
You already understand the benefits of the BPE and how to deal with the feature, now it’s time to better understand how it works.
Here we are, the last article of this Buffer Pool Extension series. We came from the explanation of what is the Buffer Pool, made an introduction of the new In-Memory technology and saw on what the Buffer Pool Extension can help in keep a stable environment, and finally, the part 3 showed how to implement the Buffer Pool Extension in your SQL Server 2014 system.
Now, on this last part, we will add more details on how the Buffer Pool Extension works, and see the behavior of SQL Server is when this feature is enabled.
To refresh what we already saw in the other articles, I’ll add a few points as a reminder:
- Buffer Pool Extension is a SQL server 2014 new feature.
- This feature is supported also in the Standard Edition of SQL Server.
- Buffer Pool Extension is only supported in 64 bit servers.
- You can enable and disable the feature without interfere in the instance’s availability – No restart is required.
- Buffer Pool Extension is a transparent solution – No application change is needed.
- Buffer Pool Extension deals with Clean Pages only – No possibility of data loss.
- The objective is to improve the OLTP like workload systems, anyway systems with a very high number of writes may not take advantage of this feature.
- Enable the Buffer Pool Extension in systems with the In-Memory working is a good practice, as both technologies are complimentary.
- The Buffer Pool Extension is nothing more than a file, placed in the fastest disk possible. Anyway, if you have the option to add more memory, better go for it!
I listed the most important points, but if you are reading this article without reading the previous ones, I recommend to check the third part, where I showed how to enable, change and disable this feature as well as the options to monitor and troubleshoot the Buffer Pool Extension using DMVs, xEvents, and Performance Counters.
How it works?
Now that we have all the basic information, we can dive more into details… The objective of the Buffer Pool Extension is to create a group of the most used pages. I categorized this group in two parts: The hot area and the warm area.
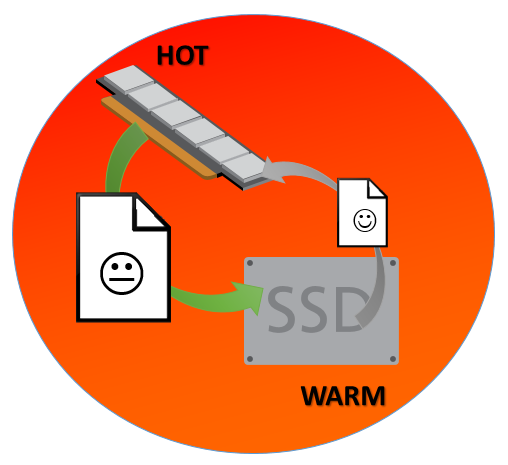
As you can see in the picture, the hot area is located on the memory side, where the Buffer Pool is storing its pages. On the other hand, the warm area is the SSD, where the Buffer Pool Extension is located. You can also observe that the pages are moving in cycles, from the Buffer Pool to the Buffer Pool Extension and the inverse, from the Buffer Pool Extension to the Buffer Pool. We will understand better how it works more ahead.
With the SQL Server instance being online for a certain amount of time, the almost closed ecosystems will be formed, and a group of most requested pages will be available into this, avoiding the disk access in order to fetch pages. That’s why the performance is improved. You can notice that the page going to the Buffer Pool is happy, and the other pager is not in a good mood… I represented this that way to show that the good place to be is the Buffer Pool, where the “Super Star” pages are located. Worse than being “demoted” to the Buffer Pool Extension, is to be simply evicted, which means that the page is not even in the most popular pages.
With this explanation, we can get a lot of information already, but let’s take a look on three different cases:
- How the Buffer Pool Extension is filled?
- How a page request works when the Buffer Pool Extension is enabled?
- What if we have duplicated pages in the Buffer Pool Extension and Buffer Pool?
How the Buffer Pool Extension is filled?
All the story starts when the Buffer Pool decides to evict a page. This decision can be caused by different reasons.
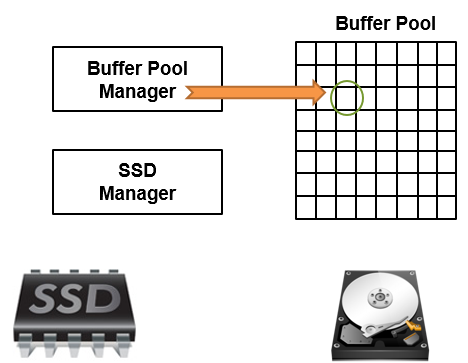
The page evicted by the Buffer Pool will be analyzed and, based on the certain thresholds, it may be selected to be a part of the Buffer Pool Extension. If it’s not interesting enough to be placed in the Buffer Pool Extension, the page will keep its way to the trash can. Once it is evicted, the only way to access the page is to go to the disk to get it.
