
Indexing strategy is complex; it depends on many factors, including database structure, queries, and stored procedures used. One of general recommendations is to create a clustered index on tables where data is frequently queried. Although some DBAs and developers don’t prefer having clustered indexes on tables frequently inserted or updated, others consider that a clustered index on the right column can improve performance in these situations.
Creating a clustered index on every table is highly recommended, the challenge is to create the right index.
With a proper clustered index, less reads are required to retrieve the records requested by a query or stored procedure. Therefore, fewer disk I/O are preformed and the operation is completed faster.
A clustered index provides more efficient search for values in a specific range. When you already have a table where the records are sorted ascending by e.g. AddressID, it’s easy to find the rows where AddressID is between 100 and 200, or lower than 500.
One of the rare scenarios where a heap table can be a good practice is when the row identifier is smaller than the clustered index.
What is poor indexing?
Any SQL Server table configuration where performance suffers due to excessive, improper, or missing indexes is considered to be poor indexing.
If indexes are not properly created, SQL Server has to go through more records in order to retrieve the data requested by a query. Therefore, it uses more hardware resources (processor, memory, disk, and network) and obtaining the data lasts longer.
A wrong index can be an index created on a column that doesn’t provide easier data manipulation or an index created on multiple columns which instead of speeding up queries, slows them down.
A table without a clustered index can also be considered as a poor indexing practice. Execution of a SELECT statement, inserting, updating, and deleting records is in most cases slower on a heap table than on a clustered one.
Which columns to use to build an index?
Both clustered and nonclustered indexes can be built from one or more table columns.
When you create a new table with a primary key in a SQL Server database, a unique clustered index is automatically created on the primary key column. Although this default action is acceptable in most cases, this might not be the optimal clustered index.
The column used for a clustered index should be a unique, identity, or primary key, or any other column where the value is increased for each new entry. As clustered indexes sort the records based on the value, using a column already ordered ascending, such as an identity column, is a good solution.
If a column where new values are not higher than previous is used for a clustered index, adding each new row would require re-ordering, i.e. moving the whole row and placing it to its proper location in accordance with clustered index ordering, thus splitting data pages and affecting SQL Server performance. If such clustered index is created on a table with frequent inserts and updates, it can cause performance degradation.
It’s not recommended to use the primary key as a clustered key without checking whether that is the optimal solution in you scenario first. Also, note the difference between a primary key and clustered index – a primary key can’t have duplicate or null values, while a clustered index can.
Using a unique column for a clustered index enables more efficient search for a specific value.
On the other hand, a column that frequently changes its value should not be used for a clustered index. Each change of the column used for the clustered index requires the records to be reordered. This re-ordering can easily be avoided by using a column that is not updated frequently, or not updated at all.
Using a column that stores large data, such as BLOB columns (text, nvarchar(max), image, etc.), and GUID columns is not recommended. Using large values to sort the data is not efficient, and in case of GUID and image columns doesn’t seem to make sense.
A clustered index should not be built on a column already used in a unique index.
In the tests below, we used the Person.Address table in the AdventureWorks database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE TABLE [Person].[Address] ( [AddressID] [int] IDENTITY(1, 1) NOT FOR REPLICATION NOT NULL ,[AddressLine1] [nvarchar](60) NOT NULL ,[AddressLine2] [nvarchar](60) NULL ,[City] [nvarchar](30) NOT NULL ,[StateProvinceID] [int] NOT NULL ,[PostalCode] [nvarchar](15) NOT NULL ,[SpatialLocation] [geography] NULL ,[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL ,[ModifiedDate] [datetime] NOT NULL ,CONSTRAINT [PK_Address_AddressID] PRIMARY KEY CLUSTERED ([AddressID] ASC) WITH ( PAD_INDEX = OFF ,STATISTICS_NORECOMPUTE = OFF ,IGNORE_DUP_KEY = OFF ,ALLOW_ROW_LOCKS = ON ,ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO |
We created almost identical Person.Address1 table. The difference is that the AddressID column is a nonclustered index and the clustered index is created on the non-unique City column. The data is the same as in Person.Address
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE TABLE [Person].[Address1] ( [AddressID] [int] IDENTITY(1, 1) NOT FOR REPLICATION NOT NULL ,[AddressLine1] [nvarchar](60) NOT NULL ,[AddressLine2] [nvarchar](60) NULL ,[City] [nvarchar](30) NOT NULL ,[StateProvinceID] [int] NOT NULL ,[PostalCode] [nvarchar](15) NOT NULL ,[SpatialLocation] [geography] NULL ,[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL ,[ModifiedDate] [datetime] NOT NULL ,CONSTRAINT [PK_Address1] PRIMARY KEY NONCLUSTERED ([AddressID] ASC) WITH ( PAD_INDEX = OFF ,STATISTICS_NORECOMPUTE = OFF ,IGNORE_DUP_KEY = OFF ,ALLOW_ROW_LOCKS = ON ,ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO CREATE CLUSTERED INDEX [Clustered_City_Address1] ON [Person].[Address1] ( [City] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO |
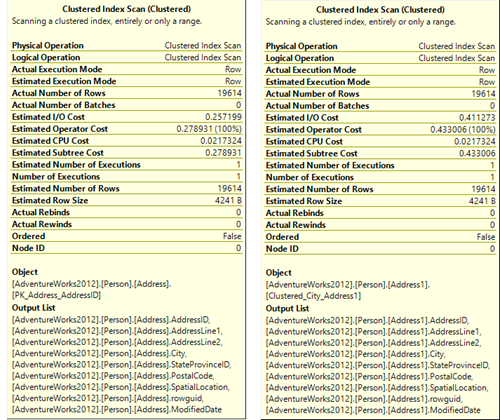
The actual query execution plan for a SELECT * statement looks the same for both tables. The operator that requires most resources is the Clustered Index Scan.

