
Introduction
Have you ever felt like pulling your hair out, trying to ascertain exactly which fields in your existing Reporting Services datasets are being utilized by your reports. This happened to me recently during a corporate conversion and cleanup exercise for a database migration to the cloud.
The “aha moment” came after having presented a paper at the PASS SQL Server Nordic Rally (March 2015), when one attendee came up to me and asked if I knew of a method to do this. As they say ‘necessity is the mother of invention’ and spiking my interest, I played around until I came up with the solution that we are going to chat about today. The end solution may be seen below
Let’s get started.
Getting Started
Management at SQL Shack Cars would like to know which fields in their database tables are NOT actively be utilized. The reason for this is that they wish to migrate the database to the cloud maintaining only those fields that are being used, in order to reduce the cost of pulling data from the cloud to their local data warehouse.
All the data that we are looking for resides within the Reporting Services database. The challenge that we have is that the data that we are looking for resides within the XML code of the reports themselves. This said, in order to isolate and extract the required data we have to integrate lines of code which are XML oriented.
As we shall be working with XML, we need to ensure that the necessary namespaces are present. The code below will ensure that our query has the necessary access to the required ‘libraries’. We shall be utilizing a Common Table Expression (CTE).
|
1 2 3 4 5 6 7 8 |
;WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/reporting/2008/01/reportdefinition' ,'http://schemas.microsoft.com/sqlserver/reporting/reportdesigner' AS rd) ,DEF AS |
With this knowledge, we begin with our inner most or ‘core query’
Our ‘core query’ runs against the catalog table within the Reporting Services database.
|
1 2 3 4 5 6 7 |
SELECT RPT.Path AS ReportPath ,RPT.name AS ReportName ,CONVERT(xml, CONVERT(varbinary(max), RPT.content)) AS contentXML FROM [ReportServer$STEVETOPMULTI].dbo.[Catalog] AS RPT WHERE RPT.Type = 2 -- 2 = A Report is Type 2 |
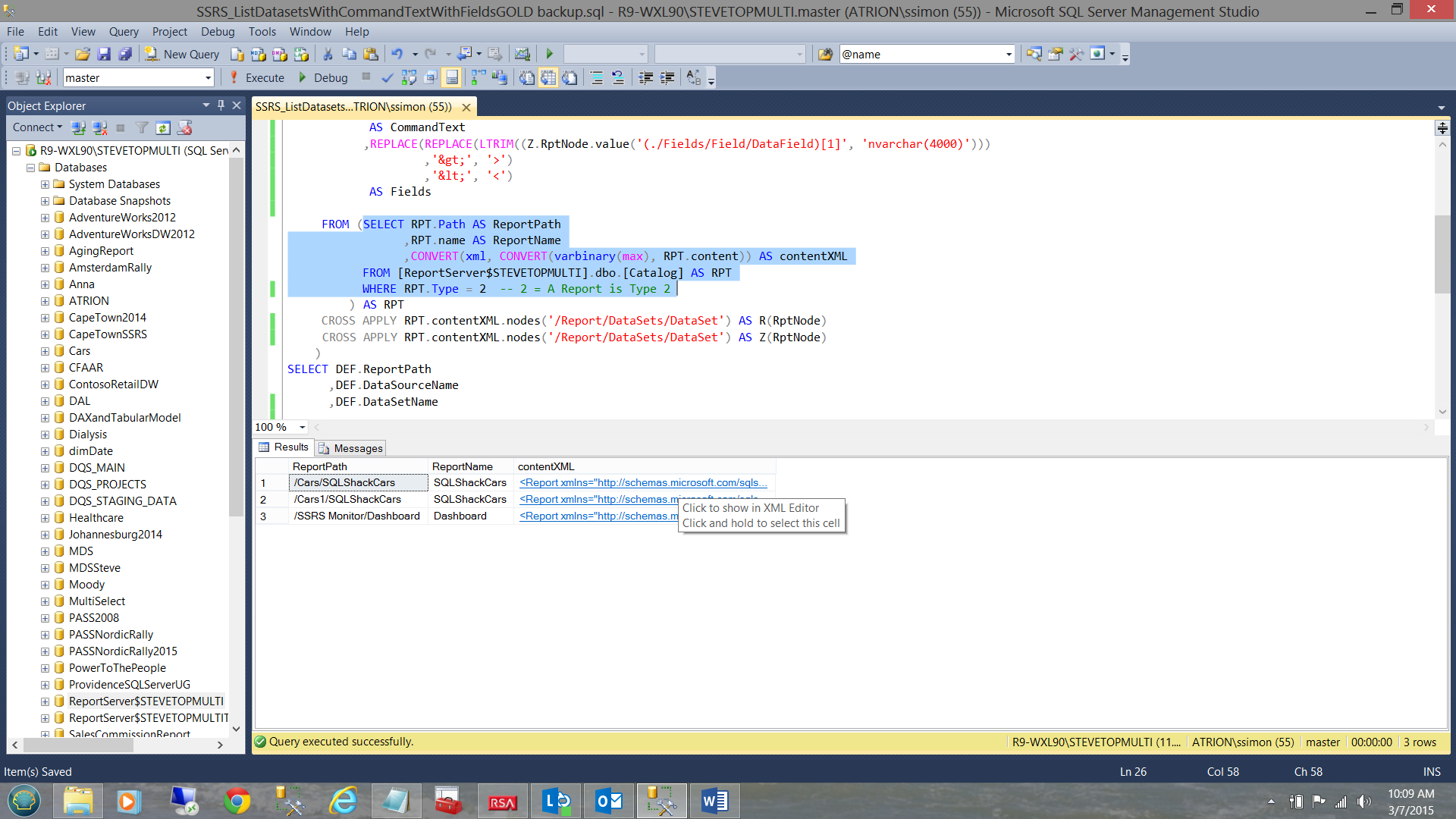
We note that the query renders the path of the report (i.e. where the report resides on disc and the name of the report. We note also that there is a third field (contentXML) which contains the data for which we are looking.
