
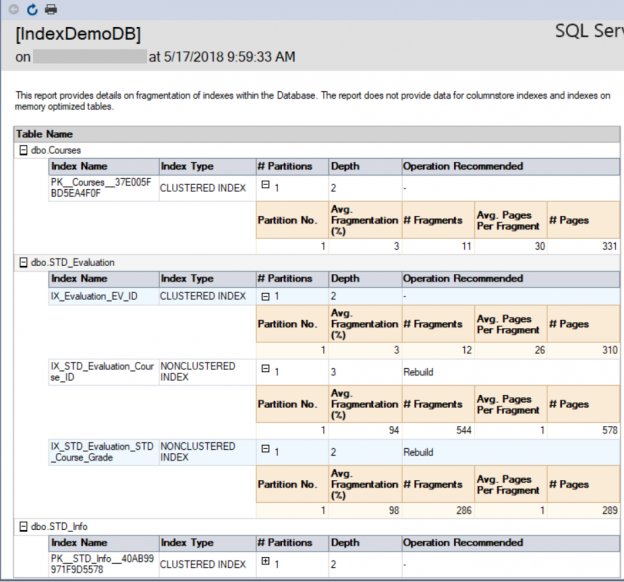
En los artículos previos de estas series (véase el artículo entero TOC abajo), discutimos la estructura interna de ambas tablas SQL Server e Índices, las mejores prácticas que puedes seguir para diseñar un índice apropiado, lista de operaciones que puedes realizar en los índices SQL Server, cómo diseñar índices Agrupados y No agrupados efectivos, los diferentes tipos de índices SQL Server, arriba y más allá de la clasificación de Índices Agrupados y No agrupados y finalmente cómo ajustar el rendimiento de las consultas malas usando los diferentes tipos de Índices SQL Server. En este artículo, vamos a discutir cómo obtener información estadística sobre la estructura del índice y el uso de la información del índice.
Para este punto en estas series, estamos familiarizados con la estructura del índice de SQL Server y cómo diseñar y crear los índices más convenientes, del cual el Optimizador de Consultas SQL Server va a tomar definitivamente beneficios., al hacer más rápido el rendimiento de nuestras consultas. Después de crear los índices, deberíamos saber proactivamente cuáles índices son mal usados, o totalmente no usados para tomar la correcta decisión de mantener estos índices o remplazarlos por unos más eficientes. Recuerda que removiendo los índices no usados o índices malos, va a mejorar el rendimiento de la modificación de información de las consultas, que necesita replicar el mismo cambio de tabla a los índices, y reducir el mantenimiento de índices y costo de almacenaje.
Información de la estructura del Índice
La primera categoría de la información que necesitamos obtener sobre los índices es la lista de índices disponibles en nuestra base de datos, la lista de columnas participando en cada índice y las propiedades de esos índices. El modo clásico de obtener esa información sobre índices es expandiendo los nodos de Índices bajo la tabla de base de datos, luego hacer clic derecho en cada índice, y escoger la opción de Propiedades como se muestra abajo:
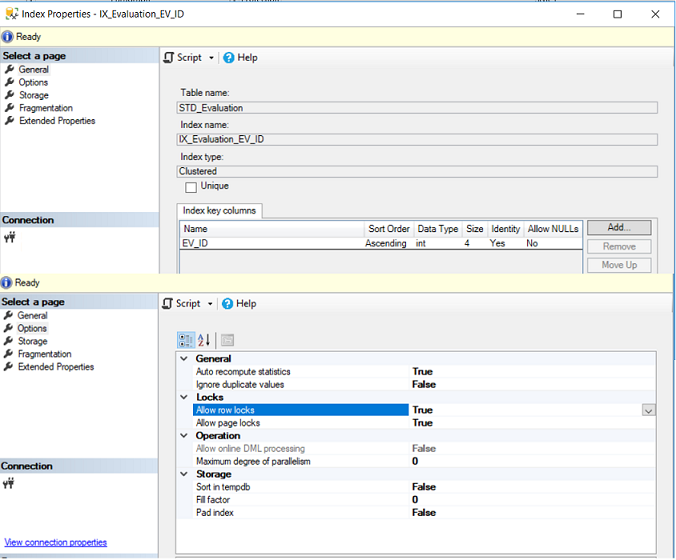
Donde puedes abrir la lista de columnas participando en el índice clave y diferentes propiedades del índice seleccionado. El problema con obtener la información de los índices usando el método de interface de usuario es que necesitas abrir un índice a la vez para cada tabla. Puedes imaginar el esfuerzo requerido para verificar todos los índices en una base de datos específica. La lista de propiedades de un índice seleccionado puede ser mostrada abajo:
