
In sequence of the first article about the server memory importance, we will check another In-Memory OLTP key point: The Checkpoint files. Check what wrong can happen, and how to avoid this!
In continuation to the previous article about the three key points to monitor on In-Memory OLTP, where we talked about the server memory and its (obvious) importance, we will check now the second key point of In-Memory OLTP: The Checkpoint Files!
If you start reading this series of three articles from this article, I recommend you to check the previous one and the last one (when available). All the explored three key points are summarily important to the In-Memory OLTP health, and also for all the other instance components.
Case #2: Checkpoint Files
One of the new concepts that In-Memory OLTP brought to SQL Server, were the checkpoint files. In order to support those kind of files, we have a new Filegroup flavor, specific for memory optimized data.
This “new flavor” is based on FILESTREAM and it’s basically a container of checkpoint files.
But what are checkpoint files?
The mission of the checkpoint files is store all the needed information to recreate the rows of data on memory-optimized tables. This way, in case of a crash or a voluntary server restart, SQL Server will be able to keep the data.
When you create a memory-optimized table, you have two choices: persistent tables and non-persistent tables. The checkpoint files are only applicable for the persisted ones.
We talk about checkpoint files, but in the reality the checkpoint files are a pair of two distinct files:
- Data file
- Delta file
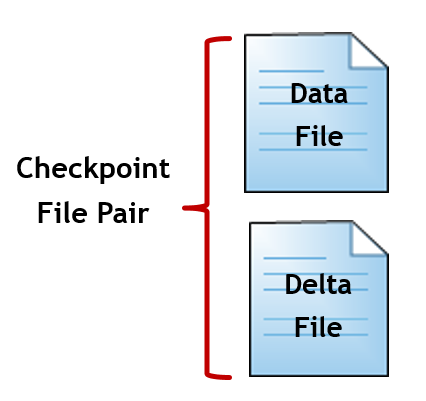
Those files are paired by the same timestamp, recording the activity of a defined range of time.
The data file stores all the inserted rows. An UPDATE command is also writing to the data files, as an update is nothing more than a DELETE (hiding the row from the “table scope” followed by an INSERT.
The delta file has always data file as its pair and stores de ID of deleted rows. This way, “summing up” the data and delta file we will be able to achieve the latest table state.
As you can imagine, after some a memory-optimized table will be target of various INSERTS, UPDATES and DELETES, making the checkpoint files grow, and grow…As the data file is just writing the inserted data and not removing what was deleted, its size will only grow! The same happen with the delta file. All the deleted rows, generated by DELETES and UPDATES, are being tracked and the tendency is just grow, and grow…
Merge Process
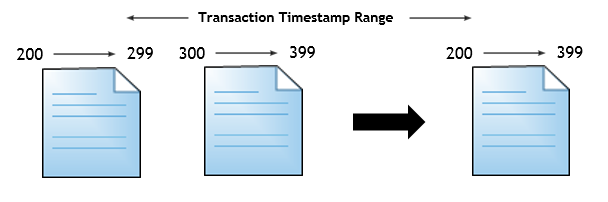
At certain point, a data file will have most of its data invalidated by the delta file. In order to avoid an enormous number of checkpoint files in the disk as well as waste of space storing invalid data, SQL Server has process called “Merge”.
What the Merge Process does? Basically it will select two contiguous (based on timestamp sequence) checkpoint files, remove all the invalid information from the data file, based on its paired delta file, and then it merges de valid data, generating a brand new checkpoint file, which will reflect the same time range covered by the original ones. The bellow image is showing a visual example of what is done.
What is the big problem here? The disk! Yes, even using memory optimized tables we are still hostage of the disk, when we are talking about persisted tables. There are two possible situations here that we need to keep the heads up:
- Disk performance.
- Free space.
Both are much known from any SQL Server DBA, and usually we are caring about that…But what really happens when there is no space for the checkpoint files growth?
I tested this, and was surprised with the final result. So, what I did was:
- Created a database with memory-optimized tables.
- Created a huge file in the same disk as the container of checkpoint files is set, using the following command:
fsutil file createnew E:\Data\DummyFile.txt 18307298099 - Started loading data into the memory-optimized table.
As a result of this test, I was expecting for some behavior comparable to the “full transaction log in a full disk”, that we sometimes see around there… But not!
As expected, the transactions started to fail, and for my surprise, the entire database was in “recovery” state. The way I found to make it work again, was free up some disk space (I just deleted the dummy file) and took the database “offline“ and right after to “online” state. This way everything started to work again.
The main point here is that even if you have a database mixing memory-optimized tables with traditional tables, no matter if you have space for you MDF, NDF and LDF files, the database is going to stop! So it’s a very critical situation where we need to take care and never relax. Remember that with a low percentage of free disk space you risk that an “out-of-normal” insert, loading more data than usual, can cause your database to be unresponsive, of course, reflecting in the application unavailability and all the “snow ball” kind flow that comes on those situations.
In order to monitor this situation, I created a PowerShell script, which is going to watch the free space in the disk, as follows:

This job returns an error message if the minimum free space threshold is not being achieved.
The presented solution, is following the idea of the ones presented in the previous article. You can create a job, with the provided code, and add an operator, who is going to be alerted in case of a job failure. I suggest to run this job on every five minutes.
As said before, the disk monitoring is something that we are used to do. However, more than try to show how to monitor the free disk space, I wanted to show the effects of not have enough free space in the disk hosting the memory-optimized table’s container.
I hope it was useful! See you in the next article, talking about the remaining key point: the BUCKET NUMBER.

With experience working in Portugal, Holland, Germany and United Kingdom, he's always available to learn and share his knowledge, in order to contribute to SQL Server community,
View all posts by Murilo Miranda
- Understanding backups on AlwaysOn Availability Groups – Part 2 - December 3, 2015
- Understanding backups on AlwaysOn Availability Groups – Part 1 - November 30, 2015
- AlwaysOn Availability Groups – Curiosities to make your job easier – Part 4 - October 13, 2015