By double clicking on the XML value in the first row, the XML is exploded and shows the structure of the data (see below).
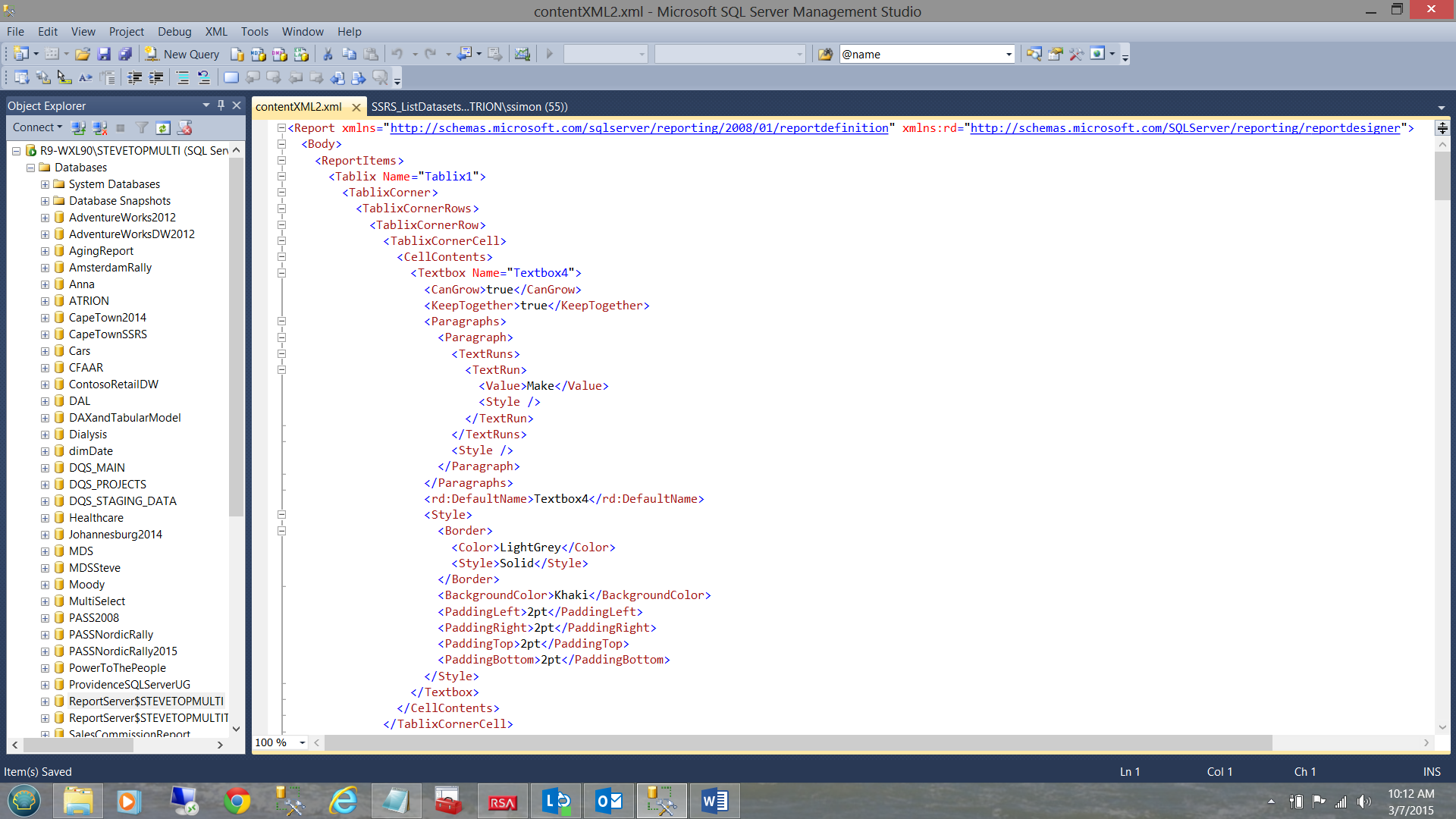
The trick is now to parse the tree and extract what we require. In order to understand what is transpiring, let us step through the lines of code to obtain a better understanding.
We first issue our select statement calling for the Report Path which was extracted directly from the catalog table.
|
1 2 3 |
(SELECT RPT.ReportPath |
We must now locate the Data Source Name(s) and Data Set Name(s).
We select the “Query/DataSourceName” branch off of the XML root choosing the first XML descendant on this branch. “Query/DataSourceName” subs off from “/Report/DataSets/DataSet” as
may be seen below. Thus the whole chain thus far is
| Root | Child |
“/Report/DataSets/DataSet/ Query/DataSourceName”.
