
This article will help you get introduced to all the transformations offered in the Data Flow component of Azure Data Factory.
Introduction
A major practice area of data transport and transformation is the development of ETL pipelines. There are many tools and technologies available that enable building ETL pipelines on-premises as well as on the cloud. An ETL tool is as efficient as the number of data transformations that is supported as transformations are the key factors that enable the building of rich ETL pipelines that developers can use to build data transformations using out-of-box controls instead of placing large scale custom development efforts to transform the data. Azure Data Factory is a service on Azure cloud that facilitates developing ETL pipelines. The typical way to transform data in Azure Data Factory is by using the transformations in the Data Flow component. There are several transformations available in this component. In this article, we will go over all the transformations offered in the Data Flow component and we will understand some key settings and the use-case in which these transforms can be used as well.
Data Flow Transformations
To access the list of transforms in Data Factory, one needs to have an instance of it created using which we can create data pipelines. We can create Data Flows which can be used as a part of the data pipeline. In the Data Flow graph, once you have added one or multiple data sources, then the next logical step is to add one or more transformations to it.
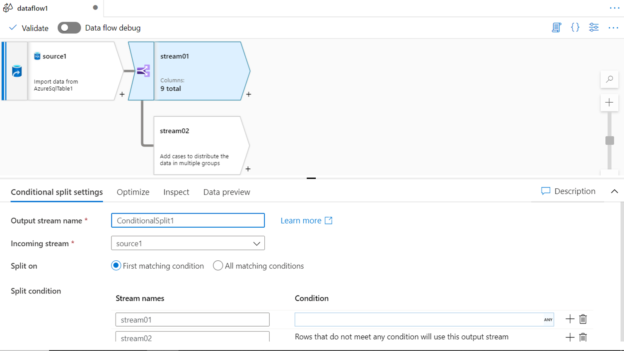
JOIN
