
In this article, we will learn how to execute U-SQL jobs that have been developed or tested locally, to the production environment from a local machine.
Introduction
In the third part of this article series, we learned how to execute U-SQL jobs locally using Visual Studio IDE and using local data as well. Typically, when the developer has perfected the U-SQL job, the next logical step is to test the job on the Azure Data Lake Analytics account. Jobs are executed in different environments from development or non-production environment to production environments.
Deploying U-SQL jobs
Firstly, we need a U-SQL script that can be executed or deployed on the Azure Data Lake Analytics account. In the previous parts of the article, we created a sample U-SQL application that has ready-to-use scripts, which we tested on local machines as well as using Visual Studio. It’s assumed that you already have this setup available on your local machine as shown below, from where we would be deploying the scripts on the Azure Data Lake Analytics account.
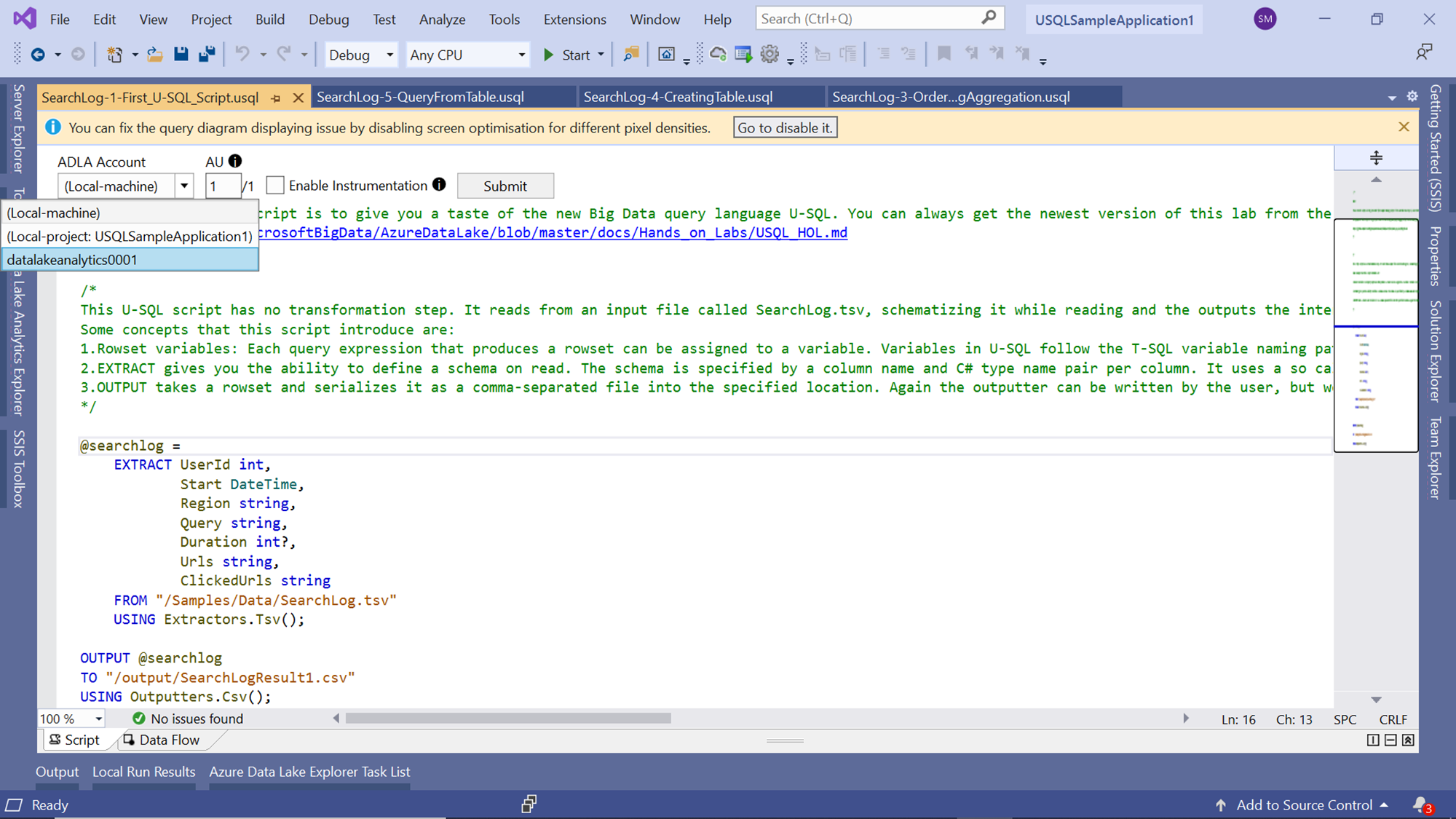
We executed the job shown below in the previous part of this article. By default, the Azure Data Lake Analytics account that is selected in Visual Studio is the local account. To execute the job on the cloud, the only change we need to do here is changing the account on which the job would be executed. Click on the ADLA Account dropdown as shown below and change the account to the Azure Data Lake Analytics account. If you are not able to find the Azure account listed in this dropdown, you may want to check whether you have logged on with your Azure credentials in the Data Lake explorer. Only after successful login into Azure Data Lake Explorer, it is able to fetch the subscriptions and retrieve the Azure Data Lake Analytics account.
Before executing the job, one another setting that one may want to consider modifying is the AU allocation for the job. When we execute the job on the local machine, the AU allocation may not be that important of a consideration. But when the job would be executed on a larger volume of data stored in the Azure Data Lake Storage account, the AU allocation should be increased, else with a larger volume of data, the job would execute at a considerably lower speed. Change the AU allocation for the job depending on the performance and cost requirements as shown below.