La segunda forma de obtener meta-información sobre la estructura de los índices es el procedimiento almacenado de sistema sp_helpindex, al proveer el nombre de la tabla que necesita para listar sus índices. Para poder obtener información sobre todos los índices en una base de datos específica, necesitas ejecutar el número sp_helpindex de tiempo igual al número de tablas de tu base de datos. Para la base de datos previamente creada que tiene tres tablas, necesitamos ejecutar el sp_helpindex tres veces como se muestra abajo:
|
1 2 3 4 5 |
sp_helpindex '[dbo].[STD_Evaluation]' GO sp_helpindex '[dbo].[Courses]' GO sp_helpindex '[dbo].[STD_Info]' |
El nombre del índice, las columnas que participan en el índice clave, y la descripción de ese índice, como el tipo de índice, serán retornados del procedimiento almacenado de sistema sp_helpindex, como se muestra en el resultado de abajo:
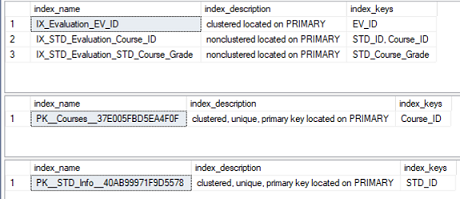
La principal desventaja de usar el procedimiento almacenado de sistema sp_helpindex para recuperar la información de los índices de una base de datos específica es que necesitas ejecutarla para cada tabla, como se mencionó previamente. Además, el procedimiento almacenado de sistema sp_helpindex retorna solo las columnas clave que están participando en el índice clave. Puedes ver que las columnas que son añadidas usando la cláusula INCLUDE como columnas no-clave no serán listadas usando ese procedimiento almacenado.
La tercera forma, y la mejor para mí, de obtener meta-información sobre la estructura del índice es consultando la vista de administración de sistema dinámico sys.indexes. El sys.indexes contiene una fila por cada índice en la tabla o vista. Es recomendado unir sys.indexes DMV con otros sistemas DMVs, como las columnas sys.index, sys.columns, y sys.tables para retornar información significativa sobre estos índices. Un buen ejemplo de uso del sys.indexes DMV, que necesita ser ejecutado una vez por cada base de datos, es mostrada abajo:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT Tab.name Table_Name ,IX.name Index_Name ,IX.type_desc Index_Type ,Col.name Index_Column_Name ,IXC.is_included_column Is_Included_Column FROM sys.indexes IX INNER JOIN sys.index_columns IXC ON IX.object_id = IXC.object_id AND IX.index_id = IXC.index_id INNER JOIN sys.columns Col ON IX.object_id = Col.object_id AND IXC.column_id = Col.column_id INNER JOIN sys.tables Tab ON IX.object_id = Tab.object_id |
El resultando de la consulta previa, que incluye el nombre de la tabla, el nombre del índice, el tipo de índice y finalmente el nombre y el tipo de columnas clave y no-clave participando en estos índices, será como mostrado abajo:
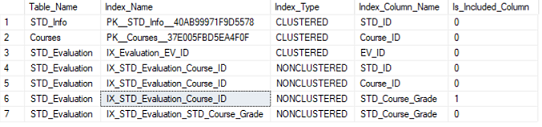
