
This article talks about the table distribution styles supported in Azure Synapse and how to use them for creating distributed tables.
Introduction
In a traditional Online Transaction Processing (OLTP) approach, data is accumulated into a variety of database objects in a transactional database. The primary database object that hosts data physically is usually a table in a database. As the data volume, as well as data consumption needs grow, there is an increasing need for resources that can cater to the performance needs. The first approach to the increasing needs of performance is scaling up by increasing the hardware capacity available to the database server. A scale-up approach is usually a costly approach after a certain extent as one reaches the limit of scaling up hardware. Also, the risk of a single server failure can be catastrophic as the data hosted on a single instance may get lost or corrupted.
Data warehouses host much larger volumes of data compared to transactional databases, the volume of reads is much more compared to writes and queries tend to result in much larger result sets compared to queries that retrieve scalar values or paginated record sets from transactional databases. Due to this nature of data warehouses, there is a higher impetus on the server to perform faster. Modern data warehouses like AWS Redshift, Azure Synapse, Snowflake and others employ approaches like data sharding where data is distributed horizontally on multiple nodes which process data in parallel. This approach is highly scalable as nodes can be easily added to a data cluster as the storage and performance need increases. One key aspect that is different for tables hosted on such data warehouses is that tables are distributed horizontally using different distribution algorithms, so that all the nodes in an Azure Synapse cluster have an equal share of responsibility for hosting, processing, and delivering data for any given query to maximize performance.
In this article, we will learn about the table distribution styles supported in an Azure Synapse and how to use them for creating distributed tables.
Distribution Styles and Distribution Keys
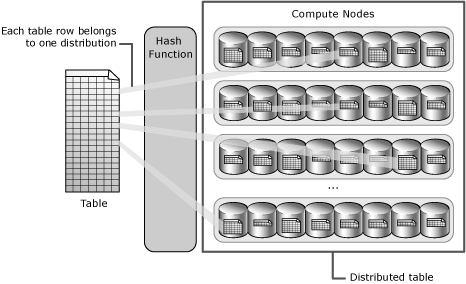
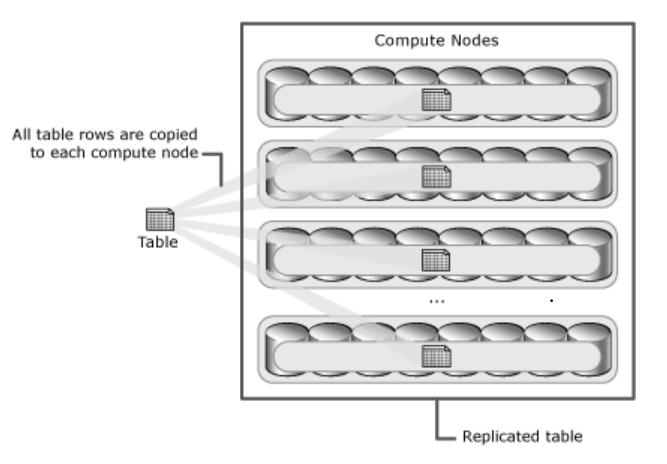
A distributed table in Azure Synapse is a table that logically exists as a single table, but the rows are physically stored on all the nodes or distribution (typically sixty) of the dedicated SQL pool. The efficiency of data distribution is directly proportional to the query execution performance. Distributed tables are the basic unit of database objects in a dedicated Azure Synapse SQL pool where the data is physically hosted. Though most of the data exist in the form of distributed tables in Azure Synapse, there are tables that may not be distributed. When the tables are very small in terms of data volume, it may make sense to replicate these tables across all the nodes of the Azure Synapse dedicated SQL pool to avoid intra-node traffic. Such tables are known as Replicated Tables.
