
SQL Server indexes are created to speed up the retrieval of data from the database table or view. The index contains one or more columns from your table. The structure of these keys are in the shape of B-tree distribution, enabling SQL Server to find the data quickly.
You need to balance between the data retrieval and the data update when trying to create the suitable index. Indexes with fewer number of columns in the index key, will require less disk space and also less maintenance overhead. Covering index, on the other hand, serve more queries. It is better to test many scenarios and workloads before choosing the efficient index.
There are two main types of indexes in SQL server; Clustered and non-clustered indexes. The clustered index controls the sort of the data pages in the disk, including all the columns in the table, although the index is created by one column only. The non-clustered index does not specify the real data order.
SQL Server Indexes can be categorized also to other types, such as the composite index; which is an index that contains more than one column. Unique index; which ensures the uniqueness of each value in the indexed column or columns as a whole. The last type is the covering index which contains all columns needed for a specific query.
How could we overcome the non-clustered index design limitations?
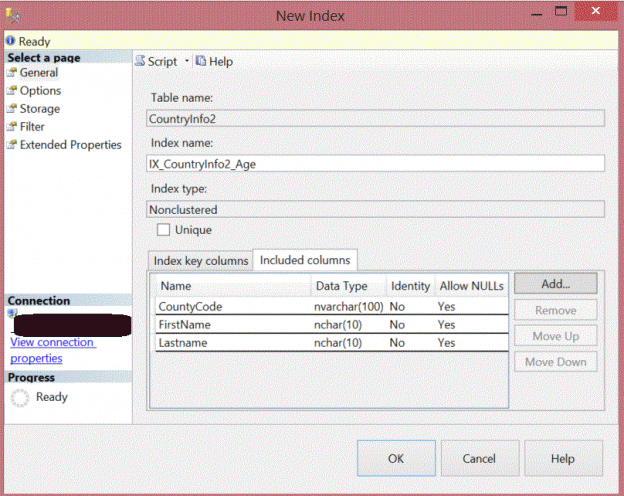
Non-Clustered index is created by adding key columns that are restricted in the number, type and size of these columns. To overcome these restrictions in the index keys, you could add a non-key columns when creating a non-clustered index, which are the Included Columns. The Included columns option is only available to the non-clustered index and not available to the clustered indexes.
A column cannot be involved as key and non-key in the same index. It is either a key column or a non-key, included column. The main difference between the key and non-key columns is in the way it is stored in the index. The key column stored in all the levels of the index B-tree structure, where the non-key column stored in the leaf level of the B-tree structure only.
Data Type
Included columns can be varchar (max), nvarchar(max) , varbinary(max) or XML data types, that you cannot add it as index keys. Computed columns can also be used as included columns.
You should take into consideration that adding these large data types as non-key columns will increase the disk space requirements, as the column values will be copied into the index leaf level in addition to the table or clustered index.
On the other hand, you still can’t use TEXT, NTEXT and IMAGE as included columns.
Index Size
Included columns can’t exceed its size limit, which is 900 byte only for index keys. So, when designing your index with large index key size, only columns used for searching and lookups are key columns, and all other columns that cover the query are non-key columns. As a result, you have all columns needed to cover the query, at the same time, the index size is small.
Number of Columns
Non-clustered index can contain up to 16 index keys; where you are not restricted with this number in the included columns. But you should take into consideration that creating indexes using large number of keys is not commonly used or recommended. In SQL Server, you can include up-to 1023 columns per each non-clustered index. But you have to add minimum one key column to your non-clustered index in order to create it.
Covering Index
Indexes with included columns provide the greatest benefit when covering the query. This means that the index includes all columns referenced by your query, as you can add columns with data types, number or size not allowed as index key columns.
Performance gains are achieved as the query optimizer can locate all the column values within the index in fewer disk I/O operations; as the table or clustered index data is not accessed. However, having too many included columns may increase the time required to perform insert, update, or delete operations to your table.
Let’s have an example of creating a covering index with key and non-key columns and how this will enhance the query performance.