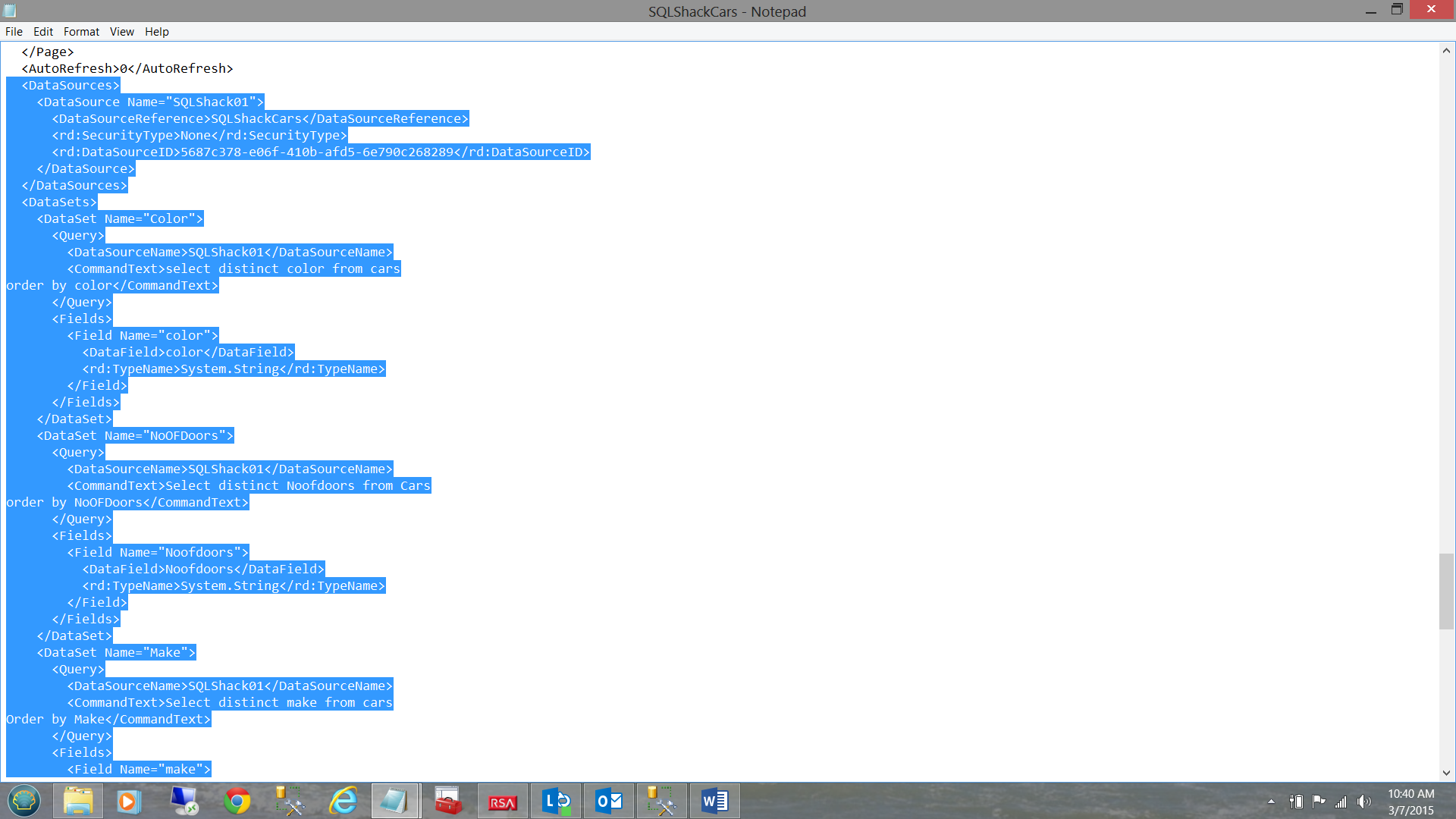
The code for this may be seen below:
|
1 2 3 4 |
,R.RptNode.value('(./Query/DataSourceName)[1]', 'nvarchar(425)') AS DataSourceName ,R.RptNode.value('@Name[1]', 'nvarchar(425)') AS DataSetName |
Next we wish to view the Query Command Text.
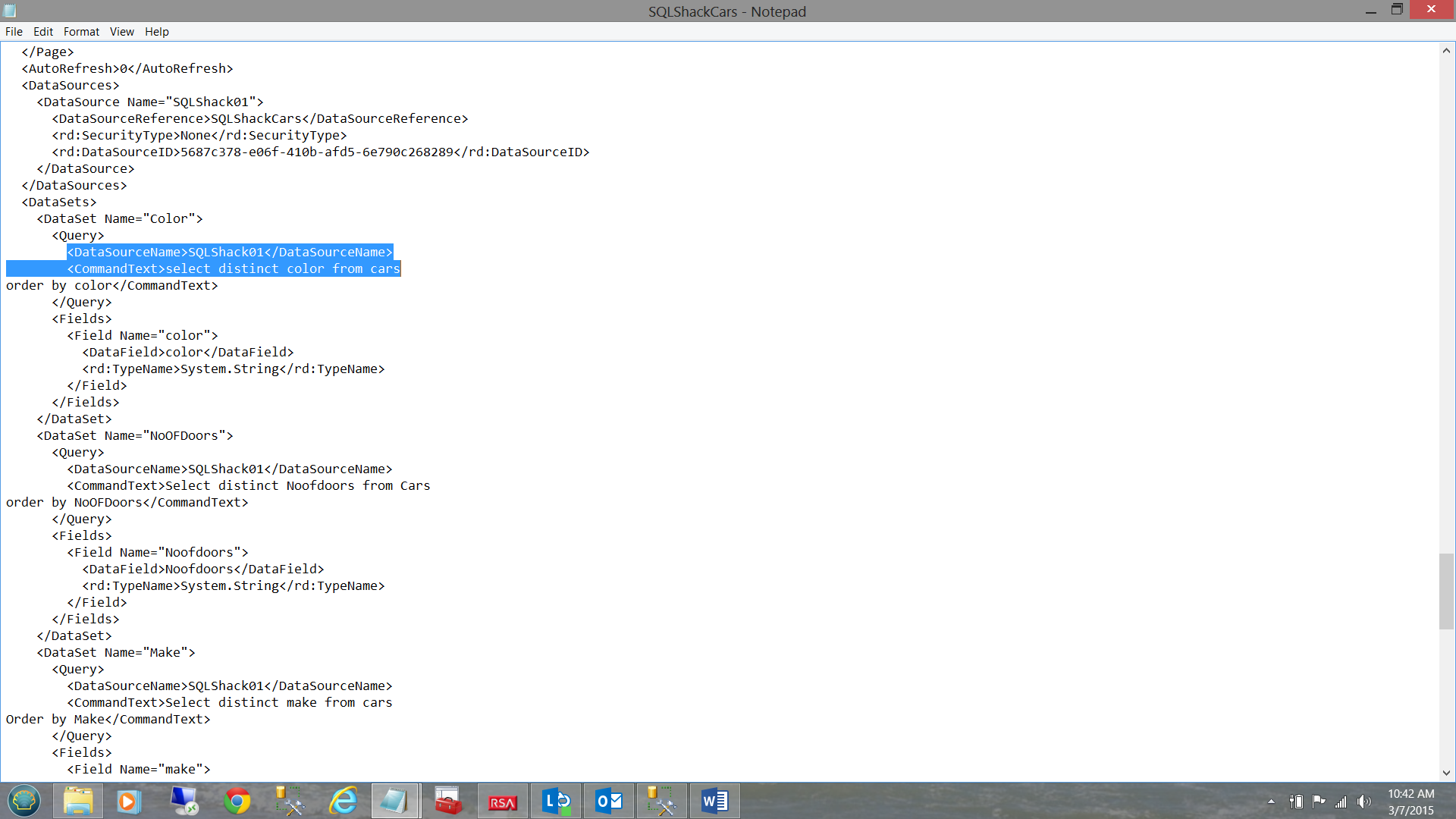
The astute reader will note that the command text falls under the <Query> element and the code to extract this field may be seen below:
|
1 2 3 4 5 6 7 |
,REPLACE(REPLACE(LTRIM((R.RptNode.value('(./Query/CommandText)[1]', 'nvarchar(4000)'))) ,'>', '>') ,'<', '<') AS CommandText |
This coded we are now in a position to extract the dataset field names. They are located on a different branch of the XML tree. The fields that we have identified thus far have been prefixed with an “R”. More on this when we discuss the CROSS APPLY in a few minutes. The CROSS APPLY links our current branch of the tree back from its “Dataset” to the root called “Report”. As we shall be discussing two distinctly different branches under ‘/Report/DataSets/DataSet’ we need to prefix them differently.
|
1 2 3 4 5 6 |
,REPLACE(REPLACE(LTRIM((Z.RptNode.value('(./Fields/Field/DataField)[1]', 'nvarchar(4000)'))) ,'>', '>') ,'<', '<') AS Fields |
Note that we prefix this branch with the letter “Z”. The relationship between the two branches and the parent branch may be seen below:

We have now reached the portion of our code where the sub query (that we discussed above) is located. To refresh our memory this is the query that showed us the report path (see below).
