
After receiving new additions to backup and restore capabilities of SQL Servers like file and page restores, I thought that nothing will surprise me anymore, but well, here it is; SQL Server file-snapshot backups in Azure.
SQL Server 2016 introduces a new type of SQL Server backup for database files stored in Microsoft Azure blob storage.
This new type of backup is called File-Snapshot backup and it leverages the storage snapshot capabilities of Azure blob storage to take nearly instantaneous backups and perform incredibly fast restores.
Within the article we will cover the following topics:
- Understand what file-snapshot backups is and how it works
- How we can configure it and use it in production
- Restoring a database to a point in time using file-snapshot backups
- And how much faster it actually is than traditional streaming backup
First of all, note file snapshots leverage the storage snapshot capabilities within Microsoft azure. It is quite different from the standard backup and recovery process, so let’s dive and review the base objects of which the file snapshot consists.
Base files are our standard database files – the database files (mdf and ndf) and the transaction log file (ldf). To take advantage of the file-snapshot backup it is mandatory for us to store them within the Azure blob storage.
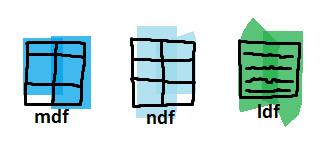
Snapshots retain the differential changes between the database base files and the exact moment we have initiated a file-snapshot backup.
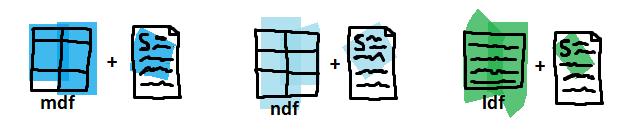
The .BAK container stores pointers instead of data pages here. The pointers are tied with the exact snapshots we would need in case of a database recovery.
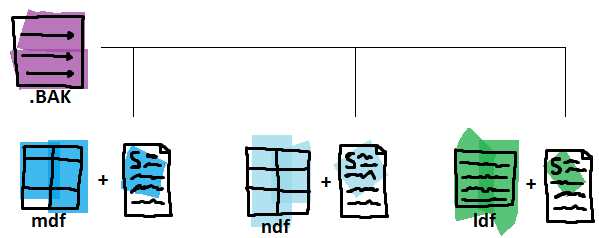
The first file-snapshot backup performed must be a Full one. Upon starting the backup it creates an azure snapshot of all the database base files – both data files and transaction logs, then it establishes the transaction log backup chain and writes the locations of the file-snapshots into the *.bak container file as pointers.
After the initial full backup that was required to establish the transaction log chain you can only perform transaction log backups because each and every transaction log file-snapshot backup set has file-snapshots of all the database files – both data and log and can be used in a RESTORE operation for the whole database or just the log.
Meaning that full database file-snapshot backup is required only once and all other backups can (and should) be transaction log file-snapshot backups.
Of course there are some limitations when using file-snapshot backup:
- Within the current version of Azure the backup file itself cannot be stored using premium storage, which to explain quickly is a high performance storage relying on SSD drives
- The frequency of the backups cannot be shorter than 10 minutes
- The maximum number of snapshots (backups cannot be over 100)
- Every time when you are performing a RESTORE it is required to use WITH MOVE statement
- Both the base objects and the file-snapshots must use the same storage account
Let’s set up the test environment we will be working with;
In Microsoft Azure, as a start, we have created a resource group “fsbdemorg” and within a storage account “fsbdemostorage” true the Azure Portal.
Let’s create a standard virtual machine using the wizard, size of ‘Basic A1’ will be more than enough (note the data disk will not be used at the moment, except maybe for comparing the speed between standard and file-snapshot backups, so make it a bit smaller, not 1 TB).
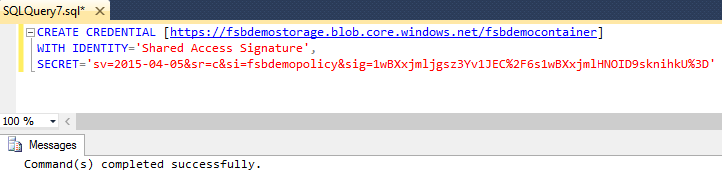
Once our SQL Server is live, up and running, we can create a CREDENTIAL for it to use the remote blob*:
We would need a database, so let us create one using the blob**:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE [master] GO CREATE DATABASE [Database01] ( NAME = N'Database01', FILENAME = N'https://fsbdemostorage.blob.core.windows.net/fsbdemocontainer/data.mdf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'Database01_log', FILENAME = N'https://fsbdemostorage.blob.core.windows.net/fsbdemocontainer/log.mdf' , SIZE = 8192KB , MAXSIZE = 1073741824KB , FILEGROWTH = 65536KB ) GO USE [master] GO ALTER DATABASE [Database01] SET RECOVERY FULL WITH NO_WAIT GO |
Some test tables, couple millions of test rows later we are ready to start with the tests.