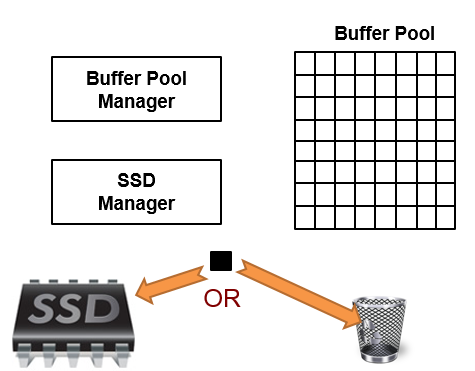
There’s a nuance here: the Buffer Pool Extension may be full. If you remember, we need to set a size to enable the feature. In this case, the Buffer Pool Extension will use a Replacement Policy to evict pages in order to open space for other, and more interesting, pages coming from the Buffer Pool.
How a page request works?
With the Buffer Pool Extension enabled, the page request flow slightly changes.
Let’s say that some user ran a query, and all the needed pages are already in the Buffer Pool. What happens in this case is very simple: the Buffer Pool returns the page handle and we are done.
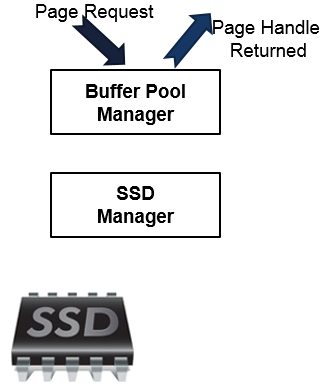
Let’s now imagine that some of the requested pages is not in the Buffer Pool. Having the Buffer Pool Extension enabled, the Buffer Pool will ask the Buffer Pool Extension for this page. If the page is present at the Buffer Pool Extension, a copy of the page is made to the Buffer Pool and the page handle is returned to the requester. Notice that on that moment, the “same” page is located both in the Buffer Pool and its Extension.
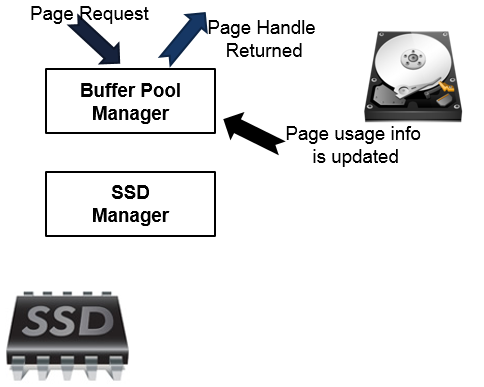
To complete the flow, let’s pretend that the page is not in the Buffer Pool Extension also. Now the worst case scenario: the page should be fetched from the disk. Why it’s bad? Because disk access is very expensive, comparing to the memory and also SSD. At this point, the page is fetched from the disk and copied to the Buffer Pool, which returns the page handle.
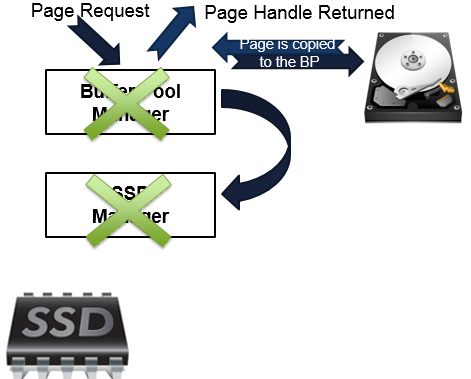
What if a duplicated page is modified?
Finally, the last case. Do you remember when a page copy, from the Buffer Pool Extension to the Buffer Pool was made? The page was on both ends, and the BPE copy is a serious candidate to be evicted. Anyway, while we have two copies of the pages in the cache, the page can be modified. What happens with the copy in the Buffer Pool Extensions? It’s invalidated and the page is evicted.
We’ve reached the end of this series, I hope it helped you to better understand the purpose and benefits of the Buffer Pool Extension. This is a great adding to the SQL Server and I’m sure that it’s going to be very useful in the future. Thank you for reading and I hope to “see you” in another article.

With experience working in Portugal, Holland, Germany and United Kingdom, he's always available to learn and share his knowledge, in order to contribute to SQL Server community,
View all posts by Murilo Miranda
- Understanding backups on AlwaysOn Availability Groups – Part 2 - December 3, 2015
- Understanding backups on AlwaysOn Availability Groups – Part 1 - November 30, 2015
- AlwaysOn Availability Groups – Curiosities to make your job easier – Part 4 - October 13, 2015