
Nowadays many customers are spread globally and need to manage the requirement for users to connect from/to any location, perform an activity (insert, update, delete), and the databases should be kept synchronized across multiple sites.
Suppose we have been working an online supermarket website spread across multiple locations. Customers from different countries open the website and then redirected to the website for their respective country. The website is redirecting to the application server which connects database on backend locally, but all country database needs to be in sync. If any of the country database servers fails, a database request should be automatically redirected to another country server without any loss of data or loss of connectivity for the application.
Transaction replication in SQL server is used to replicate a full database or a subset of the database configured for the scalability of the database. Below are the terms used in the replication:
Publisher: It is the source database, which contains data to replicate.
Subscriber: This is the destination database; there may be many subscribers for a single publisher.
Distributor: It is used to distribute the transactions to the subscriber database.
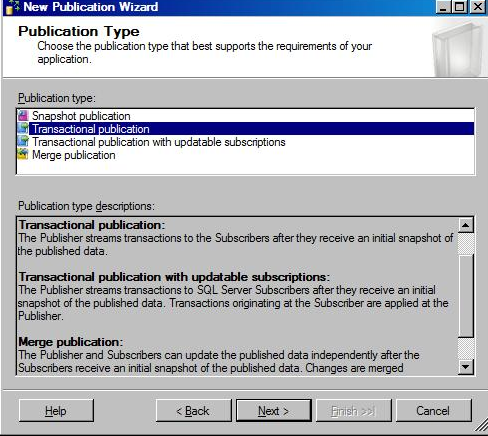
In transaction replication, data flows from publisher to subscriber. A subscriber cannot act as a publisher replication however; it can serve as the other publisher if needed. Peer to peer replication is built on the concept of transaction replication, which propagates consistent transactional data. Peer to peer replication involves Multiple servers are called as (nodes). In this, each node acts as a publisher as well as a subscriber that means it receives and sends transactions to other nodes, data is synchronised across the nodes.
Below is the architecture for two node peer to peer replication
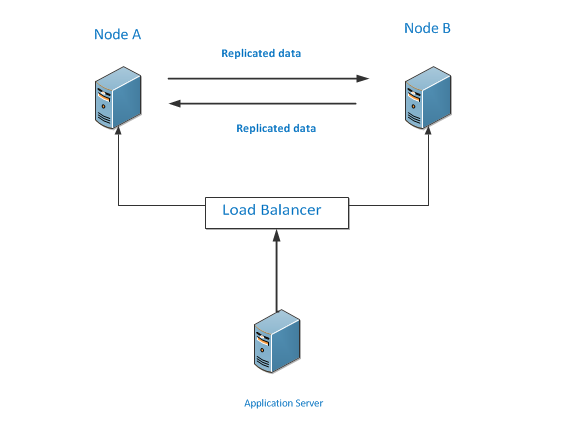
As per the above architecture, we can see the application server is sending requests to both the database servers. Both nodes A and B are replicating its data with each other. If any DML statement is executed for node A, it is then replicated to node B and vice-a-versa. The application should be getting a consistent result whether it is connecting to either node. So since, it is bi-directional replication, each database is publisher and subscriber so these are called as nodes and replication is called peer to peer replication.
If any node goes down, the application will still be functional. Later, once the node is up it can be again brought in sync. This way we can achieve both high availability and fault tolerance.
If we look at the three nodes architecture below, we can see each one is replicating transactions to the other node and all are having the same copy of the data.
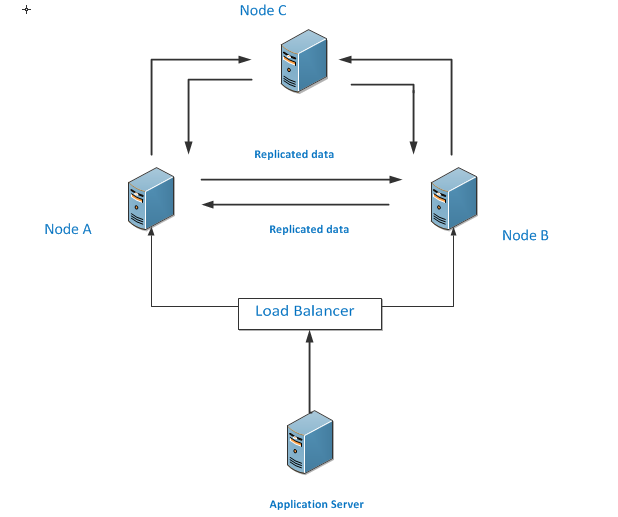
In another scenario, there may be a separate application server for each databases node so each database server is getting its own inserts, updates but at the end, it is also being replicated to other nodes as well.