|
1 2 3 4 5 6 7 8 9 |
FROM (SELECT RPT.Path AS ReportPath ,RPT.name AS ReportName ,CONVERT(xml, CONVERT(varbinary(max), RPT.content)) AS contentXML FROM [ReportServer$STEVETOPMULTI].dbo.[Catalog] AS RPT WHERE RPT.Type = 2 -- 2 = A Report is Type 2 ) AS RPT |
As we discussed above, we need some way to link our children to the mother path. This is where the CROSS APPLY comes in (see below). Note that the one branch to the command text has been prefixed “R” and the other (to the field list) “Z”.
|
1 2 3 4 5 |
CROSS APPLY RPT.contentXML.nodes('/Report/DataSets/DataSet') AS R(RptNode) CROSS APPLY RPT.contentXML.nodes('/Report/DataSets/DataSet') AS Z(RptNode) ) |
The entire query is now executed by the SELECT portion of the CTE (see below).
SELECT DEF.ReportPath ,DEF.DataSourceName ,DEF.DataSetName ,DEF.Fields ,DEF.CommandText FROM DEF
Quo Vadis?
In a prior “get together” we discussed the construction of a SQL Server Monitoring dashboard. At that time we developed one stored procedure that we are now going to reuse. This query tells us which reports have not been used over a given time period. The link to this article may be found below.
/monitoring-sql-server-reporting-services/
This combined with the query that we have just created will give us the answer that we are looking for. Both queries have a common field “Report Path”.
We create an inner join on the output of both queries (each extract has its own temporary table). The code listing may be seen in Addenda 2.