This is the first transform you would find in the list when you click on the + sign in the graph to add transformations. Typically, when you have data from one or more data sources, there is a need to bind this data into a common stream and for such use-cases, this transform can be used. Shown below are the different types of joins that are supported along with the option to specify join conditions with different operators.
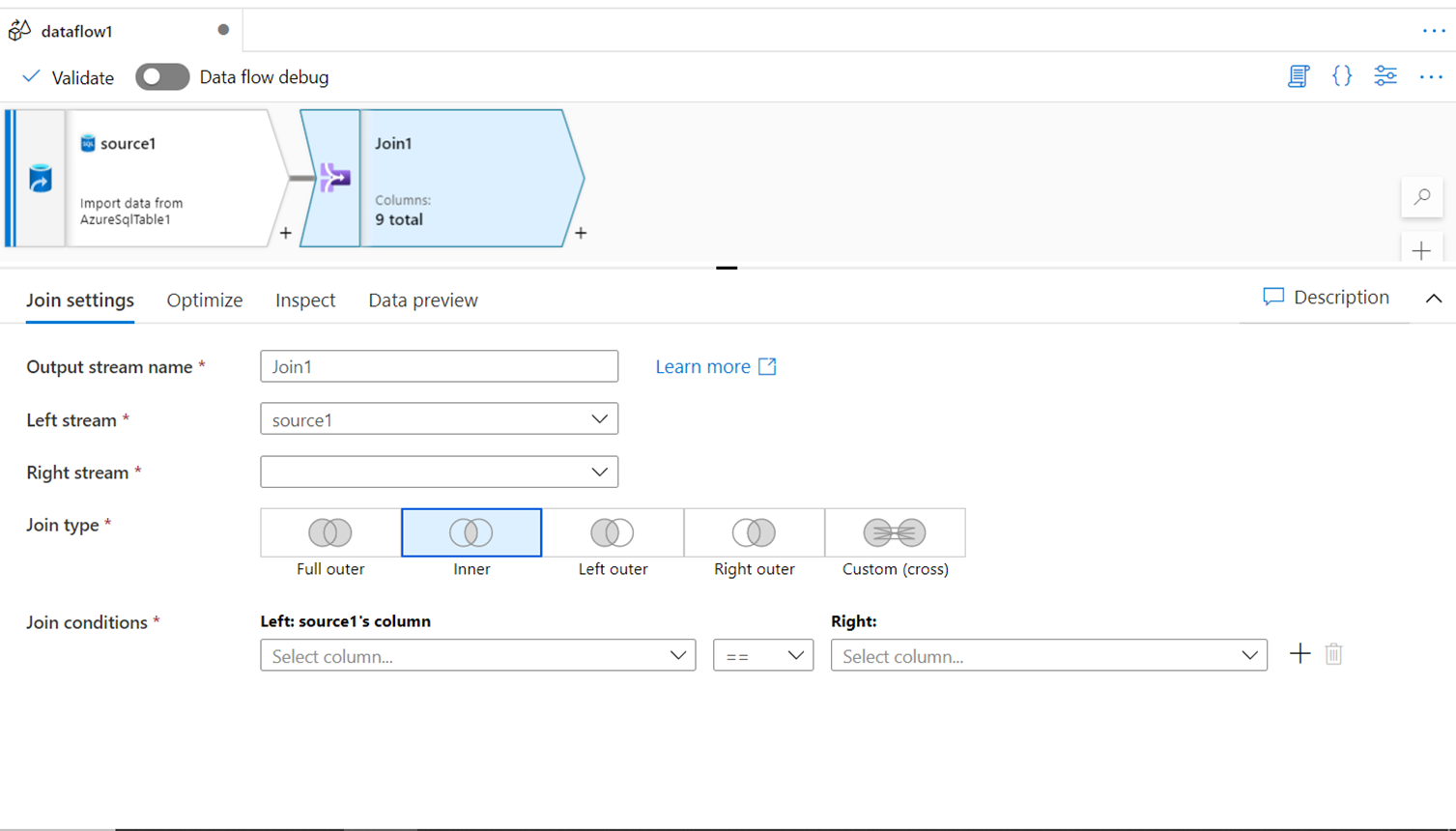
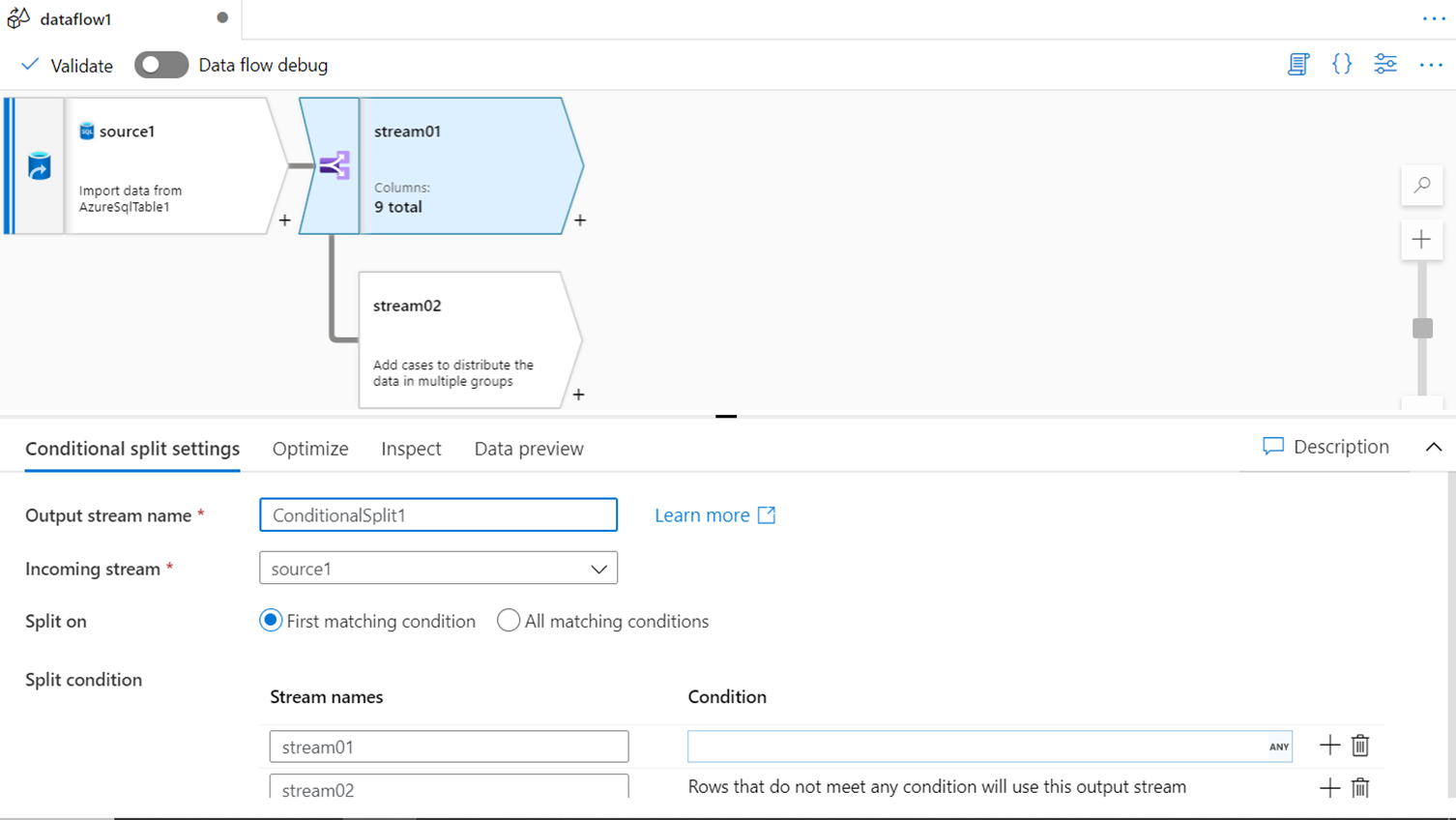
SPLIT
In Azure Data Factory, the split transform can be used to divide the data into two streams based on a criterion. The data can be split based on the first matching criteria or all the matching criteria as desired. This facilitates discrete types of data processing on data divided categorically into different streams using this transform.
