
This article will help you process file sets with U-SQL in Azure Data Lake Analytics.
Introduction
In the previous articles, we learned how to create database objects in Azure Data Lake Analytics using U-SQL. We also looked at some of the frequently used DDL and DML commands. So far, we have learned different aspects of Azure Data Lake Analytics and U-SQL using a single file stored in Azure Data Lake Storage as the source data. In real-world scenarios, often there are tens to thousands of files that are stored on the data lake storage, and the same must be processed in parallel based on specific criteria. Considering Azure Data Lake Storage forms the storage layer of a data lake in Azure, massive volumes of data hosted in different types of files are expected to be stored and processed. We will understand how to process this data using U-SQL in this article.
Processing file sets using U-SQL
In the previous parts of this Azure Data Lake Analytics series, we installed Visual Studio Data Tools and set up a sample U-SQL application that has a few sample scripts as well as sample data. To proceed with the rest of the steps explained in this article, one would need this setup on their local machine. It’s assumed that this setup is in place.
Navigate to the solution explorer window and expand the TestData as shown below. You would be able to see the sample data files. The files starting with the term “vehicle” are the series of files that resemble the types of files that typically exist in production environments. These files are classified by numbers and dates. We already installed sample data on the Azure Data Lake Storage account in the previous parts of this series, so the data visible below exists in the same folder hierarchy on our Azure Data Lake account as well.
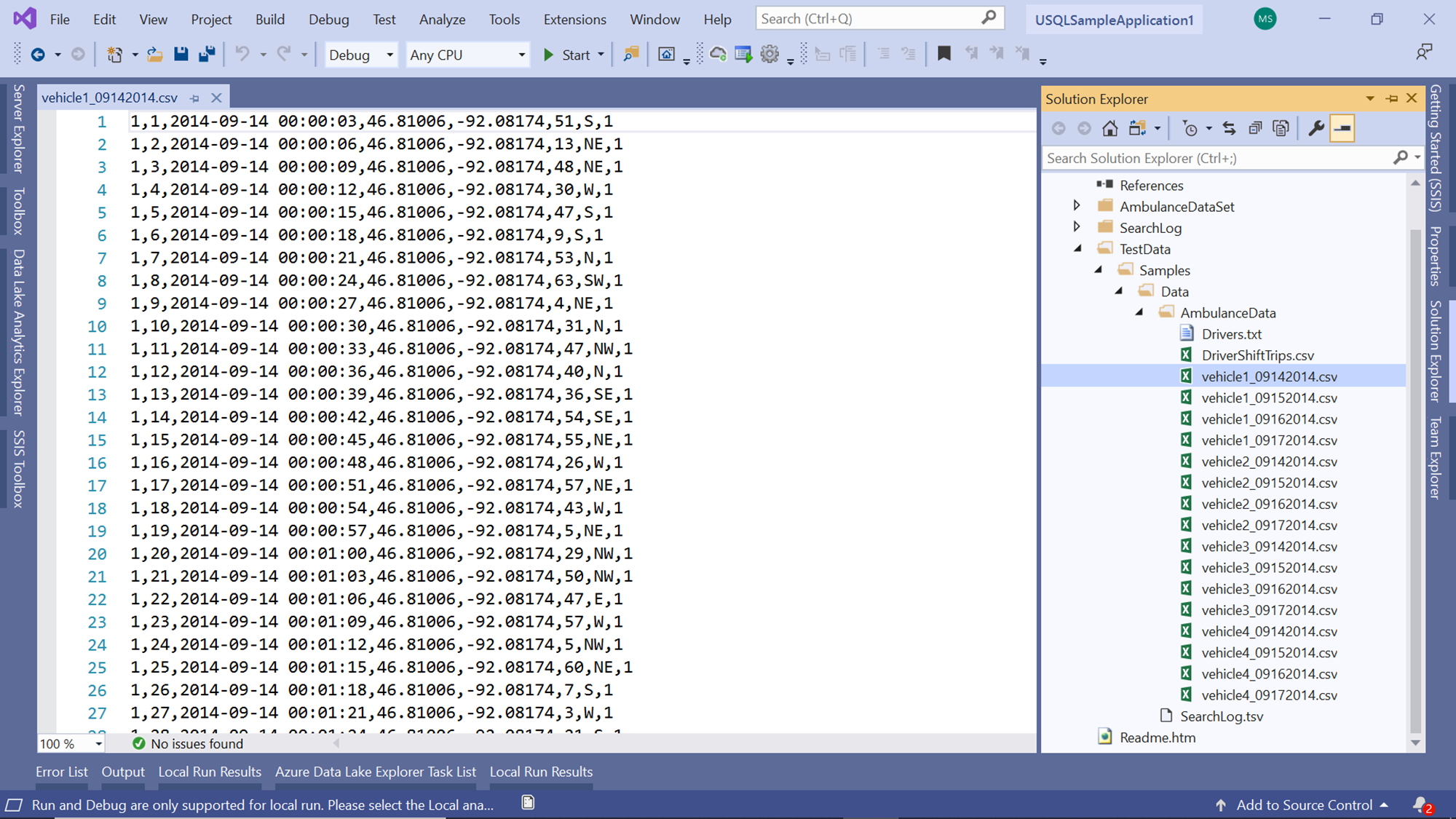
If you open any one of the files, you would be able to see the schema and data as shown below. These files are in CSV format, and contains a few fields and a reasonable number of records as well.
If you open the same file using Azure Data Lake Explorer, you would be able to preview the data in a more formatted manner. Navigate back to the solution explorer window and open the script titled Ambulance-3-1-FileSets as shown below. This script contains the U-SQL code that would process the data in these vehicle-related files.