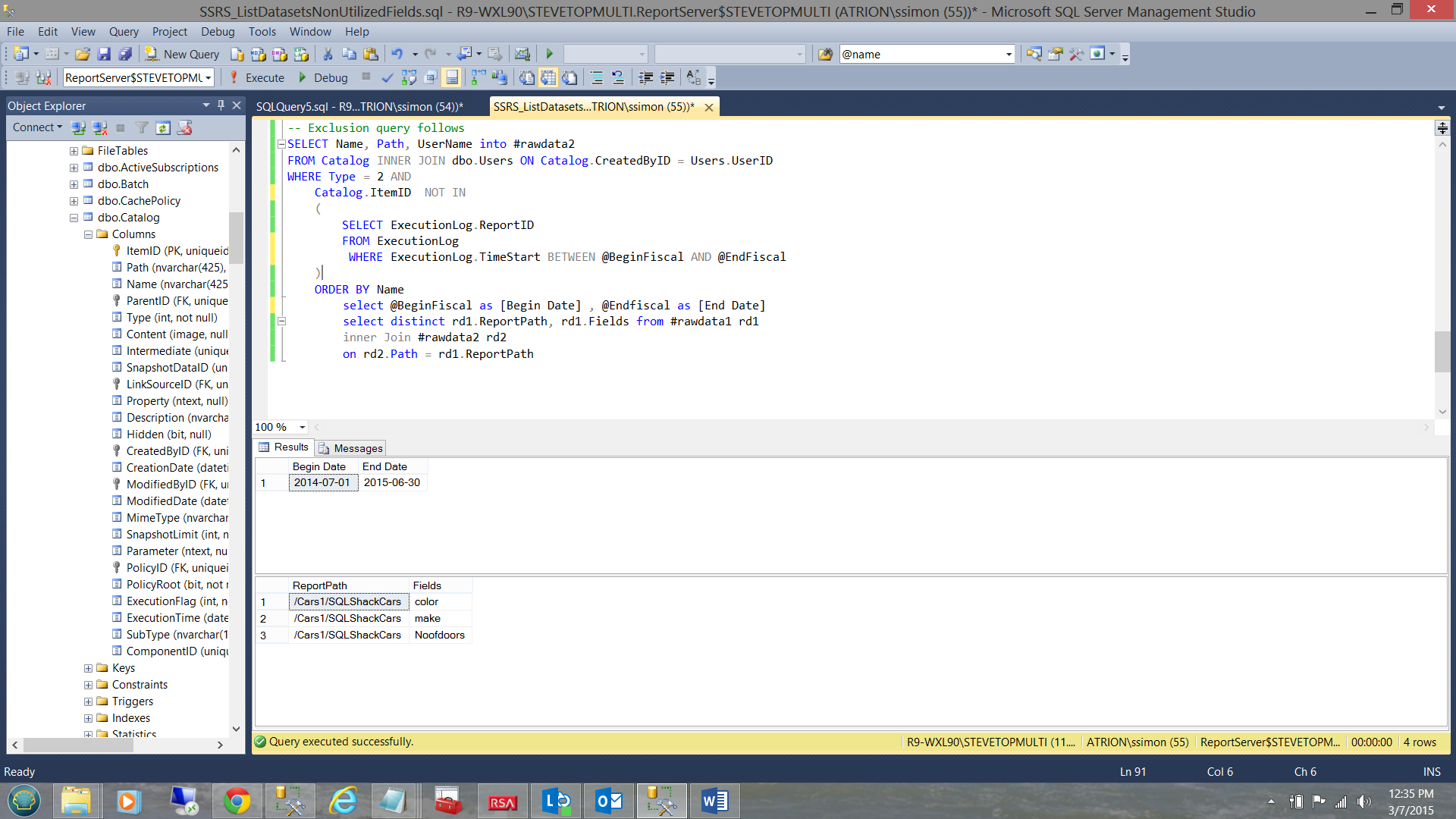
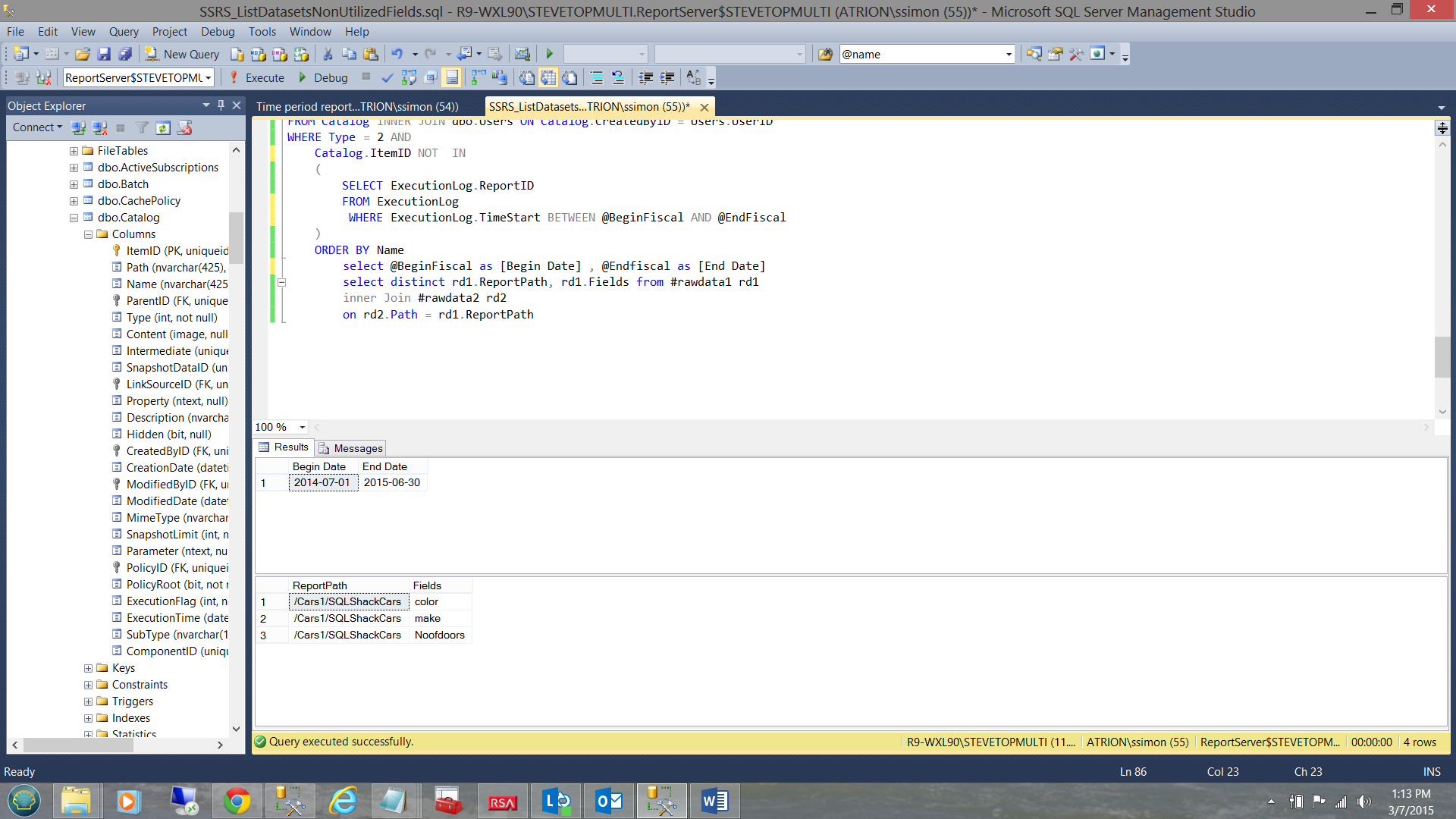
Note the result of the first query which gives us the start and end date of our period (see above). This is there for information only.