To perform a backup the database using file snapshot backup we would need to use BACKUP TO URL along with the FILE_SNAPSHOT statements as follows:
|
1 2 3 4 5 6 |
BACKUP DATABASE [Database01] TO URL = N'https://fsbdemostorage.blob.core.windows.net/fsbdemocontainer/Database.BAK' WITH FILE_SNAPSHOT GO |
To continue the backup chain we should go with a LOG backups:
|
1 2 3 4 5 6 |
BACKUP LOG [Database01] TO URL = 'https://fsbdemostorage.blob.core.windows.net/fsbdemocontainer/Database01.BAK' WITH FILE_SNAPSHOT GO |
Note that the name of the backup files should be different because they coexist in the same blob:
The restore process is fairly different than the traditional streaming backup. The file-snapshot backups contains a snapshot of all database files and the restore process requires only up to two adjacent file-snapshot backups sets. The traditional streaming backups would need the entire backup chain, which usually consist of full, differential and numerous transaction log backup files.
To perform a restore at the time when a backup is taken only the specific backup set is required along with the base blobs. We would need to use WITH MOVE statement even if we are recovering the original database.
|
1 2 3 4 5 6 7 |
RESTORE DATABASE [Database01_Recovery] FROM URL = 'https://fsbdemostorage.blob.core.windows.net/fsbdemocontainer/Database06.BAK' WITH MOVE 'Database01' to 'https://fsbdemostorage.blob.core.windows.net/fsbdemocontainer/data_recovert.mdf' ,MOVE 'Database01_log' to 'https://fsbdemostorage.blob.core.windows.net/fsbdemocontainer/log_recovery.mdf' ,RECOVERY |
Processed 0 pages for database ‘Database01_Recovery’, file ‘Database01’ on file 1.
Processed 0 pages for database ‘Database01_Recovery’, file ‘Database01_log’ on file 1.
RESTORE DATABASE successfully processed 0 pages in 0.439 seconds (0.000 MB/sec).
To perform a restore to a point in time between two backup sets we would need two adjacent backup sets. One before and one after the desired time. In our scenario to perform a recovery at 19:15:00 on 17th September 2016 we would need the files Database08.BAK, Database09.BAK together with the base files.
We will be restoring the backup set Database08.BAK fully and will use the STOPAT statement when restoring the set Database09.BAK:

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
ALTER DATABASE Database01 SET SINGLE_USER WITH ROLLBACK IMMEDIATE; RESTORE DATABASE Database01 FROM URL = 'https://fsbdemostorage.blob.core.windows.net/fsbdemocontainer/Database08.BAK' WITH NORECOVERY ,REPLACE; RESTORE LOG Database01 FROM URL = 'https://fsbdemostorage.blob.core.windows.net/fsbdemocontainer/Database09.BAK' WITH RECOVERY , STOPAT = 'September 17, 2016 19:15 PM'; ALTER DATABASE Database01 SET MULTI_USER; |
Processed 0 pages for database ‘Database01’, file ‘Database01’ on file 1.
Processed 0 pages for database ‘Database01’, file ‘Database01_log’ on file 1.
RESTORE DATABASE successfully processed 0 pages in 1.275 seconds (0.000 MB/sec).
Processed 0 pages for database ‘Database01’, file ‘Database01’ on file 1.
Processed 0 pages for database ‘Database01’, file ‘Database01_log’ on file 1.
RESTORE LOG successfully processed 0 pages in 0.148 seconds (0.000 MB/sec).
The restore is completed almost instantly, now we can start with the speed tests, so …
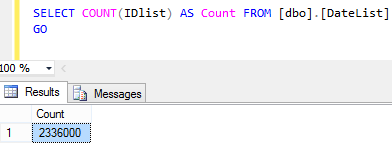
How much faster the file-snapshot backup actually is than traditional streaming backup? Let us do a simple test with backup and restore operations. We will start with table having 2336000 rows, then we double it and so on.
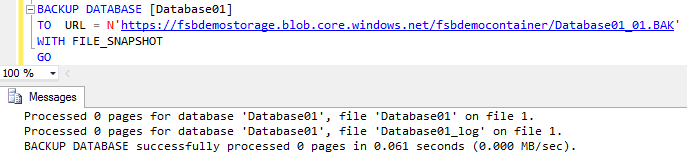
Standard file-snapshot operation of the database with 2336000 rows took 0.061 seconds.
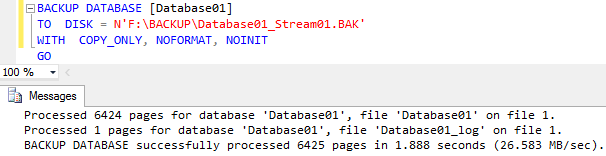
The same operation but using traditional streaming backup took 1.888 seconds.
After performing similar backup and recovery operations with bigger tables we have the following results:
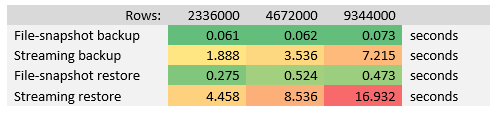
The file-snapshot backup using Azure Snapshot service is ~64 times faster on average than traditional streaming backup, and file-snapshot restore is ~23 times faster on average by the tests performed above.

View all posts by Kaloyan Kosev
- Performance tuning for Azure SQL Databases - July 21, 2017
- Deep dive into SQL Server Extended events – The Event Pairing target - May 30, 2017
- Deep dive into the Extended Events – Histogram target - May 24, 2017