Java and R.
Now the question is:
What is Azure Databricks and how is it related to Spark?
Simply put, Databricks is the implementation of Apache Spark on Azure. With fully managed Spark clusters, it is used to process large workloads of data and also helps in data engineering, data exploring and also visualizing data using Machine learning.
While I was working on databricks, I find this analytic platform to be extremely developer-friendly and flexible with ease to use APIs like Python, R, etc. To explain this a little more, say you have created a data frame in Python, with Azure Databricks, you can load this data into a temporary view and can use Scala, R or SQL with a pointer referring to this temporary view. This allows you to code in multiple languages in the same notebook. This was just one of the cool features of it.
Why Azure Databricks?
Evidently, the adoption of Databricks is gaining importance and relevance in a big data world for a couple of reasons. Apart from multiple language support, this service allows us to integrate easily with many Azure services like Blob Storage, Data Lake Store, SQL Database and BI tools like Power BI, Tableau, etc. It is a great collaborative platform letting data professionals share clusters and workspaces, which leads to higher productivity.
Outline
Before we get started digging Databricks in Azure, I would like to take a minute here to describe how this article series is going to be structured. I intend to cover the following aspects of Databricks in Azure in this series. Please note – this outline may vary here and there when I actually start writing on them.
- How to access Azure Blob Storage from Azure Databricks
- Processing and exploring data in Azure Databricks
- Connecting Azure SQL Databases with Azure Databricks
- Load data into Azure SQL Data Warehouse using Azure Databricks
- Integrating Azure Databricks with Power BI
- Run an Azure Databricks Notebook in Azure Data Factory and many more…
In this article, we will talk about the components of Databricks in Azure and will create a Databricks service in the Azure portal. Moving further, we will create a Spark cluster in this service, followed by the creation of a notebook in the Spark cluster.
The below screenshot is the diagram puts out by Microsoft to explain Databricks components on Azure:
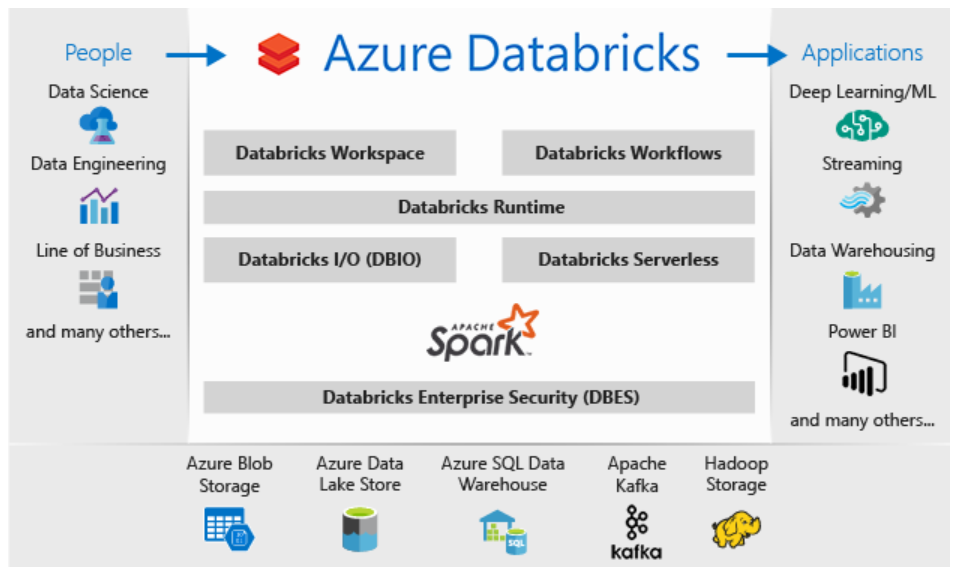
There are a few features worth to mention here:
- Databricks Workspace – It offers an interactive workspace that enables data scientists, data engineers and businesses to collaborate and work closely together on notebooks and dashboards
- Databricks Runtime – Including Apache Spark, they are an additional set of components and updates that ensures improvements in terms of performance and security of big data workloads and analytics. These versions are released on a regular basis
- As mentioned earlier, it integrates deeply with other services like Azure services, Apache Kafka and Hadoop Storage and you can further publish the data into machine learning, stream analytics, Power BI, etc.
- Since it is a fully managed service, various resources like storage, virtual network, etc. are deployed to a locked resource group. You can also deploy this service in your own virtual network. We are going to see this later in the article
- Databricks File System (DBFS) – This is an abstraction layer on top of object storage. This allows you to mount storage objects like Azure Blob Storage that lets you access data as if they were on the local file system. I will be demonstrating this in detail in my next article in this series
Now that we have a theoretical understanding of Databricks and its features, let’s head over to the Azure portal and see it in action.
Create an Azure Databricks service
Like for any other resource on Azure, you would need an Azure subscription to create Databricks. In case you don’t have, you can go here to create one for free for yourself.