The second set, contains the reports that were not run during this time period. The key to this logic lies in the “Catalog.ItemID NOT IN” part of the predicate (see above).
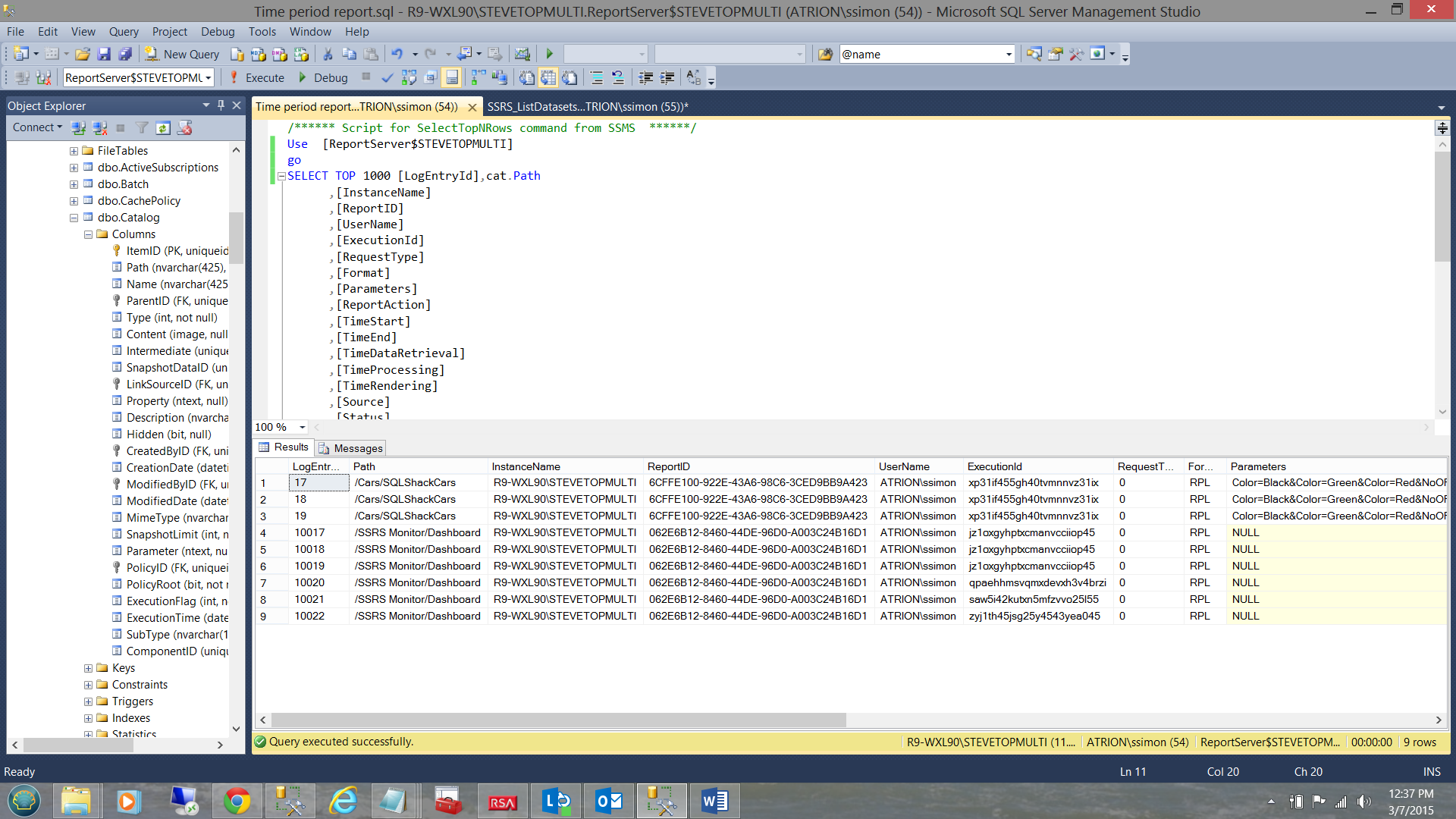
The screen shot shown above shows the reports that were run during the time period 7/1/2014 to 6/30/2015. Note that the report in the “Cars1” directory is not showing. The reason being that that report has not been run on this instance of the reporting server.