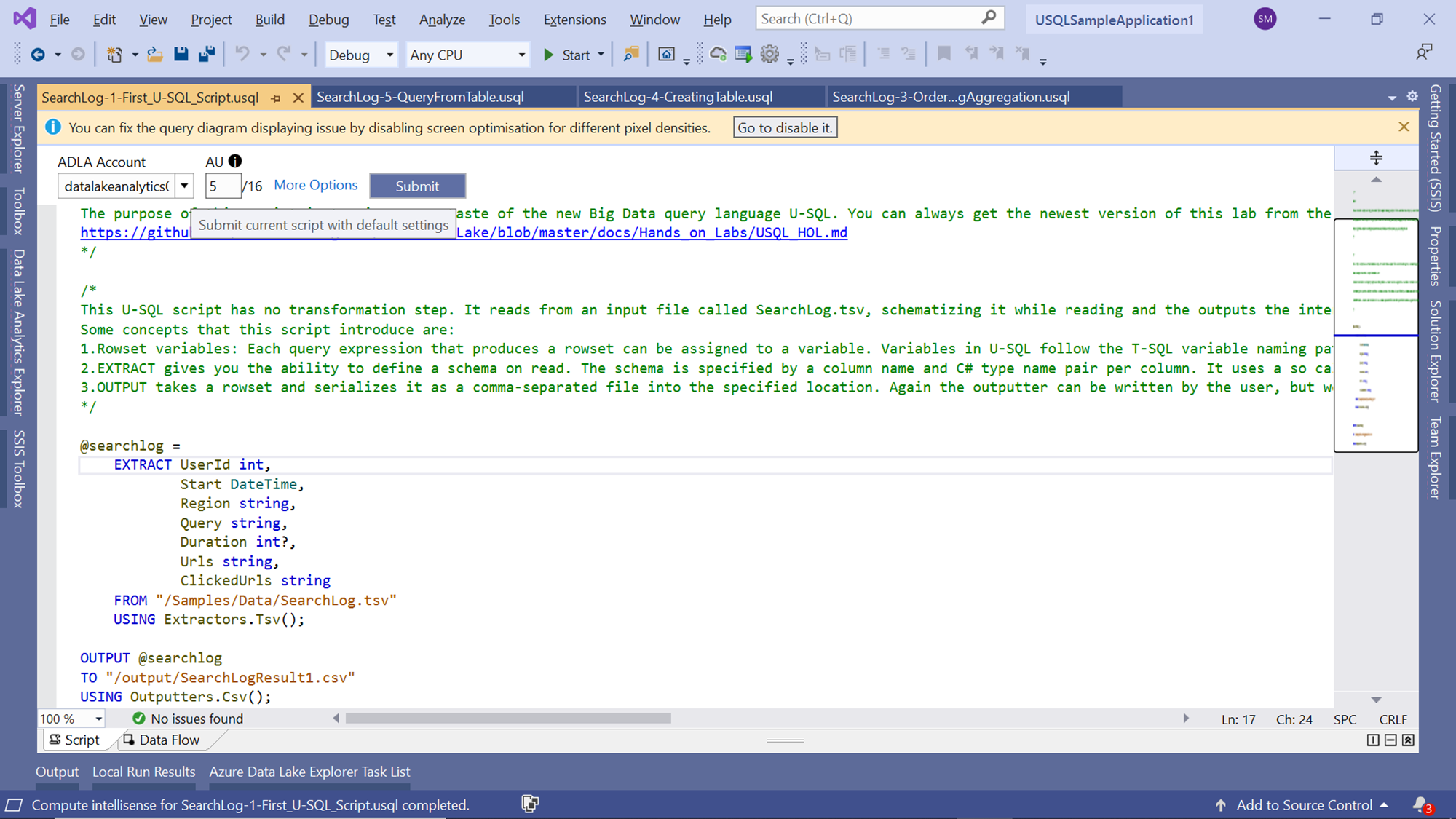
After these configuration changes, we are now ready to execute the job on the cloud account. Click on the Submit button to submit this job for execution on the cloud account. As soon as the execution starts, messages would start appearing in the output window as shown below.
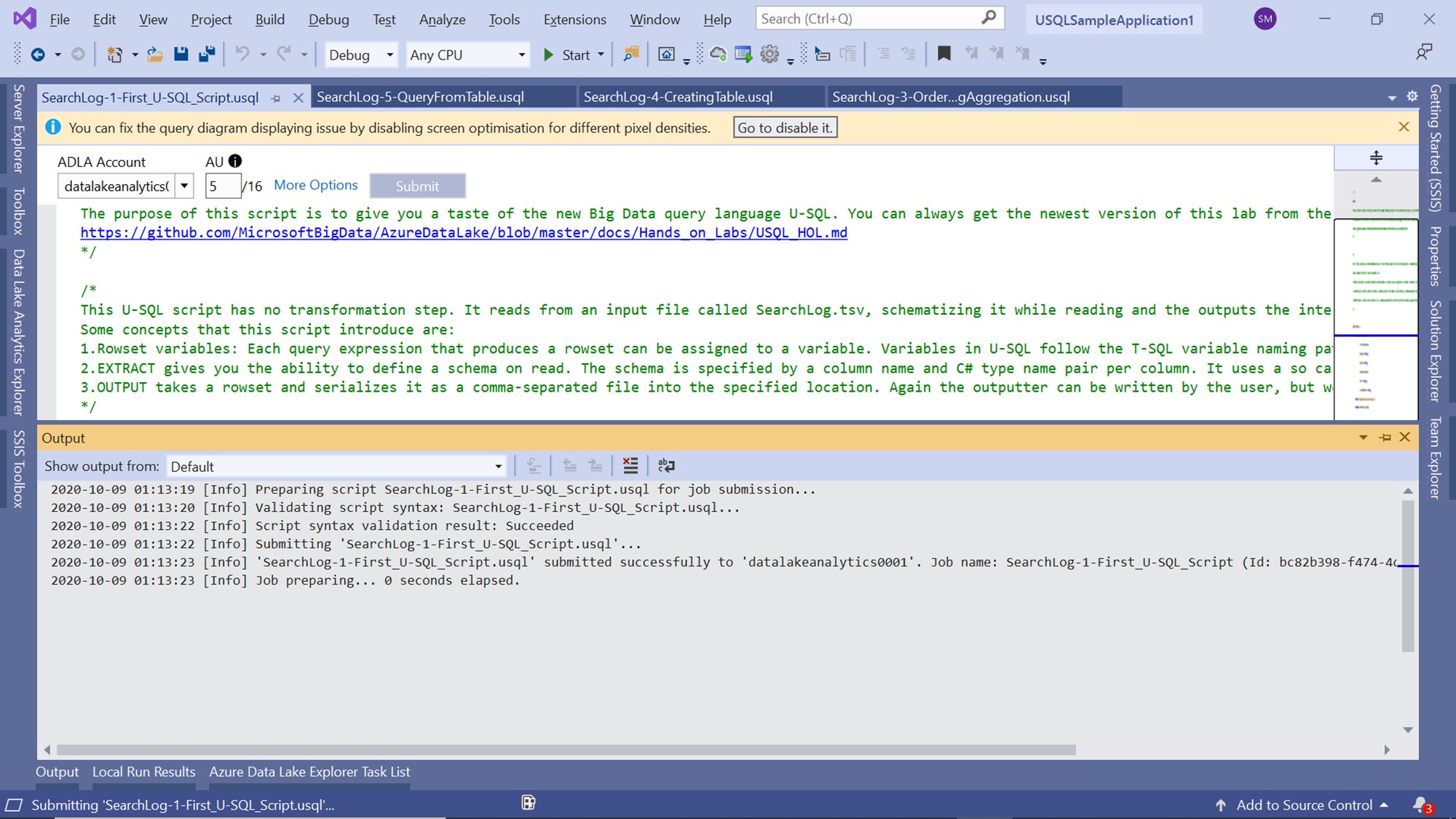
Once the job gets Queued for execution, you would be able to see the job graph as well as status as shown below. The process of job execution on the local account/machine is identical to job execution on the Azure Data Lake Analytics account as well.
