
En el artículo anterior, se explicaron los índices agrupados, no agrupados y como crearlos. En este nuevo artículo, se explicará la manera en que una indexación deficiente puede terminar y a brindar recomendaciones generales para la indexación de tablas al igual que seleccionar las columnas correctas en donde crear los índices
La estrategia que se utiliza para la indexación es compleja y depende de diferentes factores que incluyen la estructura de base de datos, las consultas y los procedimientos almacenados. Entre las recomendaciones generales se tiene el crear un índice agrupado en tablas cuyos datos se consultan con frecuencia. Si bien algunos administradores de bases de datos y programadores no tienen preferencia en un índice agrupado en tablas en que se ingresan o actualizan datos frecuentemente, otros programadores piensan que el tener un índice agrupado a la derecha de la columna puede mejorar la performance en estos casos.
Tener un índice agrupado en cada tabla es una práctica altamente recomendable. El reto es crear el índice correcto.
Cuando se tiene el índice agrupado adecuado, se necesitan menos lecturas para tener y poder recuperar los registros requeridos para una consulta o para un procedimiento almacenado. Por lo tanto, hay menos lecturas de disco de entrada y salida realizadas y la operación resulta más veloz.
El índice agrupado tiene mayor eficiencia al buscar valores de rangos específicos. Cuando ya tiene una tabla con los registros que se han seleccionado en orden descendente, por ejemplo: AddressID, es fácil poder encontrar las filas en que la identificación de la dirección se encuentra entre 100 y 200 o menos de 500.
Entre los escenarios más extraños que se tiene está el de la tabla montón (llamado en inglés heap que es una tabla sin índice cluster) que puede ser una buena práctica y ocurre cuando el identificador de filas es más pequeño que el índice agrupado.
¿Qué es una indexación deficiente?
En cualquier SQL Server en el que la configuración de tabla tenga un performance deficiente, se debe a la mucha y mala indexación de datos que faltan. Esto es lo que se denomina una indexación deficiente.
Si es que los índices no se crean de manera eficiente, el SQL Server deber utilizar más registros para lograr obtener los datos requeridos en la consulta. Por lo tanto, utiliza mayor cantidad de recursos de hardware (procesador, memoria, disco y red) obteniendo datos en mayor tiempo.
El índice malo puede ser un índice que fue creado en una columna específica la cual no brinda los datos en una forma sencilla o accesible, o un índice creado utilizando múltiples columnas que, en vez de acelerar las consultas, las convierte en consultas más tediosas.
Cuando se tiene una tabla que no tiene un índice agrupado, también se la considera como una mala práctica en la indexación. Al ejecutar el comando SELECT, INSERT, o UPDATE y DELETE mayormente se hace más lenta en una tabla montón que en un índice agrupado.
¿Qué columnas pueden utilizarse en la construcción de un índice?
Los índices que son agrupados o no agrupados se pueden construir de una o varias columnas de una tabla específica.
En el momento en que usted llega a crear una nueva tabla que contiene una llave primaria en la base de datos del SQL Server, el índice agrupado único es creado automáticamente en la llave primaria. Aun cuando esta acción realizada por defecto es aceptable en la mayor parte de los casos, este no puede ser un índice agrupado óptimo.
La columna que se utiliza para lograr un índice agrupado tiene que ser un único, con la propiedad de identidad o clave primaria u otra columna en el que su valor se incremente con cada inserción o nueva iteración. De esta forma, los índices agrupados llegan a clasificar los registros de acuerdo con su valor, usando una columna ordenada de manera ascendente lo cual se considera una buena solución.
Si es que una columna tiene valores nuevos que no son más altos que los anteriores usados en un índice agrupado, agregar una nueva fila podría requerir un reordenamiento nuevo. Por ejemplo, mover una fila entera y ponerla en una ubicación adecuada según el índice ordenado, así dividiendo las páginas de datos y afectando el rendimiento del SQL Server. Si esta clase de índice agrupado se crea en una tabla con frecuentes inserciones y actualizaciones, puede llegar a causar una degradación en el rendimiento.
No es recomendable utilizar la clave principal como clave agrupada sin antes verificar que sea la solución óptima en su actual situación. Es importante también notar la diferencia entre la clave primaria y el índice agrupado – la clave primaria no contiene valores duplicados o del tipo nulo, mientras que un índice agrupado si puede tener estos valores.
Utilizar una columna única en un índice agrupado hace que una búsqueda sea más eficiente cuando se tiene un valor específico.
Por otro lado, una columna cuyo valor cambia constantemente no debería ser usado en un índice agrupado. Los diferentes cambios que sufre la columna utilizado para el índice agrupado requieren un reordenamiento de registros. Dicho proceso puede ser evitado de manera sencilla usando una columna que no sea actualizada con frecuencia o que no sea actualizada nunca.
No es recomendable usar una columna que contiene gran cantidad de datos como ser columnas BLOB (texto, nvarchar (max), image, etc), y columnas del tipo GUID. Usar valores grandes para obtener datos no es eficiente, y usar GUID en columnas de imágenes no tiene sentido.
