
To SQL Server DBAs who are the shepherds of data in organizations, key GDPR questions, in general, center around whether data will need to be treated differently, safeguarded more etc. and specifically, as it relates to allowing production data to be used in testing.
That will be the focus of this article as we’ll work our way through the details of this regulation as well as various authoritative articles on the subject, to address this key question. Then we’ll look to ways and means to potentially ameliorate our findings to provide alternatives and workarounds if possible.
Can I use raw production data in testing and be compliant with GDPR?
In terms of personal data e.g. names, addresses, phone numbers etc, the short answer is “no” and we’ll go through the reasons why not.
Lawful basis
To begin with GDPR stipulates that data can only be processed if there is a lawful basis
“Data can only be processed if there is at least one lawful basis to do so. The lawful bases for processing data are:
- the data subject has given consent to the processing of his or her personal data for one or more specific purposes.
- processing is necessary for the performance of a contract to which the data subject is party or in order to take steps at the request of the data subject prior to entering into a contract.
- processing is necessary for compliance with a legal obligation to which the controller is subject.
- processing is necessary in order to protect the vital interests of the data subject or of another natural person.
- processing is necessary for the performance of a task carried out in the public interest or in the exercise of official authority vested in the controller.
- processing is necessary for the purposes of the legitimate interests pursued by the controller or by a third party, except where such interests are overridden by the interests or fundamental rights and freedoms of the data subject which require protection of personal data, in particular where the data subject is a child.” 1
For our purposes, item #6 is the only one that is relevant as none of the other items, by their nature, would allow for the use of production data, whether personal or sensitive, to be used for testing purposes.
So far we haven’t determined, with authority, that we can’t use raw production data for testing, but our window for allowing this has considerably narrowed, and we must demonstrate “legitimate interests” to proceed (see next).
Legitimate basis
Initially, this seems promising e.g. “Hey, testing is certainly a legitimate interest” but there are already some hints of trouble.
Although testing certainly isn’t a nefarious activity, by any sense, the qualification is already limited by the “interests or fundamental rights and freedoms of the data subject”.
GDPR offers helpful examples of legitimate use of further data processing including Recital 47: processing for direct marketing purposes or preventing fraud; But … this is specifically qualified to include the interests, expectations and rights of the subjects of the data e.g. “The interests and fundamental rights of the data subject could in particular override the interest of the data controller where personal data are processed in circumstances where data subjects do not reasonably expect further processing”
Although this recital refers to marketing, not testing, it is analogous. Would you expect that your data would be viewed, manipulated, tested or otherwise “processed” for the purposes of software development and quality control? Unlikely. Also, as there is no recital that explicitly (or implicitly) allows for data testing, we can’t rely on that.
So basically, unless the subjects of the data would have a reasonable expectation that their data would be used for such purposes, they can’t be considered “legitimate” in the context of GDPR and therefore would not be allowed under GDPR.
For the purposes of using raw production data in testing, this is essentially the end of the road. But if there was an ambiguity, or remaining questions, those should be put to rest by additional considerations that makes processing production data for testing, even a worse idea, in the context of GDPR, namely processing purpose and the right to object.
Processing purpose
This should come as no surprise to some who have followed, or been affected by similar legislation. This finding is consistent with the UK Data Protection Act, which is a precursor to GDPR. The UK Data Protection Act actually states that
“Personal data shall be obtained only for one or more specified and lawful purposes, and shall not be further processed in any manner incompatible with that purpose or those purposes.”
So unless the original purpose of the data collection was for testing purposes, then using it in such a manner would seem to violate both the spirit and letter of the act, and its subsequent incarnation, GDPR, as well.
Right to object
Furthermore, GDPR provides for the right to object, so even if your organization used personal data without consent, for the reasons of “legitimate interests”, you would still have an obligation to inform the data subjects of the new instance of processing, and allow them to explicitly opt out of this. This would obviously be impractical for the purposes of software/database testing.
Summary
So regardless of the safeguards and protections applied to the data, production data can’t be processed for ulterior purposes from when it was originally obtained, without explicit permission from the data subject, an unrealistic scenario.