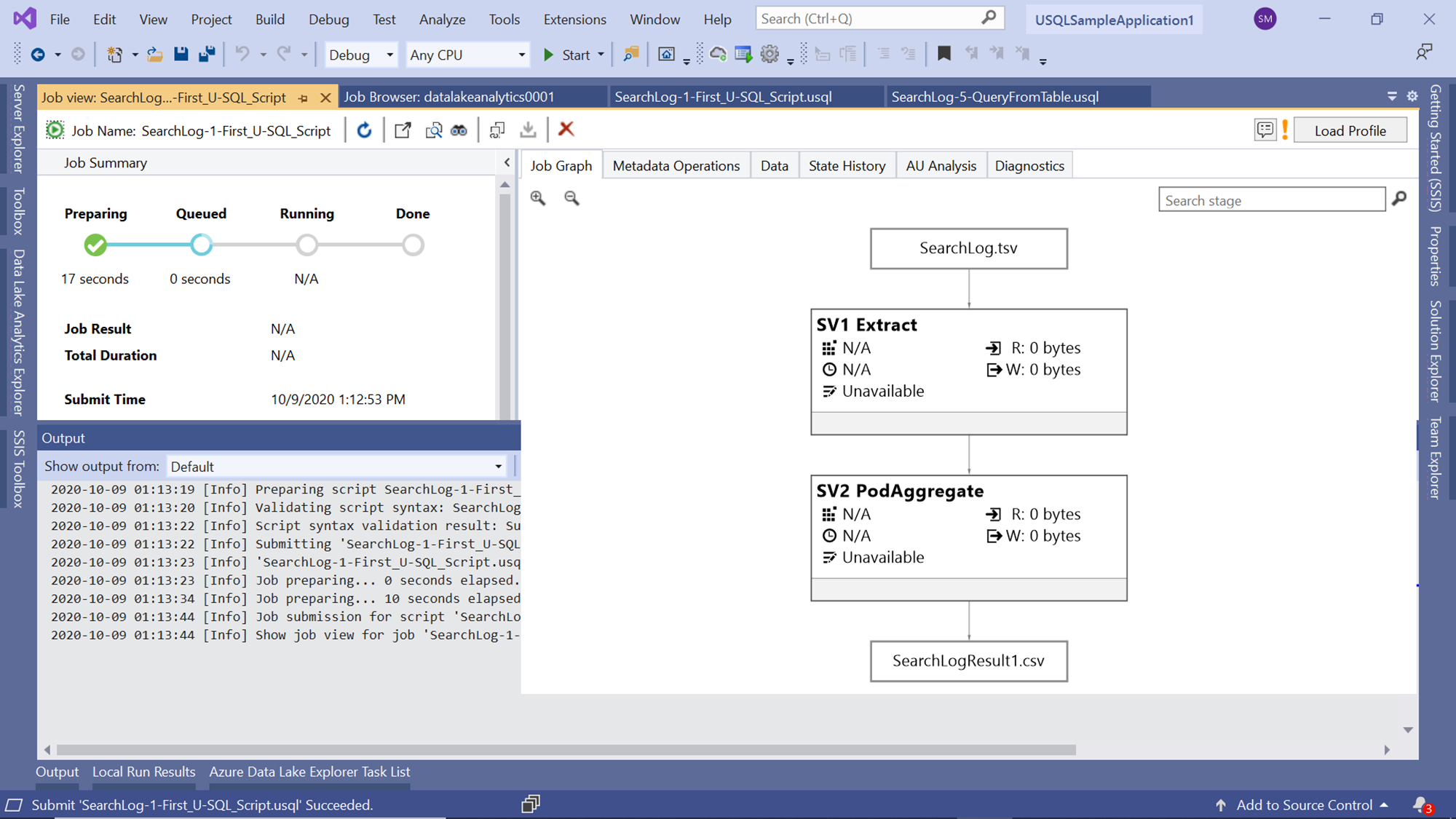
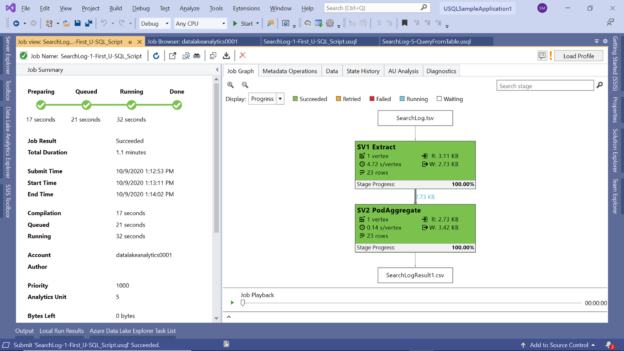
Once the job execution is complete, you would be able to view all the job execution statistics as well as the state of the steps in the job graph as shown below.