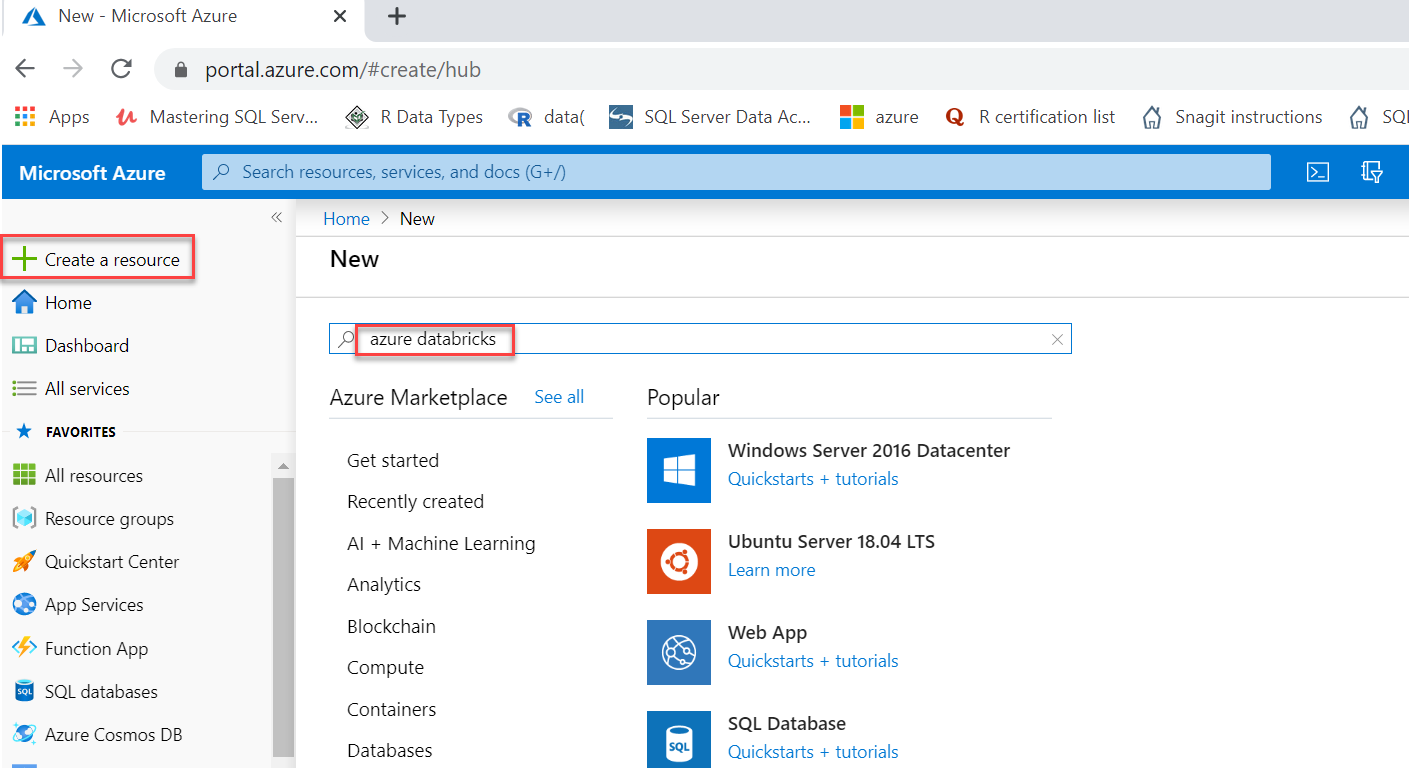
Sign in to the Azure portal and click on Create a resource and type databricks in the search box:
Click on the Create button, as shown below:
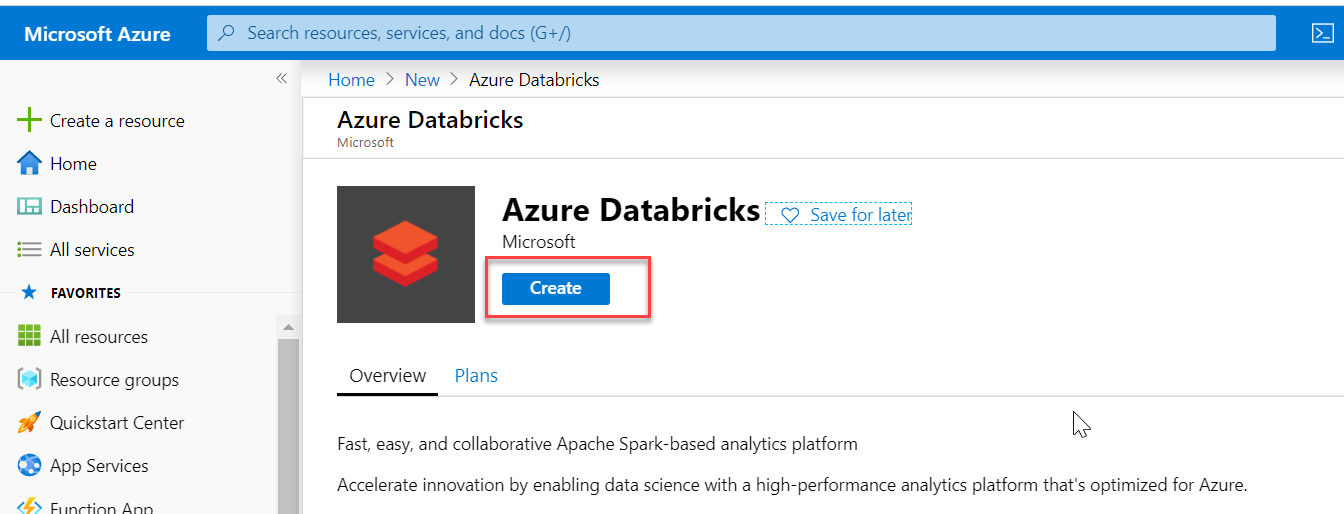
You will be brought to the following screen. Provide the following information:
- Subscription– Select your subscription
- Resource group – I am using the one I have already created (azsqlshackrg), you can create a new also for this
- Workspace name – It is the name (azdatabricks) that you want to give for your databricks service
- Location – Select region where you want to deploy your databricks service, East US
- Pricing Tier – I am selecting Premium – 14 Days Free DBUs for this demo. To learn about more details on Standard and Premium tiers, click here