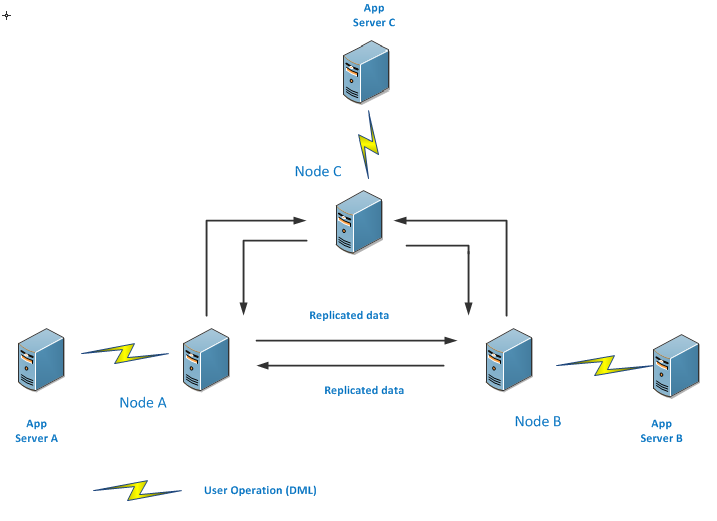
The primary concept of peer to peer replication is that each node is updated with the data but responsible for updating its own data thus it is the essential requirement to have identical schema and data. Database restoration is required on participating nodes to fulfil the requirement.
Requirements for configuring peer to peer replication
- Peer to peer replication is supported in the Enterprise version of SQL server only.
- Row level and column level filtering cannot be used, which means each and every database needs to have all the data rows and columns.
- There should be identical publication name on all participating nodes.
- Each Node should have its distribution database; this eliminates the risk of single point of failure.
- Peer to peer subscriptions cannot be reinitialized. Restoration of backup should be done in that case.
- We cannot add tables in multiple peers to peer publications in the same publication database.
Steps to configure peer to peer replication
Suppose we need to configure replication for three servers named node a, node b, node c. below steps will be required for configuration
-
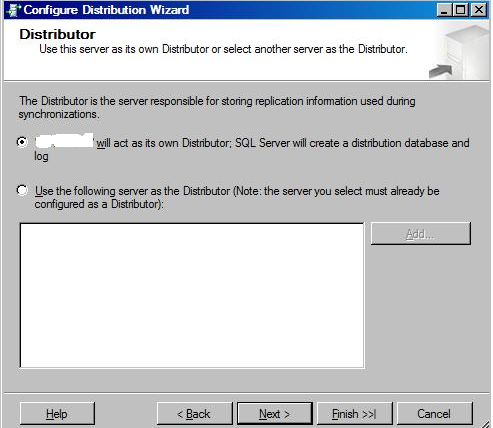
Configure distribution on all three nodes.

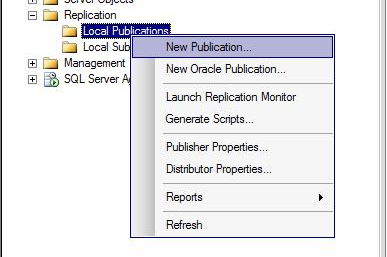
Create publication at node a by using the new publication wizard, select transaction replication and complete the wizard
-
Now enable the publication for peer to peer replication by right click on the publication and then click on properties
- Initialize the schema and data onto other nodes b and c by taking backup from node a followed by database restore on b and c.
-
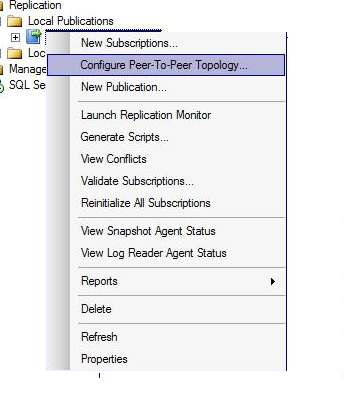
Once the backup restoration is done, we need to configure peer to peer topology
Conflict detection
Peer to peer replication allows performing insert, update, and delete transactions against any node participating in the topology so there may be chances of conflict if same data gets changes at different nodes at the same time.
Conflicts are not detected when changes are committed at individual peers instead when transactions are replicated across peers. In peer to peer replications, all publication tables have a hidden column which stores an ID that combines with an originator id for node and version of the row. During synchronization, distributor agent runs the procedures that use this column to apply the transaction. If the method detects a conflict when it reads the hidden value, it raises error 22185 of severity 16.