If we run the query below on the SQLShackDemo database, the execution plan generated using APEXSQL PLAN application will be like:
|
1 2 3 4 5 6 7 8 |
USE SQLShackDemo GO SELECT CountyCode, FirstName,Lastname,Age FROM CountryInfo2 WHERE Age >25; GO |
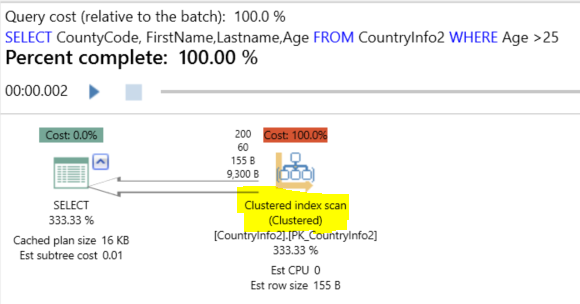
Index Scan means that the search will touch all rows in your table if needed or not, with cost proportional to the number of rows in your table. It is not a bad issue if you have a small table with few number of records.
On the other hand, the Index Seek indicates that the search will touch only the rows that meet a specific criteria, with the cost proportional to the number of rows in the table that meet that criteria, not the whole table rows.
To resolve the scan performance issue, we will creating non-clustered index on CountryInfo2 table to cover our query, by adding the predicate column in the WHERE clause as key column and the rest of columns that will be retrieved in the SELECT statement as non-key columns as below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_CountryInfo2_Age] ON [dbo].[CountryInfo2] ( [Age] ASC ) INCLUDE ( [CountyCode], [FirstName], [Lastname]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO |
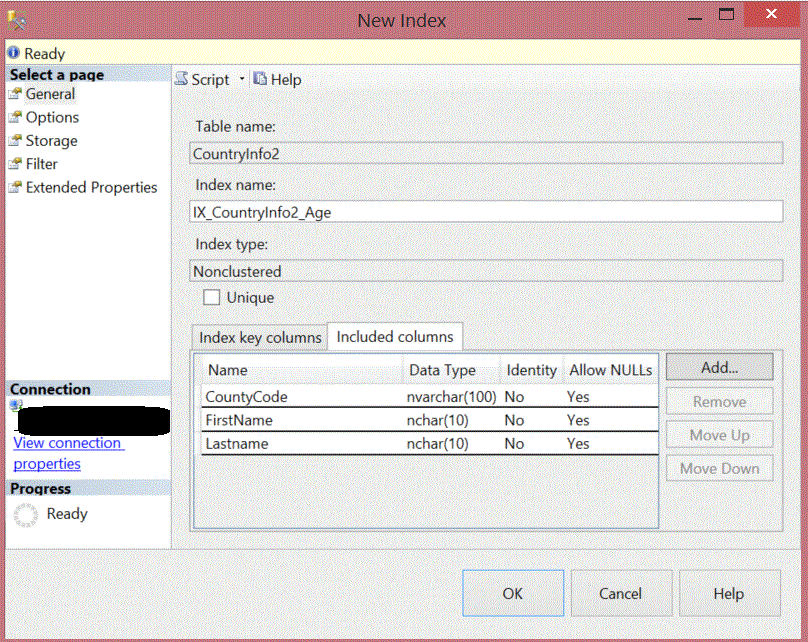
Adding included columns can also be done using the Management Studio from the New Index window. From this window, you can choose the key and non-key columns, also you can sort or remove it as below:
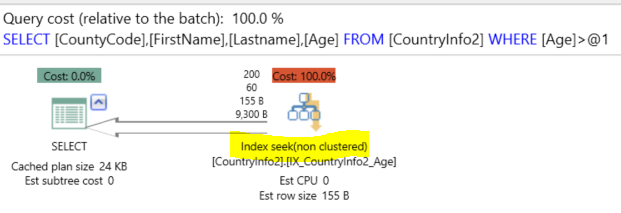
Try to run the same SELECT statement above, Index seek will be performed as all the data retrieved included in that index without touching the table or the clustered index as below:
Once the non-clustered index created, you can’t drop any index non-key column unless you drop the index first. Also these non-key columns can’t be changed except changing it from NOT NULL to NULL or increasing the length of varchar, nvarchar, or varbinary columns.
Badly designed SQL Server indexes or missing ones are the main cause of the slowness in most environments. Plan and study deeply, test many scenarios and finally decide which one is suitable for your situation. Review the index usage regularly in order to remove unused indexes and plan to add the missing ones

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021