
Introduction
Data replication has been around for many decades. There are two primary types of data replication, logical and physical. This article covers a high-level view of logical replication, the differences between logical and physical replication, and the specifics of SQL Server transactional replication.
Logical replication common characteristics
Logical replication, also known as transactional replication, is a type of asynchronous replication and at a 10,000-foot level is very simple to understand. When two databases are set-up for replication, one being the source system and the other the target selected Data Manipulation Language (DML – Inserts, Updates and Deletes) and in some cases, Data Definition Language (DDL – Create Table, Truncate, etc.), through a series of processes and queues are read from the transaction log on the source system and then replayed on the target system. Hence, if performing an insert on the source system, that same insert is replayed on the target system. Also, selected DML or DDL, means you can pick and choose which tables to replicate, it does not have to be all the tables in the entire database.
This concept is quite different than physical/block level replication, where any changed block on the source system is replicated to the target system (discussed later on in this article).
The common characteristics of most, if not all, logical replication solutions is a process to read or scrape transactions from the transaction log (or make a call to a vendor-provided database API), store the transactions in either a dynamic memory queue, persistent queue at the file system level or an actual database, and then to have a process rebuild the transaction and apply it as a normal database user with the appropriate privileges for the tables being replicated to the target database.
There are many vendors in the replication space, which is discussed later in this article.
Logical replication use cases
Logical replication is a much more flexible solution than physical replication and offers many more use cases.
HA/DR (High Availability/Disaster Recovery)
Logical replication is not bound by the same limitations as physical replication and can replicate between different hardware platforms, operating systems, database versions, and in some cases different databases.
Most database vendors provide an HA/DR solution with an enterprise license for their database and it makes sense to use it where possible. However, it may not support replication between different hardware platforms, operating systems, or versions of the database. Use of a logical replication solution may need to be considered if the vendor- provided solution does not meet your requirements.
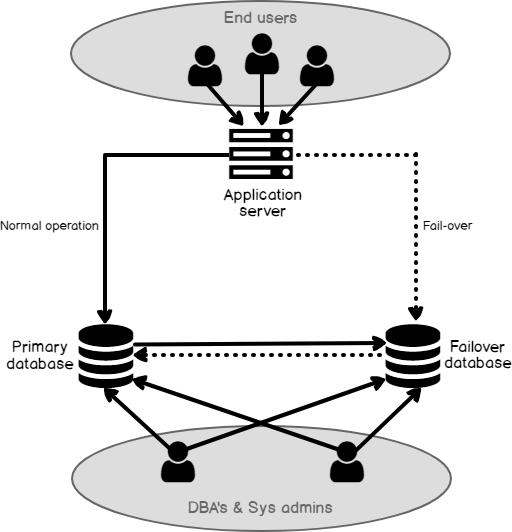
Logical replication solution target databases are generally available for read and write, which is good if managed correctly. Generally speaking, DBAs manage the replication solution and will have direct access to both source and target systems along with system administrators. Most end-users do not access the data servers directly but utilize an application that resides on a separate application server connected to a source data server as its repository. End-users accessing the application cause the application to make changes to the source data server repository, which is then replicated to the target server (See Figure 1). It is imperative that the DBA manages the target database so users cannot make any changes to the tables being replicated. In the case of an HA/DR scenario, all tables in the source database need to be replicated to the target.
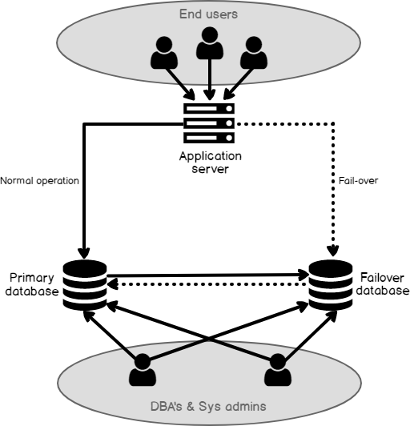
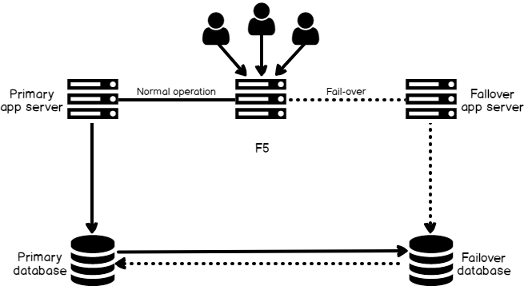
In an HA/DR scenario, the target system is an identical copy of the source system. If the source system goes down, the application server needs to be redirected to the target system, which will presume the role as the source system and start replicating back to the original source now acting as the target. Although the original source is down, logical replication solutions will store the changes until the source system recovers and then apply the queued changes when the database is accessible. Once everything gets caught up, the application server can be redirected back to the original source. Note that the redirecting of the application server is not managed by the replication solutions there are other solutions available to automate the fail-over process, such as F5, Big-IP, etc. (See Figure 2). Also, since the target system is available for read and write, reporting can be run off the target system to alleviate the load on the source system.