Ok, I can’t use raw production data, but what if I obfuscate aka pseudonymise it?
We’ve determined how re-processing raw production data for an ulterior purpose, in this case, for database testing, is a non-starter in the context of GDPR, but can anything be done to mitigate the requirement and/or provide some workarounds?
GDPR explicitly encourages and recommends the obfuscation of data. In the context of GDPR, obfuscation is a basic requirement for re-processing data. Obfuscation doesn’t, necessarily, get you out from the stipulations of GDPR but it does relax some of the compliance and auditing requirements.
As to the question above, short answer is “yes” but with the qualification that such pseudonymised data, in turn, falls under GDPR, is considered “personal” data and must still be audited, secured etc. In some cases, the cost of GDPR compliance might preclude the use of production data for test, even though it would be allowable
“Pseudonymization is a procedure by which the most identifying fields within a data record are replaced by one or more artificial identifiers, or pseudonyms.” 2
The basic goal of pseudonymization, is to break up interrelated data or reduce its “linkability” so that it can’t be attributed back to the original data subject. So, if a name, social security number and address were required to uniquely identify and individual, then if two of the three items were pseudonymised then there would be no way to definitively identify the data subject.
Pseudonymised data is reversible, which means it is still considered personal data from the perspective of GDPR and must is held to the same rigorous compliance standards of non pseudonymised data.
Examples of pseudonymization might be converting the data based on a particular algorithm or process that is reversible or replacing data, but storing the replaced data in way that allows it to be achieved. Another example is encrypting the data, but allowing for decryption to its original state.
Advantages and disadvantages
The advantages of pseudonymization are that
- Data is usually not totally altered and transformed to a state that might break the integrity of systems or make data unreadable.
- Pseudonymization is generally less effort because it is less intrusive/comprehensive
- The process is reversible
The disadvantage of pseudonymization is that since it is reversible, it is still considered personal data, and falls under the same stringent data protection, auditing and compliance requirements as non-obfuscated data, which can be time consuming and expensive to implement, and expose additional teams, like QA, to liability.
Can I use production data for testing without having to worry about GDPR at all?
Yes, the data can be used if it is anonymized.
Anonymization is a more rigorous form of obfuscation, that essentially renders the process data to a state that it can never be re-identified, unlike pseudonymization where data can be re-identified. All of the data elements are obfuscated, vs Pseudonymization, in which only enough data elements need to be obfuscated to de-link them, to prevent identification of the data subject.
An example of anonymization, would be to encrypt the data and then delete the encryption key so that the data could never be decrypted again.
Advantages and disadvantages
The advantage of anonymization is that GDPR compliance requirements no longer apply to it.
The disadvantage of anonymization is that it can be costlier and labor intensive to apply, since all of the data must be processed and with methods that are sophisticated enough that they can’t be reversed.
The challenge with this solution is that the cost and expense of anonymizing all of your production data, needs to be weighed against the costs and expenses of just complying with GDPR and using lessor forms of obfuscation.
What are the common solutions for obfuscation?
Masking is the primary means for data obfuscation. It is the process of scrambling, blurring, replacing existing data with data of approximate length and format.
Encryption, can be thought of as just another obfuscation technique, but it generally protects data to a much higher degree and is irreversible without a particular “key”. Note that for encrypted data to be considered anonymized, it must be totally irreversible, so the key must be destroyed or otherwise be made inaccessible.
Are there any alternatives to obfuscating production data?
Yes, another approach would be to forego the use of production data entirely and instead use synthetic data. Randomly generated, synthetic data or “test data” isn’t production data so wouldn’t be required to be audited or secured to comply with GDPR.
Synthetic data could be used as a means to implement both pseudonymization and anonymization.
Advantages and disadvantages
Creating test data would be equivalent, in time and expense, to masking production data.
If only some parts of personal production data were replaced with synthetic generated test data, to achieve pseudonymization, then you would be able to use it as test data, but not without adhering to GDPR compliance requirements.