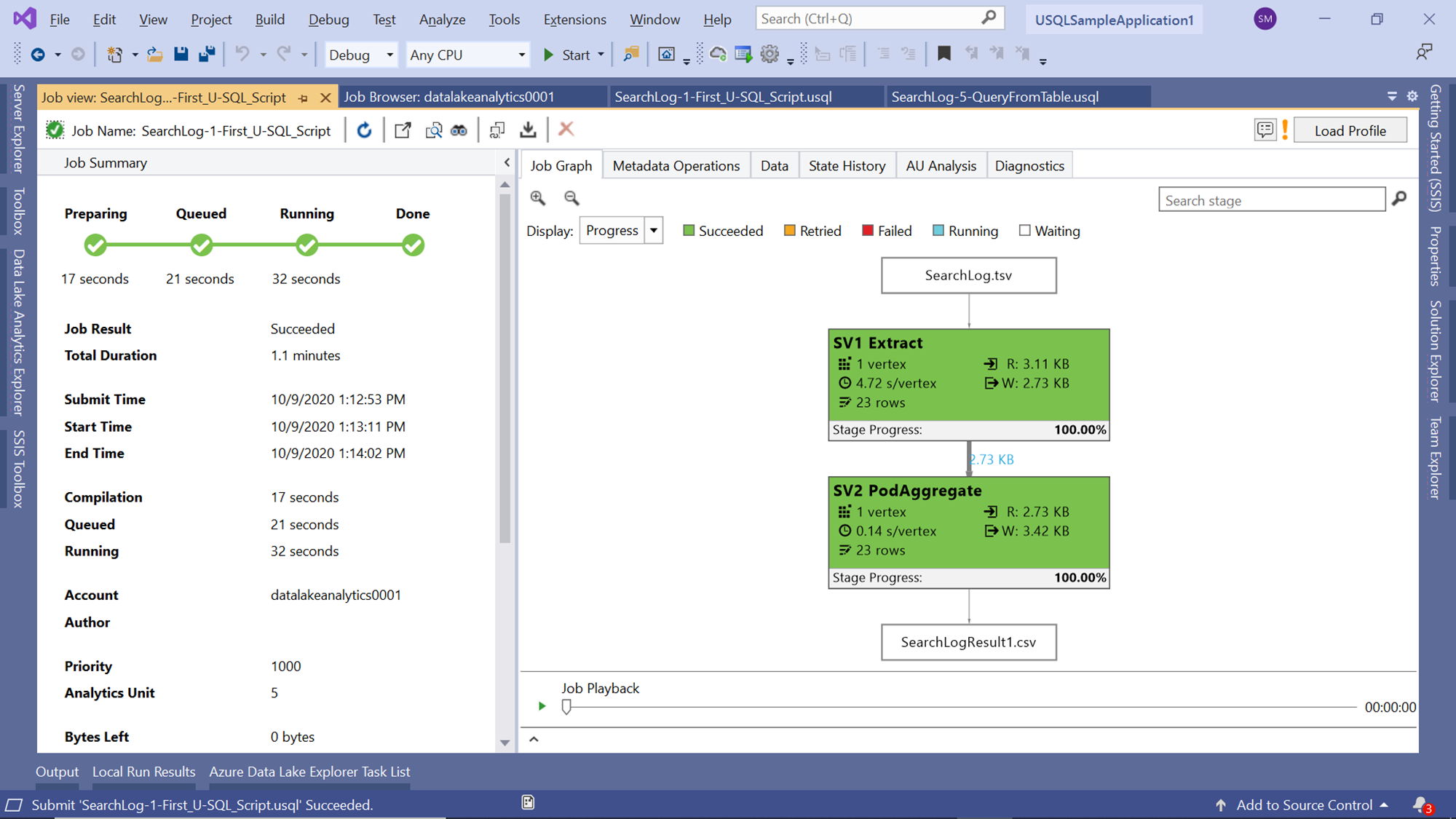
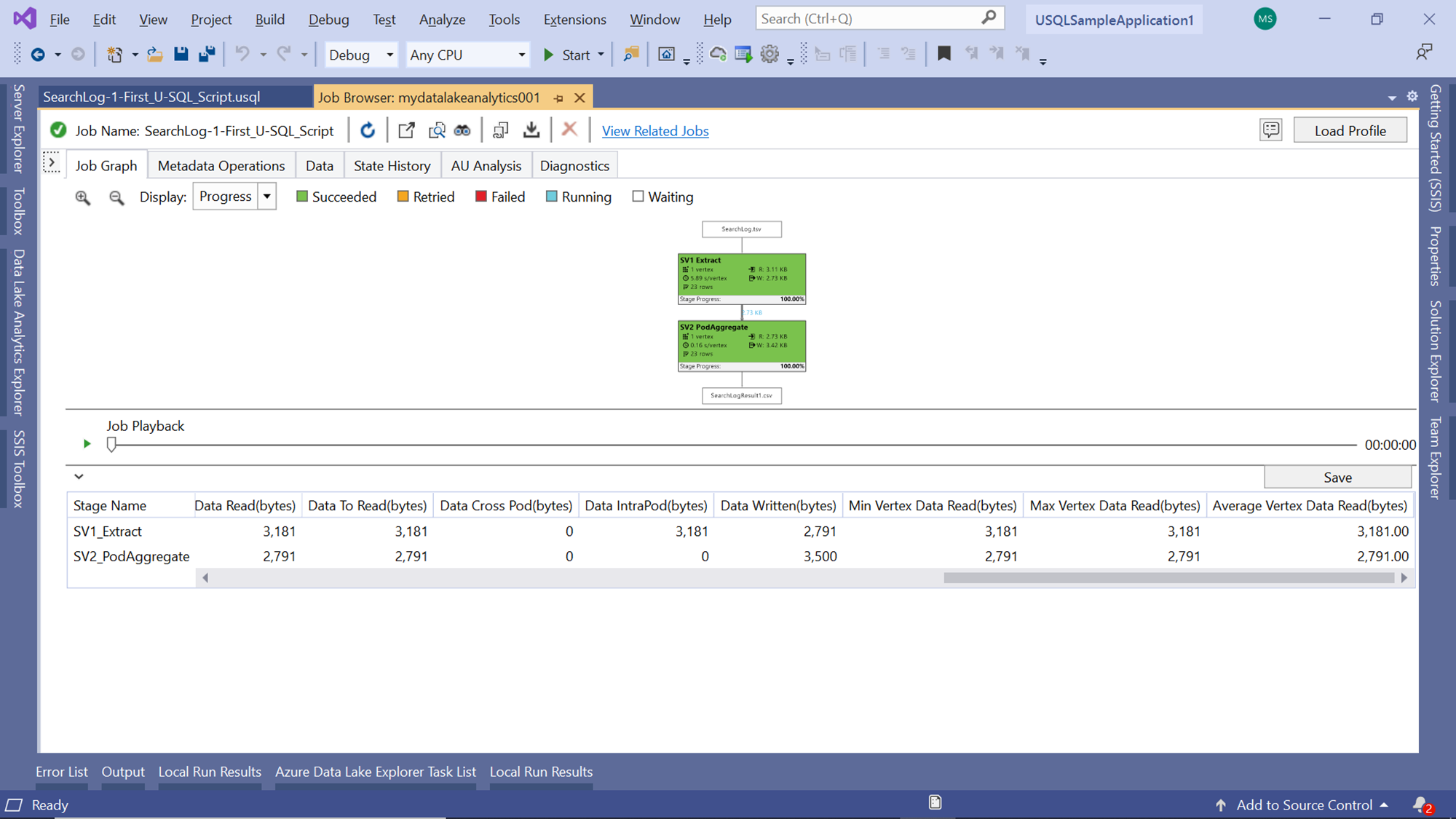
After the job has been completed, one may want to analyze the different steps as well as the performance metrics related to each step. Click on the small arrow below the Job Playback button to expand the vertex view that shows all the vertex execution details as shown below.