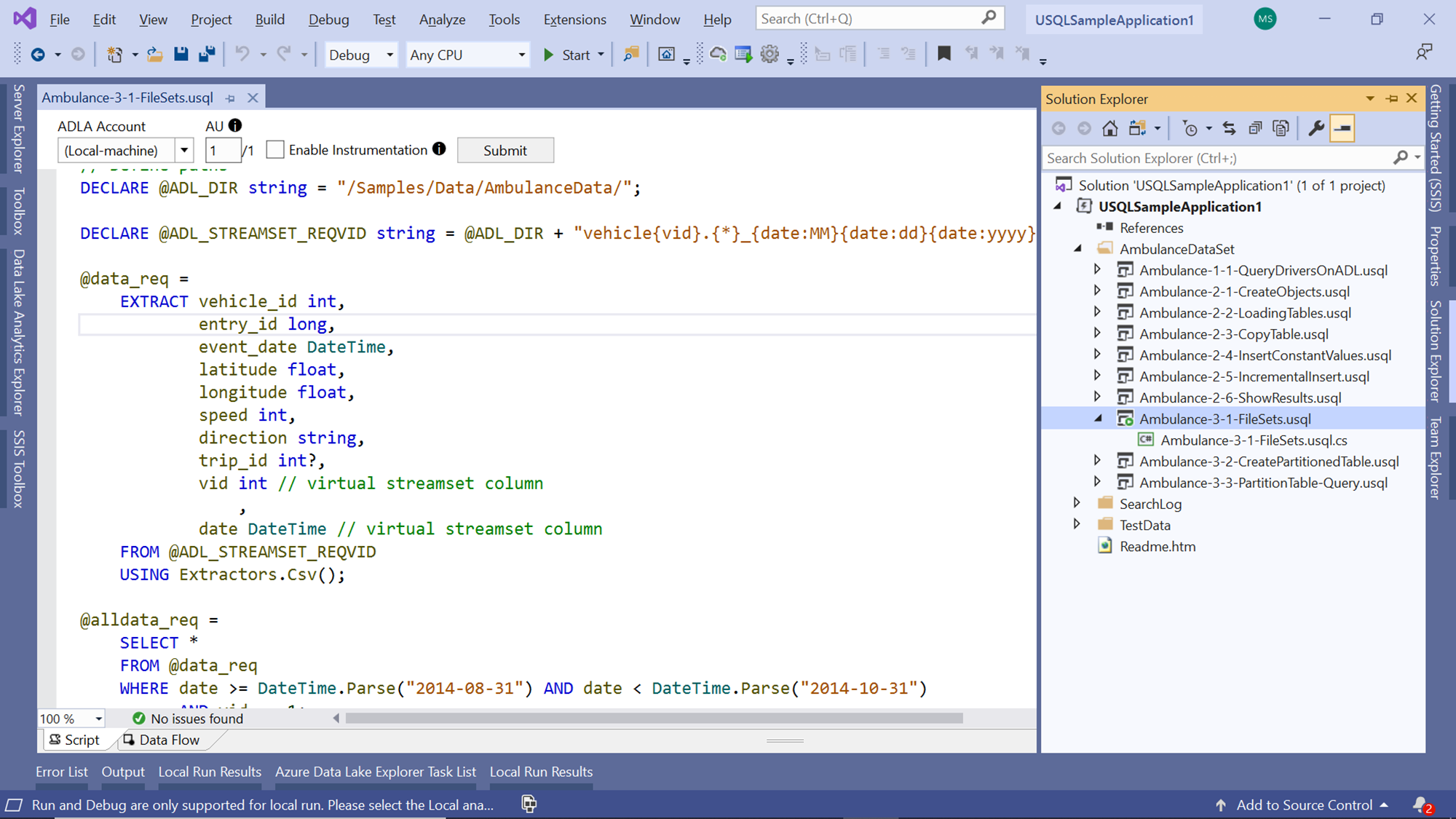
Let’s attempt to understand this U-SQL script step-by-step.
- The first step sets the path where these files are stored on the Azure Data Lake Storage account
- In the next step, we are forming the path to the file set from which we intend to extract data. We intend to be able to select the files based on the desired criteria. So, we need to specify the metadata in the file using a regular expression. This expression is defined by literals – “vehicle”, virtual streamset fields “vid” where we want to specify criteria, and regular expressions like “{*}”. The virtual fields can be thought of as parameters
- In the next step, we are extracting data from the vehicle files. Here the FROM clause used the variable the has the path to those files
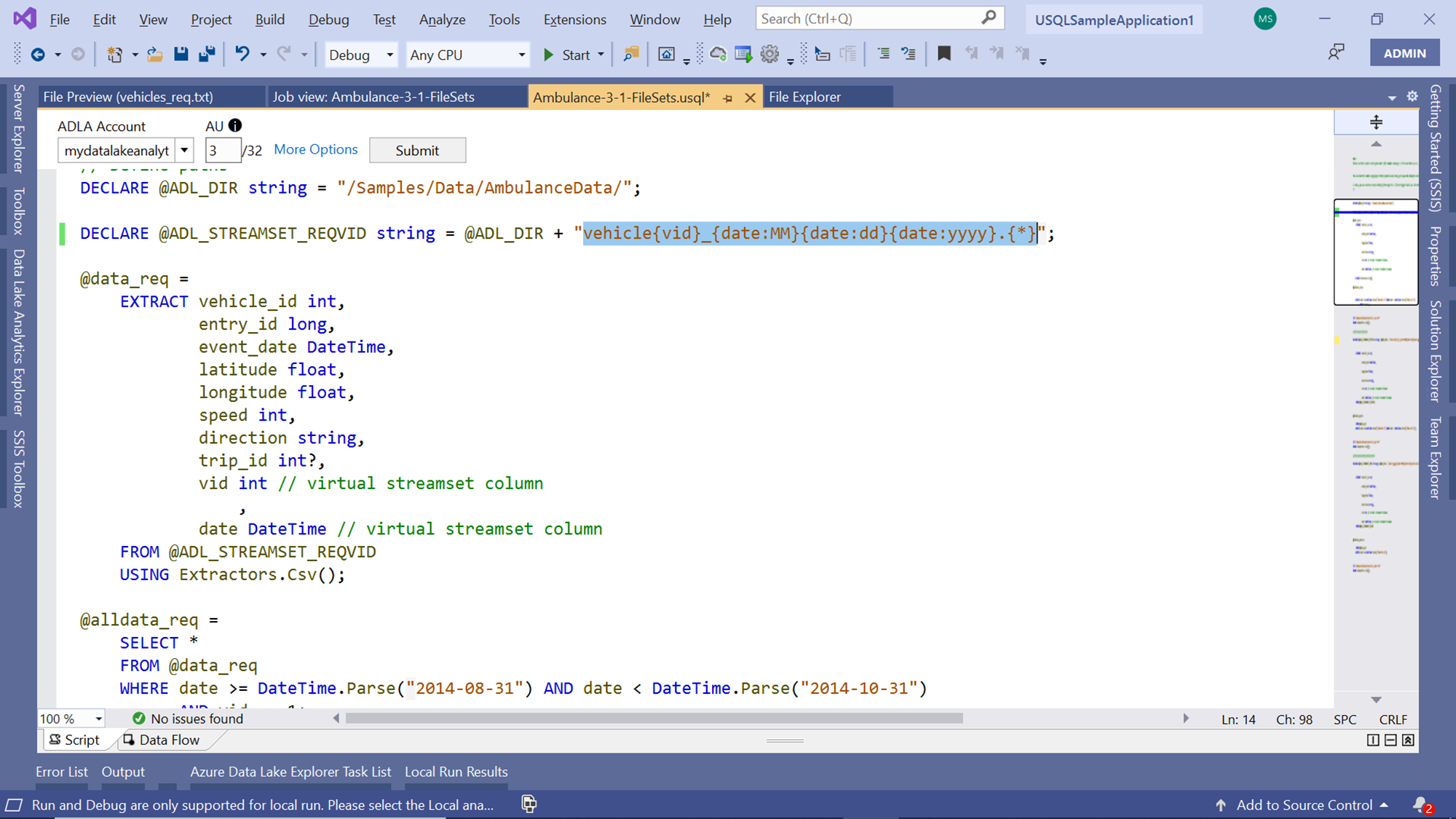
In the next step, we are filtering and selecting the extracted data based on a filter criterion. We have specified predicate to select where vid is equal to filter files based on a vid and date range. If you analyze the names of files, you would find four files that have the value of “vehicle1” as the name of the file. So only those files will be selected. And then the date range also will be applied.
