
I attended a TDWI conference in May 2016 in Chicago. Here I got a hint about the datatype hierarchyid in SQL Server which could optimize and eliminate the good old parent/child hierarchy.
Until then I (and several other in the class) hadn’t heard about the hierarchyid datatype in SQL Server.
So here’s an article covering some of the aspects of the datatype hierarchyid – including:
- Introduction
- How to use it
- How to optimize data in the table
- How to work with data in the hierarchy-structure
- Goodies
Introduction
The datatype hierarchyid was introduced in SQL Server 2008. It is a variable length system datatype. The datatype can be used to represent a given element’s position in a hierarchy – e.g. an employee’s position within an organization.
The datatype is extremely compact. The storage is dependent in the average fanout (fanout = the number of children in all nodes). For smaller fanouts (0-7) the typical storage is about 6 x Log A * n bits. Where A is the average fanout and n in the total number of nodes in the tree. Given above formula an organization with 100,000 employees and a fanout of 6 levels will take around 38 bits – rounded to 5 bytes of total storage for the hierarchy structure.
Though the limitation of the datatype is 892 bytes there is a lot of room for extremely complex and deep structures.
When representing the values to and from the hierarchyid datatype the syntax is:
[level id 1]/[level id 2]/..[level id n]
Example:
1/7/3
The data between the ‘/ can be of decimal types e.g. 0.1, 2.3 etc.
Given two specific levels in the hierarchy a and b given that a < b means that b comes after a in a depth first order of comparison traversing the tree structure. Any search and comparison on the tree is done this way by the SQL engine.
The datatype directly supports deletions and inserts through the GetDescendant method (see later for full list of methods using this feature). This method enables generation of siblings to the right of any given node and to the left of any given node. Even between two siblings. NOTE: when inserting a new node between two siblings will produce values that are slightly less compact.
How to use it
Given an example of data – see compete SQL script at the end of this post to generate the example used in this post.
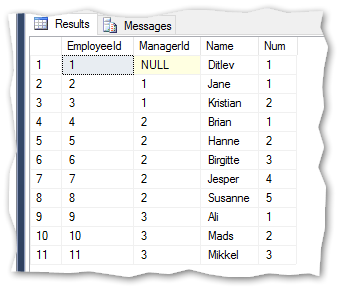
The Num field is a simple ascending counter for each level member in the hierarchy.
There are some basic methods to be used in order to build the hierarchy using the hierarchy datatype.
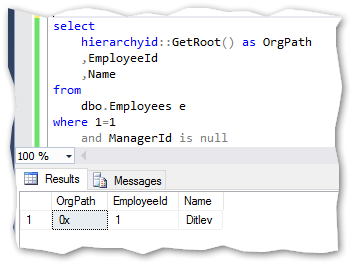
GetRoot method
The GetRoot method gives the hierarchyid of the rootnode in the hierarchy. Represented by the EmployeeId 1 in above example.
The code and result could look like this:
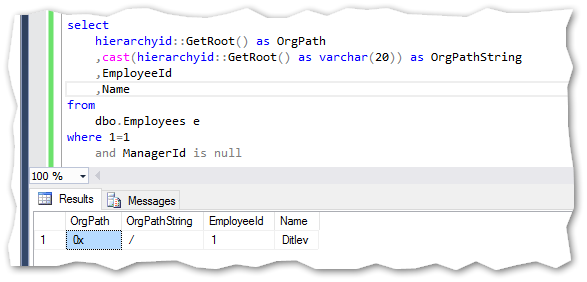
The value ‘0x’ from the OrgPath field is the representation of the string ‘/’ giving the root of the hierarchy. This can be seen using a simple cast to varchar statement:
Building the new structure with the hierarchyid dataype using a recursive SQL statement:
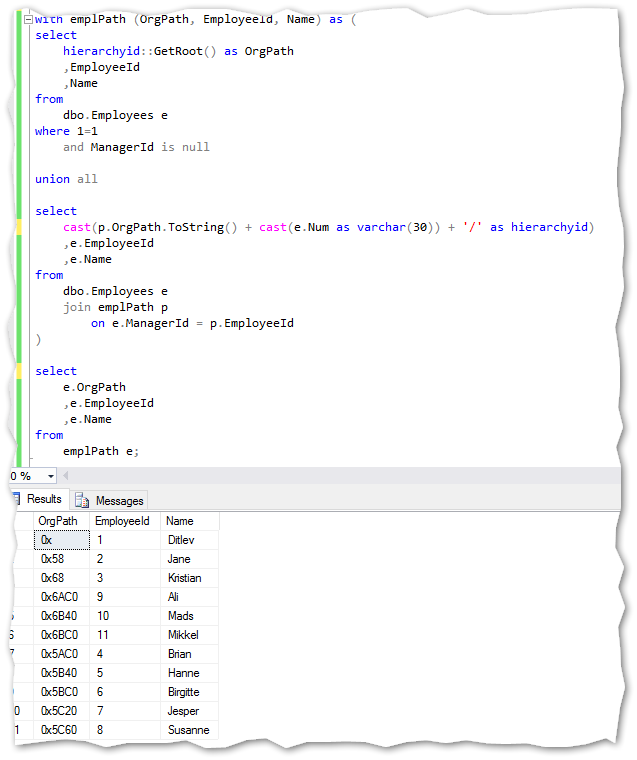
Notice the building of the path after the union all. This complies to the above mentioned syntax for building the hierarchy structure to convert to a hierarchyid datatype.