La consulta previa puede ser rescrita, para listar más propiedades de los índices, como se muestra abajo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT Tab.name Table_Name ,IX.name Index_Name ,IX.type_desc Index_Type ,Col.name Index_Column_Name ,IXC.is_included_column Is_Included_Column ,IX.fill_factor ,IX.is_disabled ,IX.is_primary_key ,IX.is_unique FROM sys.indexes IX INNER JOIN sys.index_columns IXC ON IX.object_id = IXC.object_id AND IX.index_id = IXC.index_id INNER JOIN sys.columns Col ON IX.object_id = Col.object_id AND IXC.column_id = Col.column_id INNER JOIN sys.tables Tab ON IX.object_id = Tab.object_id |
Y el resultando que contiene propiedades de índice extra que se muestra abajo:

Información de fragmentación de Indices
El objetivo principal de crear un índice SQL Server es hacer más rápido el rendimiento de recuperación de información y mejorar el rendimiento en general de las consultas. Pero cuando la información de la tabla subyacente es cambiada o eliminada, este cambio debería ser replicado en la tabla de índices relacionada. En el tiempo, y como resultando de muchas operaciones de inserción, actualización y eliminación, los índices se volverán fragmentados, con un número largo de páginas desordenadas con espacio libre en estas páginas, degradando el rendimiento de las consultas, debido al aumento del número de páginas para ser escaneadas para recuperar la información requerida. Como resultado el índice puede ser ignorado en la mayoría de los casos por el Optimizador de Consultas SQL Server. Otra causa del problema de fragmentación es la división de la página, en la cual la página será dividida en dos páginas cuando los valores insertados o actualizados nuevamente no entren en el espacio disponible en las páginas, debido a una mala configuración del Fill Factor y opciones de creación de índice pad_index, mencionado en detalle en los artículos previos de estas series.
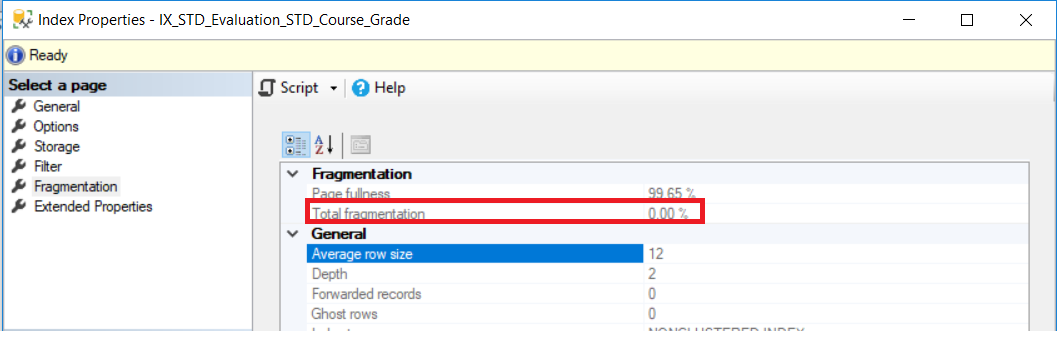
La forma correcta de obtener el porcentaje de fragmentación de un índice es de la pestaña de Fragmentación de la ventana de Propiedades del índice. Para los índices nuevos creados, el nivel de fragmentación será de 0%, como se muestra en la ventana de Propiedades de Índice de abajo:
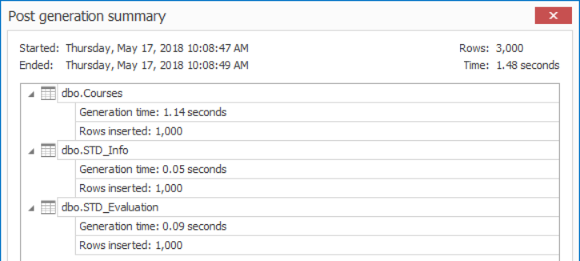
Si tratamos de llenar las tablas previamente creadas con mil registros extra, usando la herramienta APEXSQL Generate como se muestra en la captura de pantalla de abajo:
Y verificar el porcentaje de fragmentación del mismo índice otra vez, verás que el índice se vuelve muy fragmentado, debido a la operación de insertar, con un porcentaje de fragmentación igual a 99 %, como se muestra en la ventana de Propiedades del Índice de abajo:

Verificar el porcentaje de fragmentación de todos los índices en una base de datos específica, usando el método UI requiere un gran esfuerzo, ya que necesitas verificar un índice a la vez. Otro modo de obtener información del porcentaje de fragmentación sobre todos los índices de la base de datos de un solo tiro es al consultar la función de administración dinámica sys.dm_db_index_physical_stats, que es introducida por la primera vez en SQL Server 2005. El sys.dm_db_index_physical_stats DMF puede ser unido con el sys.indexes DMV para retornar el porcentaje de fragmentación de todos los índices bajo la base de datos específica, como en la consulta mostrada abajo:
|
1 2 3 4 5 6 7 8 |
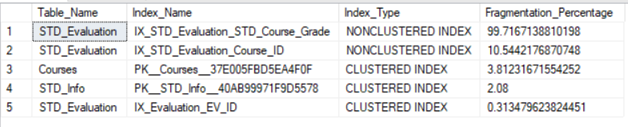
SELECT OBJECT_NAME(IDX.OBJECT_ID) AS Table_Name, IDX.name AS Index_Name, IDXPS.index_type_desc AS Index_Type, IDXPS.avg_fragmentation_in_percent Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) IDXPS INNER JOIN sys.indexes IDX ON IDX.object_id = IDXPS.object_id AND IDX.index_id = IDXPS.index_id ORDER BY Fragmentation_Percentage DESC |
The result in our case will be as shown below:
Para superar este problema, deberíamos realizar una operación apropiada de mantenimiento, con los valores óptimos FillFactor y Pad_index. En este artículo, vamos a parar al punto de obtener la información de fragmentación del índice. En el siguiente artículo de estas series, vamos a ver como arreglar el problema de fragmentación del índice.
Información de uso del índice
El SQL Server nos permite crear hasta 999 índices No agrupados y un índice Agrupado por cada tabla. Este gran número de índices permitidos, pero no recomendados, nos ayuda en cubrir y mejorar el rendimiento de un gran número de consultas que tratan de recuperar la información de la tabla de la base de datos. Los inconvenientes de tener muchos índices en la tabla incluyen alentar las operaciones de modificación de información, debido al hecho que todos los cambios realizados en la tabla deberían ser replicados a los índices relacionados. Además, este gran número de índices requiere almacenaje extra y debería ser todo mantenido, a pesar que de algunos de estos índices no están usados, dañando el rendimiento en general, en vez del mejoramiento esperado de él.
Así que, se vuelve la tarea principal para el administrador de base de datos el monitorear regularmente el uso de estos índices, para identificar los índices que están mal usados, o no usados, y abandonarlos o remplazarlos con unos más óptimos si es requerido. Los índices que están mal usados incluyen aquellos que tienen un gran número de escritura con pocos números de lecturas y un gran número de escaneos con pocos números de búsquedas.
El SQL Server guarda la información sobre la estadística del uso del índice automáticamente en el sistema de tablas y descarga la información cuando el servicio de SQL Server es reiniciado. Para acceder a este sistema de tablas el SQL Server nos provee con vistas de administración dinámica sys.dm_db_index_usage, que ayuda a encontrar el uso de los índices de la base de datos desde el ultimo reinicio del servicio SQL Server.