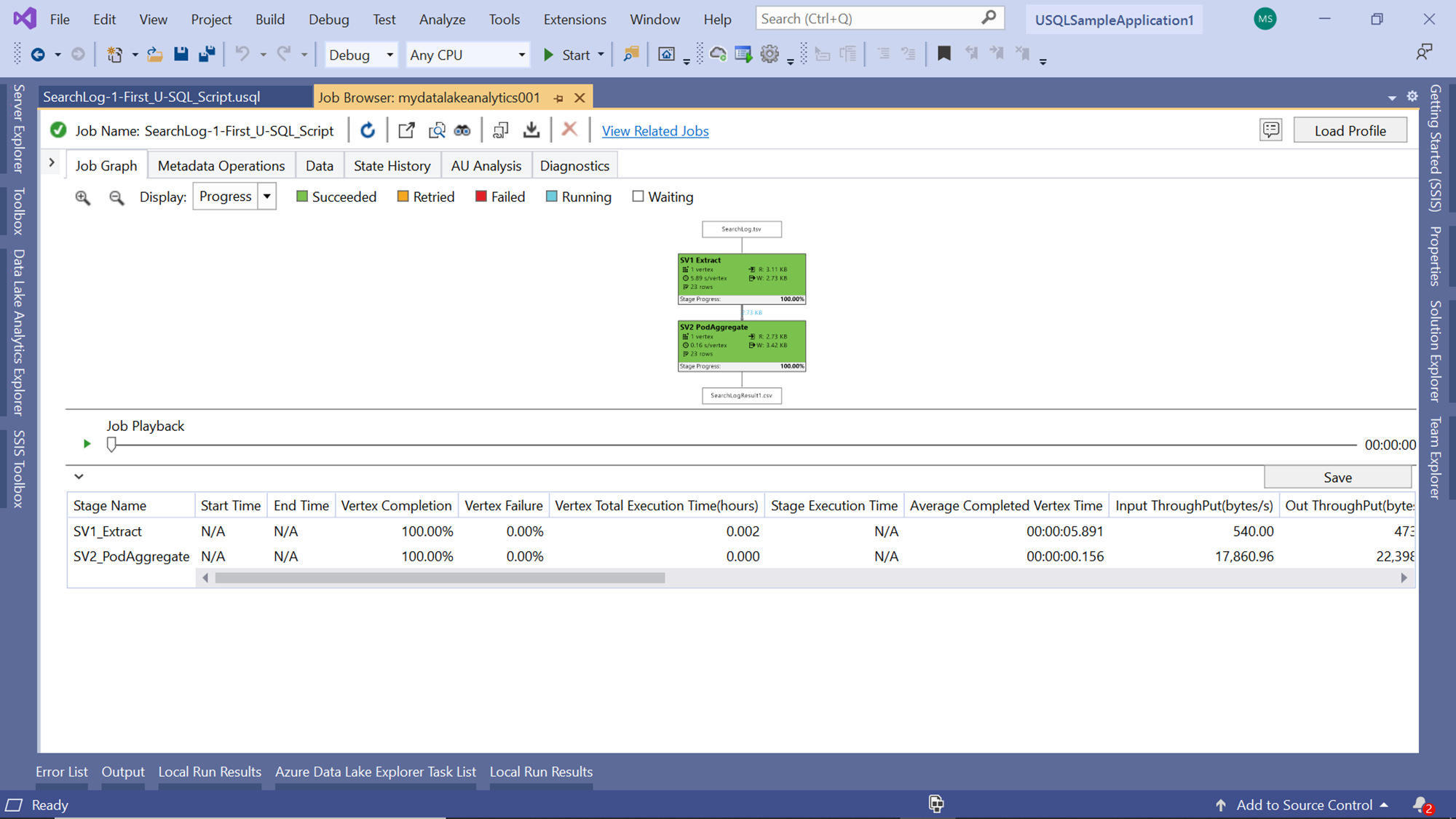
If you scroll to the end of the vertex execution details, you would be able to see the data flow and throughput related details as shown below. In complex job scenarios, there may be a number of vertexes and the inter-vertex data flow and throughput details can provide key insights into the performance of the job.
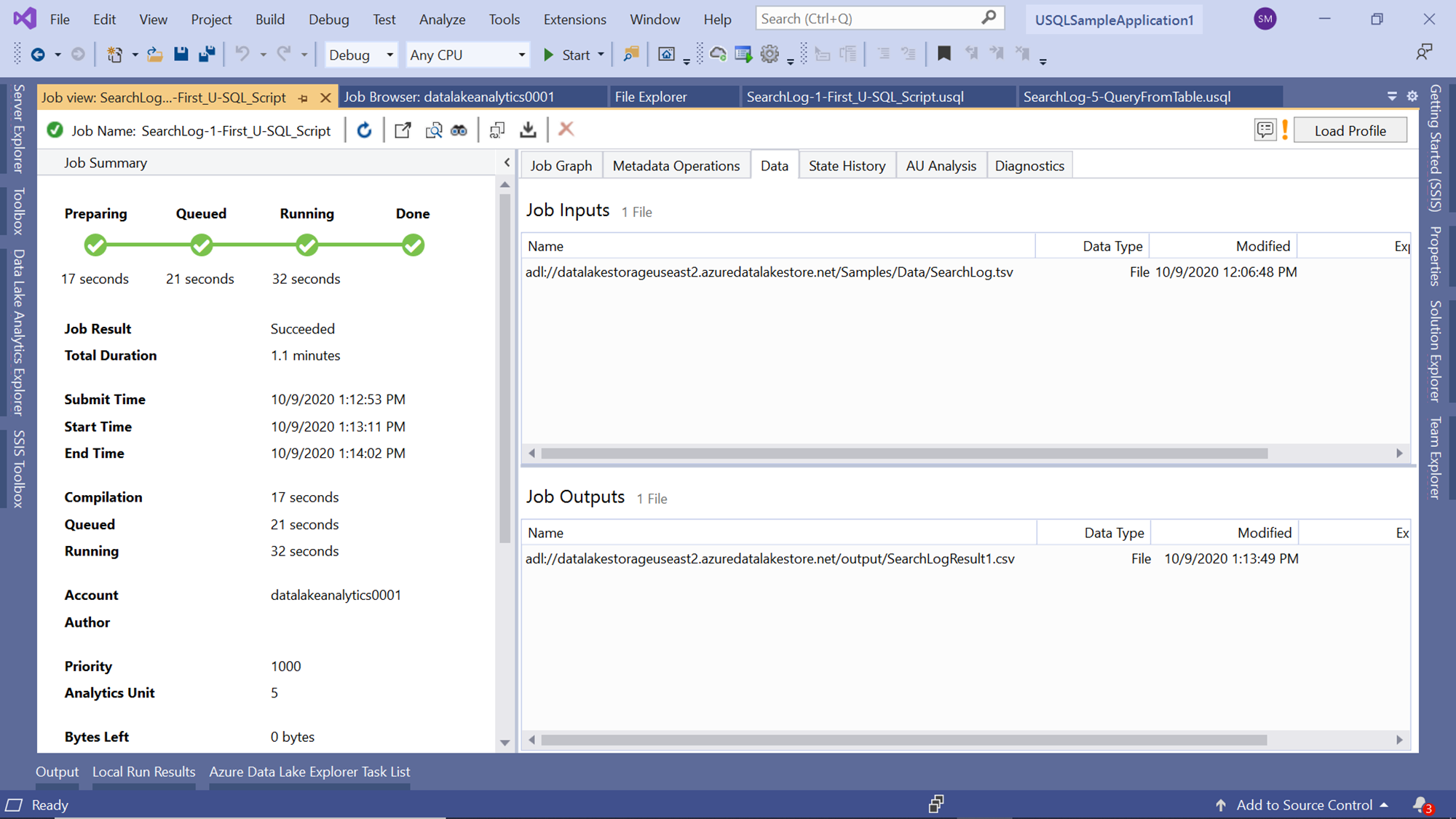
Click on the data tab of the job execution window, and you would be able to find out input and output files on the Azure Data Lake Storage Account as shown below. The input file is in the TSV format and the output file is in CSV format as expected.