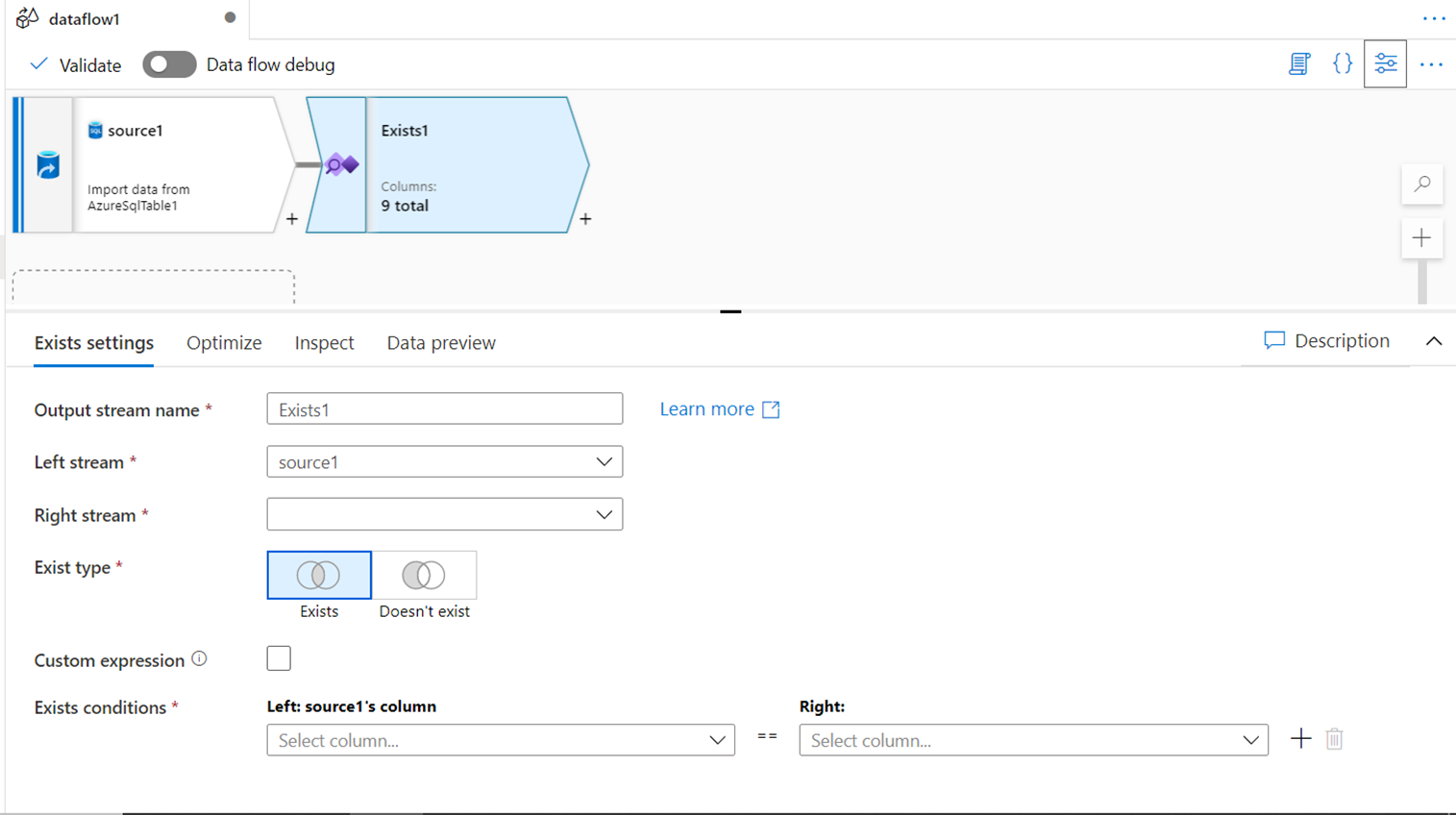
EXISTS
The Exists transform in Azure Data Factory is an equivalent of SQL EXISTS clause. It can be used to compare data from one stream with data in another stream using one or multiple conditions. As shown below, one can use exists as well as does not exist i.e. the inverse of exist to find matching or unique datasets using different types of expressions.
UNION
The Union transformation in Azure Data Factory is equivalent to the UNION clause in SQL. It can be used to merge data from two data streams that have identical or compatible schema into a single data stream. The schema from two streams can be mapped by name or ordinal position of the columns as shown below in the settings.