Afterward, hit on the Review + Create button to review the values submitted and finally click on the Create button to create this service:
Once it is created, click on “Go to resource” option in the notification tab to open the service that you have just created:
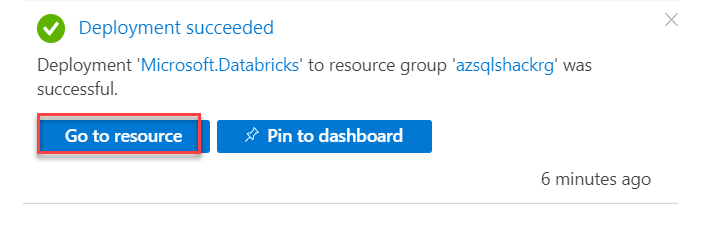
You can see several specifics like URL, pricing details, etc. about your databricks service on the portal.
Click on Launch Workspace to open the Azure Databricks portal; this is where we will be creating a cluster:
You will be asked to sign-in again to launch Databricks Workspace.
The following screenshot shows the Databricks home page on the Databricks portal. On the Workspace tab, you can create notebooks and manage your documents. The Data tab below lets you create tables and databases. You can also work with various data sources like Cassandra, Kafka, Azure Blob Storage, etc. Click on Clusters in the vertical list of options:
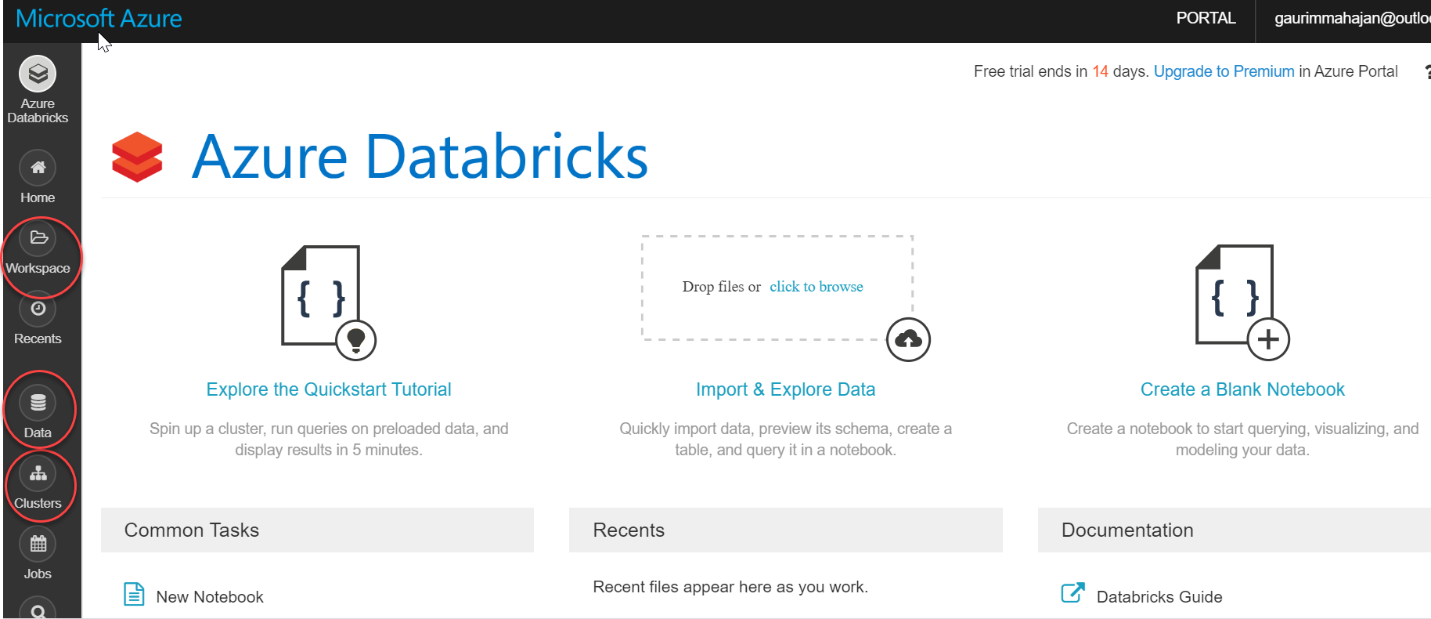
Create a Spark cluster in Azure DatabricksClusters in databricks on Azure are built in a fully managed Apache spark environment; you can auto-scale up or down based on business needs. Click on Create Cluster below on the Clusters page:
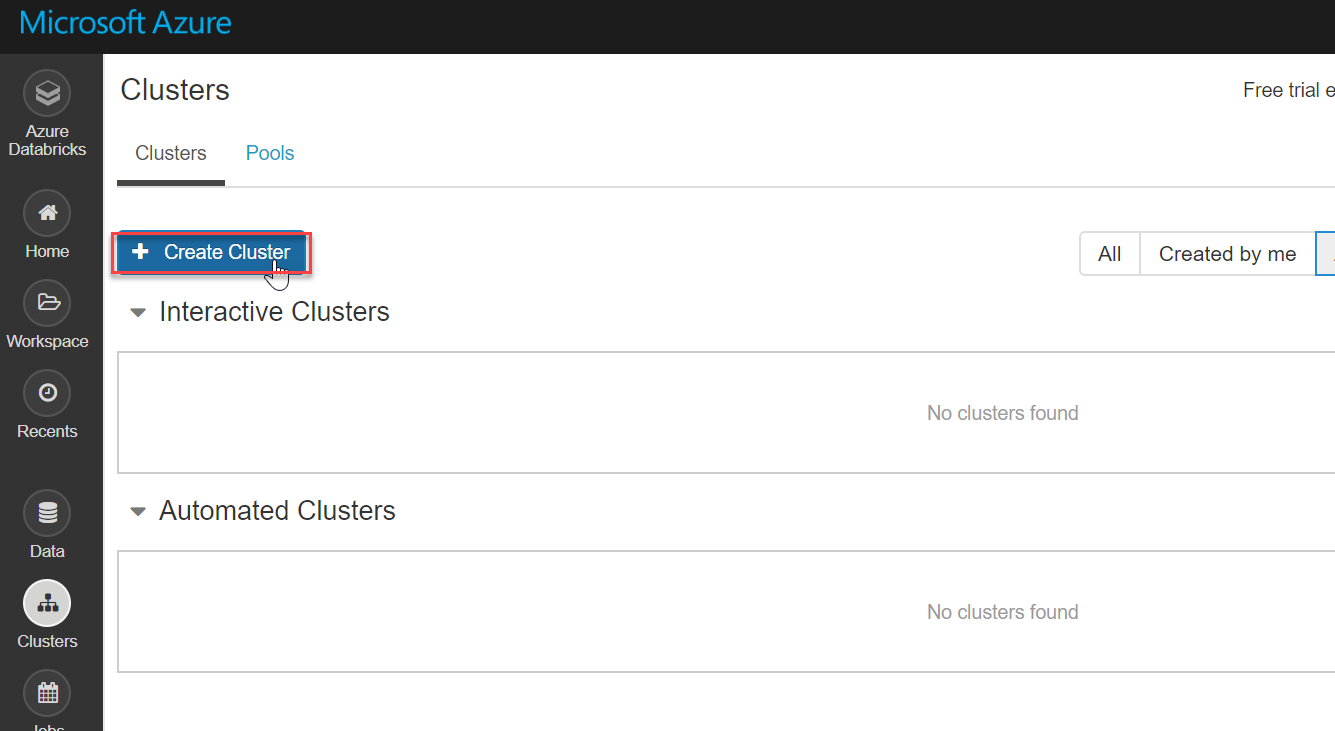
The following screenshot shows several configuration options to create a new databricks cluster. I am creating a cluster with 5.5 runtime (a data processing engine), Python 2 version and configured Standard_F4s series (which is good for low workloads). Since it is a demonstration, I am not enabling auto-scaling and also enabling the option to terminate this cluster if it is idle for 120 mins.
