
In a data-driven world, where every second see a transfer of billions of pieces of data, enterprises are focused on making the access to data fluid and capable of being accessed on demand on a myriad of devices. Leveraging these capabilities to deliver better business results is now the prime focus. Information Technology is no more what it has been. What the web saw during the dot-com boom is what enterprise data is seeing now. Social, mobile, analytics, cloud, Big Data, Internet of Things… They’ve been enabling organizations to scale.
Does the SQL Server 2017 umbrella have all or some of these core components? Let’s take a look at whether SQL Server 2017 can scale to satisfy the requirements of today’s emerging technologies.
Now that Microsoft has released SQL Server 2017, customers will be able to port to SQL Server 2017 production workloads running on Windows, Linux, and Docker containers.
The most recent leap in the evolution of SQL Server has been the most significant one in the last two decades. And the commercial partners have had a major role to play in making SQL Server 2016 the most technically successful upgrade. Microsoft introduced several new capabilities, enhanced the existing ones and managed to minimize downtime and maximize performance and data protection. It has emerged as one of the best relational database players over the last two decades on Windows platforms. As a result, database administrators (DBAs) have a number of options to choose from to help them ensure continuous access to mission-critical data while meeting availability levels according to service level agreements (SLAs). Carrying the same spirit, we will discuss a wide range of information about the footsteps in the arenas of SMAC (Social, Mobile, Analytics, and Cloud), in this article.
Social, mobile, analytics and cloud are now the prime focus of several enterprises. Businesses are seeing a paradigm shift, as we already saw. And it’s no flash news. Enterprises are now able to drive huge amounts of data. Crunching this data enables businesses to make wiser decisions, which are real-time, and data-based. And following are some data points that show us the kind of paradigm shift SMAC have brought.
- Huge Big Data investments
- 81% of companies understand the importance of data for improving efficiency and business performance.
- The growth of the NoSQL market
- The humongous volume of structured and unstructured data generation
Let’s see how the evolution of the SQL Server has helped address some of these complex challenges.
The last eighteen months has been a great journey for Microsoft. The level at which its really transforming its product as a real game changer is the key and success of Microsoft.
And Microsoft did not leave any stone unturned to ensure that they ride the wave well. They made some unexpected and even revolutionary decisions such introducing SQL Server for Linux. More such examples would be the adoption of R and Python, going all out and diving into Artificial Intelligence and Machine Learning with Cortana. And the fact that Cortana is one of the most progressive and efficient the world has ever seen is no secret. It’s constantly improved on Machine Learning and Cognitive Computing and has spread its wings to cover the company’s cloud services, business software offerings, and consumer products.
And now, it’s SQL Server’s turn. The way the SQL Server 2017 is evolving as an independent platform to serve as a core enterprise solution by covering the various pieces of technology such as Big Data, Data Science, Cloud, Mobility and Social platforms is great.
After working with SQL Server for 12 years, I can see that SQL Server now has various built-in capabilities to handle a huge volume of data. The features such as In-Memory OLTP, a memory optimized technology, provides a platform to combine the data with the right data analytical tool in order to generate real-time reports. It ensures that almost near-real-time operational analytical data processing can be seamlessly handled.
Big Data
SQL Server PolyBase is a feature that aligns with Big Data. It’s a fantastic piece of technology that allows users to seamlessly integrate relational and non-relational data. It acts as a bridge between SQL and Hadoop. PolyBase supports most of the currently available Hadoop clusters. This feature has been available for Analytics Platform System (APS) and SQL Data Warehouse (SQL DW) for some time, and fortunately, it has finally made its way to SQL Server 2016.
NoSQL
Today, when the traditional relational database systems like SQL and non-traditional database systems like NoSQL can very easily coexist, and even complement each other, enterprises need to focus on building an expertise in the Big Data space, while keeping in mind the database systems available to us. They’ve already had decades of practice designing and managing SQL databases that emphasize on storage efficiency and referential integrity. However, fast data access has not been among their primary strengths. Quick data access is important in building cloud-based applications that deliver real-time value to the users. Therefore, query-optimized modeling is the new watchword when it comes to supporting today’s fast delivery, iterative, and real-time applications.
SQL on Linux
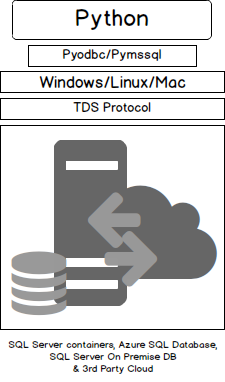
SQL Server’s portability on third party clouds and using Docker store is now seamless. The Microsoft SQL Server Docker image can be mounted and used, just by starting a container; we don’t even have to have SQL Server installed on our machines anymore.
SQL server on Linux has various advantages. Microsoft was pretty late to enter the open source market. But that was a step in the right direction. This gives platform independence; choice of platform and language. The migration of SQL Server instance from Windows to Linux saves costs such as hardware cost and migration costs.
Machine Learning
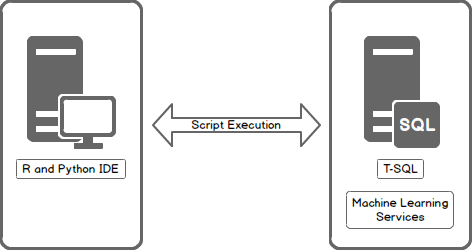
The integration of R and Python opens the door … wide, to data science. R and Python have had access SQL Server, sure, but only if running externally, by transferring data queried from the SQL Server to the machine running the code. Running the code natively on SQL Server avoids such data movement, allowing for the creation and training of predictive ML models on the server itself, over large volumes of data, analyzed in-place.
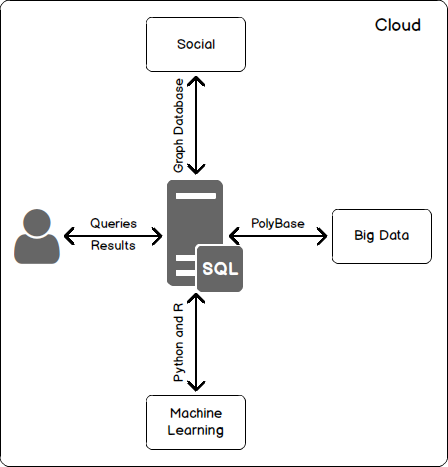
The Graph database is a language, unlike traditional database systems that have “Rows” and “Columns”, contain “nodes” and “edges”. The node represents an entity and the edge represents the relationship between the nodes. The data is best described in terms of nodes. And this model is a natural choice for Social media data.
Wrapping Up
SQL Server on Linux boosts the database market for Microsoft. Support of PolyBase (a feature to work with Big Data providers), In-Memory Optimized SQL Server, Real-time Operational Analytics, the scaling of Python and R Services for Data analytics, Graph database for NoSQL data, JSON support for transparent data interchange format between traditional and non-traditional database systems, Azure Cosmos DB from Document database to distribution database… All this helps leverage SQL Server to almost every extent, in day-to-day activities.
The shift in technology is being driven by increased expectations. The time-to-market is lower when it comes to applications; the competition is fierce. Also, there’s a lot of unstructured data floating in the ether, such as videos, images, audio, etc., which are more prevalent and problematic for traditional databases. And SQL Server 2017 has emerged, attempting to answer these calls.
It does, though, seem to have the potential to be seen as a powerhouse of a number of desirable features. It is a little early to say whether SQL Server 2017 would become an answer to the myriad of requirements we have; it may also require a lot of fine tuning and improvisation. But it is perhaps safe to say that Microsoft does seem to be taking it seriously and taking the necessary steps.

My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021