
The SQL Server Database Engine stores data changes in the buffer pool, in memory, before applying it to the database files, for I/O performance reasons. After that, a special kind of background process, called Checkpoint, will write all of these not reflected pages, also known as Dirty Pages, to the database data and log files periodically.
When a checkpoint is performed, the data will be marked by a recovery point, and the information about these recovery points will be saved to the database boot page, in order for it to be used in the case of database shutdown or crash, to roll forward all committed transactions that are written to the database transaction log file and not reflected to the database data files. This mark will be also used to rollback any data changes associated with uncommitted transaction, by reversing the operation written in the transaction log file. The purpose of the checkpoint process is to reduce the time required to recover the database in the event of crash, by writing the pages in memory to the data files, so that the SQL Engine will not apply these changes in the event of failure. This is how checkpoints help to guarantee the database consistency.
There are four types of Checkpoints that the SQL Server Database Engine supports:
- Internal
- Manual
- Automatic
- and Indirect
For more information about these types, you can check out the earlier article, Database checkpoints – Enhancements in SQL Server 2016.
Within the scope of this article, we are interested in two types of the checkpoints for Memory-Optimized tables, the Manual Checkpoint that is performed by running the CHECKPOINT command and the Automatic Checkpoint that is performed automatically by the SQL Server Database Engine when meeting specific conditions.
For disk-based tables, the checkpoint will flush all dirty pages to the database files and truncate the log for a database in simple recovery model. A log backup is required for a full recovery model database to truncate the transaction log. An automatic checkpoint is triggered based on the recovery interval configuration option value.
A durable Memory-Optimized table with SCHEMA_AND_DATA durability records the transactions in the transaction log file for recovery purposes in case of failure or crash. These transactions are written to the transaction log only when the transaction is committed, different from the disk-based tables that use Write-Ahead Logging protocol to flush the dirty pages.
For Memory-Optimized tables, the checkpoint is performed by a background worker thread in the In-Memory OLTP Engine, different from the checkpoint threads for the disk-based tables. The Memory-Optimized table checkpoint flushes the data streams that contains all new inserted data to the data files and the flushes the delta stream that contains all deleted data to the delta files. These data and delta files, called the Checkpoint File Pairs (CFPs), are written sequentially opposite to the database data files that are written randomly. Remember that the UPDATE operations are considered as DELETE then INSERT operations.
The Memory-Optimized table automatic checkpoint will be triggered when the database transaction log file becomes bigger than 1.5 GB since the last checkpoint, including the transaction log records for both the Memory-Optimized and disk-based tables. The Memory-Optimized tables checkpoint occurs periodically in order to advance the active part of the transaction log, allowing the tables to be recovered to the last successful checkpoint and applying the last active portion of the transaction log to complete the recovery process.
There is a special case in SQL Server 2016 in which the checkpoint characteristics for Memory-Optimized tables differs, called the Large Checkpoint, that is enabled on large machines with 16 or more logical processors, 128GB or greater memory or the ones that is capable of greater than 200MB/sec I/O measured for the IO subsystem of that database. The automatic large checkpoint is triggered only when 12GB of the transaction log file is filled up since the last checkpoint. The purpose of the large checkpoints is to ensure that the checkpoint process would not be continually executing and would scale efficiently.
Let us start our demo to understand how the checkpoint behaves practically. We will create a new database, InMemoryCheckpoint, create new filegroup that will contain the Memory Optimized data, create a new data file in that filegroup and finally turn on the MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT on that database using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE master GO CREATE DATABASE [InMemoryCheckpoint] ON PRIMARY ( NAME = N'InMemoryCheckpoint', FILENAME = N'D:\Data\InMemoryCheckpoint.mdf' , SIZE = 4096KB , FILEGROWTH = 1024KB ) LOG ON ( NAME = N'InMemoryCheckpoint_log', FILENAME = N'D:\Data\InMemoryCheckpoint_log.ldf' , SIZE = 2048KB , FILEGROWTH = 10%) GO ALTER DATABASE InMemoryCheckpoint ADD FILEGROUP InMemoryCheckpoint_FG CONTAINS MEMORY_OPTIMIZED_DATA ALTER DATABASE InMemoryCheckpoint ADD FILE (name='InMemoryCheckpointDF', filename='D:\Data\InMemoryCheckpoint') TO FILEGROUP InMemoryCheckpoint_FG ALTER DATABASE InMemoryCheckpoint SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT=ON GO |
From the Filegroups tab of the Database Properties window, the newly created filegroup can be found under the Memory Optimized Data as shown below:
Another important change that you need to consider, is the InMemoryCheckpoint new system folder specified in the previous ALTER DATABASE statement and created as specified under the “D:\Data” path, with two subfolders that are empty for now. We will proceed to see what will be stored in that folder!