Finally, spin it up with a click on the Create Cluster button on the New Cluster page:
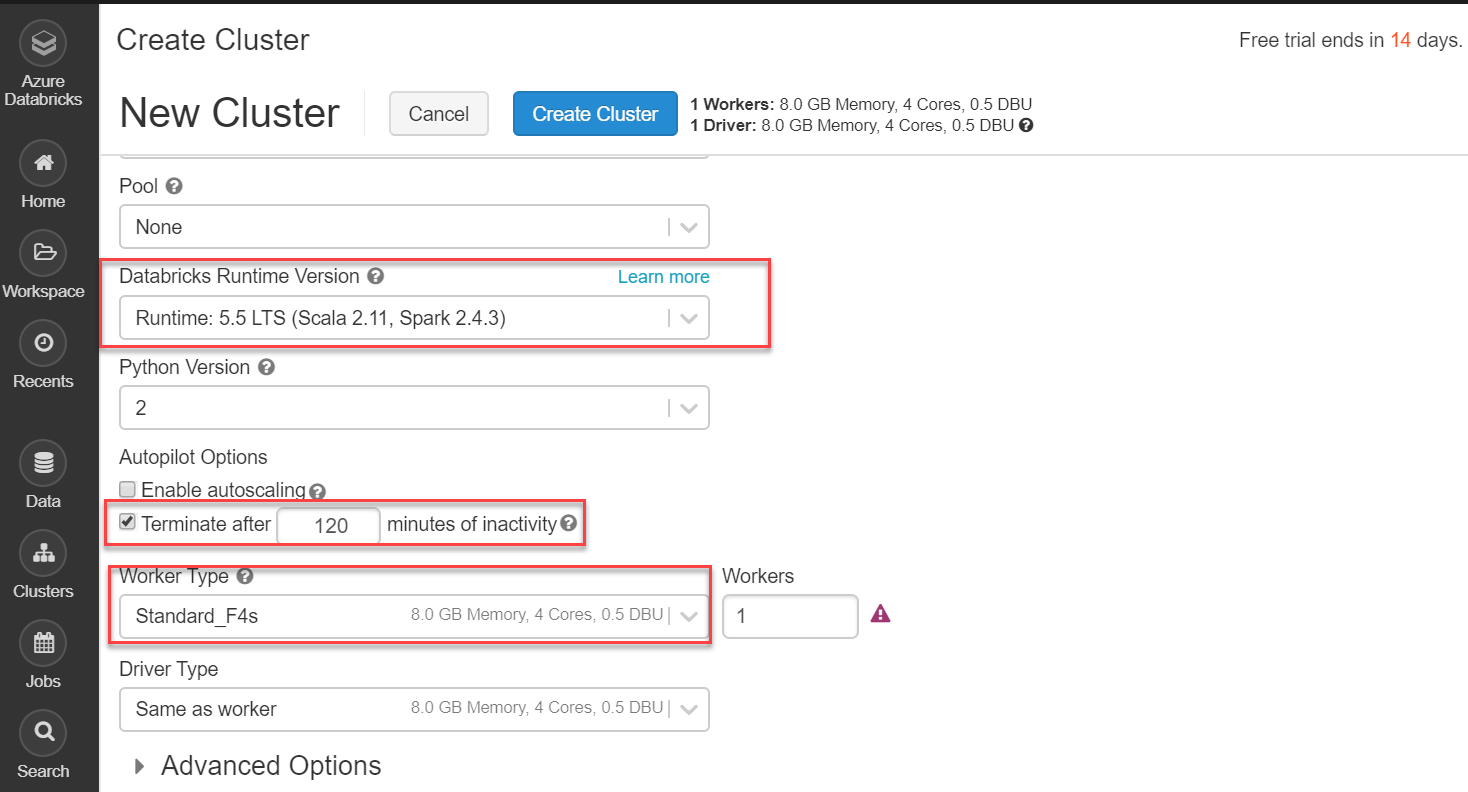
Basically, you can configure your cluster as you like. Various cluster configurations, including Advanced Options, are described in great detail here on this Microsoft documentation page.
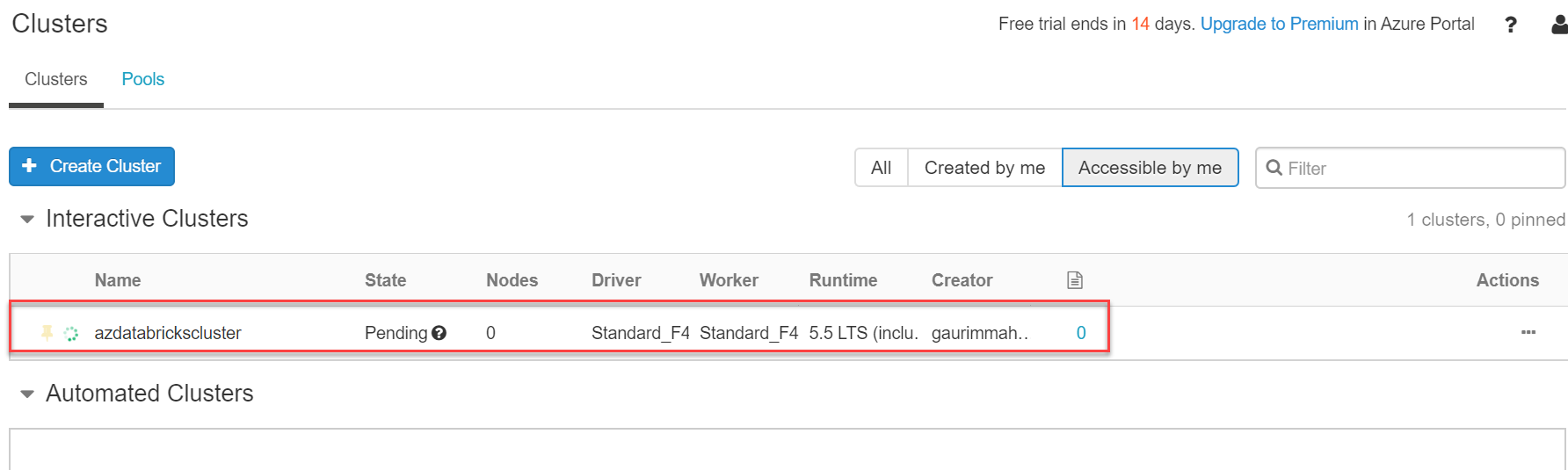