If I was to build the path for the EmployeeId 10 (Name = ‘Mads’) in above example it would look like this: ‘/2/2/’. A select statement converting the hierarchyid field OrgPath for the same record, reveals the same thing:
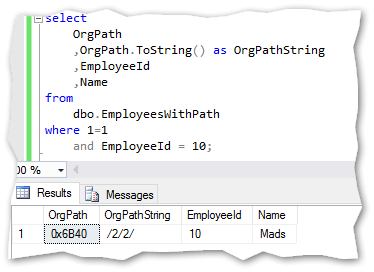
Notice the use of the ToString method here. Another build in method to use for the hierarchyid in SQL Server.
GetLevel method
The GetLevel method returns the current nodes level with an index of 0 from the top:
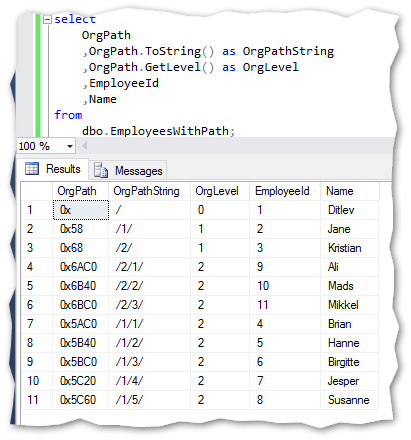
GetDescendant method
This method returns a new hierarchyid based on the two parameters child1 and child2.
The use of these parameters is described in the BOL HERE.
Below is showed some short examples on the usage.
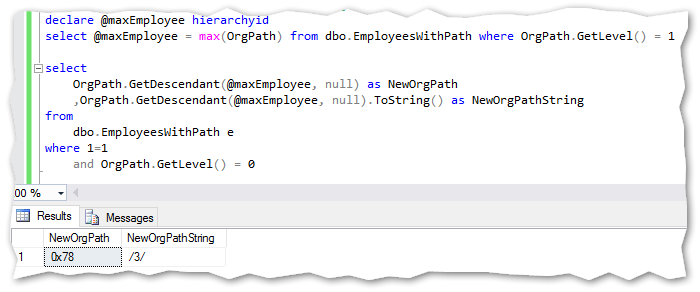
Getting a new hierarchyid when a new employee referring to top manager is hired:
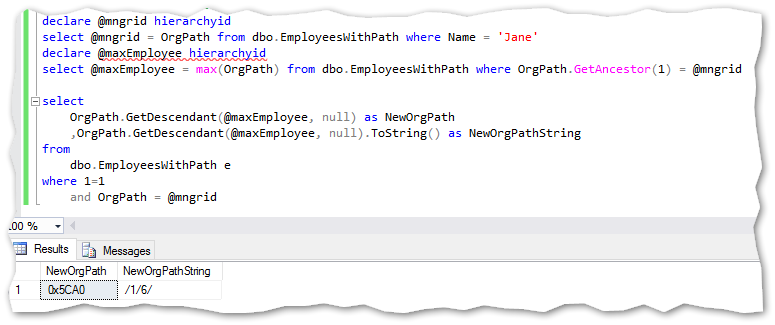
Getting a new hierarchyid when a new hire is referring to Jane on the hierarchy:
Dynamic insert new records in the hierarchy table – this can easily be converted into a stored procedure:
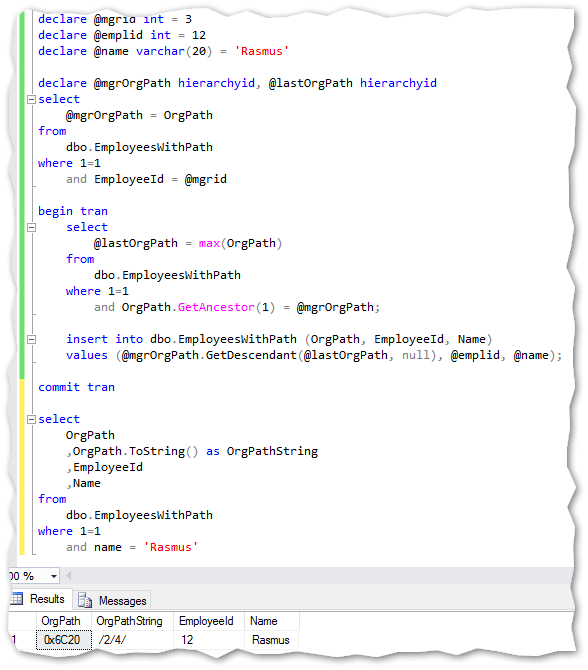
Notice the new GetAncestor method which takes one variable (the number of steps up the hierarchy) and returns that levels Hierarchyid. In this case just 1 step up the hierarchy.
