
Intro
In relational databases, operations are made on a set of rows. For example, a SELECT statement returns a set of rows which is called a result set. Sometimes the application logic needs to work with a row at a time rather than the entire result set at once. In T-SQL, one way of doing this is using a CURSOR.
If you possess programming skills, you would probably use a loop like FOR or WHILE to iterate through one item at a time, do something with the data and the job is done. In T-SQL, a CURSOR is a similar approach, and might be preferred because it follows the same logic. But be advised, take this path and trouble may follow.
There are some cases, when using CURSOR doesn’t make that much of a mess, but generally they should be avoided. Below, we will show some examples where using a CURSOR creates performance issues and we will see that the same job can be done in many other ways.
For the purpose of this demonstration we will use AdventureWorks2012 database, and let’s say we want to get some data from [Production].[ProductInventory] table, for every product that requires less than a day to manufacture, that is from table [Production].[Product].
A cursor example
Let’s start by using a CURSOR, and write the following syntax:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
USE AdventureWorks2012 GO DECLARE @id int DECLARE cursorT CURSOR --LOCAL STATIC --LOCAL FAST_FORWARD --LOCAL READ_ONLY FORWARD_ONLY FOR SELECT ProductId FROM AdventureWorks2012.Production.Product WHERE DaysToManufacture <= 1 OPEN cursorT FETCH NEXT FROM cursorT INTO @id WHILE @@FETCH_STATUS = 0 BEGIN SELECT * FROM Production.ProductInventory WHERE ProductID=@id FETCH NEXT FROM cursorT INTO @id END CLOSE cursorT DEALLOCATE cursorT |
After a short coffee break, the query finished executing, returning 833 rows in the time shown below. It’s important to mention the chosen syntaxes above are only for demo purposes, and I made no index tuning to speed things up.

In the cursor execution, we have two steps. Step one, the positioning, when the cursor sets its position to a row from the result set. Step two, the retrieval, when it gets the data from that specific row in an operation called the FETCH.
In our example, the cursor sets its position to the first row returned by the first SELECT and fetches the ProductID value that matches WHERE condition in @id variable. Then the second SELECT uses the variable value to get data from [Production].[ProductInventory] and the next row is fetched. These operations are repeated until there are no more rows to work with.
Finally, CLOSE syntax releases the current result set and removes the locks from the rows used by the cursor, and DEALLOCATE removes cursor reference.
Our demo tables are relative small containing roughly 1,000 and 500 rows. If we had to loop through tables with millions of rows it would last a considerable amount of time and the results would not please us.
Let’s give our cursor another chance and uncomment the line –LOCAL STATIC. There are many arguments we can use in a cursor definition, more on that on this link CURSOR Arguments, but for now let’s focus on what this two words mean.
When we specify LOCAL keyword, the scope of the cursor is local to the batch in which it was created and it is valid only in this scope. After the batch finishes executing, the cursor is automatically deallocated. Also, the cursor can be referenced by a stored procedure, trigger or by a local cursor variable in a batch.
The STATIC keyword makes a temporary copy of the data used by the cursor in tempdb in a temporary table. Here we have some gotchas. A STATIC cursor is read-only and is also referred to as a snapshot cursor because it only works with the data from the time it was opened, meaning that it won’t display any changes made in database on the set of data used by the cursor. Basically, no updates, deletes or inserts made after the cursor was open will be visible in the cursors result set unless we close and reopen the cursor.
Be aware of this before using these arguments and check if it matches your needs. But let’s see if our cursor is faster. Below we have the results:

12 seconds are a lot better that 4 minutes and 47 seconds, but keep in mind the restrictions explained above.
If we run the syntax using this argument LOCAL READ_ONLY FORWARD_ONLY we get the same results. READ_ONLY FORWARD_ONLY cursor can be scrolled only from the first row to the last one. If the STATIC keyword is missing, the cursor is dynamic and uses a dynamic plan if available. But there are cases when a dynamic plan is worse than a static one.
What happens when we uncomment –LOCAL FAST_FORWARD?
FAST_FORWARD is equivalent to READ_ONLY and FORWARD_ONLY cursor but has the ability to choose the better plan from either a static or a dynamic one.
LOCAL FAST_FORWARD seems to be the best choice because of its flexibility to choose between a static or dynamic plan, but FORWARD_ONLY also does the job very good. Although we got the result in an average of 12 seconds using both of this methods, these arguments should be properly tested before choosing one of them.
There are many ways of obtaining the same result, much quicker and with less impact on performance.
Cursor alternative
One method is using a JOIN, and as we can see next, the results are considerable better.
First, we have to enable statistics time to measure SQL Server execution time, and make an INNER JOIN between two tables, [Production].[ProductInventory] and [Production].[Product] on ProductID column. After hitting the EXECUTE button, we produced the same results in 330 ms, compared to 04:47 time from the cursor method, and we have a smile on our face.
|
1 2 3 4 5 6 7 8 9 |
USE AdventureWorks2012 GO SET STATISTICS TIME ON SELECT * FROM Production.ProductInventory as pinv INNER JOIN Production.Product as pp ON pinv.ProductID=pp.ProductID WHERE pp.DaysToManufacture <= 1 |
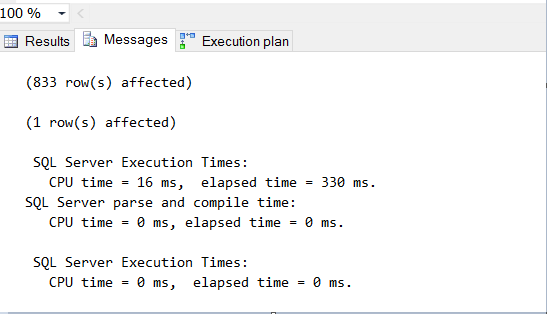
We do not need to iterate through every row to get what we need, we have no more loops, no while clause, no iterations, we are working with sets of data instead, getting what we want faster and writing less code.
An appropriate use of cursor
Now that we’ve seen how much damage a cursor can do, let’s see an example where we can make use of it.
Let’s assume we want to select the size and number of rows for only certain tables from a database. To achieve this, we will get all table names based on criteria from information_schema.tables and using a CURSOR we will loop through each of that table name and execute the stored procedure sp_spaceused by passing one table name at a time to get the information we need.
We will use the same AdventureWorks2012 database, and get all tables from Sales schema that contains the name ‘Sales‘. For every table name returned, we want to see all the info from information_schema.tables.
Below we have the T-SQL syntax and the obtained results:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
USE AdventureWorks2012 GO DECLARE @TableName VARCHAR(50) -- table name from 'Sales' schema DECLARE @Param VARCHAR(50) -- parameter for 'sp_spaceused' procedure DECLARE db_cursor CURSOR FOR --select only 'Sales' tables SELECT TABLE_NAME FROM information_schema.tables WHERE TABLE_NAME like '%Sales%' and TABLE_TYPE='BASE TABLE' OPEN db_cursor FETCH NEXT FROM db_cursor INTO @TableName WHILE @@FETCH_STATUS = 0 BEGIN --concatenate each table name in a variable and pass it to the stored procedure SET @Param='Sales.'+@TableName --execute stored procedure for every table name at a time EXEC sp_spaceused @Param FETCH NEXT FROM db_cursor INTO @TableName --gets the next table name END CLOSE db_cursor DEALLOCATE db_cursor |
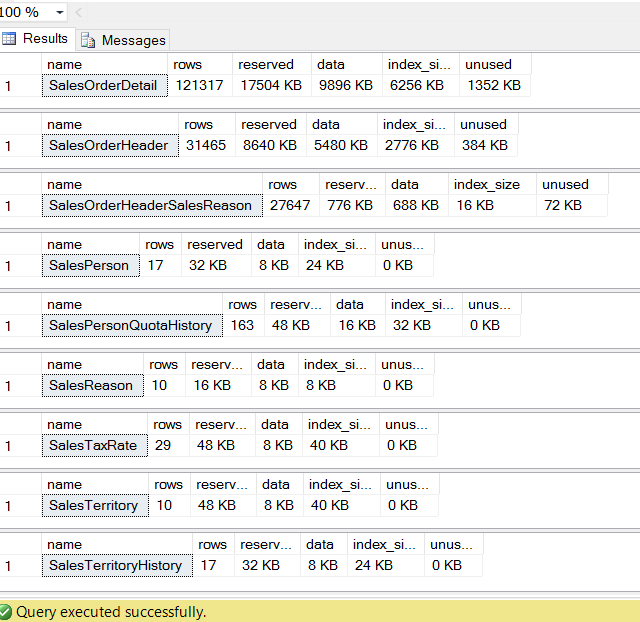
This is one method where CURSOR is helpful by iterating through some data one row at a time and gets the result needed. In this particular case, the cursor gets the job done without having implications on performance and is easy to use.
Conclusions
There we have it. We showed some examples with the good, the bad and the ugly when using cursors. In most cases, we can use JOINS, even WHILE clauses, SSIS packages or other alternative methods to get the same result quicker, with less impact on performance output and even writing fewer lines of syntax.
When we are dealing with OLTP environment and large sets of data to process, the word ‘CURSOR’ should not be spoken.
In SQL, it’s a good practice to think at making operations on sets of data, rather than think in a programmatic way, using iterations or loops, because this kind of approach is not recommended nor intended for this use. Trying to use loops like FOR or FOREACH from programming languages and associate that logic with SQL operations, is an obstacle for getting the right solution to our needs. We have to think at set-based operations rather than one row at a time to get the data we need.
Cursors could be used in some applications for serialized operations as shown in example above, but generally they should be avoided because they bring a negative impact on performance, especially when operating on a large sets of data.

I have a bachelor degree in computer engineering and also posses skills in .NET, C# and Windows Server. I developed experience in performance tuning and monitoring, T-SQL development , backup strategy, administration and configuring databases.
I am passionate about IT stuff, video games, good movies, and electro-house music helps me work when the office is noisy.
View all posts by Sergiu Onet
- Using SQL Server cursors – Advantages and disadvantages - March 23, 2016