El índice agrupado puede usarse en una columna que ya fue usada como índice único
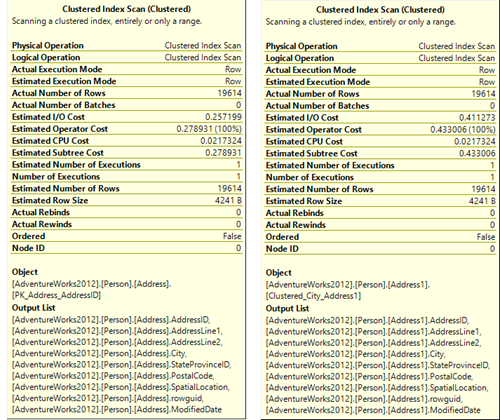
En las pruebas que se muestran a continuación, utilizaremos la tabla de Dirección de Personas en la base de datos de Adventure Works.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE TABLE [Person].[Address] ( [AddressID] [int] IDENTITY(1, 1) NOT FOR REPLICATION NOT NULL ,[AddressLine1] [nvarchar](60) NOT NULL ,[AddressLine2] [nvarchar](60) NULL ,[City] [nvarchar](30) NOT NULL ,[StateProvinceID] [int] NOT NULL ,[PostalCode] [nvarchar](15) NOT NULL ,[SpatialLocation] [geography] NULL ,[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL ,[ModifiedDate] [datetime] NOT NULL ,CONSTRAINT [PK_Address_AddressID] PRIMARY KEY CLUSTERED ([AddressID] ASC) WITH ( PAD_INDEX = OFF ,STATISTICS_NORECOMPUTE = OFF ,IGNORE_DUP_KEY = OFF ,ALLOW_ROW_LOCKS = ON ,ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO |
Se ha creado una tabla casi idéntica de Person.Address1. La diferencia está en que la columna AddressID es un índice no agrupado y el índice agrupado se crea en una Columna única denominada City. La información es la misma que en Person.Address
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE TABLE [Person].[Address1] ( [AddressID] [int] IDENTITY(1, 1) NOT FOR REPLICATION NOT NULL ,[AddressLine1] [nvarchar](60) NOT NULL ,[AddressLine2] [nvarchar](60) NULL ,[City] [nvarchar](30) NOT NULL ,[StateProvinceID] [int] NOT NULL ,[PostalCode] [nvarchar](15) NOT NULL ,[SpatialLocation] [geography] NULL ,[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL ,[ModifiedDate] [datetime] NOT NULL ,CONSTRAINT [PK_Address1] PRIMARY KEY NONCLUSTERED ([AddressID] ASC) WITH ( PAD_INDEX = OFF ,STATISTICS_NORECOMPUTE = OFF ,IGNORE_DUP_KEY = OFF ,ALLOW_ROW_LOCKS = ON ,ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO CREATE CLUSTERED INDEX [Clustered_City_Address1] ON [Person].[Address1] ( [City] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO |
El plan de ejecución actual para dicha consulta de SELECT * es igual en apariencia para las dos tablas. El operador que requiere tener mayores recursos se lo tienen en la exploración del índice agrupado.

El tiempo que se requiere para poder ejecutar el operador Clustered Index Scan es muy diferente.
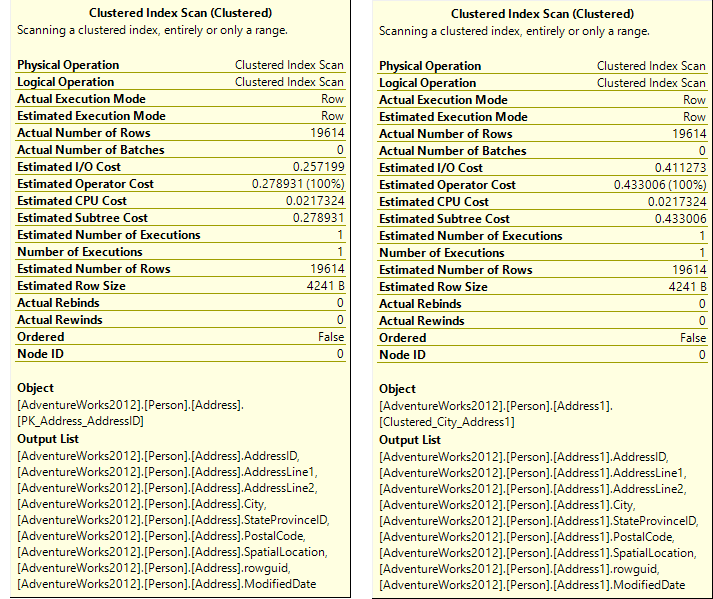
Tal como se muestra en las propiedades de Clustered Index Scan, el operador Estimado de entrada y salida (I/O), y el subárbol de costos es aproximadamente dos veces más alto en la tabla Person.Address1
Desventajas de usar índices
Tal como se indicó antes, los índices mal diseñados pueden crear una degradación significativa y hacer más lento el rendimiento de los servidores SQL Server. Sin embargo, aun así, los índices pueden brindar mejor rendimiento en algunas operaciones y por otro lado pueden producir sobrecarga en otros.