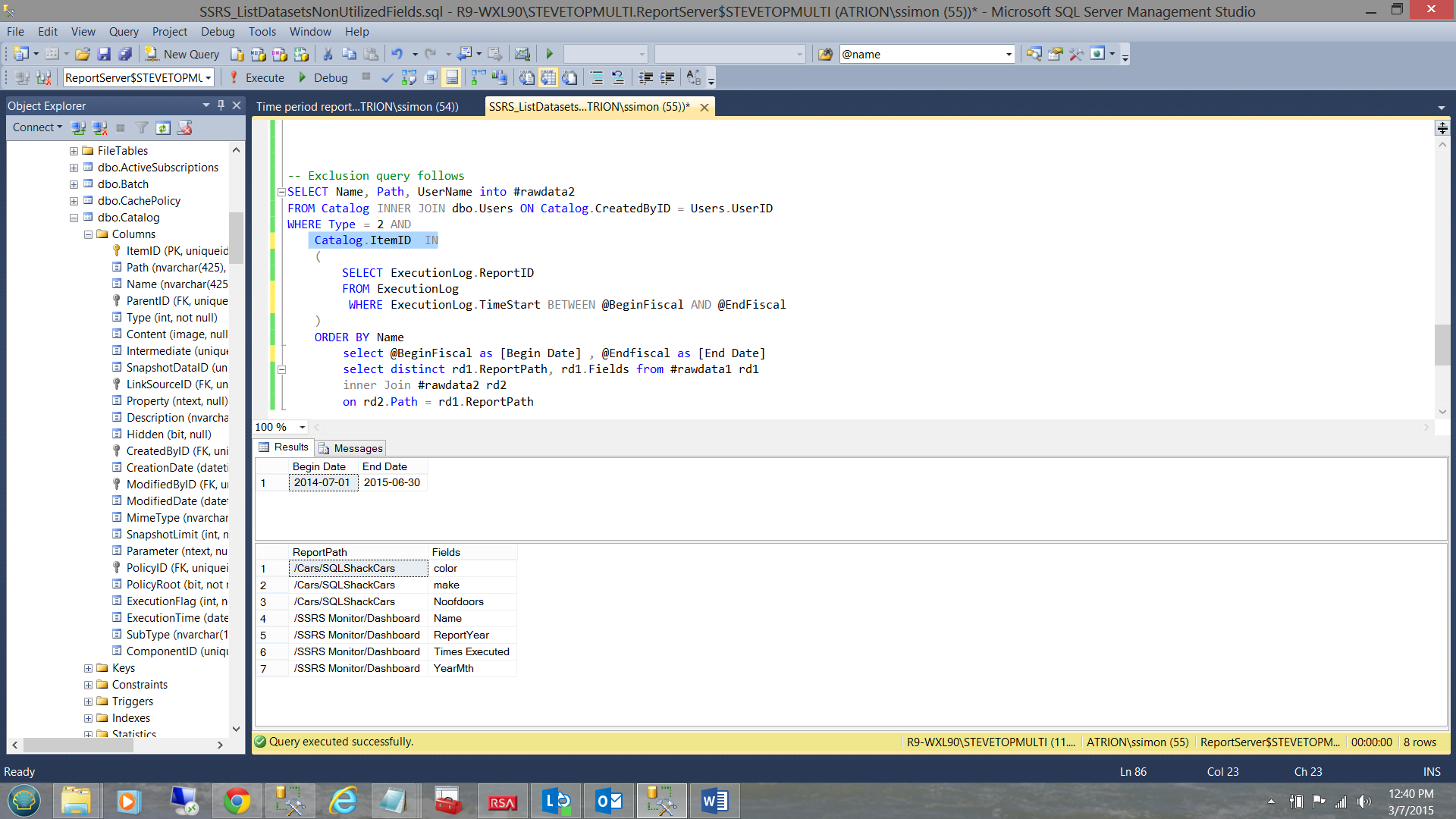
Further, when I removed the “NOT” in the query predicate, then the reports that were actually run during the time interval, now become visible (see below).
Conclusions
Thus having found that the only report that had not been run (during the given time period) was the “SQLShackCars” report that resides in the “Car1” directory, we have achieved our goal of determining which reports have not been utilized. Thus any fields unique to these reports may not have to be ported to the database in the cloud.
Further, with those report that were run during the period, we know that their fields need to be ported to the new system. Most of these fields are located in varied tables within the database and should be easily located using the query in Addenda 3. The one gotcha to be aware of, is that some fields from datasets may be calculated fields and as such should not be present in any of the tables under consideration, assuming that we do not have a naming clash.
Thus we have come to the end of another get together. I hope that this exercise is of some use to you and as always, should you have any questions or concern, please feel free to contact me.
In the interim, happy programming!