El script T-SQL de abajo usa el sys.dm_db_index_usage_stats DMV, junto con otro Sistema de vistas de catálogo, para retornar información significativa y útil sobre cada índice y su uso desde el último reinicio. Esta información incluye el nombre de la tabla, donde el índice es creado, el nombre y tipo de ese índice, el tamaño del índice, el número de búsquedas, escaneos, consultas y actualizaciones realizadas en el índice y finalmente las últimas fechas de búsquedas, escaneos, consultas y actualizaciones, como se muestra abajo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT OBJECT_NAME(IX.OBJECT_ID) Table_Name ,IX.name AS Index_Name ,IX.type_desc Index_Type ,SUM(PS.[used_page_count]) * 8 IndexSizeKB ,IXUS.user_seeks AS NumOfSeeks ,IXUS.user_scans AS NumOfScans ,IXUS.user_lookups AS NumOfLookups ,IXUS.user_updates AS NumOfUpdates ,IXUS.last_user_seek AS LastSeek ,IXUS.last_user_scan AS LastScan ,IXUS.last_user_lookup AS LastLookup ,IXUS.last_user_update AS LastUpdate FROM sys.indexes IX INNER JOIN sys.dm_db_index_usage_stats IXUS ON IXUS.index_id = IX.index_id AND IXUS.OBJECT_ID = IX.OBJECT_ID INNER JOIN sys.dm_db_partition_stats PS on PS.object_id=IX.object_id WHERE OBJECTPROPERTY(IX.OBJECT_ID,'IsUserTable') = 1 GROUP BY OBJECT_NAME(IX.OBJECT_ID) ,IX.name ,IX.type_desc ,IXUS.user_seeks ,IXUS.user_scans ,IXUS.user_lookups,IXUS.user_updates ,IXUS.last_user_seek ,IXUS.last_user_scan ,IXUS.last_user_lookup ,IXUS.last_user_update |
El número de Búsquedas indica el número de veces que el índice es usado para encontrar una fila específica, el número de Escaneos muestra el número de veces que las páginas hoja en el índice son escaneadas, el número de Consultas indica el número de veces que un índice Agrupado es usado por el índice No Agrupado para buscar la fila entera y el número de Actualizaciones muestra el número de veces que la información del índice es modificada.

El resultado en nuestro caso será como abajo:
- Todos los valores cero significa que la tabla no es usada, o el servicio SQL Server reinició recientemente.
- Un índice con cero o pequeño número de búsquedas, escaneos o consultas y un gran número de actualización es un índice inútil y debe ser removido, después de verificar con el propietario del sistema, ya que el principal objetivo de añadir el índice es hacer más rápidas las operaciones de lectura.
- Un índice que es escaneado excesivamente con cero o pequeño número de búsquedas significa que el índice es mal usado y debería ser remplazado por uno más óptimo.
- Un índice con un gran número de consultas significa que necesitamos optimizar el índice al añadir las columnas frecuentemente consultadas a las columnas de índice no-clave existentes usando la cláusula INCLUDE.
- Una tabla con un gran número de Escaneos indica que las consultas SELECT * son excesivamente usadas, recuperando más columnas de lo que es requerido, o las estadísticas de índice deben ser actualizadas.
- Un índice agrupado con un gran número de Escaneos significa que un nuevo índice No agrupado debería ser creado para cubrir las consultas no cubiertas.
- Las fechas con valores NULL significan que esta acción no ha ocurrido todavía.
- Grandes escaneos están BIEN en pequeñas tablas
- Si tu índice no está aquí, entonces ninguna acción es realizada en ese índice todavía.
Las lecturas previas te dan buenos indicadores sobre el uso de la base de datos de índices, pero necesitas ver a profundidad antes de decidir de remover o remplazar un índice. Puedes usar los resultados previos en conjunción con el resultado de la función de administración dinámica sys.dm_db_index_physical_stats para tener una vista entera el uso de índices. El sys.dm_db_index_physical_stats DMF retorna información sobre las actividades bajas de I/O, como las operaciones INSERT, UPDATE y DELETE, ocurriendo en ese índice, por cada partición de tabla.
El sys.dm_db_index_physical_stats DMF toma el database_id, el object_id, el index_id y el número de partición como parámetros. Proveyendo valores NULL O DEFAULT para el sys.dm_db_index_physical_stats DMF retornará una fila por cada partición en la base de datos. Similar a otros DMOs, el sys.dm_db_index_physical_stats DMF retorna información cumulativa que será actualizada cuando el servicio de SQL Server es reiniciado. Reconstruir, reorganizar o desactivar el índice no afectará sus estadísticas. Un índice tendrá una entrada en el sys.dm_db_index_physical_stats DMF solo si el objeto de meta-información cache que representa este índice está disponible.