After the files are selected, all the data from these files is read, and the consolidated output from these files is written to a single file using the OUTPUT command as shown below:
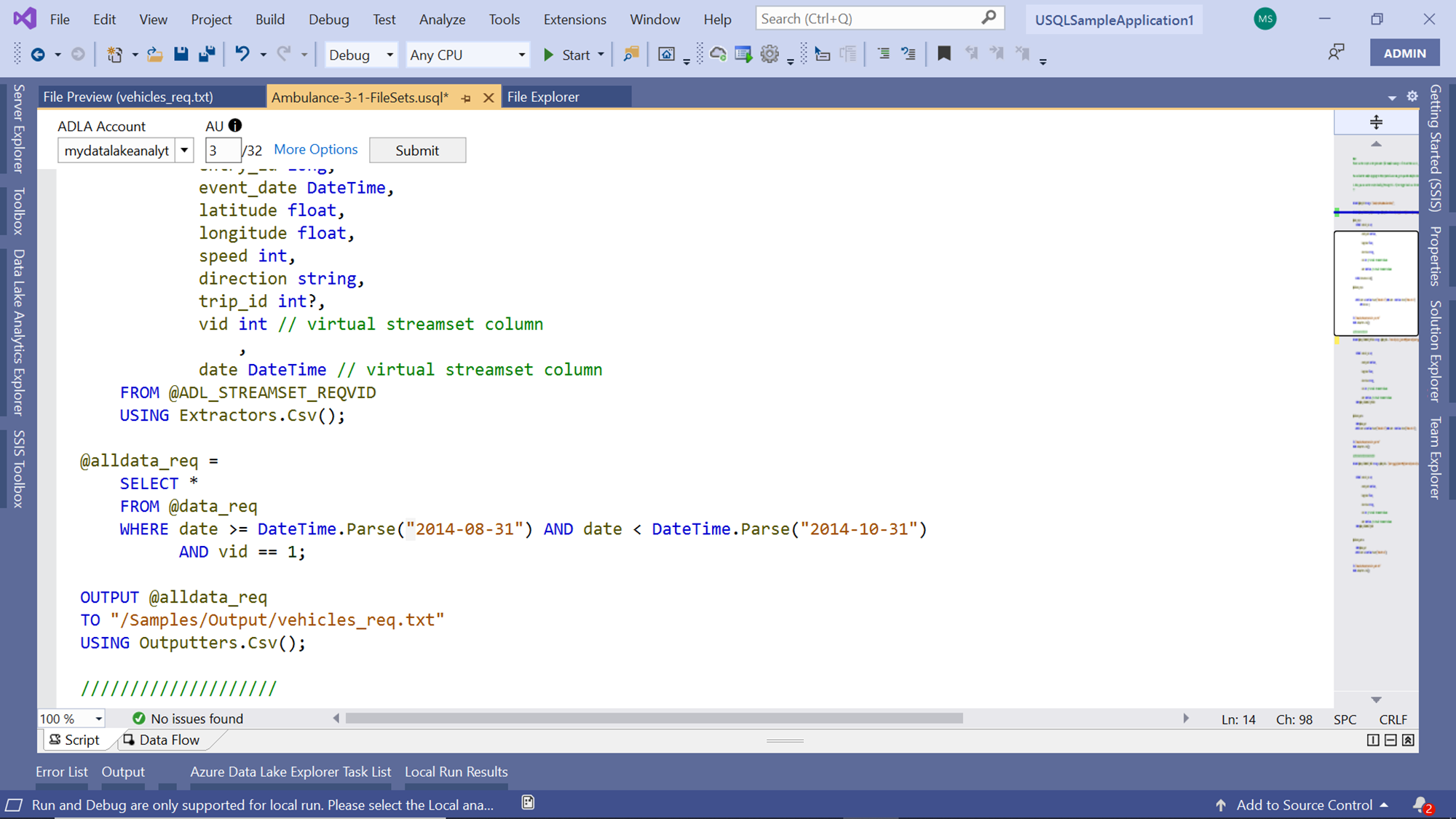
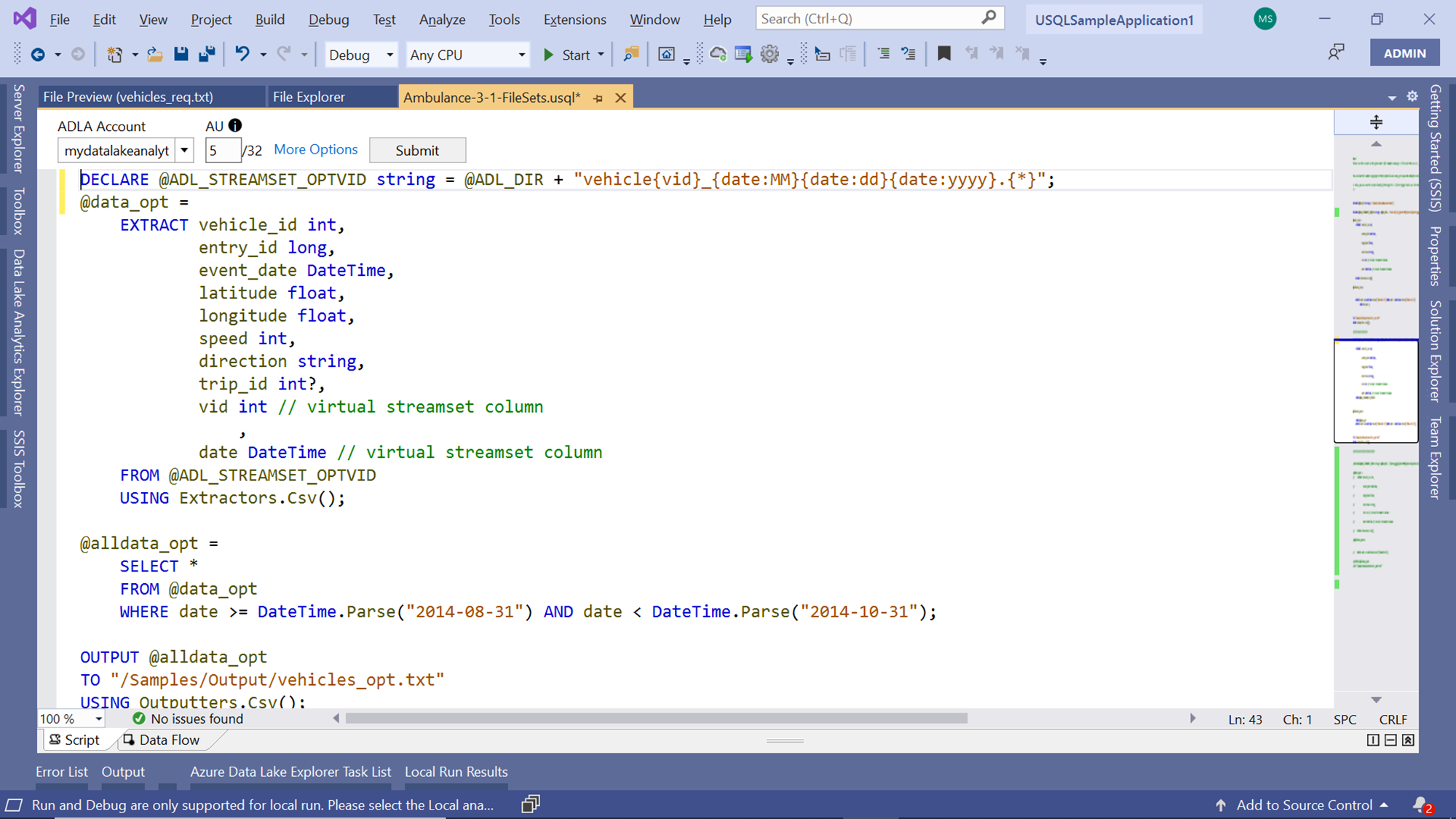
If you scroll down a little, you would find another similar script that has the exact same flow, with the only difference that the SELECT statement does not have a criterion on the vid, but only on the date range. And this data range is broad enough to accommodate all the files that have in the sample data. So, this will result in the selection of all the 16 files we have in our file set. We will focus on these two scripts, so you can comment on the rest of the script which has a similar criterion.