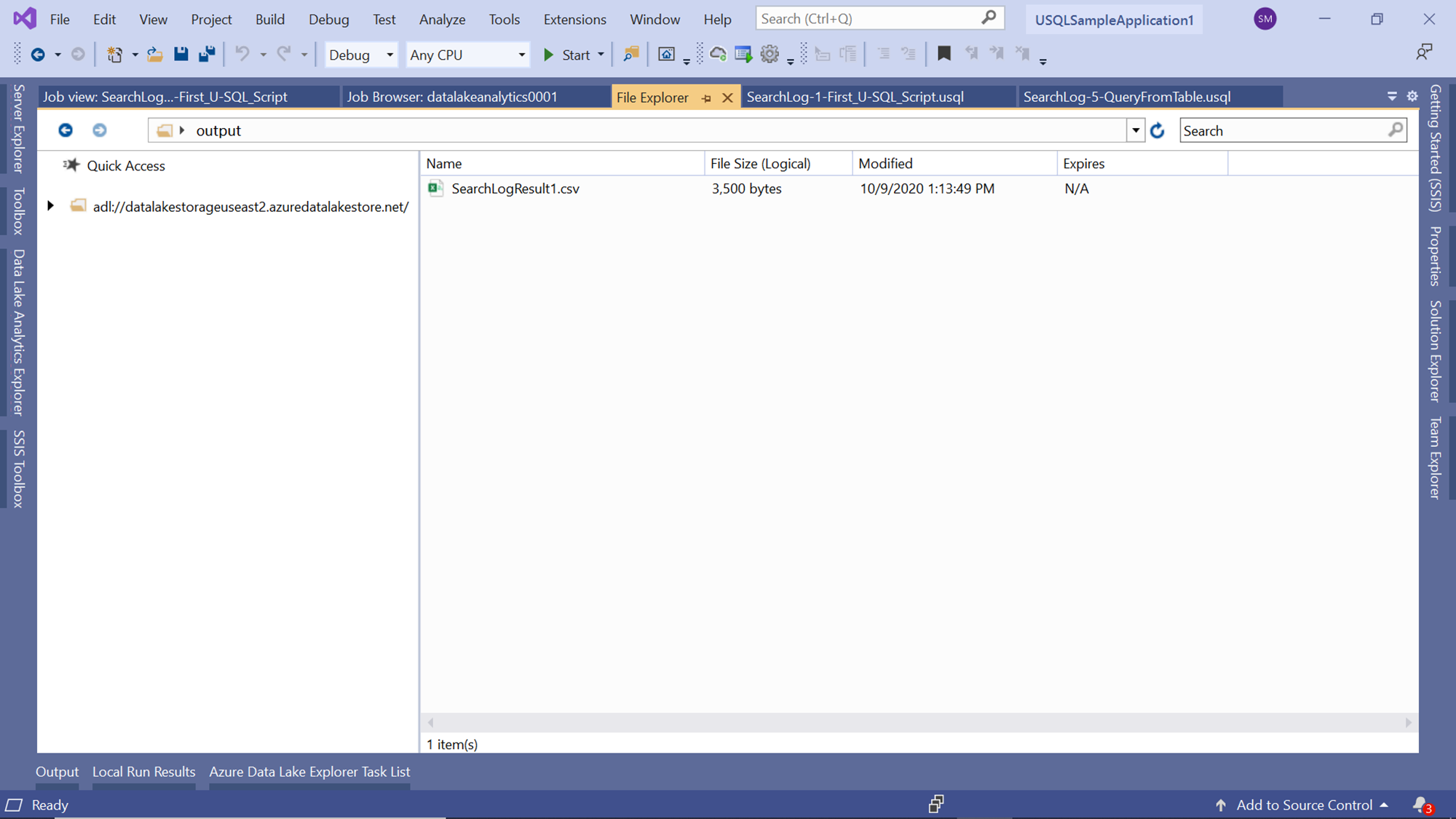
If you try to open these files, it would open in preview mode in the File Explorer window as shown below. The address shown here of these files is the address of the Azure Data Lake Storage account.