El script T-SQL de abajo puede ser usado para consultar el sys.dm_db_index_physical_stats DMF, unido con otro DMOs para tener información más significante, puede ser usado para recuperar las operaciones estadísticas I/O para cada índice en la actual base de datos. Esta información incluye el nombre de la tabla sobre la cual el índice es creado, el nombre y tamaño del índice y finalmente el número de operaciones INSERT, UPDATE y DELETE ocurridas en esos índices. El script será como el mostrado abajo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT OBJECT_NAME(IXOS.OBJECT_ID) Table_Name ,IX.name Index_Name ,IX.type_desc Index_Type ,SUM(PS.[used_page_count]) * 8 IndexSizeKB ,IXOS.LEAF_INSERT_COUNT NumOfInserts ,IXOS.LEAF_UPDATE_COUNT NumOfupdates ,IXOS.LEAF_DELETE_COUNT NumOfDeletes FROM SYS.DM_DB_INDEX_OPERATIONAL_STATS (NULL,NULL,NULL,NULL ) IXOS INNER JOIN SYS.INDEXES AS IX ON IX.OBJECT_ID = IXOS.OBJECT_ID AND IX.INDEX_ID = IXOS.INDEX_ID INNER JOIN sys.dm_db_partition_stats PS on PS.object_id=IX.object_id WHERE OBJECTPROPERTY(IX.[OBJECT_ID],'IsUserTable') = 1 GROUP BY OBJECT_NAME(IXOS.OBJECT_ID), IX.name, IX.type_desc,IXOS.LEAF_INSERT_COUNT, IXOS.LEAF_UPDATE_COUNT,IXOS.LEAF_DELETE_COUNT |
El resultado en nuestro caso será como:

El resultando previo nos provee con información más detallada sobre el número de información insertada y operaciones de modificación ocurridas en cada índice. Este resultado en conjunción con el resultado sys.dm_db_index_usage_stats DMV ayuda a decidir si necesitamos remover ese índice o remplazarlo con uno más óptimo.