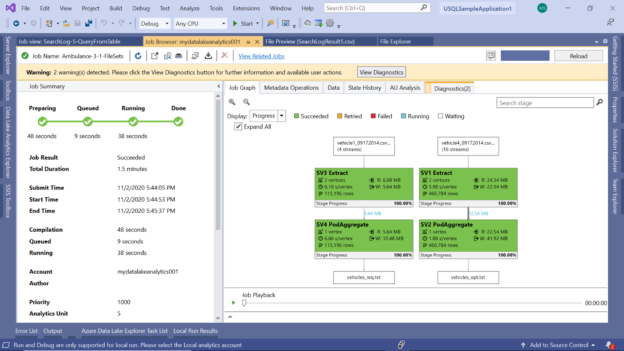
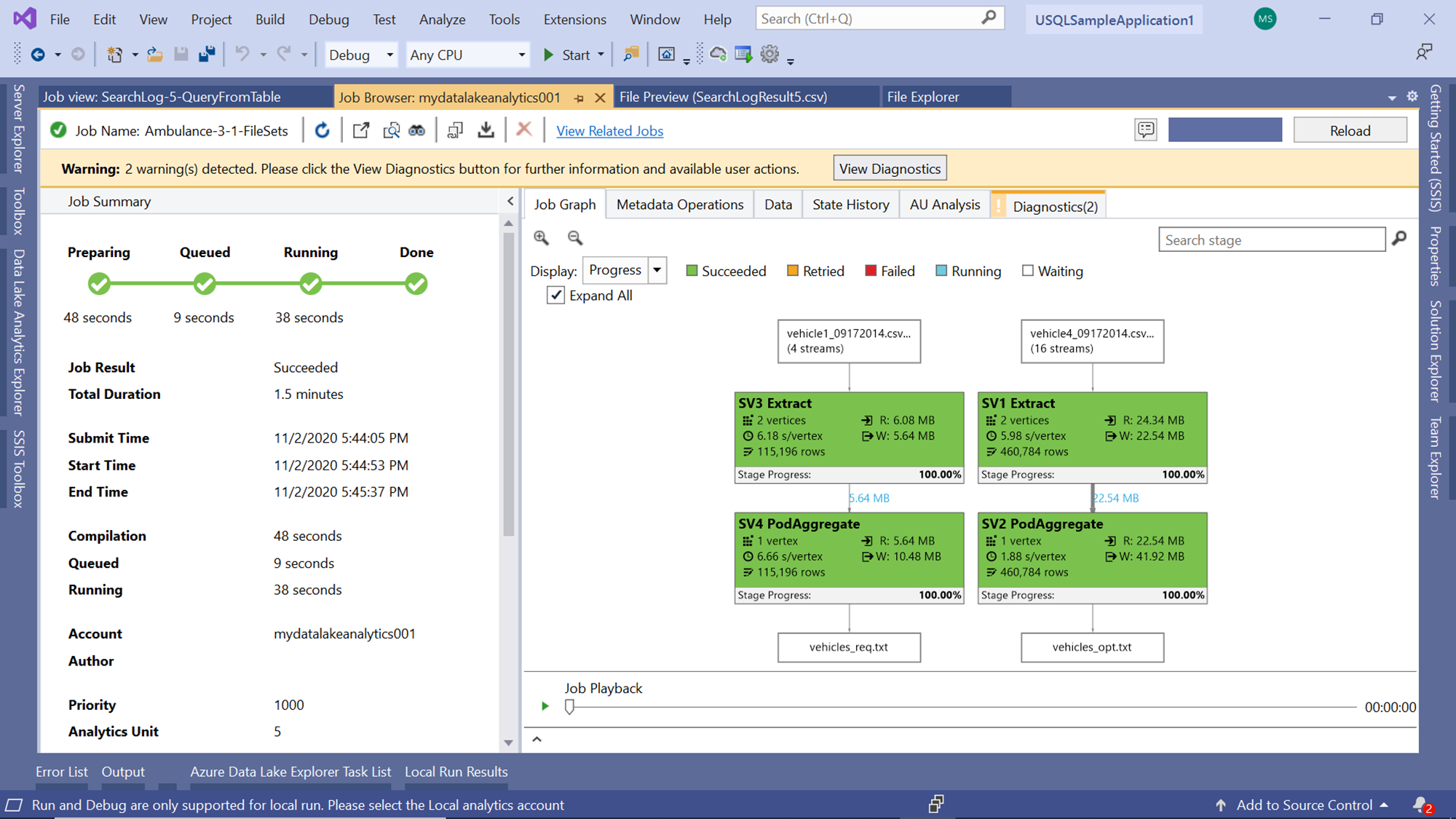
Start the execution of this script, and you would find the job graph as shown below. If you carefully observe the job graph, you would find that there are two streams of input and output. When a script is large and involves multiple steps, the job graph combines all of them and shows a consolidated view.
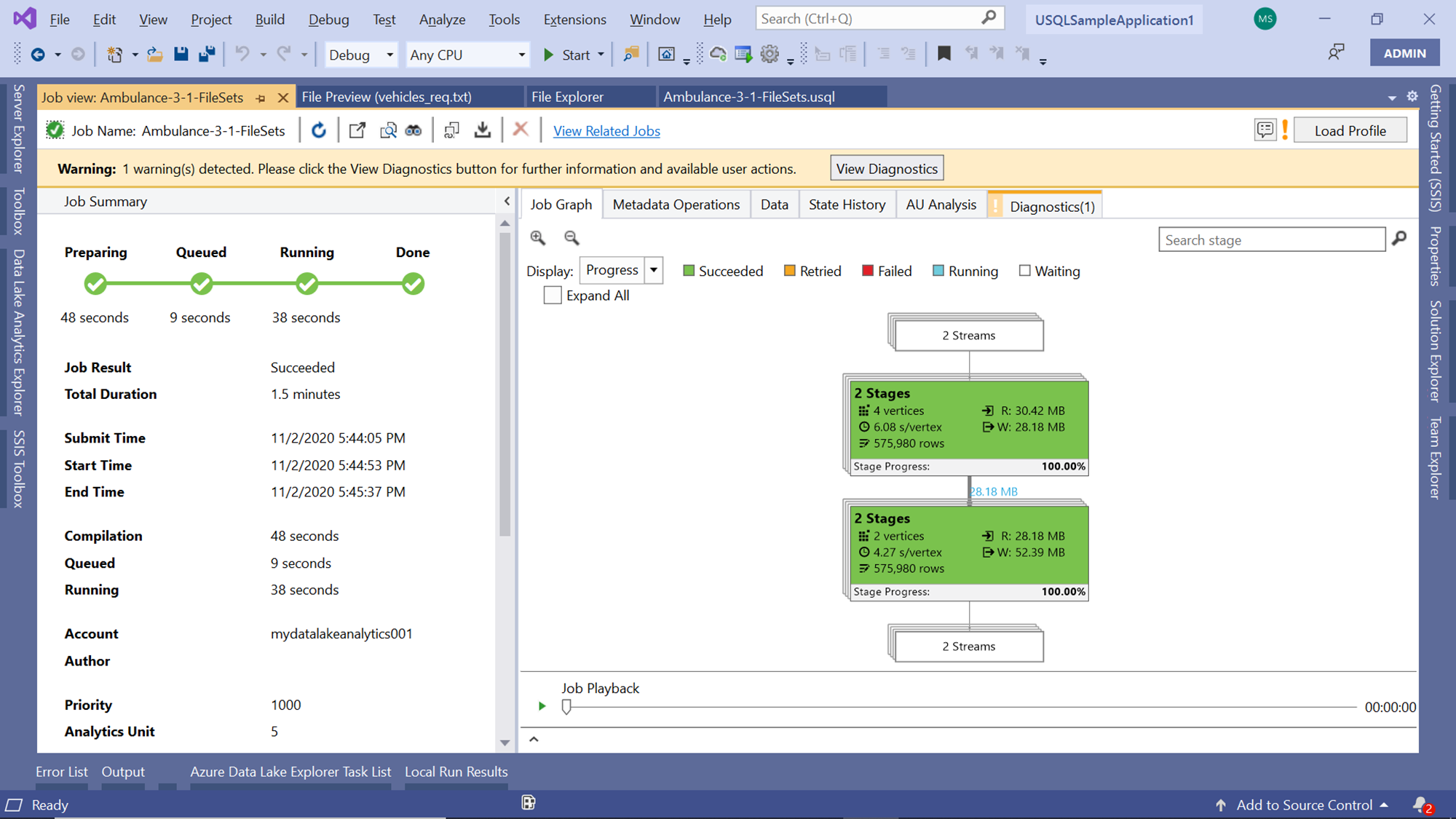
At times one may want to analyze these steps separately to monitor each step. Click on the Expand All checkbox to view them separately. Now it’s easier to read the details of both the parts of this job. The first part results in the selection of four streams and the second one resulted in the selection of 16 streams. Each stream here is a file. All the data from these files were read and written to an output file. The first job wrote the data to a file named vehicles_req.txt and the second one wrote the data to a file named vehicles_out.txt.