The time needed to execute the Clustered Index Scan operator is significantly different.
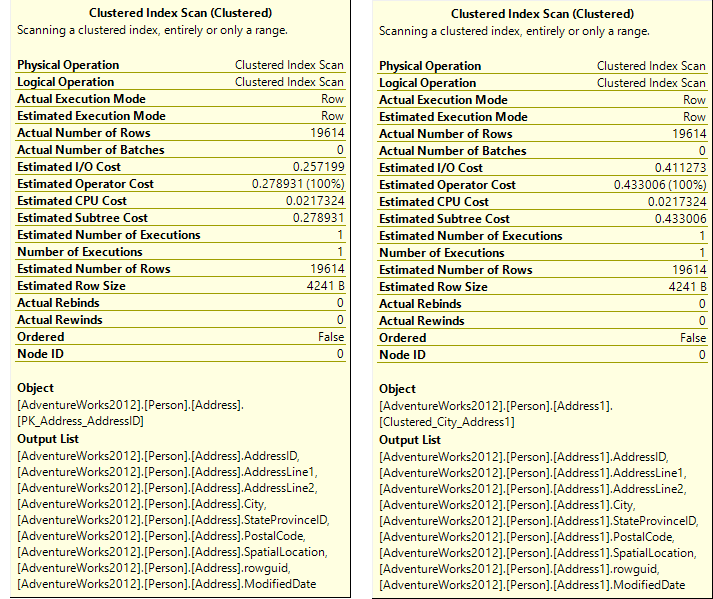
As shown in the Clustered Index Scan properties, the Estimated I/O, Operator, and Subtree costs are almost twice as high for the Person.Address1 table.
Disadvantages of using indexes
As noted above, wrong indexes can significantly slow down SQL Server performance. But even the indexes that provide better performance for some operations, can add overhead for others.
While executing a SELECT statement is faster on a clustered table, INSERTs, UPDATEs, and DELETEs require more time, as not only data is updated, but the indexes are updated also. For clustered indexes, the time increase is more significant, as the records have to maintain the correct order in data pages. Whether a new record is inserted, or an existing deleted or updated, this usually requires the records to be reordered.
Another cost of having indexes on tables is that more data pages and memory is used.
The operator costs from the Actual Query Execution Plan for the tables mentioned above are shown below. The table with the clustered index on the primary key column is [Person].[Address], the table with the clustered index on a non-primary key column is [Person].[Address1] . We created two more copies of the same table, one with a nonclustered index on the primary key column and the other without any indexes. The data in all four tables is identical.
| Clustered index on primary key | Clustered index on any column | Nonclustered index | No indexes | |
| SELECT * | 0.28 | 0.43 | 0.28 | 0.28 |
| SELECT <list> | 0.18 | 0.43 | 0.28 | 0.28 |
| INSERT | 0.04 | 0.02 | 0.02 | 0.01 |
| UPDATE | 0.02 | 0.01 | 0.01 | 0.3 |
| DELETE | 0.05 | 0.02 | 0.02 | 0.3 |
When it comes to executing a SELECT statement, the cost is the lowest when the list of returned columns is specified and the statement is executed on the table where the clustered index is created on the primary key column. The cost can be higher for a table with a non-optimal clustered index (shown in column 2), then on tables with a nonclustered index or no indexes at all.
While executing a SELECT statement is faster on a clustered table, executing DELETEs and UPDATEs requires more time. For the latter statements, the performance of a table with a nonclustered index is the same as for the table with a clustered index on a column other than the primary key.
Note that INSERTs on a table without indexes is the fastest of all – this is expected as neither re-ordering nor index updating is required. On the same table, executing UPDATEs and DELETEs is the most expensive. Again, this is expected, as SQL Server requires most time to find the specific records in such table.
As shown, indexes can speed up some queries and slow down others. In this article, we provided some basic guidelines for clustered and nonclustered indexes, as well as which columns are preferred to build indexes on, and which should be avoided. Finding the right balance between the benefits and overhead indexes bring provides optimal performance to your queries and stored procedures.

She has been working with SQL Server since 2005 and has experience with SQL 2000 through SQL 2014.
Her favorite SQL Server topics are SQL Server disaster recovery, auditing, and performance monitoring.
View all posts by Milena "Millie" Petrovic
- Using custom reports to improve performance reporting in SQL Server 2014 – running and modifying the reports - September 12, 2014
- Using custom reports to improve performance reporting in SQL Server 2014 – the basics - September 8, 2014
- Performance Dashboard Reports in SQL Server 2014 - July 29, 2014