Reportes standard SQL
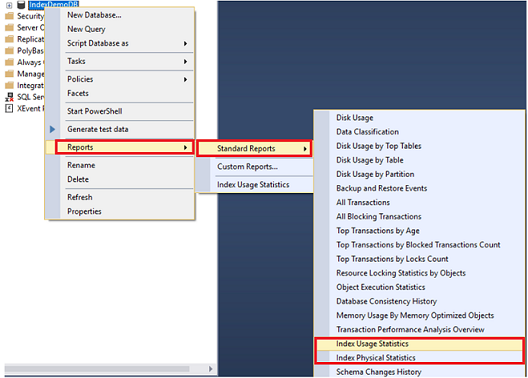
El SQL Server nos provee de dos reportes incorporados que nos ayudan a monitorear la base de datos de fragmentación de índices y el uso de estadísticas, el Index Usage Statistics y el Index Physical Statistics. Estos reportes standard usan los DMOs previamente descritos, y la información de los reportes será actualizada cuando el servicio de SQL Server es reiniciado. Ambos reportes pueden ser vistos haciendo clic derecho en la base de datos, de la cual necesitas monitorear sus índices, escoge Reports -> Standard Reports y selecciona el reporte Index Usage Statistics o Index Physical Statistics, como se muestra abajo:
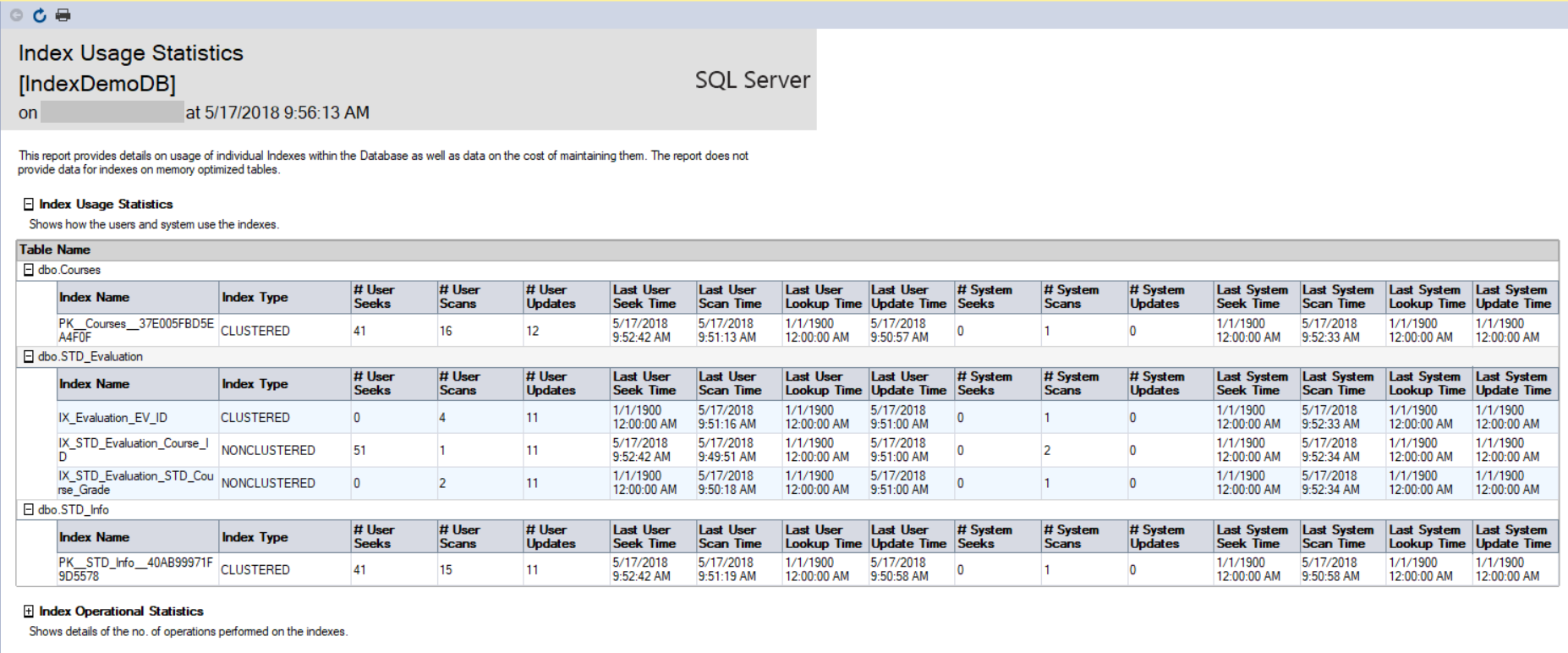
El primer reporte es el reporte de Index Usage Statistics, que consiste de dos partes: el reporte Index Usage Statistics que muestra estadísticas sobre el número de Escaneos, Búsquedas, Actualizaciones y Consultas con la fecha más actual por cada operación, que es recuperada al consultar el sys.dm_db_index_usage_stats DMV, como se muestra abajo:
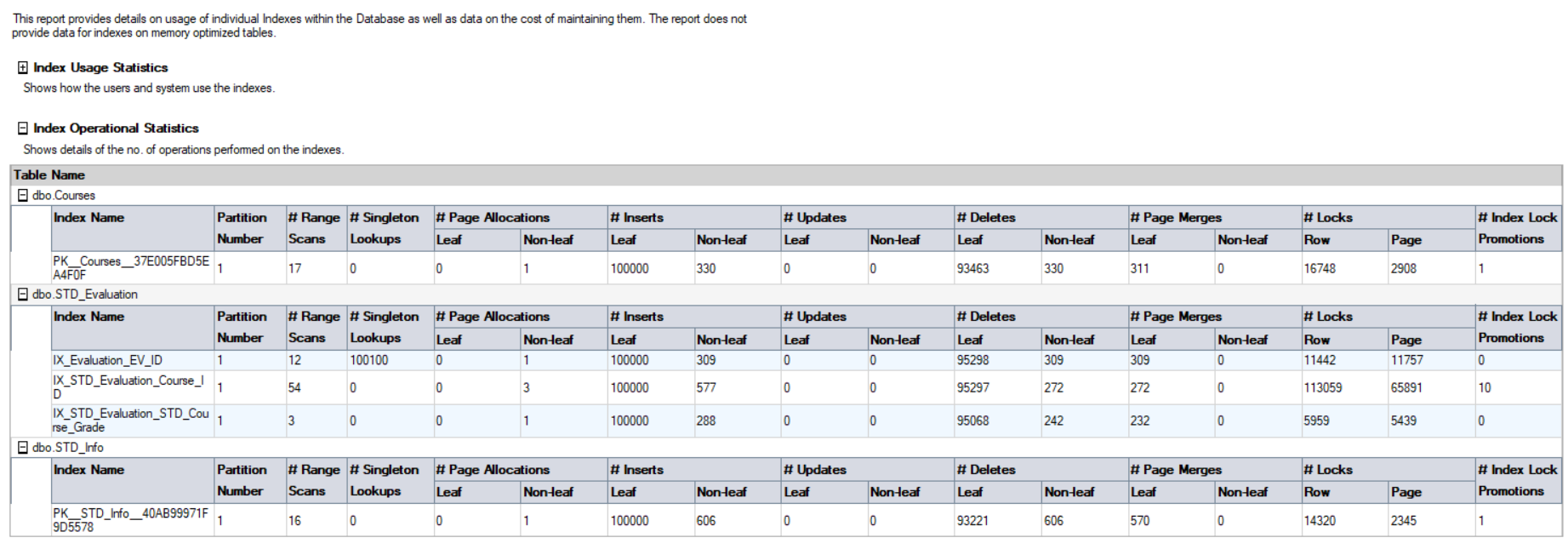