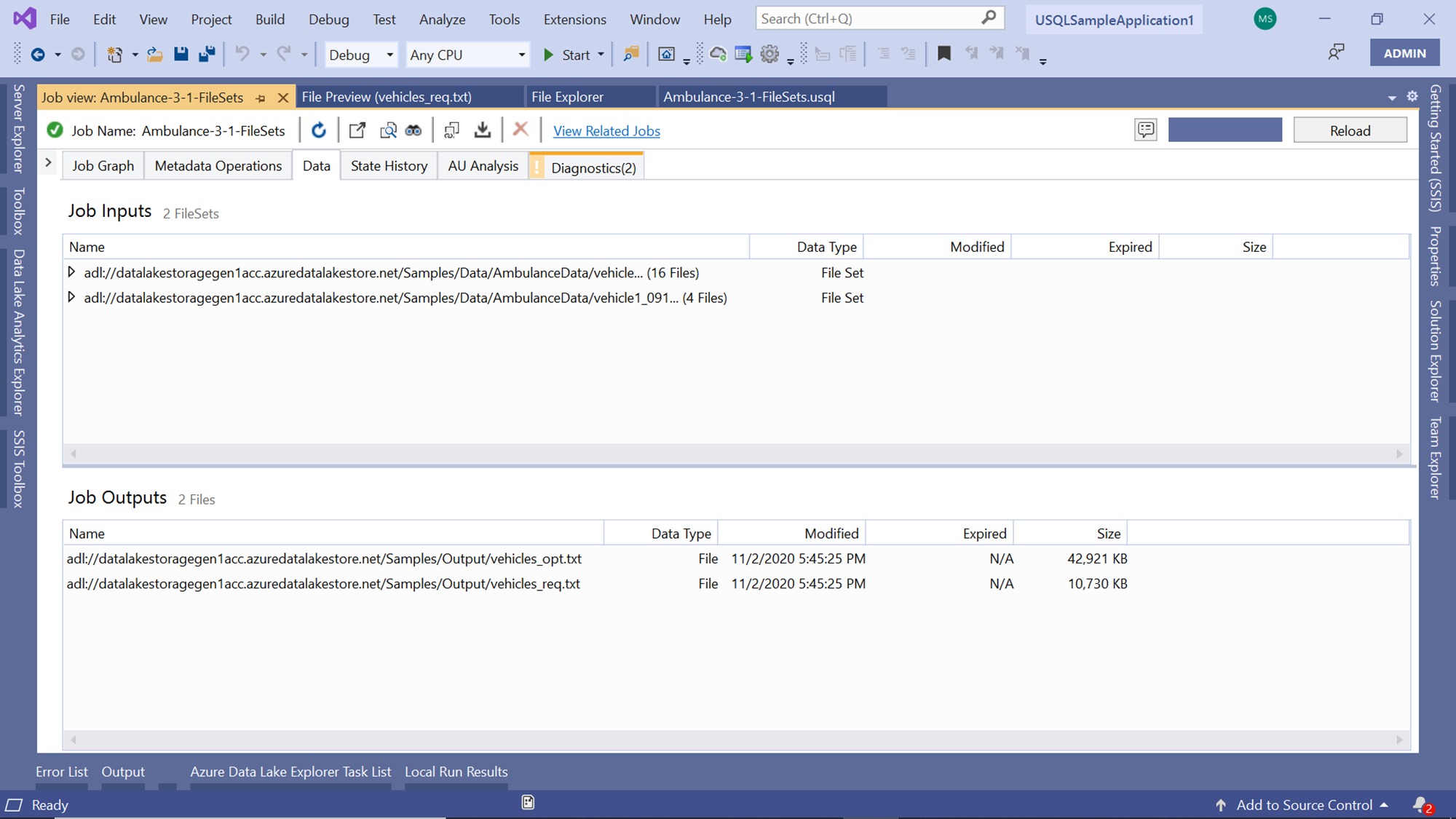
Click on the Data tab to view the details of the input and output files. This view would show the same detail about the files that we saw in the job graph as shown below. Here we can see the file path as well as the size of the files. One of the files is approximately 43 MB in size and another one is approximately 11 MB.