You can see the status of the cluster as Pending in the below screenshot. This will take some time to create a cluster:
Now our cluster is active and running:
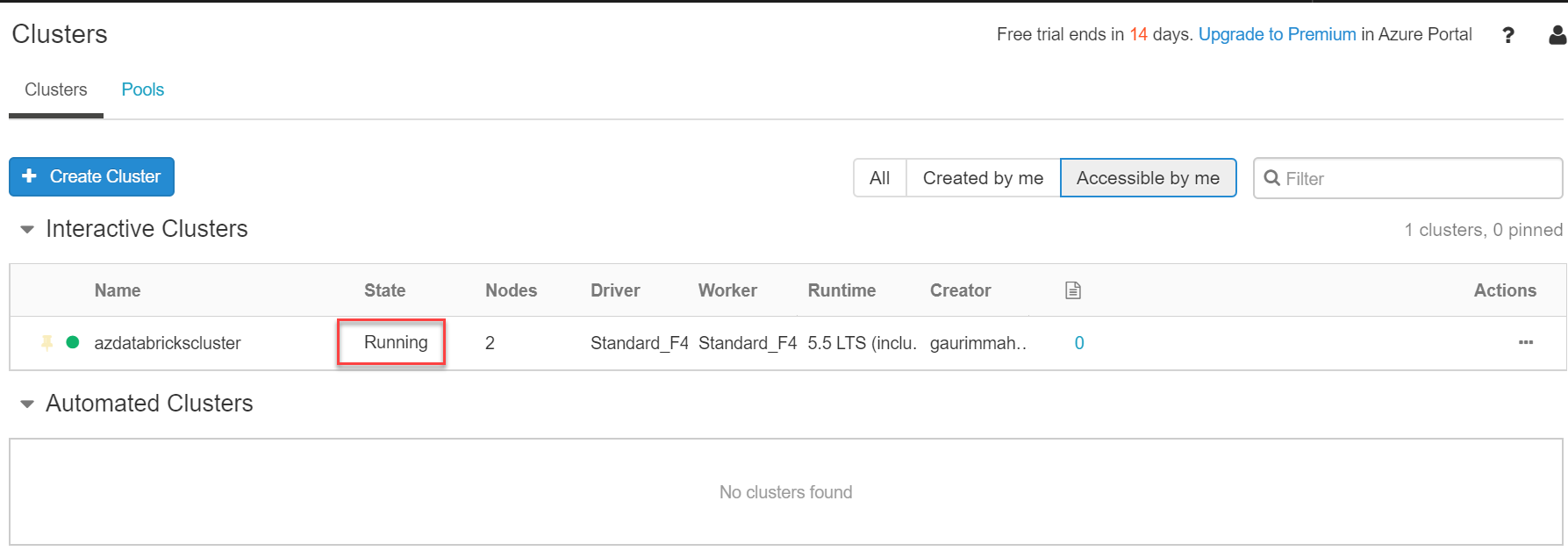
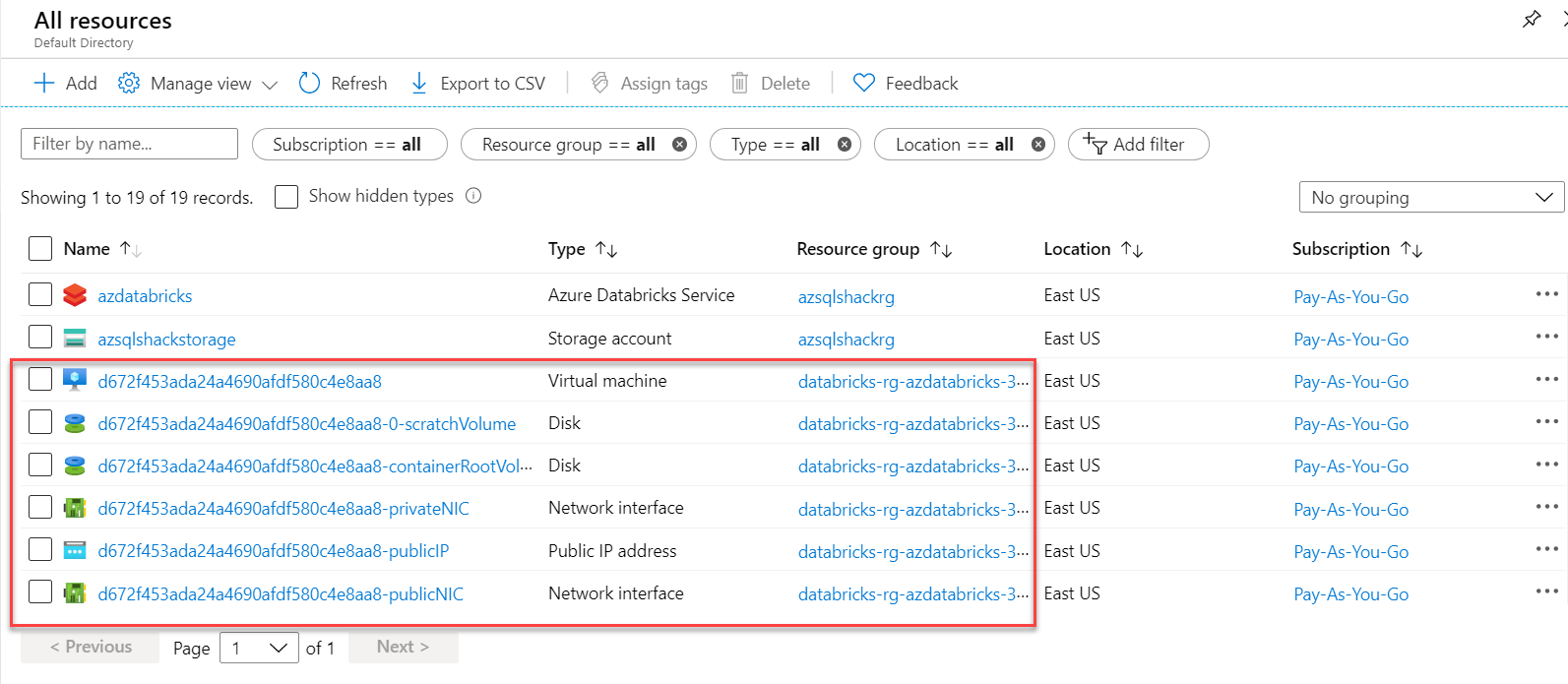
By default, Databricks is a fully managed service, meaning resources associated with the cluster are deployed to a locked resource group, databricks-rg-azdatabricks-3… as shown below. For the