
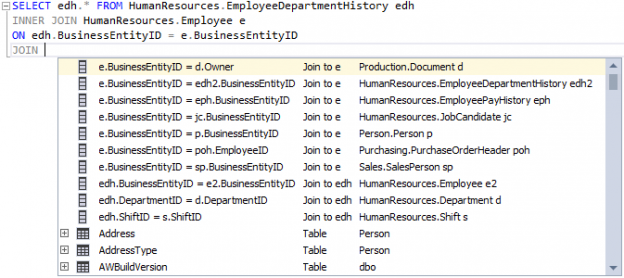
A SQL Join clause is put within a Select statement and at the end, it’s given a join condition, which tells the database how to fetch your data. The column specified within the join condition must be preceded by a table name if the column name is the same in both tables. When a column is preceded with a table name, it’s known as a qualified column.
In other words, joining is the process of taking data from multiple tables and putting it into one generated result set. This article will be pretty basic and hopefully easy to follow because the goal here is to fully grasp the idea of SQL joins.
Joins are a complex subject, and some find them confusing and tricky. Because of that, let’s see the concept of retrieving data from multiple tables rather than just diving into all different types of joins. Some might not even know what a join is or maybe you’ve been writing queries involving a single table. But now you need information from more than one table. Either way, you’re in the right place. So, thank you for joining us (see what we did there) and let’s begin.
Data can be structured in a database in a confusing no user-friendly way and we basically use SQL joins to present it in the opposite. Now, this is done in a way, so we can store our data in a database that is the best structured to where we protect our data integrity and it’s normalized, separated across tables with the proper relationships, data types, keys, indexes, etc. When we actually want to output that data, e.g. on a web page, or within an application, or to another person we need the results to be organized and structured, so it makes sense to us. That’s a purpose of SQL Joins, it takes a mess and puts it out in a way that looks beautiful and this can be done over multiple tables.
- Note: To automatically complete SQL statements, such as Join clause or cross-database queries, in a single click check out a free SQL Server Management Studio and Visual Studio add-in.
For example, let’s say that we have three different tables with relationships between them:
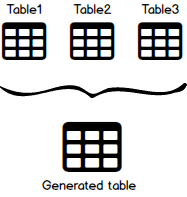
We don’t need any specifics of what kind of tables, data we are dealing with but basically, the SQL Join will take all of this (Table1, Table2, Table3) and it’s going to present us with a generated table that is more pretty, structured, user-friendly and it makes more sense to us.
Now, the way this is done is by using foreign and primary key connections. So, these tables are going to have relationships between them, as shown below, this is known as a foreign key connection that references a primary key:

In other words, one of these tables is the parent and another one is the child and we want the end result to combine them into one generated table as shown above.
The relationship that is used within the SQL Join condition is often already defined in the database (usually foreign key/primary key connection) but it doesn’t have to be. If it’s not already in the database, it’s known as an ad hoc relationship.
You should know that when we do this, these columns that are connected are going to be indexed to make data joining faster. This is another complex subject and we highly recommend that you check out articles below associated with indexes that speed up retrieval of rows from the table or view:
- How to identify and solve SQL Server index scan problems
- How to optimize SQL Server query performance – Statistics, Joins and Index Tuning
- How to create and optimize SQL Server indexes for better performance
- Top things you need in a SQL Server query plan analysis tool
Moving on, when we are joining tables it’s a common practice to replace the columns names with more user-friendly names. For example, let’s say that we got a comment on a website, it says “This article is awesome!”, and it’s posted by a reader named ”Michael“:

This username on a website is probably a user ID in a comment table. So, let’s say we have two tables: Users table and Comments table and there’s a foreign key from the User ID referencing the User ID in the Users table:
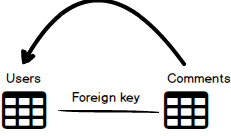
Well, when we present that data on a database we will want to replace that user ID with the actual username. Otherwise, we could end up with a user that’s named ”4523“ and nobody would know who that is. Since all of this information is within the Comments table, we can just take the information from the Users table and put that username instead of the user ID.
This is how SQL Join works conceptually. We have to think conceptually because it’s important to understand that this article should only be helping you understand the concepts of a different kind of SQL Joins. This is why we got these mockup examples instead of writing actual queries. Also because joins are done differently from a database management system to a database management system. All you need to know is how the joins work and the expected results. Then, when you start working with MySQL, SQL Server, Oracle database, etc. hopefully you’ll be able to just figure out how to do their joins. Ultimately, the most important thing when it comes to joins is to know beforehand what the results are going to be because if you understand the joins then you’ll be able to just type it out.
Bear in mind that all of this is data manipulation language (DML). This is different from data definition language or data description language (DDL). These are two parts of the SQL concept and when dealing with SQL Joins, it’s important to know that we already have the definition of a database. This simply means that the database might already have been designed and structured with the column and rows but now, we’re manipulating that data to look a certain way. So, by quering data using joins you’re not actually changing the structure of the database itself. You’re just changing the presentation of that database.
Joining data from multiple tables depends a lot on database design. A database can be structured to have a friendly design but in reality, it doesn’t work because it’s not normalized, there’s repeating data, etc. A simple example is a table called ”Comments“:

Let’s say inside this table we got three comments by the username”Michael”.
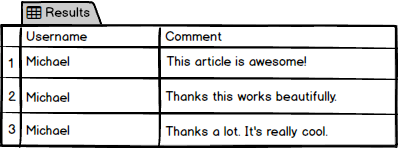
If you show this to someone who is not familiar with databases, he or she will probably say that user Michael posted a comment “This article is awesome!”. The same user posted another comment and so on. You get the point. But this isn’t the best way to store data because of data integrity and also repeating data that we mentioned above. In this artificial example, we got the same username three times. The best practice here would be to use a user ID and get rid of the “Username” and “Michael” and have something like this so we can apply the SQL Join logic:
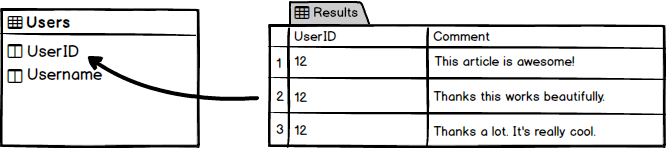
Here we simply have a Users table with the ”UserID“ column which has all of our user IDs for each individual person. So we started off with this friendly design but in reality, it does not work because it’s not normalized, there’s repeating data, etc. The only con in this case it that it looks pretty. Once we have that, we can break it up and normalize it so that we have two tables.
Next thing we got to do is to take up those pieces of the puzzle and put them back together in a SQL Join to get the final result. We basically want to replicate the original table we had before by using joins of our normalized database and recreate it. This UserID 12 in the ”Comments” table will be connected with the UserID 12 in the ”Users“ table which is assotiated with the name ”Michael”.
There are a couple different kinds of SQL Joins like: inner joins, outer joins, cross joins, etc. and we’d highly recommend that you check out detailed articles below that covers not only basics but also shows actual examples of data retrieval:

He has written extensively on both the SQL Shack and the ApexSQL Solution Center, on topics ranging from client technologies like 4K resolution and theming, error handling to index strategies, and performance monitoring.
Bojan works at ApexSQL in Nis, Serbia as an integral part of the team focusing on designing, developing, and testing the next generation of database tools including MySQL and SQL Server, and both stand-alone tools and integrations into Visual Studio, SSMS, and VSCode.
See more about Bojan at LinkedIn
View all posts by Bojan Petrovic
- Visual Studio Code for MySQL and MariaDB development - August 13, 2020
- SQL UPDATE syntax explained - July 10, 2020
- CREATE VIEW SQL: Working with indexed views in SQL Server - March 24, 2020