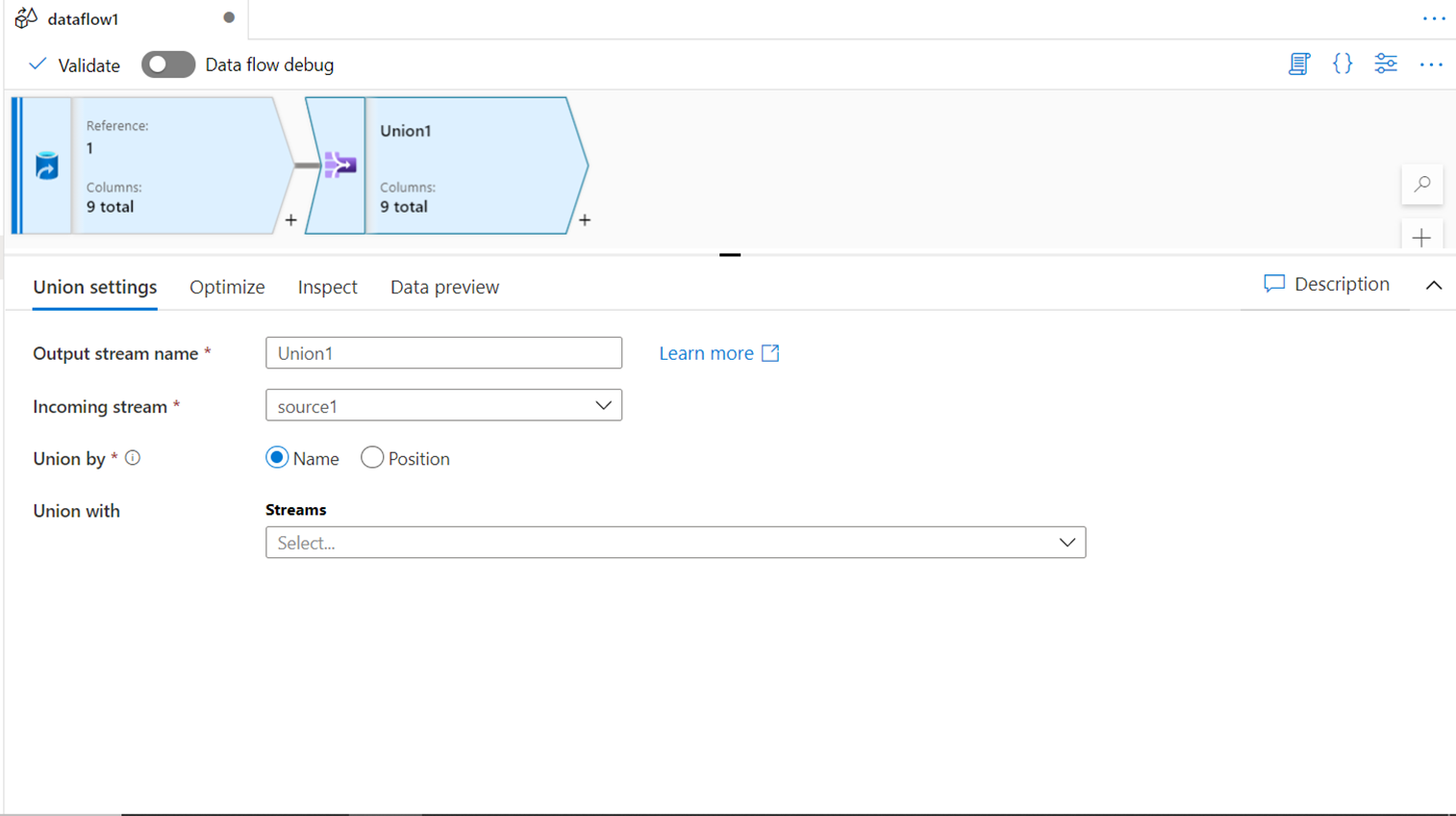
LOOKUP
The Lookup transform in Azure Data Factory is one of the most critical data transformations that is used in data flows that involve transactional systems as well as data warehouses. While loading data into dimension or facts, one needs to validate if the data already exists to take a corresponding action of updating or inserting data. In transactional systems as well, this transform can be used to perform an UPSERT-type action. The lookup transform takes data from an incoming stream and matches it with data from the lookup stream and appends columns from the lookup stream into the primary stream.