Databricks Service, azdatabricks, VM, Disk and other network-related services are created:
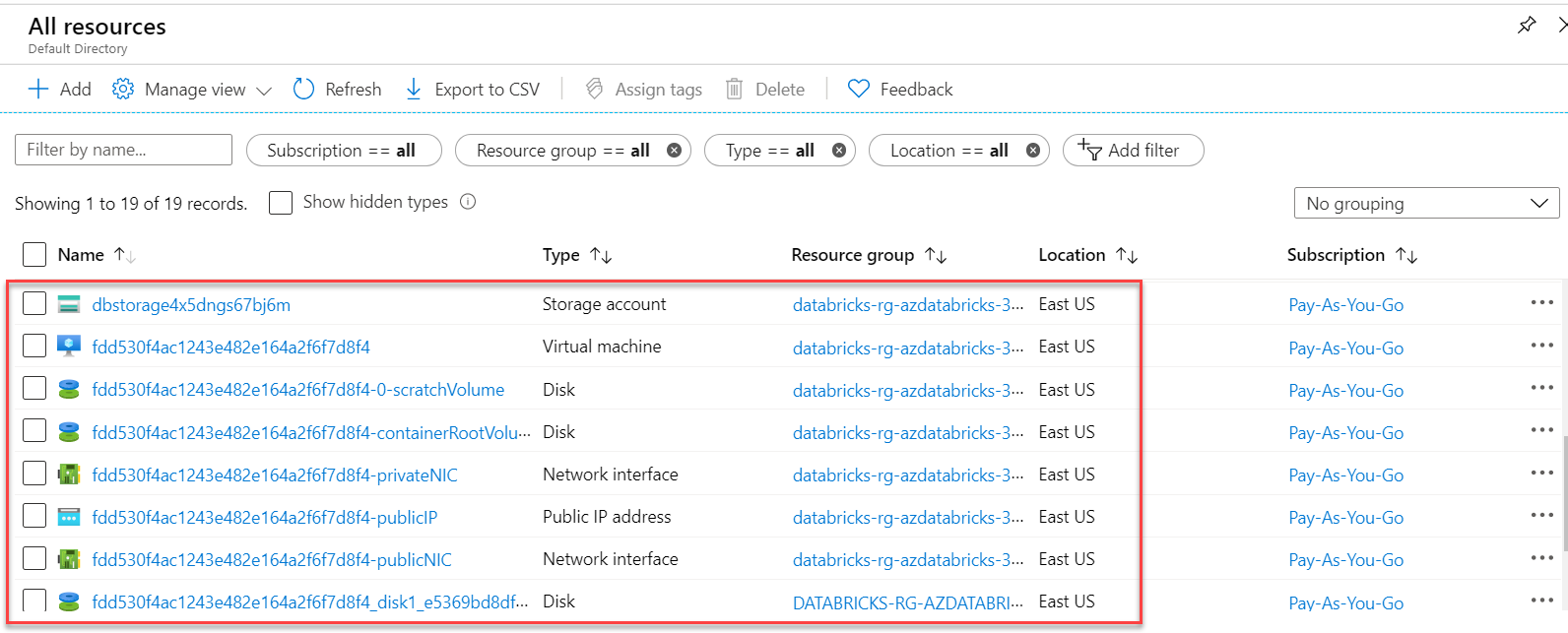
You can also notice that a dedicated Storage account is also deployed in the given Resource group:
Create a notebook in the Spark cluster
A notebook in the spark cluster is a web-based interface that lets you run code and visualizations using different languages.