Off-load reporting
One of the most popular use cases for logical replication is off-loading of reporting to a target database. In a world of real-time, everyone wants current data. Hence the source on-line transaction processing system (OLTP) becomes the only source for live reporting, which can obviously cause performance issues.
The source OLTP system is usually very light on indexing. Indexing is not good for a database that gets a lot of inserts, update and delete activity, hence developers use as few indexes as possible. On the other hand, indexing is great for running queries. So you have a situation where queries are run against a database with little indexing which compounds the performance problems.
Replicating just the needed tables for reporting to a target system is a very valuable solution. Most logical replication solutions have the ability not only to pick and choose which tables to replicate, but can also apply “where clauses” to limit the data, and even choose which columns to replicate. Also, many solutions have the ability to do row level transformations including column concatenation, date manipulation, string manipulation, etc. Lastly, because it is a logical solution, the target system can be indexed as desired to improve query efficiency.
Zero downtime migrations, database upgrades and application upgrades
This particular topic can be an article in its own. Many organizations have a “five nine’s” uptime requirement on their applications which is 99.99999% uptime, less than 6 minutes downtime per year. Hence, they need technology that can allow them to perform patches, migrations, database upgrades, etc., with little to no downtime.
Performing zero downtime migrations and database upgrades are not terribly complex but very procedural and must be done in exact order. Performing zero downtime application upgrades, on the other hand, is a complex beast. It requires one to know the physical, as well as, logical differences between the current version of the application repository and the upgraded version so the differences can be mapped and transformed accordingly.
This use case is very valuable to organizations with tight uptime service level agreements (SLAs).
Active – active replication
Active – Active replication, also known as, Peer-to-Peer replication is by far the most complex replication use case. Since logical replication solutions are read/write, this becomes a valid use case in situations where organizations want to write to both systems and replicate back and forth for geographical reasons, such as the source server residing in New York and the target server in Los Angeles. In this type of scenario, active-active makes sense. The biggest issue with this use case is that applications are not designed to be Active – Active and will most likely need to be altered in some fashion to make this type of replication possible. The second biggest issue is managing conflicts, such as two users updating the same record at the same time. Some logical replications solutions provide for conflict resolution and detection (CDR), others do not.
Regardless if CDR is provided with the replication solution, here are some general rules that need to be followed when configuring for this use case (this is for two servers in an active – active scenario):
- All tables need to have a primary key.
- The primary keys’ values, as well as, unique index values must be unique to each system. Insert conflicts cannot really be managed at all and must be avoided. Uniquely generating primary key values and unique index values on each system avoid all insert conflicts.
- If using sequences or identity columns, they must be offset or ranged. Offset is the preferred method where sequences or identity columns are odd values on one system and even on the other.
If the replication solution being used has CDR rules built in, then these rules will need to be configured for update/update conflicts, delete/delete conflicts, and update/delete conflicts. If the solution does not have CDR rules, then conflicts must be avoided by making sure that from the system where the row originated, it can only be updated or deleted from that same system.
Replication to big data
With the growing popularity of Big Data, several of the major players in the logical replication arena have added Big Data to their list of replication targets.
Several companies can now replicate DML one-way to Hadoop, HDFS, Hive, Kafka, Hbase, etc.
Physical replication versus Logical replication
Physical or block level replication is also an option in the replication space. Hardware vendors, such as EMC, Veritas, etc., have been providing this type of solution for many years. Here are the pros and cons of logical verse physical replication.
Physical replication is generally implemented as synchronous replication, which requires a two-phase commit with a zero data loss recovery point objective (RPO). Even the fastest logical replication solutions will have some lag time, and since they are asynchronous it is not possible to guarantee a zero data loss RPO. Also, physical replication replicates any block that changes on the source system keeping everything in sync, not just the database. These two characteristics of block-level replication are its biggest advantage. However, physical replication does come with its downside.
Physical replication must be a completely homogeneous environment. The source and target systems need to be the same hardware platform, operating system, database version, etc. There is no sub-setting of the data or table selection, everything gets replicated. There is no transformation capability, hence, block level replication fits one use case, HA/DR. The target system is not open for reads or writes, which makes Active – Active and reporting off the system not possible. Also, because it is synchronous replication, geographical limits will most likely apply due to network constraints. Lastly, when switching to the target system for fail-over, the target database needs to be recovered. If there are stringent SLAs on uptime, one or two fail-overs in a given year may exceed the SLA for uptime.
Thus, choosing between logical or physical replication really depends on the particular environment, use case, SLAs and geographical location of servers.