If all personal data were replaced with synthetic generated test data, or an entirely new set of data was generated from scratch, you will have achieved the benefits of full anonymization and could escape the rigors of GDPR compliance entirely.
Comparison
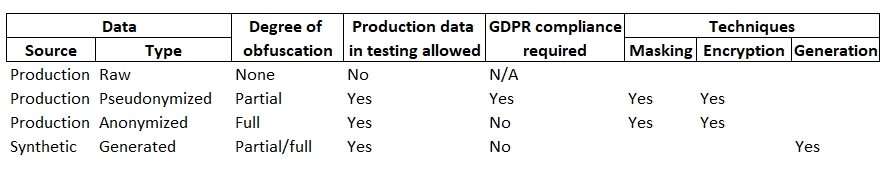
This illustration shows the four source/types of data in the context of GDPR and obfuscation.
Raw production data can’t be used in production.
Pseudonymised production data is partially obfuscated, using either masking or encryption. Although such data can be used in testing, GDPR compliance is still required.
Anonymized production data is fully obfuscated either by irreversible masking or encryption. GDPR compliance is not required.
Automatically generated, synthetic test data, can be used to partially or fully obfuscated personal data, but in most cases, such data would be fully obfuscated. In this case, GDPR compliance is not required.
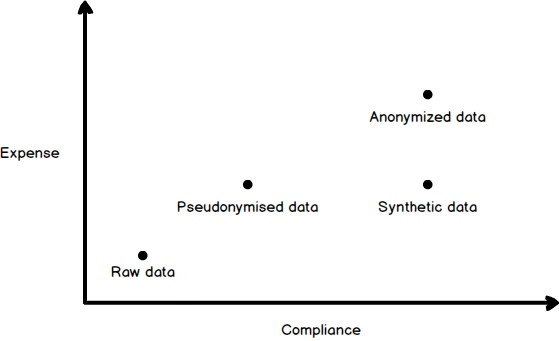
The above schematic shows the relative costs and compliance level to the four types of data used in testing.
- Raw data is the least expensive, because, by definition, it doesn’t require refactoring but it is also the least compliant, and in the context of GDPR, totally non-compliant/illegal
- Pseudonymised data is more expensive, than raw data, as it must be partially obfuscated, at least, and through this re-processing, it becomes more compliant with GDPR, and even fully compliant as long as the data is audited and secured
- Synthetic data, involves similar effort and expense of Pseudonymised data, but since the data is new, and totally different than the production data, that it would replace, it would no longer be considered personal data, and as such have no requirements for GDPR compliance
- Anonymized data is more expensive because all personal data, not just parts, must be obfuscated and the obfuscation process must be irreversible. But for this effort and expense, the reward is that such data is fully compliant with GDPR to the degree that it falls outside the requirement for auditing, security etc
Summary
Using raw personal data in production, was never a good idea, but GDPR essentially makes it illegal, for affected countries because such data can’t be re-processed, without explicit opt in.
But GDPR does allow for obfuscated data to be re-processed, even for purposes it was never originally intended or gathered for.
Obfuscation, is an umbrella term that includes varying degrees of data transformation. It includes pseudonymization of data, which partially obfuscates data and is reversible. Anonymization is a process that fully obfuscates that data and it is irreversible.
Although pseudonymization of data allows it to be re-processed, and does ameliorate some of the requirements of GDPR, it doesn’t change the classification of the data, so it must continue to be considered personal data and treated like that, in the context of GDPR, including auditing and security.
Anonymization of data, entirely frees you of the requirement to comply with GDPR in managing the obfuscated data.
Randomly generated, synthetic test data can be used as an alternative to obfuscated production data. It can be used to pseudonymise and/or fully anonymize data, depending on how much production data is replaced.
1 EUR-Lex REGULATION (EU) 2016/679
2 Pseudonymization

- Eating the frog: How to create a daily-deliverable sprint burn down graph in Excel - July 12, 2018
- How to create an advanced sprint burn down chart in Excel - July 10, 2018
- Sharpen your ax - July 4, 2018