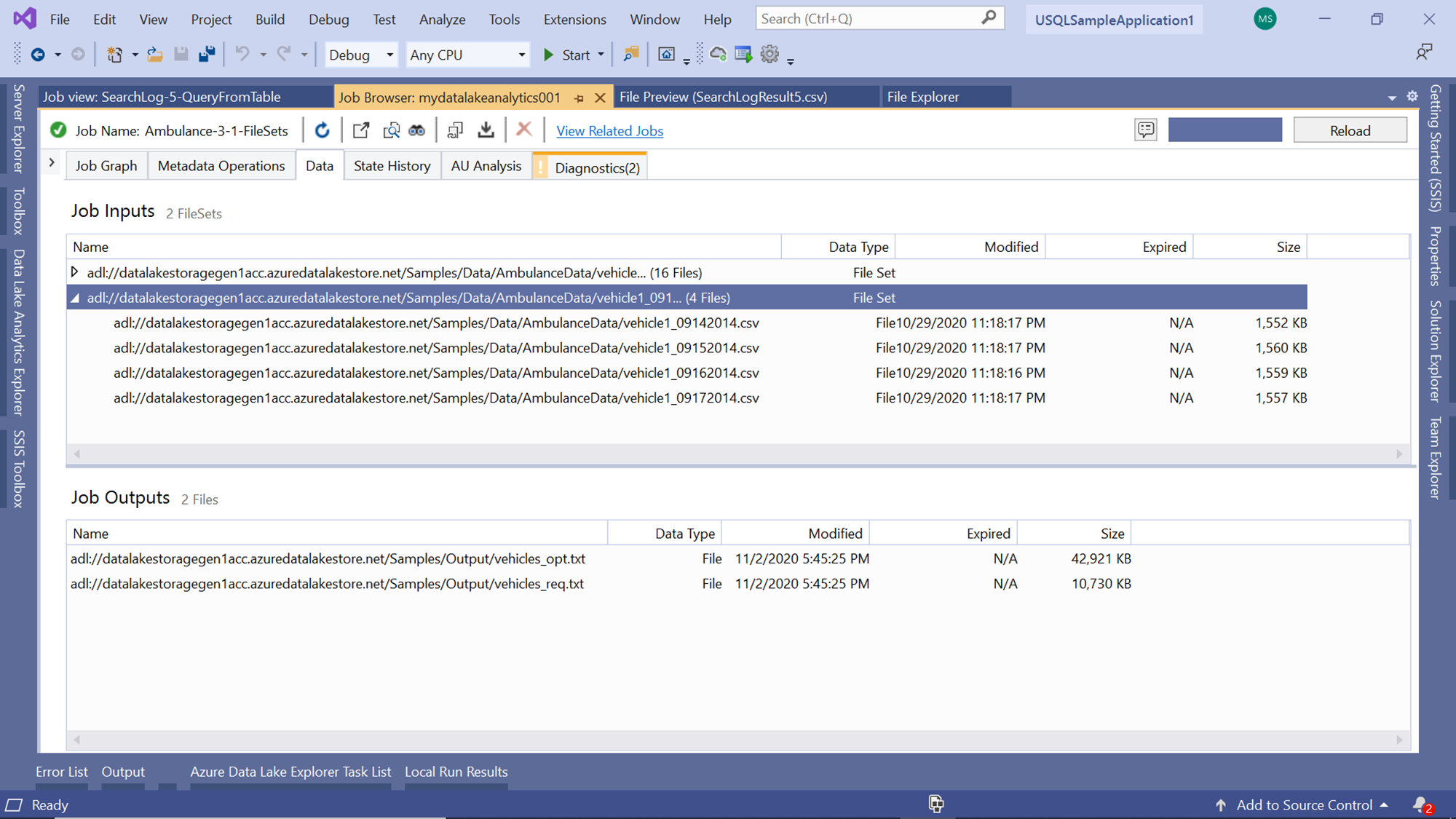
Expand one of the items under the Job Inputs section, and you would be able to see which files were selected. If you carefully observe the below image, it shows the four vehicle files that had the value of 1 in the file name, which was the filter criteria that we mentioned in the 1st part of the script.
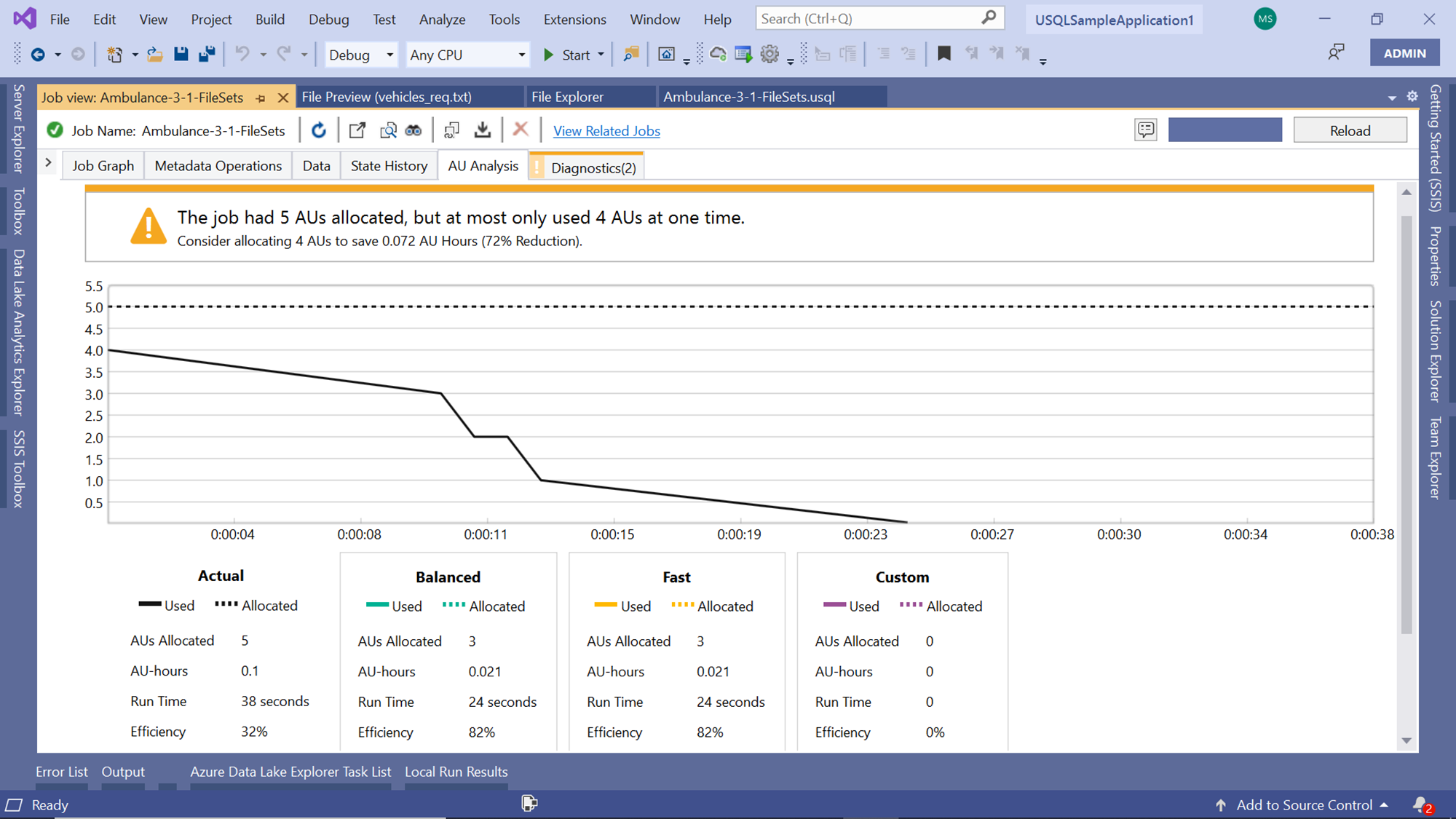
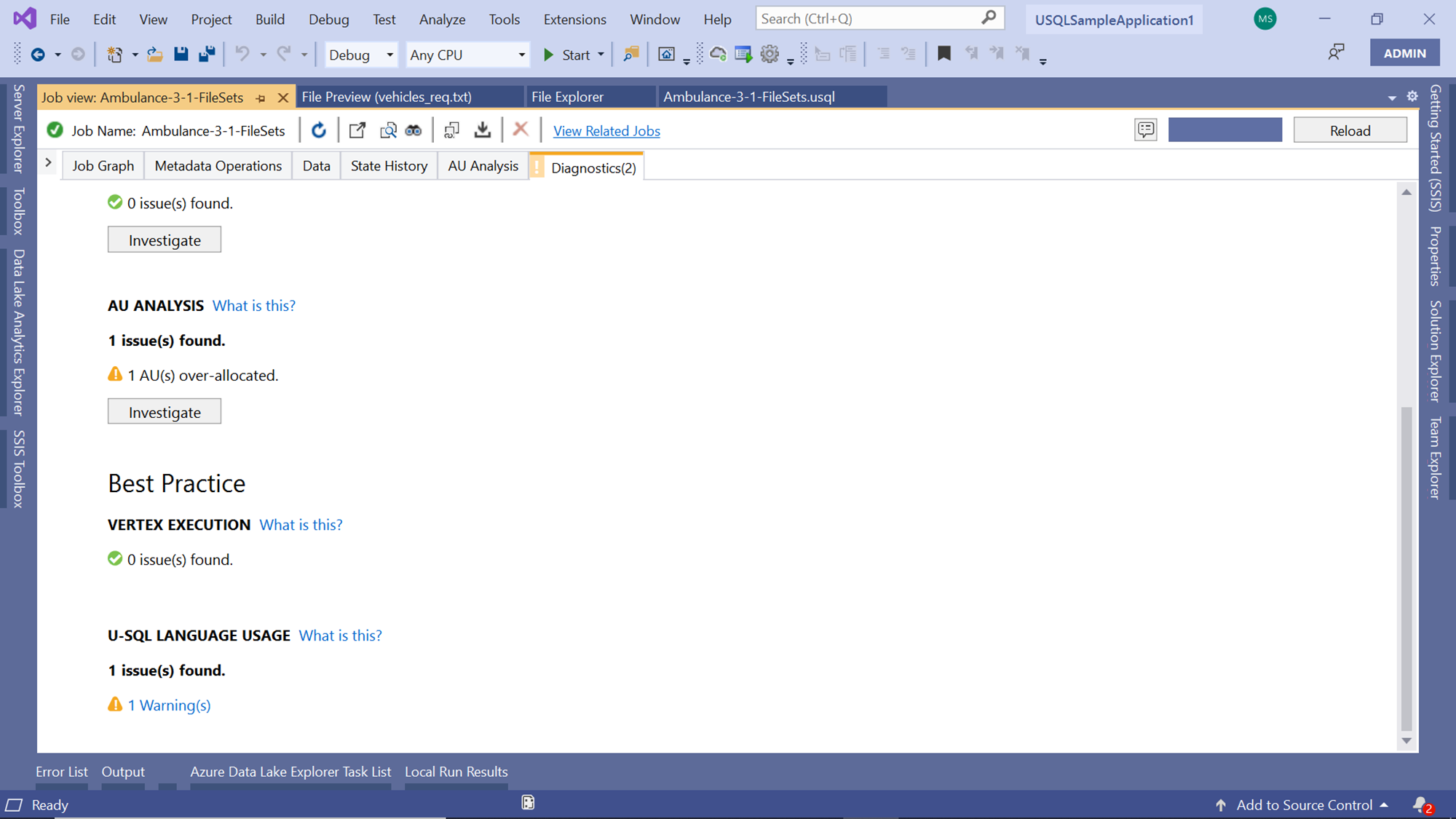
Navigate to the Diagnostics tab that shows 2 issues. When you click on the tab, you would be able to see as shown below. By default, the job executes on the Azure Data Lake Analytics account with 5 AUs, and based on the job execution analysis, it’s found that it’s over-allocated as the job uses a maximum of 4 AUs at any given time.