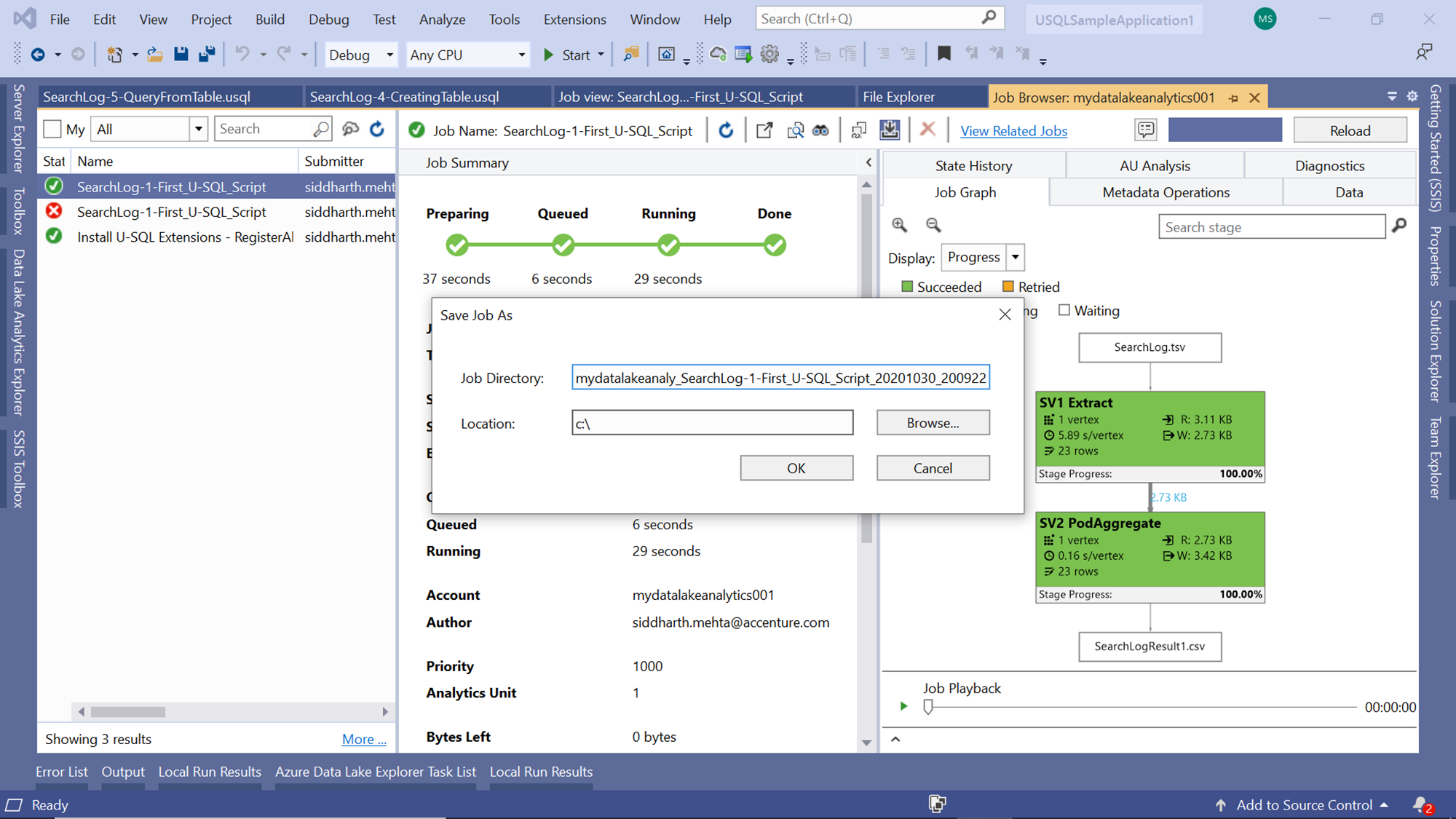
Cloud environments are generally not static. For example, test environments maybe set up as required, and then may be scaled down or even decommissioned where there is no active development. Dev environments may be repurposed at times for different purposes. Test data on the data lake storage development accounts may get removed. Similarly, there may be various reasons due to which environments in which these jobs are executed may change. For this reason, one may want to download an executed job from the Azure Data Lake Analytics account in the local environment. On the job execution window, on the tool bar, you would find a button that allows you to download the job locally as shown below. Click on the job start downloading of the job. Once you click on the button, you would get a prompt asking for the location where the job and its dependent files would be downloaded locally.
Navigate to the folder where the files are downloaded. It would look as shown below. You would find several files downloaded including the actual script that contains the U-SQL code. The rest of the additional files are the project dependencies and the reference libraries. These files can be added to the version control repository as well.
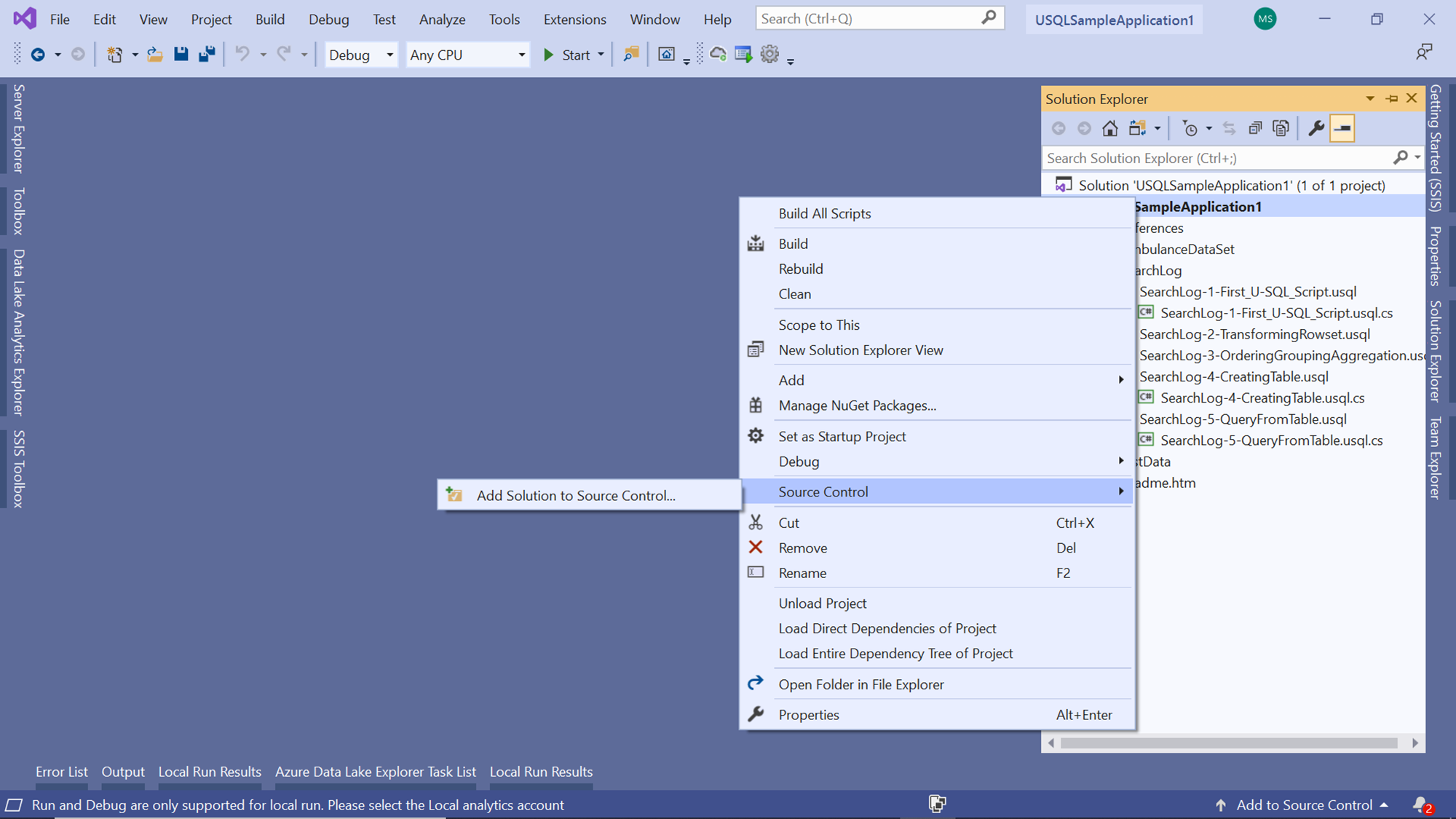
To add the project to version control, right-click on the solution in the solution explorer window. In the source control menu item and click on Add Solution to Source Control to add the solution to version control.