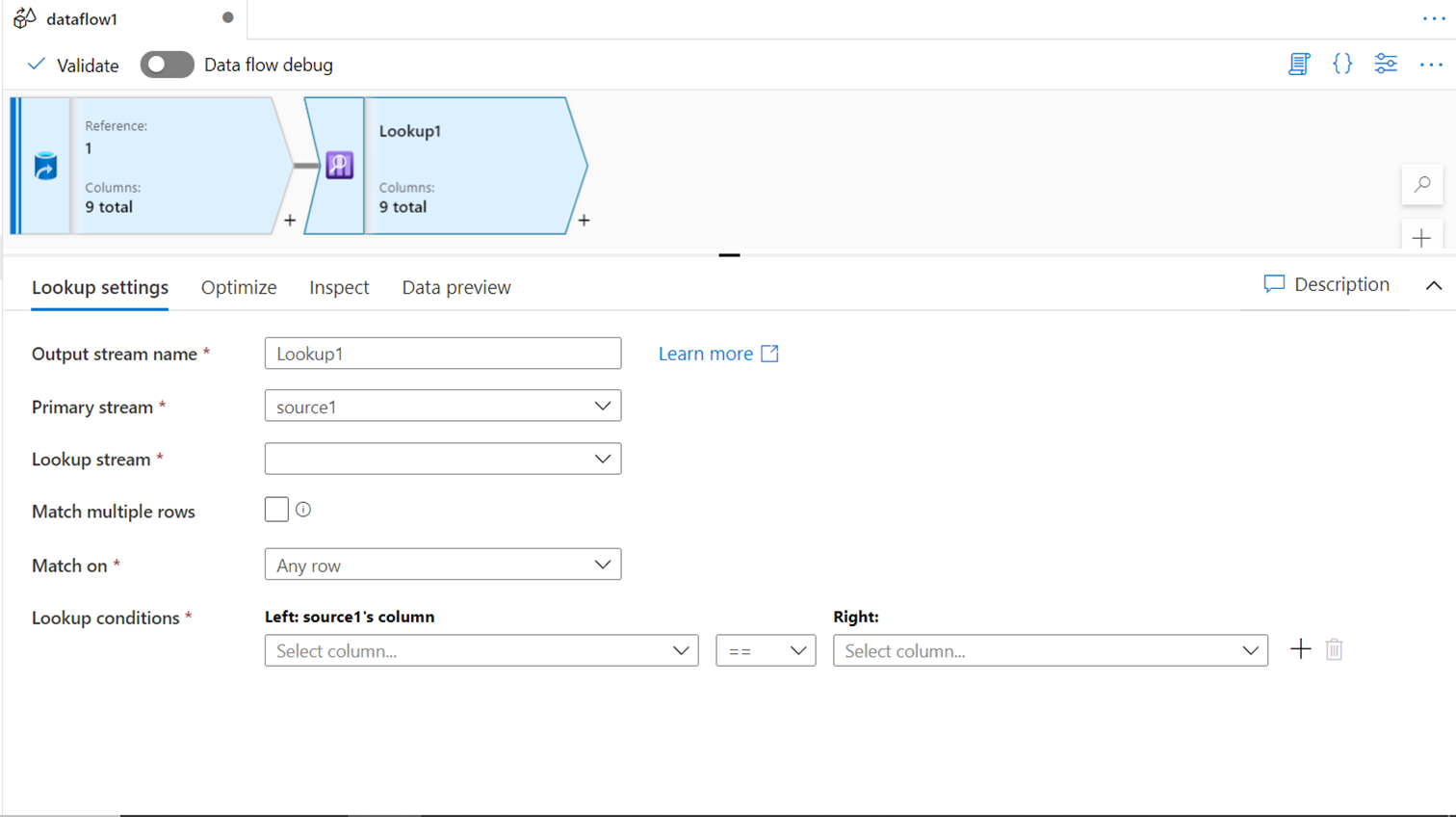
DERIVED COLUMN
With this transformation, we are starting with the schema modifier category of transforms. Often there is a need to create new calculated fields or update data in the existing fields in a data stream. Derived column transformation can be used in such cases. One can add as many fields as needed in this transformation and provide the calculation expression for the new fields as shown below.