If we scroll down further, we would find one warning listed as shown below. This warning is one of the U-SQL language usage, which generally signals that the U-SQL used in the script can be optimized further.
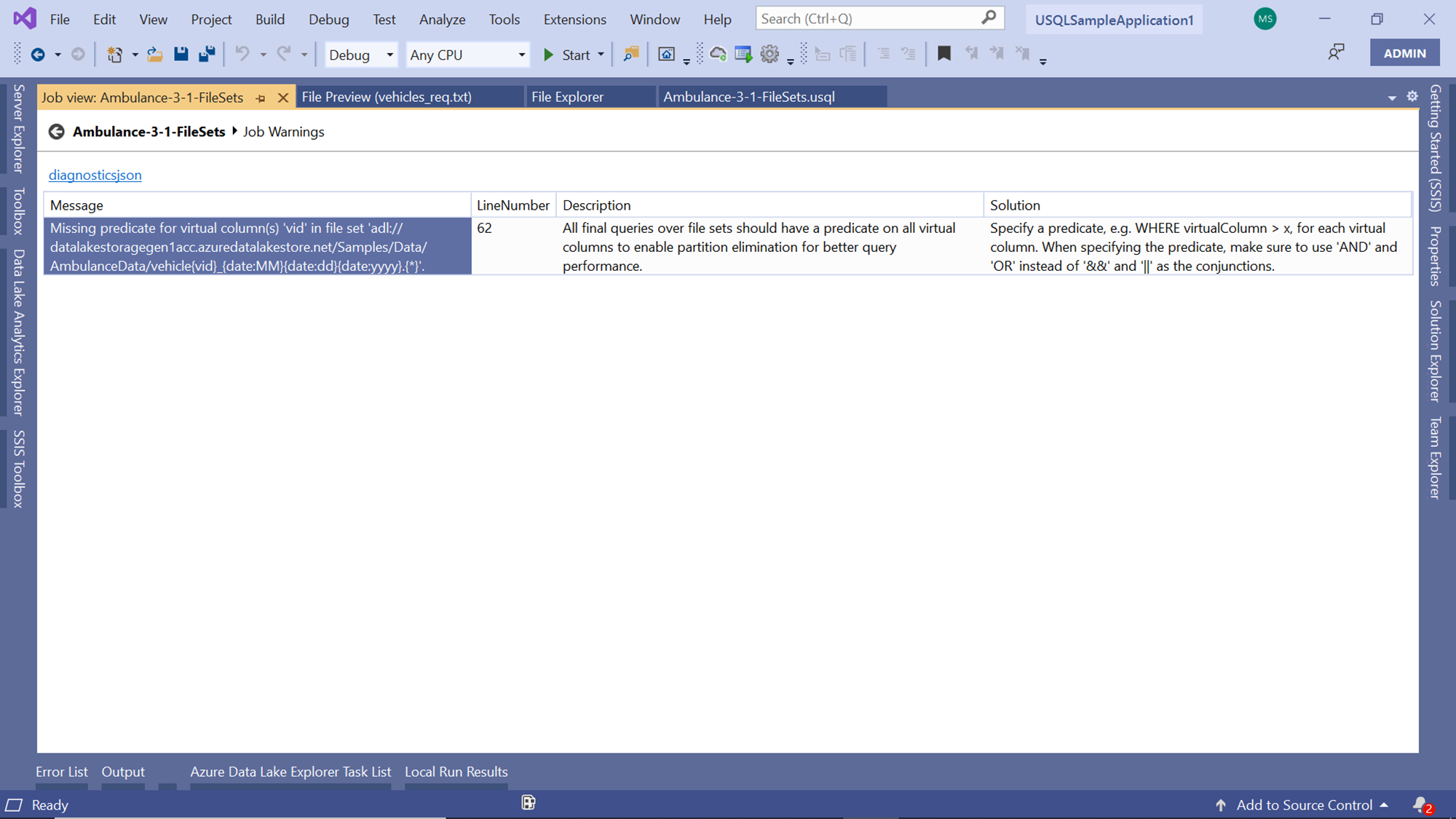
Click on the warnings link, and that would open the details as shown below. The message means that in the second part of the script, we did not use the virtual column vid in the streamset selection. As per the analysis, all streamset columns should be used for better query performance, which is the reason this warning was issued by the job.