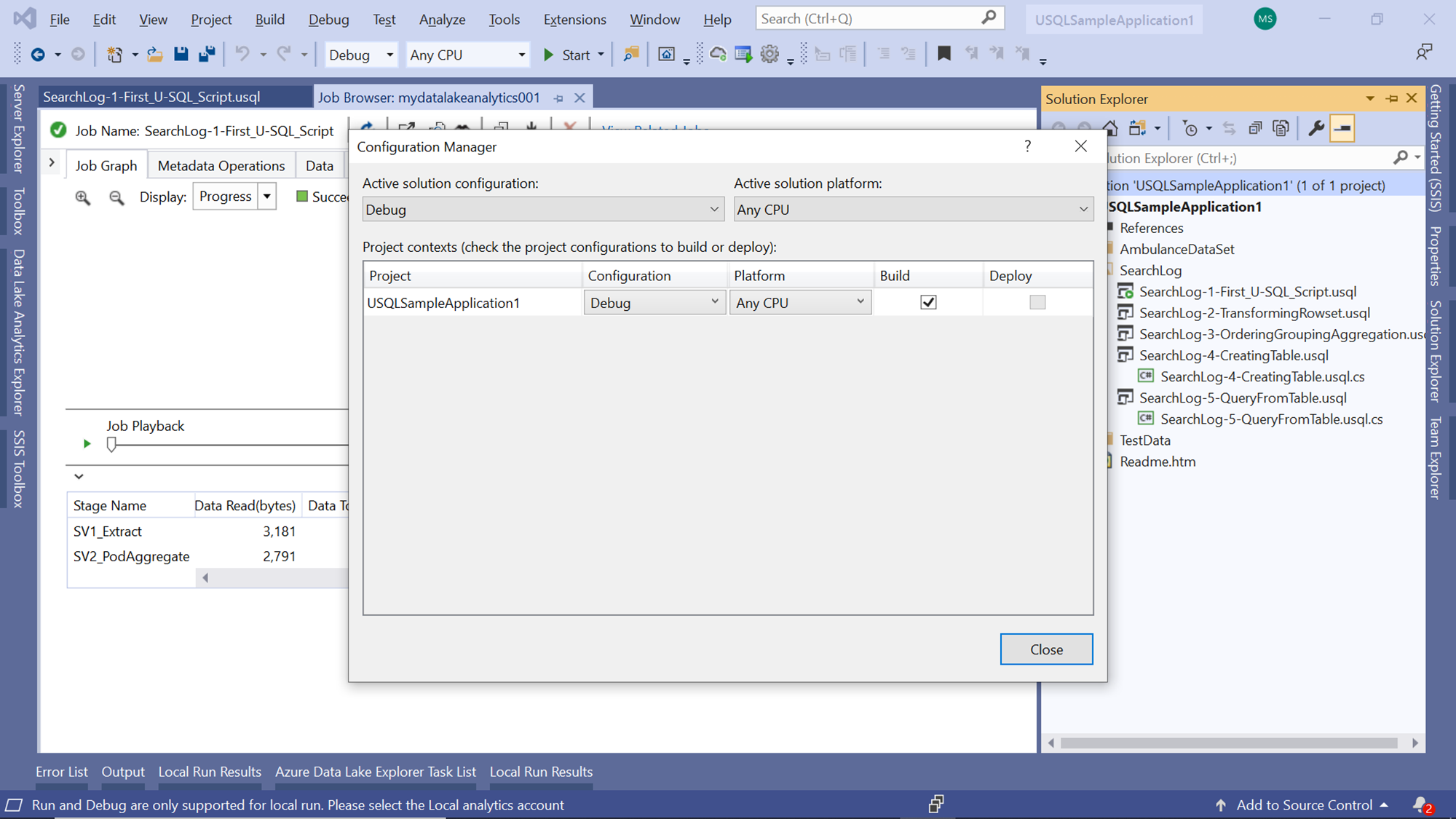
When deploying a solution on the Azure Data Lake Analytics account, one may need to change the configuration of the project properties as well. Right-click on the solution and select the Configuration Manager to open the configuration properties. The two main configuration properties that can be changed as the platform and configuration. Platform decides that when the job or the application is executed, CPU type or architecture should be used like x86 or x64. On the configuration tab, by default, the value is DEBUG which is typically used during the development phase. This introduces debugging and tracing flags in the solution. When deploying in a production environment, the configuration value can be changed to RELEASE or any new version.
In this way, using Visual Studio one can change the configuration of the solution to tune it for production release, and then execute jobs as well as deploy the same on any non-production and production environments.
Conclusion
We started with a basic setup of a sample U-SQL application that has sample data and scripts that operate on the data. We learned how to connect to the Azure Data Lake Analytics account and execute the job directly on the cloud account. Executing the job generates the job graph and several vertex executions details. We briefly looked at the different vertex execution metrics available in the job graph window. We looked at how to download an executed job from the Azure Data Lake Analytics account to a local machine, and how to add the solution to version control. We also looked at the different settings that can be changed while deploying a U-SQL project to different environments.
Table of contents

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023