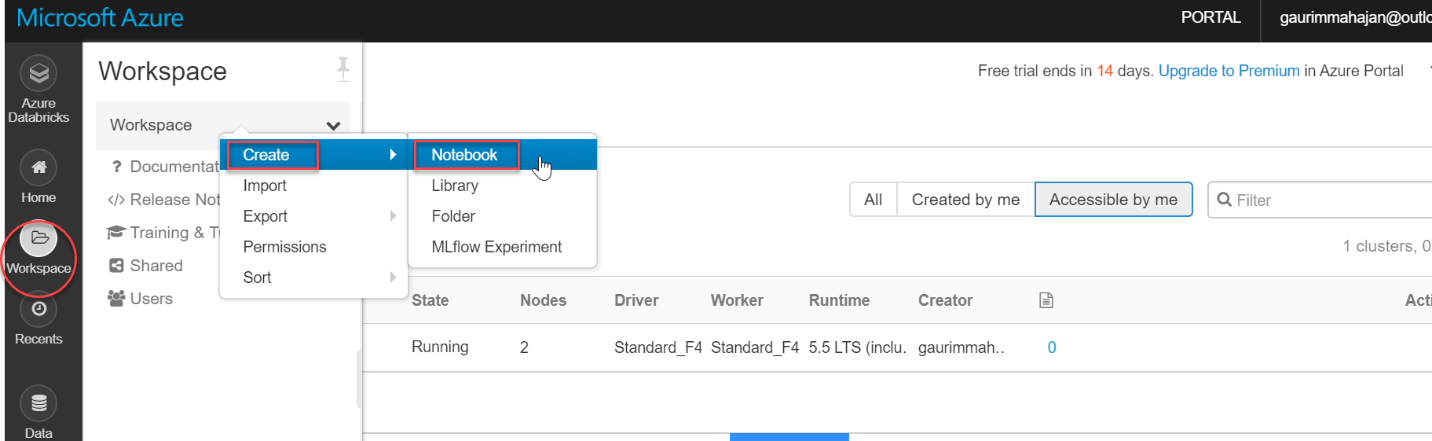
Once the cluster is up and running, you can create notebooks in it and also run Spark jobs. In the Workspace tab on the left vertical menu bar, click Create and select Notebook:
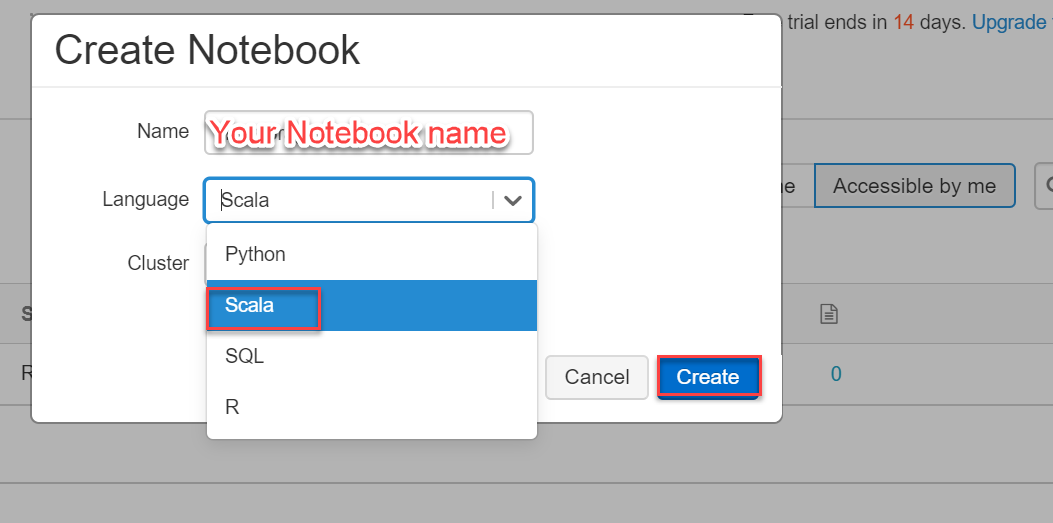
In the Create Notebook dialog box, provide Notebook name, select language (Python, Scala, SQL, R), the cluster name and hit the Create button. This will create a notebook in the Spark cluster created above:
Since we will be exploring different facets of Databricks Notebooks in my upcoming articles, I will put a stop to this post here.
Conclusion
I tried explaining the basics of Azure Databricks in the most comprehensible way here. We also covered how you can create Databricks using Azure Portal, followed by creating a cluster and a notebook in it. The intent of this article is to help beginners understand the fundamentals of Databricks in Azure. Stay tuned to Azure articles to dig in more about this powerful tool.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023