Vendors
There are many vendors in the logical replication space; however, three stand out as the most predominant.
IBM purchased DataMirror several years ago and re-branded their replication solution as IBM InfoSphere CDC. DataMirror was a heterogeneous logical replication solution that had a niche for DB2 I series, so the acquisition made a lot of sense for IBM. IBM InfoSphere CDC can replicate cross platform, cross database and integrates with IBM’s ETL solution, DataStage. It supports Active-Active replication and has limited conflict detection and resolution (CDR).
Quest Software has expanded SharePlex to somewhat heterogeneous database replication by supporting SQL Server in addition to Oracle. It can also replicate to Big Data and supports Active-Active replication with CDR. Shareplex uses dynamic memory queues to queue transactions.
Prior to the acquisition of a small San Francisco based company called GoldenGate several years ago, Oracle had the following replication solutions:
Oracle Advanced Replication
Physical DataGuard
Logical DataGuard
Streams
Active DataGuard
Advanced Replication was Oracle’s first trigger-based solution that does still exist, but has been deprecated.
All other solutions are still supported except Streams (replacement for advanced replication), which has been deprecated due to the GoldenGate acquisition.
Oracle GoldenGate (OGG) can replicate cross platform, cross database and integrates with Oracle’s ETL solution ODI (Oracle Data Integrator). It supports Active-Active replication and has complete CDR. It can also replicate to Big Data. OGG uses persistent queues at the file system level to queue transactions.
SQL Server replication overview and limitations
Much like Oracle, SQL Server has multiple types of replication solutions including Snapshot, Merge and Transactional replication (see related links for a brief description of each).
The rest of the article will focus on transactional replication. SQL Server has the same components as all logical replication solutions. It just uses different terminology that is defined in the next section of this article. SQL Server transactional replication does have some heterogeneous capability, but it appears that feature will be deprecated in future releases (see related links for publishers and subscribers).
It appears transactional replication going forward with the next release will be for SQL Server to SQL Server with support for Active – Active with no CDR, which means, as discussed above, all conflicts must be avoided. This is done by making sure that from the system where the row originated, it can only be updated or deleted from that same system. Also, SQL Server Transactional replication has no capability to replicate to Big Data.
Lastly, only tables with primary keys can be replicated with SQL Server Transactional replication. Other solutions allow for the replication of tables with no primary key. However, on update and delete operations the entire row is considered the primary key, and all columns will be used in the where clause (except LOB data types), which is not very efficient.
SQL Server transactional replication architecture
SQL Server transactional replication uses a publish/subscribe paradigm. Publications (source systems) define what articles to replicate and an article is merely a table. Typical to most logical replications solutions, you can pick and choose what tables, columns, and records (via a where clause) to replicate within a source database. Once articles to replicate have been defined, a process called the log reader agent reads the transaction log and captures changes made to the articles (tables) that have been defined in the publication. When it finds the changes, it writes them to a database called the distribution database, which can reside on the publishing server or on a middle tier server, which is the recommended approach. Then finally, there’s a process called the distribution agent which reads from the distribution database and applies the transactions to the subscribers which are the articles (tables) in the target databases. The distribution agent can apply the transactions to multiple subscribers (see Figure 3).
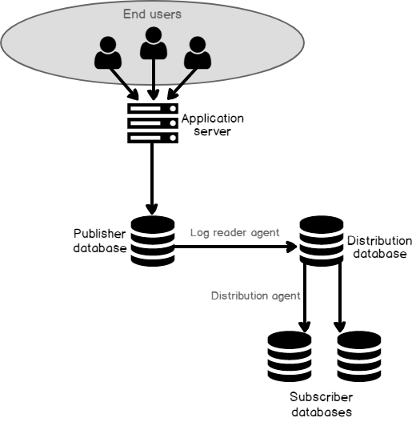
Before a new transactional replication Subscriber can receive changes from the distribution agent, the Subscriber must be seeded with tables with the same schema and data as the tables at the Publisher. The initial dataset can be created by a process called the Snapshot Agent and be applied by the Distribution Agent. The initial dataset can also be created through a SQL Server database backup.
Summary
I hope this article has enlightened you on the architecture and use cases of transactional/logical replication and has given you a basic understanding of the architecture of SQL Server transactional replication.

After Quest, Thomas moved to GoldenGate (later purchased by Oracle) and specialized on GoldenGate’s replication solution, which supports many relational databases including Oracle, MSSQL Server, Sybase, DB2, etc. Thomas retired in mid-2017 after working with GoldenGate software for over 11 years.
Thomas piloted data replication solutions in a pre-sales capacity for some of the biggest telecommunication companies and banking institutions in the country, such as Verizon, AT&T, Wells Fargo, Capital One, etc.
- Logical SQL Server data replication 101 - May 4, 2018