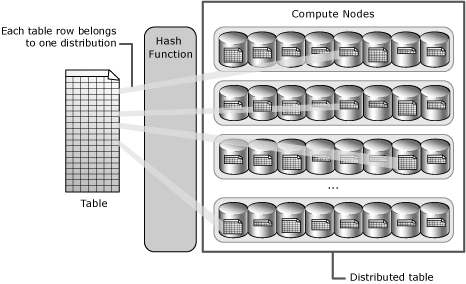
There are two prominent distribution styles in Azure Synapse – Hash Distribution and Round-Robin Distribution. Let’s understand a little more detail about both styles of distributions.
Hash Distribution
A hash-function will result in the hash for identical input values. So, when the distribution style has been set to “hash-distributed”, the values of the fields used to hash distribution will determine how data is distributed. One key aspect to keep in view while using hash-distribution is that the hash-key used for distribution has skewed values i.e., let’s say 80% of records have the same value and 20% have different values, it will result in 80% values being stored in the same node or distribution. This will create an imbalanced distribution and typically the slice holding 80% of values will complete last during query execution, result in poor performance. One should consider using fields with as many evenly distributed values as possible to create an even distribution. The below image shows a diagrammatic view of hash distribution.
Round-Robin Distribution
Let’s say that our use-case is that we have more frequent data loads compared to data reads i.e., data consumption. Or let’s say that we do not have a field in our table that can be used to evenly distribute data, then the alternative distribution style for data distribution in Azure Synapse is round-robin distribution. In this style of distribution, data is guaranteed to be distributed evenly across all the compute nodes hosting the data. The aspect to keep in view here is that identical values may get stored on different nodes as well, as here we are not using any field for sharding or distributing data. Round-robin is the default distribution style. One easy way to determine whether to use this distribution style is if you do not have a joining key in your table that is going to be used with other tables to form a resultset, then generally you are good to go with the round-robin style.
Distribution Key
As we learned above, the distribution key will come into the picture only in the case of hash-distribution. One can select a single field from a table as the distribution key or create a composite distribution key by selecting multiple fields that make a unique value. The key purpose of selecting one or more distribution keys is to create an even distribution of data. While making a design choice of a distribution key, there are a few quick checks that one can perform to quickly eliminate fields that may not be a good candidate for a distribution key. For example, fields having continuous values like decimal or highly distributed numerical values, date fields, fields with missing values, fields that are used to filter or scope the data, etc. are not good candidates for distribution keys. Alternatively, there are also checks that one can make to ensure that the right keys are selected as distribution keys. For example, fields that are common across multiple tables which may be typically used for joining tables, fields used for aggregation or window functions, fields that are typically used in functions that go over the entire range of data are good candidates for use as a distribution key.
Creating Distributed Tables
One can specify the distribution style when the table is created. The syntax of the same is as shown below. Using the distribution table option with one of the three supported values will result in the creation of the distributed table. Once a distribution style and fields are chosen, they cannot be changed. The only option to change it is by creating a new table from the existing table, but with a new distribution style. Though the distribution style and key cannot be changed, the values of the column used as distribution key can be changed which will result in a data re-distribution operation. Typically, in data warehouse applications, updates in data are relatively low which is ideal for distribution keys.

Monitoring data distribution
Over the period, data may change in the distribution key resulting in data skew. A situation where imbalanced weightage of values in distribution keys resulting in imbalanced data distribution is called data skew. It is not practical to get a perfect distribution of data in most cases, and there would be some degree of data skew in any distributed table. But if the skew is so large that it impacts query performance, then one needs to identify as well as address the same. One way of addressing it is by changing the distribution keys or even distribution style if required. One needs to monitor large time-consuming queries to assess data volumes, data processing logic, intra-node traffic which may be due to the nature of data distribution, present and future data loads that may impact data skew, and other such factors to determine whether there is a need to change the data distribution. In other words, one needs to understand their data landscape quite well to achieve the optimal distribution style for their use-case.
Conclusion
In this article, we understood the importance of distributed tables, distribution styles and distribution keys in Azure Synapse. We learned how to use these for different types of workloads or use-cases and assess the workloads to determine when there is a need to fine-tune distribution styles or distribution keys.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023