Addenda 1
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
-- Transact-SQL to query datasets fields with command text for all SSRS reports. -- List datasets WITH FIELD NAME with command text for all SSRS reports on Report Server ;WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/reporting/2008/01/reportdefinition' ,'http://schemas.microsoft.com/sqlserver/reporting/reportdesigner' AS rd) ,DEF AS (SELECT RPT.ReportPath ,R.RptNode.value('(./Query/DataSourceName)[1]', 'nvarchar(425)') AS DataSourceName ,R.RptNode.value('@Name[1]', 'nvarchar(425)') AS DataSetName ,REPLACE(REPLACE(LTRIM((R.RptNode.value('(./Query/CommandText)[1]', 'nvarchar(4000)'))) ,'>', '>') ,'<', '<') AS CommandText ,REPLACE(REPLACE(LTRIM((Z.RptNode.value('(./Fields/Field/DataField)[1]', 'nvarchar(4000)'))) ,'>', '>') ,'<', '<') AS Fields FROM (SELECT RPT.Path AS ReportPath ,RPT.name AS ReportName ,CONVERT(xml, CONVERT(varbinary(max), RPT.content)) AS contentXML FROM [ReportServer$STEVETOPMULTI].dbo.[Catalog] AS RPT WHERE RPT.Type = 2 -- 2 = A Report is Type 2 ) AS RPT CROSS APPLY RPT.contentXML.nodes('/Report/DataSets/DataSet') AS R(RptNode) CROSS APPLY RPT.contentXML.nodes('/Report/DataSets/DataSet') AS Z(RptNode) ) SELECT DEF.ReportPath ,DEF.DataSourceName ,DEF.DataSetName ,DEF.Fields ,DEF.CommandText FROM DEF ORDER BY DEF.ReportPath ,DEF.DataSourceName ,DEF.DataSetName DEF.Fields |
Addenda 2
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
-- Transact-SQL to query datasets fields with command text for all SSRS reports. -- List datasets WITH FIELD NAME with command text for all SSRS reports on Report Server Use [ReportServer$STEVETOPMULTI] go IF OBJECT_ID(N'tempdb..#rawdata1') IS NOT NULL BEGIN DROP TABLE #rawdata1 END IF OBJECT_ID(N'tempdb..#rawdata2') IS NOT NULL BEGIN DROP TABLE #rawdata2 END GO declare @Yearr varchar(4) declare @LowYearr varchar(4) declare @decider int declare @YearIncoming as varchar(4) Declare @BeginFiscal as date Declare @EndFiscal as date set @decider = datepart(Month,convert(date,getdate())) set @Yearr = datepart(YEAR,Convert(date,Getdate())) set @Lowyearr = @Yearr -1 set @Lowyearr = case when @decider > 6 then datepart(YEAR,Convert(date,Getdate())) else @LowYearr end set @Yearr = case when @decider >= 7 then datepart(YEAR,Convert(date,Getdate())) + 1 else @Yearr end set @Beginfiscal = convert(varchar(4),@LowYearr) + '0701' set @Endfiscal = convert(varchar(4),@Yearr) + '0630' ;WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/reporting/2008/01/reportdefinition' ,'http://schemas.microsoft.com/sqlserver/reporting/reportdesigner' AS rd) ,DEF AS (SELECT RPT.ReportPath ,R.RptNode.value('(./Query/DataSourceName)[1]', 'nvarchar(425)') AS DataSourceName ,R.RptNode.value('@Name[1]', 'nvarchar(425)') AS DataSetName ,REPLACE(REPLACE(LTRIM((R.RptNode.value('(./Query/CommandText)[1]', 'nvarchar(4000)'))) ,'>', '>') ,'<', '<') AS CommandText ,REPLACE(REPLACE(LTRIM((Z.RptNode.value('(./Fields/Field/DataField)[1]', 'nvarchar(4000)'))) ,'>', '>') ,'<', '<') AS Fields FROM (SELECT RPT.Path AS ReportPath ,RPT.name AS ReportName ,CONVERT(xml, CONVERT(varbinary(max), RPT.content)) AS contentXML FROM [ReportServer$STEVETOPMULTI].dbo.[Catalog] AS RPT WHERE RPT.Type = 2 -- 2 = A Report is Type 2 ) AS RPT CROSS APPLY RPT.contentXML.nodes('/Report/DataSets/DataSet') AS R(RptNode) CROSS APPLY RPT.contentXML.nodes('/Report/DataSets/DataSet') AS Z(RptNode) ) SELECT DEF.ReportPath ,DEF.DataSourceName ,DEF.DataSetName ,DEF.Fields ,DEF.CommandText into #rawdata1 FROM DEF ORDER BY DEF.ReportPath ,DEF.DataSourceName ,DEF.DataSetName ,DEF.Fields -- Exclusion query follows SELECT Name, Path, UserName into #rawdata2 FROM Catalog INNER JOIN dbo.Users ON Catalog.CreatedByID = Users.UserID WHERE Type = 2 AND Catalog.ItemID IN ( SELECT ExecutionLog.ReportID FROM ExecutionLog WHERE ExecutionLog.TimeStart BETWEEN @BeginFiscal AND @EndFiscal ) ORDER BY Name select @BeginFiscal as [Begin Date] , @Endfiscal as [End Date] select distinct rd1.ReportPath, rd1.Fields from #rawdata1 rd1 inner Join #rawdata2 rd2 on rd2.Path = rd1.ReportPath |
Addenda 3
The code snippet below will find all tables (within the database) that have a field with that name.
|
1 2 3 4 5 6 7 8 9 10 11 |
use [SQLServerFinancial] go SELECT t.name AS table_name, SCHEMA_NAME(schema_id) AS schema_name, c.name AS column_name FROM sys.tables AS t INNER JOIN sys.columns c ON t.OBJECT_ID = c.OBJECT_ID WHERE c.name LIKE '%sku%' -- or c.name LIKE '%order%' ORDER BY schema_name, table_name,column_name |
Steve has presented papers at 8 PASS Summits and one at PASS Europe 2009 and 2010. He has recently presented a Master Data Services presentation at the PASS Amsterdam Rally.
Steve has presented 5 papers at the Information Builders' Summits. He is a PASS regional mentor.
View all posts by Steve Simon
- Reporting in SQL Server – Using calculated Expressions within reports - December 19, 2016
- How to use Expressions within SQL Server Reporting Services to create efficient reports - December 9, 2016
- How to use SQL Server Data Quality Services to ensure the correct aggregation of data - November 9, 2016