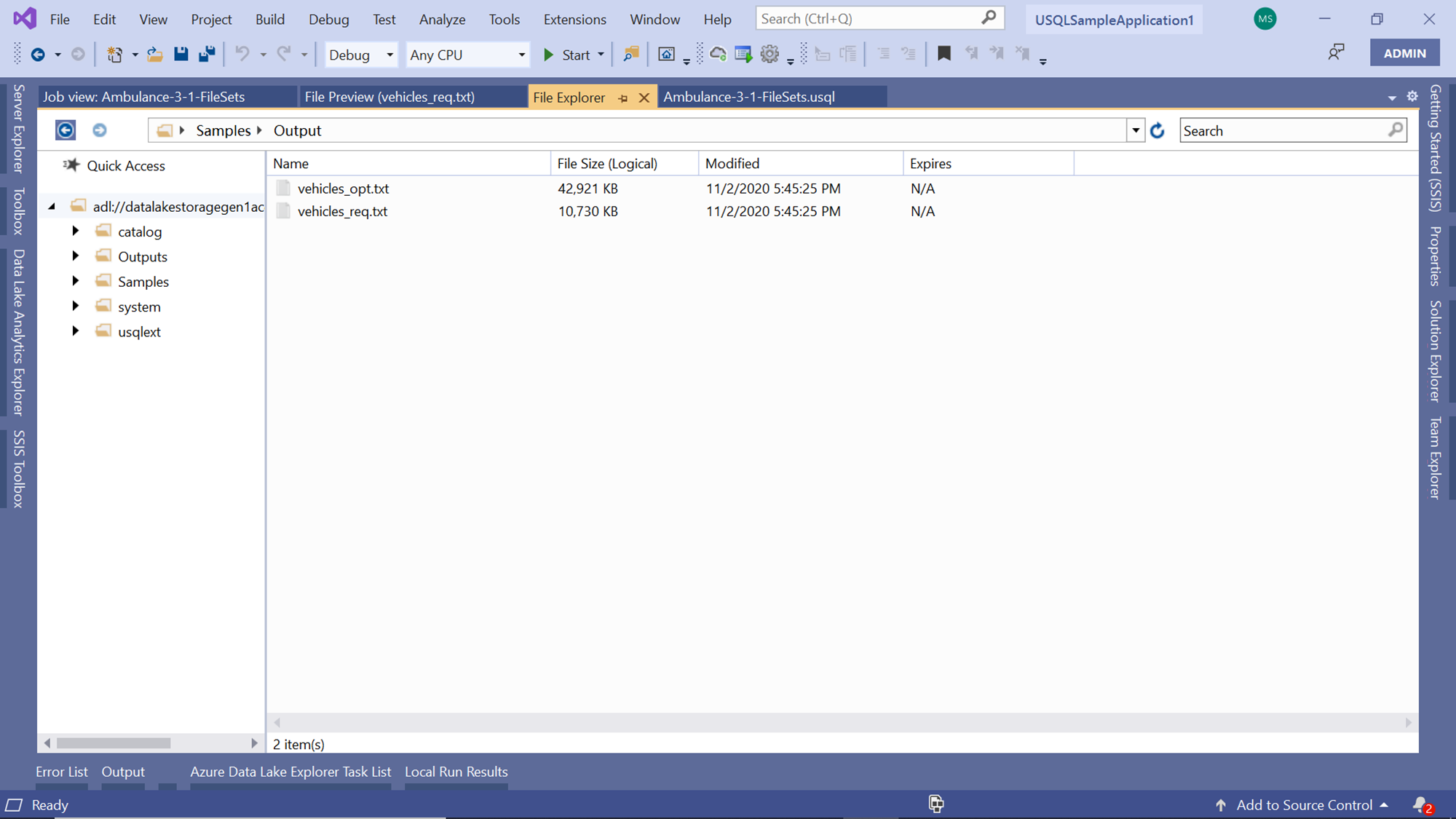
In the Data Lake Explorer, navigate to the path where the output files are stored and you would be able to see the files as shown below:
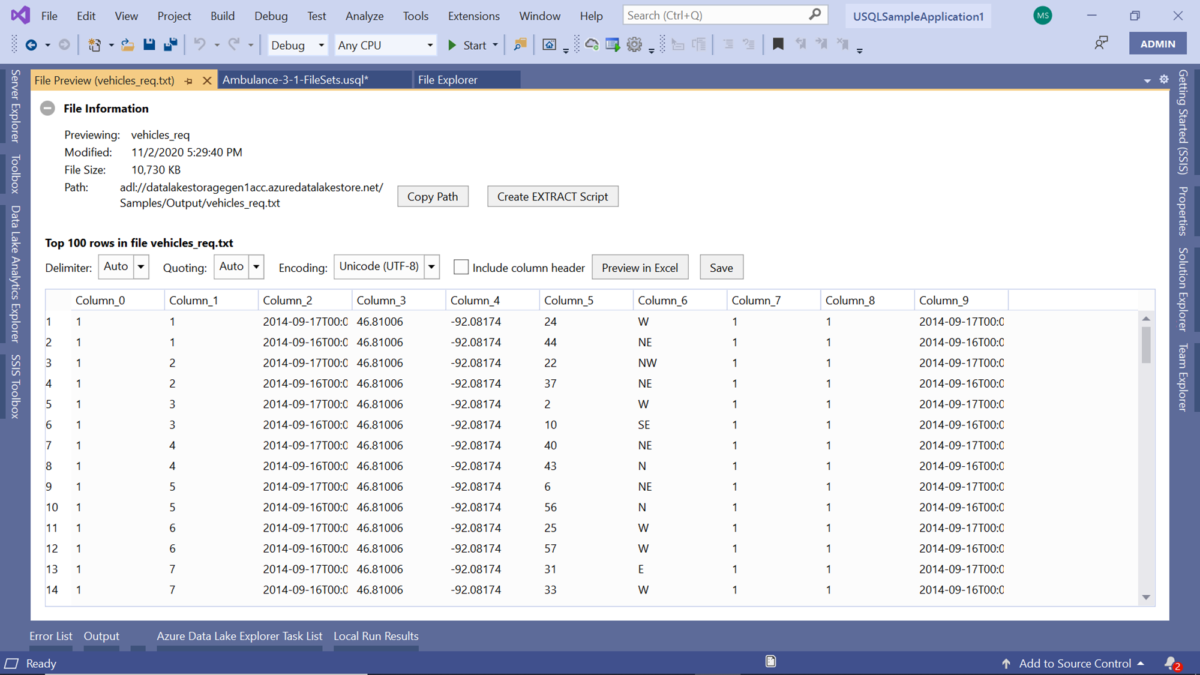
Open any of these files and you would be able to preview it as shown below. As we can see below, it has ten fields. This file can be previewed in Excel, saved locally, as well as an Extract script can be readily created by clicking the corresponding buttons on this view:
In this way, we can process file sets stored in Azure Data Lake Storage, using U-SQL in the Azure Data Lake Analytics account.
Conclusion
In this article, we used a sample dataset formed of various files having an identical schema and organized with a specific naming convention. Such a dataset is also known as file sets. We used U-SQL to select the files based on the desired criterion, read data from these files and stored the output in the data lake storage. We also understood how the job graph is generated when using multiple scripts with a file set and how to analyze the input and output files that were processed by the job.
Table of contents

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023