The next step is to create the Memory-Optimized table. The below T-SQL scrip is used to create a new EmployeeWithInMemory Memory-Optimized table, with SCHEMA_AND_DATA durability. This means that the table data is recoverable in the case of database shutdown or crash:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE InMemoryCheckpoint GO CREATE TABLE [dbo].[EmployeesWithInMemory]( [EmpID] [int] NOT NULL CONSTRAINT PK_EmployeesIM_EmpID PRIMARY KEY NONCLUSTERED HASH (EmpID) WITH (BUCKET_COUNT = 100000), [EmpName] [varchar](50) NOT NULL, [EmpAddress] [varchar](50) NOT NULL, [EmpDEPID] [int] NOT NULL, [EmpBirthDay] [datetime] NULL ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) GO |
Once the new table is created successfully, let us have another look to the InMemoryCheckpoint system folder, and browse the subfolders. You will see five “.HKCKP” new files created under the $HKv2 folder with unique identifiers for the files names, as shown below. So, what are these files?
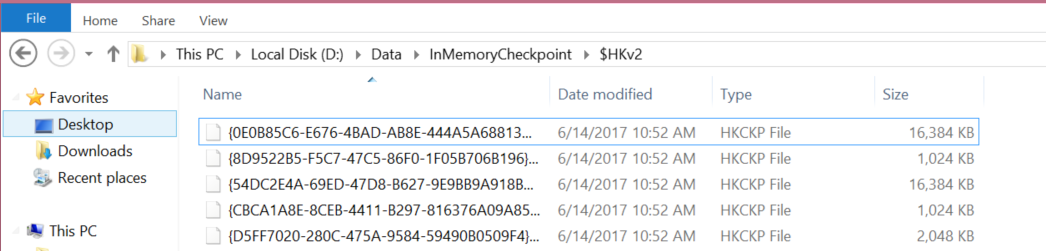
The “.HKCKP” files are physical data and delta Checkpoint File Pair files, also known as CFPs, that are used to keep the data streams resulted from inserting new records into memory-optimized tables and the delta streams that contain references to rows in data files that have been deleted.
Information about these checkpoint files can be displayed by querying the sys.dm_db_xtp_checkpoint_files system object using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT container_id, internal_storage_slot, file_type_desc, state_desc, logical_row_count, lower_bound_tsn, upper_bound_tsn FROM sys.dm_db_xtp_checkpoint_files ORDER BY file_type_desc, state_desc |
The query result in our situation will look as follows:

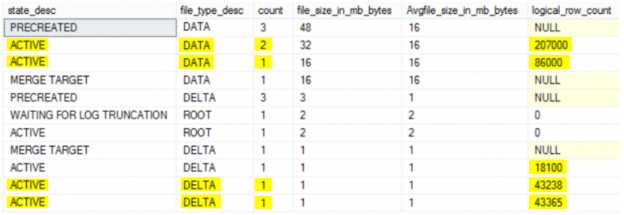
From the previous result, you can see four DATA and DELTA files, where each pair of data and delta files constitutes a Checkpoint File Pair, with two pairs in the previous result. The ROOT files contain system metadata for memory-optimized tables.
Another type of “.HKCKP” files that can be viewed from the sys.dm_db_xtp_checkpoint_files system object are the FREE files, where all files maintained as FREE are available for allocation.
The PRECREATED file state shown in the previous result means that these checkpoint files are pre-allocated to minimize any waits to allocate new files as transactions are being executed. There files with PRECREATED state contain no data. The ACTIVE file state means that the files contain the inserted/deleted rows from previous closed checkpoints, these rows are read into the memory before applying the active part of the transaction log at the database restart.
For huge number of “.HKCKP” files, it is better to have an aggregate view for these files, in which we summarize the files statistics using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT state_desc, file_type_desc, count(state_desc) count, sum(file_size_in_bytes)/(1024*1024) file_size_in_mb_bytes, Avg(file_size_in_bytes)/(1024*1024) Avgfile_size_in_mb_bytes , logical_row_count FROM sys.dm_db_xtp_checkpoint_files GROUP BY state_desc, file_type_desc, logical_row_count ORDER BY file_type_desc |
The aggregate result, with the files count, size and description will be as follows:

To start the backup chain, we will perform a full backup for the database as shown below:
|
1 2 3 4 |
BACKUP DATABASE [InMemoryCheckpoint] TO DISK = N'D:\backupSQL\InMemoryCheckpoint.bak' WITH NOFORMAT GO |
Then we will fill the table with 500K records using ApexSQL Generate, a tool for automatically creating synthetic test data:
After filling the table, the transaction log file is pending log backup. This can be verified from the log_reuse_wait_desc column of the sys.databases object:
|
1 2 3 4 5 6 |
SELECT name, log_reuse_wait_desc FROM sys.databases WHERE name = 'InMemoryCheckpoint' GO |
The log file is waiting for transaction log backup to be truncated as shown below:

The percentage of the transaction log space used can be viewed by the DBCC command below:
|
1 2 3 4 |
DBCC sqlperf(logspace) GO |
You can see that about 91.8% of the transaction log space is consumed:
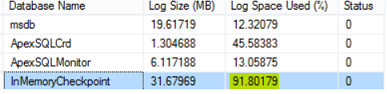
Checking the size of transaction log generated since the last checkpoint and the ID of current checkpoint can be also verified by querying the sys.dm_db_xtp_checkpoint_stats system object as in the T-SQL script below:
|
1 2 3 4 5 6 7 |
SELECT log_bytes_since_last_close /(1024*1024) as Log_bytes_since_last_close_mb, time_since_last_close_in_ms, current_checkpoint_id FROM sys.dm_db_xtp_checkpoint_stats GO |
The result shows that 28MB of transaction log are generated since the last checkpoint, with the current checkpoint ID equal to 2:

After completing the insertion process, let us see what happened to the CFPs files, by running the aggregate T-SQL query again:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT state_desc, file_type_desc, count(state_desc) count, sum(file_size_in_bytes)/(1024*1024) file_size_in_mb_bytes, Avg(file_size_in_bytes)/(1024*1024) Avgfile_size_in_mb_bytes , logical_row_count FROM sys.dm_db_xtp_checkpoint_files GROUP BY state_desc, file_type_desc, logical_row_count ORDER BY file_size_in_mb_bytes desc |
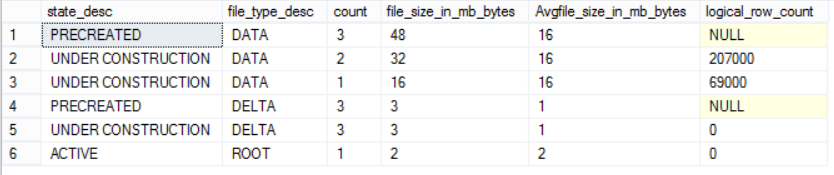
It is clear from the below result, that an additional number of DATA and DELTA files are created after the data insertion process, to which the changes are written, in addition to the logical_row_count that contains the number of rows inserted to the DATA file and the number of deleted rows in the DELTA files. A new file description appears here after filling the table; UNDER CONSTRUCTION, indicating that, these files are being populated based on the log records generated by the database, and not yet part of a checkpoint, as this checkpoint is not closed yet:

Let us perform a transaction log backup again to free up the log file, and see if this will trigger a checkpoint:
|
1 2 3 4 |
BACKUP LOG [InMemoryCheckpoint] TO DISK = N'D:\backupSQL\InMemoryCheckpoint.trn' WITH NOFORMAT GO |
Verifying the log_reuse_wait_desc column of the sys.databases object again:
|
1 2 3 4 5 6 |
SELECT name, log_reuse_wait_desc FROM sys.databases WHERE name = 'InMemoryCheckpoint' GO |
The transaction log file is waiting for nothing now:

Anything changed in the CFPs files? Let us run the aggregate T-SQL query again:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT state_desc, file_type_desc, count(state_desc) count, sum(file_size_in_bytes)/(1024*1024) file_size_in_mb_bytes, Avg(file_size_in_bytes)/(1024*1024) Avgfile_size_in_mb_bytes , logical_row_count FROM sys.dm_db_xtp_checkpoint_files GROUP BY state_desc, file_type_desc, logical_row_count ORDER BY file_size_in_mb_bytes desc |
Nothing changed in the CFPs files from the previous result, as the transaction log backup did not trigger any checkpoint:
The checkpoint will be closed automatically when there is sufficient transaction log growth since the last checkpoint, which is 1.5GB for the Memory-Optimized tables, or if you issue the CHECKPOINT command.
Let us run the below delete statement that will delete about 100K records from the Memory-Optimized table:
|
1 2 3 4 5 |
DELETE FROM [EmployeesWithInMemory] WHERE [EmpID] < 448758456; GO |
Moreover, see the size of log that will be used until the current checkpoint using the sys.dm_db_xtp_checkpoint_stats system object:
|
1 2 3 4 5 6 7 |
SELECT log_bytes_since_last_close /(1024*1024) as Log_bytes_since_last_close_mb, time_since_last_close_in_ms, current_checkpoint_id FROM sys.dm_db_xtp_checkpoint_stats GO |
Only 31MB of transaction log is used until the current checkpoint, which will not trigger the checkpoint:

Although we consumed 99% of the transaction log file size, the checkpoint will not be closed:
|
1 2 3 4 |
DBCC sqlperf(logspace) GO |
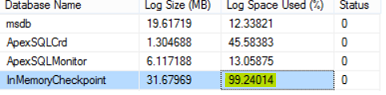
We will not wait for the automatic checkpoint to be triggered. Let us run it manually by executing the CHECKPOINT command below:
|
1 2 3 4 |
CHECKPOINT GO |
The previous checkpoint with ID equal to 2 was closed and the current checkpoint ID is 3 now, with only 3 MB of the transaction log used only:
|
1 2 3 4 5 6 7 |
SELECT log_bytes_since_last_close /(1024*1024) as Log_bytes_since_last_close_mb, time_since_last_close_in_ms, current_checkpoint_id FROM sys.dm_db_xtp_checkpoint_stats GO |

Closing the checkpoint should flush the data and delta streams to the DATA and DELTA files. Verifying the CFPs files:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT state_desc, file_type_desc, count(state_desc) count, sum(file_size_in_bytes)/(1024*1024) file_size_in_mb_bytes, Avg(file_size_in_bytes)/(1024*1024) Avgfile_size_in_mb_bytes , logical_row_count FROM sys.dm_db_xtp_checkpoint_files GROUP BY state_desc, file_type_desc, logical_row_count ORDER BY file_size_in_mb_bytes desc |
The state of the DATA files that contain the inserted records and the DELTA files that contain the deleted records, with UNDER CONSTRUCTION previous state, is ACTIVE now after closing the checkpoint as shown below:
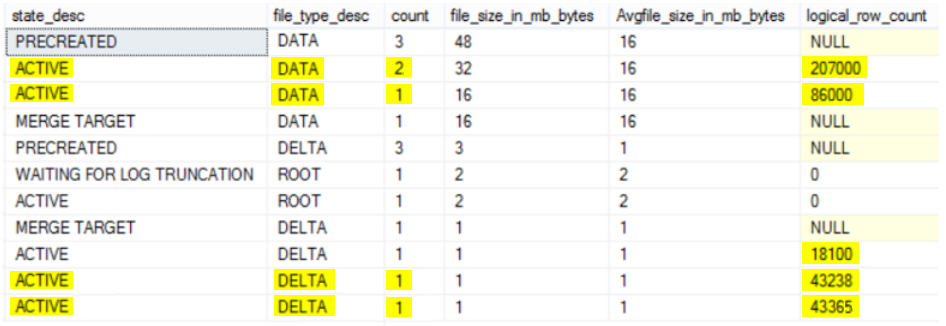
From the previous result, the files with MERGE TARGET state store the consolidated data rows from the source files that were identified by the merge policy. Once the merge is fully installed, the MERGE TARGET file state becomes ACTIVE. This merge process is performed to prevent the files from growing indefinitely. The Merge Source checkpoint file state changes to WAITING FOR LOG TRUNCATION once the merge has been installed. Files in this state are required mainly for operational correctness of the database with memory-optimized table, such as recovering from a durable checkpoint to go back in time.
Having the recovery model of the database is FULL, the transaction log will not be truncated unless we perform a transaction log backup after the checkpoint:
|
1 2 3 4 |
BACKUP LOG [InMemoryCheckpoint] TO DISK = N'D:\backupSQL\InMemoryCheckpoint.trn' WITH NOFORMAT GO |
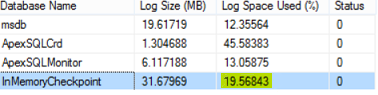
Checking the transaction log space used, only 19% of the log file is used after the transaction log truncation:
|
1 2 3 4 |
DBCC sqlperf(logspace) GO |
In the case of a crash, the DATA and DELTA files will be used to recover the Memory-Optimized tables by scanning and loading these files to the memory, where the deleted rows from the DELTA files will be removed from the active DATA files, and the remaining active rows will be inserted. The recovery process can be run in multiple threads; with each thread will work on a DATA/DELTA files pair. After loading the data completely, the log tail will be replayed in order to bring the database online back.
Conclusion
The checkpoint is a special background process that is responsible for reducing the time required to recover the database in the event of crash, where it writes the dirty pages in memory to the data files, so that there is no need to apply these changes in the event of failure by the SQL Engine.
The Memory-Optimized table checkpoint differs from the disk-based table checkpoint in many aspects. For the disk-based table, the Write-Ahead Logging protocol is used to flush the dirty pages to the database files and triggered based on the recovery interval configuration option value.
For the durable Memory-Optimized table, the checkpoint flushes the data streams that contain all new inserted data to the data files and the delta streams that contain all deleted data to the delta files. The Memory-Optimized table checkpoint will be triggered when the database transaction log file becomes bigger than 1.5 GB since the last checkpoint.
We saw also reviewed, in practical terms, within this article’s demo how the checkpoint behaves in different situations.
The previous article in this series

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021