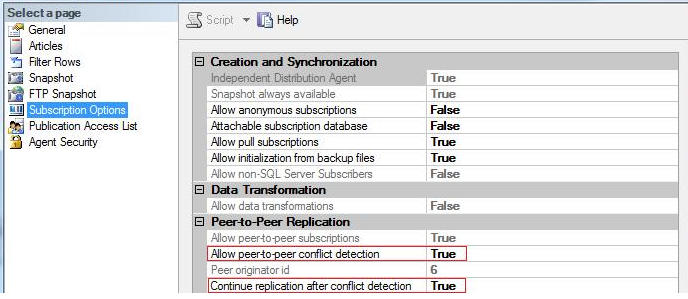
By default if any conflict is detected distributor agent, stop applying changes to that node. Conflict detection was not available in SQL server 2005, it was introduced in SQL server 2008. When we enable conflict detection, a conflicting change is considered a critical error that causes distribution agent to fail. So topology will remain in an inconsistent state until it is resolved and data is consistent across all the nodes.
To use this feature, all peer to peer nodes must be running SQL 2008 or later, and we need to enable the detection across all the nodes.
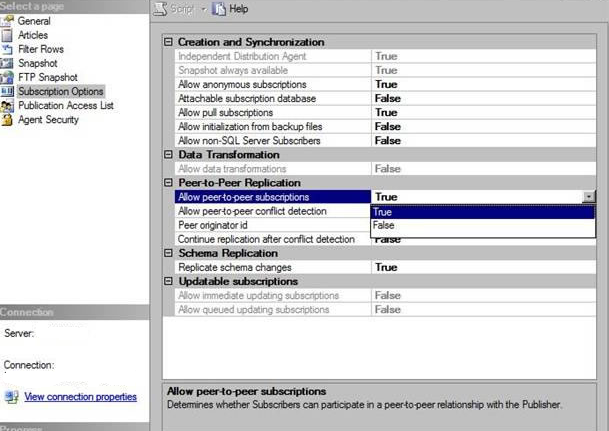
We can allow this by right click on publication -> properties and then in subscription options
Set ‘Allow peer to peer subscriptions’ to True
If we select later option ‘continue replication after conflict detection’ replication will ignore the conflict and continue replicating transactions.
Sp_configure_peerconflictdetection stored procedures can also be used to enable this.
As per MSDN Syntax for this function is
Syntax
|
1 2 3 4 5 6 7 |
sp_configure_peerconflictdetection [ @publication = ] 'publication' [, [ @action = ] 'action'] [, [ @originator_id = ] originator_id ] [ , [ @conflict_retention = ] conflict_retention ] [, [ @continue_onconflict = ] 'continue_onconflict'] |
Sp_help_peerconflictdetection stored procedure returns information about the conflict detection settings for a publication connected in a peer-to-peer transactional replication topology.
Syntax
|
1 2 3 4 |
sp_help_peerconflictdetection [ @publication = ] 'publication' [ ,[ @timeout = ] timeout ] |
Conflict scenarios
As per MSDN Peer-to-peer, replication detects the following types of conflicts:
-
Insert-insert
All rows in each table participating in peer-to-peer replication are uniquely identified by using primary key values. An insert-insert conflict occurs when a row with the same key value was inserted at more than one node. -
Update-update
Occurs when the same row was updated at more than one node. -
Insert-update
Occurs if a row was updated at one node, but the same row was deleted and then reinserted at another node. -
Insert-delete
Occurs if a row was deleted at one node, but the same row was deleted and then reinserted at another node. -
Update-delete
Occurs if a row was updated at one node, but the same row was deleted at another node. -
Delete-delete
Occurs when a row was deleted from more than one node.
If there is any conflict occurs it gets logged in error logs as
An update-update conflict between peer 1 (incoming) and peer 2 (on disk) was detected and resolved. The incoming update was skipped by peer 2
An update-update conflict between peer 2 (incoming) and peer 1 (on disk) was detected and resolved. The incoming update was applied to peer 2.
We need to look at the transactions through exec distribution..sp_browsereplcmds and see which is the command that is in conflict. Transactions on both nodes need to be checked. It might require the transaction to be deleted from one of the nodes. If we have the ‘continue conflict detection’ enabled it will continue the replication even in the case of conflict.
Configuring conflict detection alerts
- Right click the Publication and select Launch Replication Monitor option.
- In the replication monitor, navigate to any P2P publisher.
Select the Warning tab and choose the Conflict Alerts
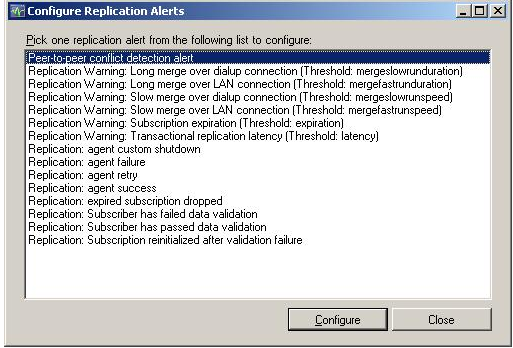
Click on configure and provide the email address in case of email operator, this will notify each time any conflict is detected.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023