Si bien es verdad que la ejecución de SELECT como instrucción es más veloz con una tabla agrupada, INSERTs, UPDATEs Y DELETEs requieren de más tiempo en su ejecución debido a que no solo se actualizan los datos, sino que también se actualizan los índices. En índices agrupados, el tiempo se incrementa de manera significativa, así como los registros se deben mantener en orden correcto en las páginas de datos. Sea en un registro nuevo que se inserte o uno que se haya eliminado u otro que haya sido actualizado, esto requiere de una reorganización de registros.
Otro costo que se tiene al tener índices en tablas es que se usan más páginas de datos y mayor cantidad de memoria.
El costo del operador en un Plan Actual de Ejecución de Consultas de tablas mencionadas arriba se muestra a continuación. La tabla con índice agrupado de la columna del código principal es [Person]. [Address]. La tabla con el índice agrupado en una columna de clave no principal es [Person].[Address1]. Se han creado dos o más copias de la misma tabla, una con un índice no agrupado en una columna de clave primaria y la otra que no tiene ningún índice. Los datos de las cuatro tablas son los mismos.
| Índices agrupados en llave primaria | Índice agrupado en cualquier columna | Índice no agrupado | Sin Índices | |
| SELECT * | 0.28 | 0.43 | 0.28 | 0.28 |
| SELECT <list> | 0.18 | 0.43 | 0.28 | 0.28 |
| INSERT | 0.04 | 0.02 | 0.02 | 0.01 |
| UPDATE | 0.02 | 0.01 | 0.01 | 0.3 |
| DELETE | 0.05 | 0.02 | 0.02 | 0.3 |
Cuando se debe ejecutar la sentencia SELECT, el costo es bien bajo en el caso en que la lista de las columnas de retorno se especifica y se ejecuta según la instrucción de la tabla en que el índice agrupado se ha creado en la columna de la clave primaria. Su costo puede ser más alto en una tabla con índice agrupado que no es óptimo (tal como se muestra en la columna 2), luego se muestran las tablas con índices no agrupados o que no tengan índices.
En el momento de ejecutar el SELECT, su costo es el menor cuando la lista de las columnas de retorno se especifica y las instrucciones se ejecutan en la tabla en que el índice agrupado se ha creado en la columna de la clave primaria. El costo puede ser mayor en el caso en que una tabla con un índice agrupado no óptimo (que se muestra en la columna 2), que en las tablas con índices no agrupados o que no contengan índices.
Por otro lado, la instrucción SELECT con una tabla agrupada es más veloz. Ejecutar sentencias DELETE y UPDATEs toman más tiempo. Por lo mencionado anteriormente, el rendimiento de una tabla que tiene un índice no agrupado es el mismo para una tabla con un índice agrupado en una columna diferente que una con clave primaria.
Tome en cuenta que el INSERT en una tabla sin índices es más veloz que todas – esto es lo que se espera ya que no se requiere ni reordenar ni de actualizar índices. Usando la misma tabla, ejecutar sentencias UPDATEs y DELETEs resulta más caro. De la misma manera, este es el resultado esperado, así como el SQL Server que requiere de mayor tiempo para poder encontrar los registros específicos en la tabla.
Tal como se puede ver, los índices hacen que se aceleren algunas consultas, pero también pueden retrasar otras. En este artículo, se enseñaron algunas guías básicas para poder trabajar con índices agrupados y no agrupados y también ver cuáles son las columnas preferidas para lograr construir índices y cuáles son las que se deben evitar. Se debe poder llegar a encontrar un equilibrio entre los beneficios y las desventajas de los índices que nos proveen un óptimo rendimiento en las consultas y procedimientos almacenados.
Ver más
Para aprender más sobre índices de la base de datos por favor entrar a How to detect a high level of SQL Server database index fragmentation and fix it automatically.
Para poder ver y analizar planes y la ejecución de SQL Server gratis, vea: ApexSQL Plan.
Recursos
Directrices pare diseñar índices cluster
Stop Worrying About SQL Server Fragmentation
Crear índice únicos


Ella ha estado trabajando con SQL Server desde 2005 y tiene experiencia con SQL 2000 hasta SQL 2014.
Su tema favorito de SQL Server son las recuperaciones de desastres, la auditoría y el monitoreo de desempeño.
Vea todas las entradas de Milena “Millie” Petrovic
- Una guía de DBA para la solución de problemas de rendimiento de SQL Server – parte 2 – utilización de la supervisión - May 7, 2019
- Planes de ejecución de consultas – Entendiendo y leyendo los planes - April 19, 2018
- Mala indexación de base de datos – El asesino de las consultas SQL – recomendaciones - April 18, 2018