More methods
There are several more methods to use when working on a hierarchy table – as found on BOL:
GetDescendant – returns a new child node of a given parent. Takes to parameters.
GetLevel – returns the given level for a node (0 index)
GetRoot – returns a root member
ToString – converts a hierarchyid datatype to readable string
IsDescendantOf – returns boolean telling if a given node is a descendant of given parent
Parse – converts a string to a hierarchyid
Read – is used implicit in the ToString method. Cannot be called by the T-SQL statement
GetParentedValue – returns node from new root in case of moving a given node
Write – returns a binary representation of the hierarchyid. Cannot be called by the T-SQL statement.
Optimization
As in many other scenarios of the SQL Server the usual approach to indexing and optimization can be used.
To help on the usual and most used queries I would make below two indexes on the example table:
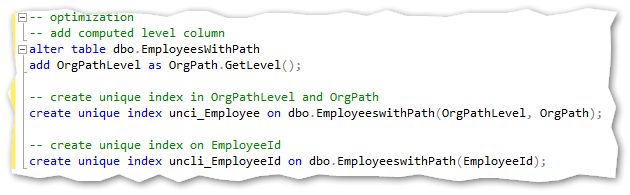
But with this like with any other indexing strategy – base it on the given scenario and usage.
Goodies
So why use this feature and all the coding work that comes with it?
Well – from my perspective – it has just become very easy to quickly get all elements either up or down from a given node in the hierarchy.
Get all descendants from a specific node
If I would like to get all elements below Jane in the hierarchy I just have to run this command:
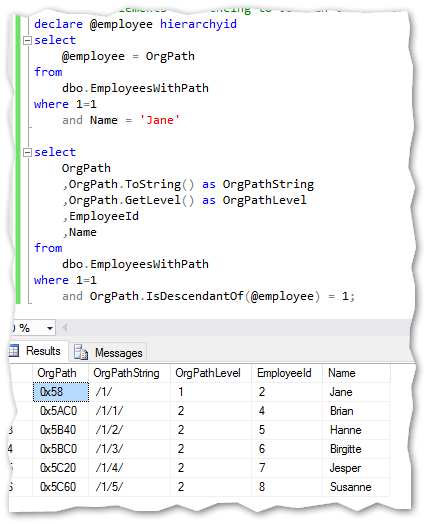
Think of the work you would have to do if this was a non hierarchy structured table using only parent/child and recursive SQL if the structure was very complex and deep.
I know what I would choose.
Conclusion
As seen above the datatype hierarchyid can be used to give order to the structure of a hierarchy in a way that is both efficient and fairly easy maintained.
If one should optimize the structure even further, then the EmployeeId and the ManagerId could be dropped as the EmployeeId is now as distinct as the OrgPath and can be replaced by this. The ManagerId is only used to build the structure – but this is now also given by the OrgPath.
Happy coding…
You can download the SQL code here
External references:

His work spans from the small tasks to the biggest projects. Engaging all the roles from manual developer to architect in his 11 years experience with the Microsoft Business Intelligence stack. With his two certifications MSCE Business Intelligence and MCSE Data Platform, he can play with many cards in the advisory and development of Business Intelligence solutions. The BIML technology has become a bigger part of Brians approach to deliver fast-track BI projects with a higher focus on the business needs.
View all posts by Brian Bønk Rueløkke
- How to import flat files with a varying number of columns in SQL Server - February 22, 2017
- Ready, SET, go – How does SQL Server handle recursive CTE’s - August 19, 2016
- Use of hierarchyid in SQL Server - July 29, 2016