Nota que el resultado en el reporte difiere del resultado DMV previo, como el servicio SQL Server es reiniciado en mi máquina y una diferente carga de trabajo es realizada en esa base de datos. La segunda parte de ese reporte es el Index Operational Statistics, que retorna el número si las operaciones I/O INSERT, UPDATE y DELETE ocurren en la base de datos. Las estadísticas en ese reporte son recuperadas al consultar el sys.dm_db_index_operational_stats(db_id(),null,null,null) DMF ,como se muestra abajo:
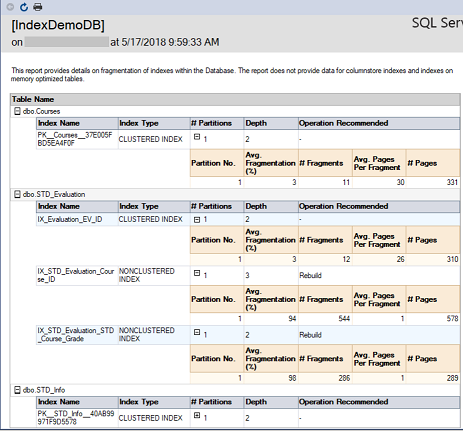
El segundo reporte es el reporte Index Physical Statistics, que retorna estadísticas sobre la partición del índice, porcentaje de fragmentación y el número de páginas en cada partición de índice. Este reporte también da las recomendaciones para reconstruir o reorganizar el índice dependiendo del porcentaje de fragmentación del índice. La recomendación provista por ese reporte no toma en consideración el tamaño de la tabla. Si tratas de reconstruir un índice en una tabla pequeña, puedes todavía recibir la misma recomendación de ese reporte. El reporte en nuestro caso será como es mostrado abajo:
En este artículo hemos descrito los diferentes métodos que pueden ser usados para obtener información estadística sobre la estructura y uso de los índices SQL Server. Sigue sintonizado para el último artículo en estas series, en el cual vamos a describir cómo mantener los índices SQL Server.
Tabla de contenido
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.


He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019