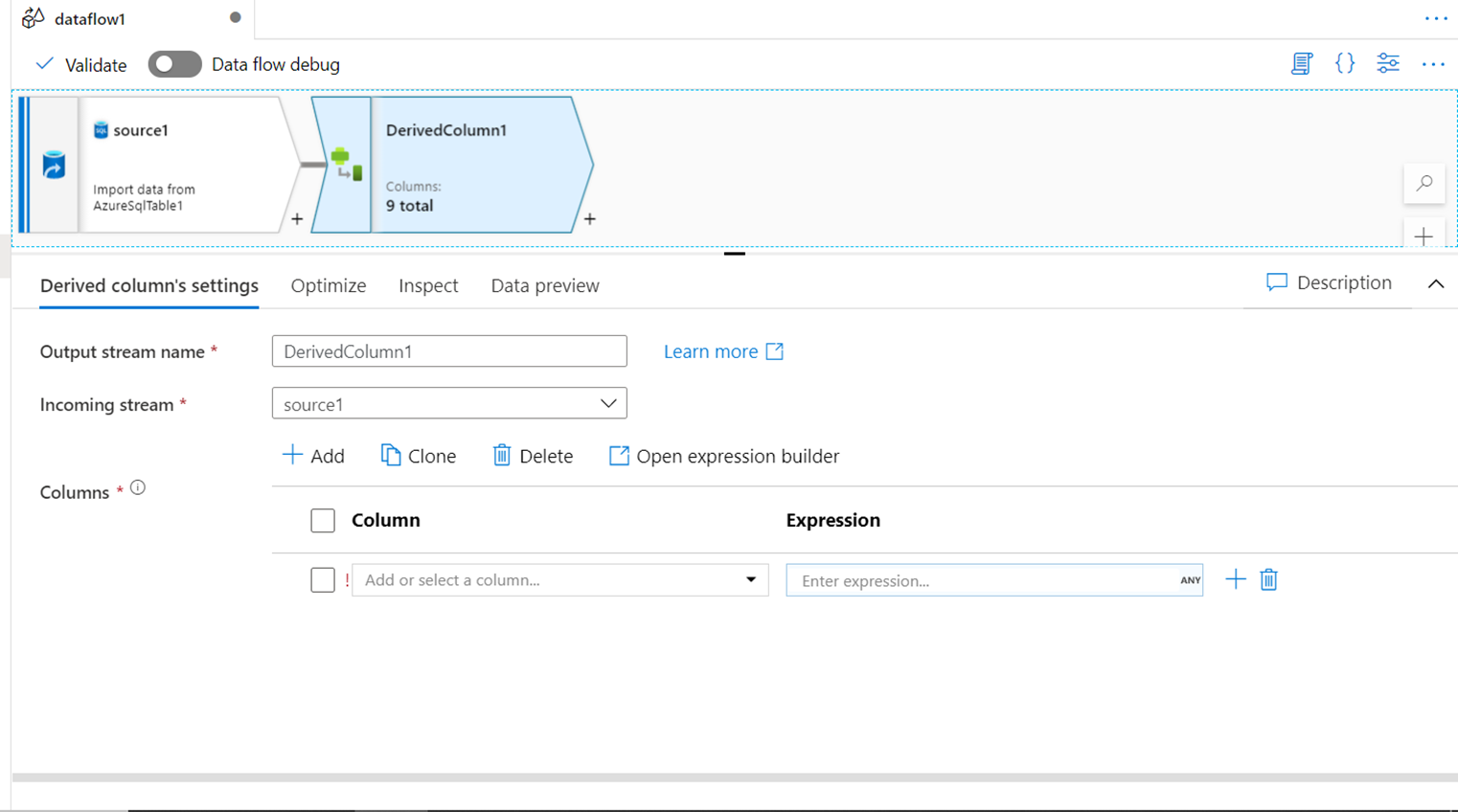
SELECT
While data in the input stream is being processed, there may be cases that while joining, merging, splitting, and creating calculated fields, it may result in some unnecessary fields or duplicate fields. To remove such fields from the data stream, one can rename the fields, change the mappings as well as remove the undesired fields from the data stream. The SELECT transform facilitates this functionality to curate the fields in the data stream.
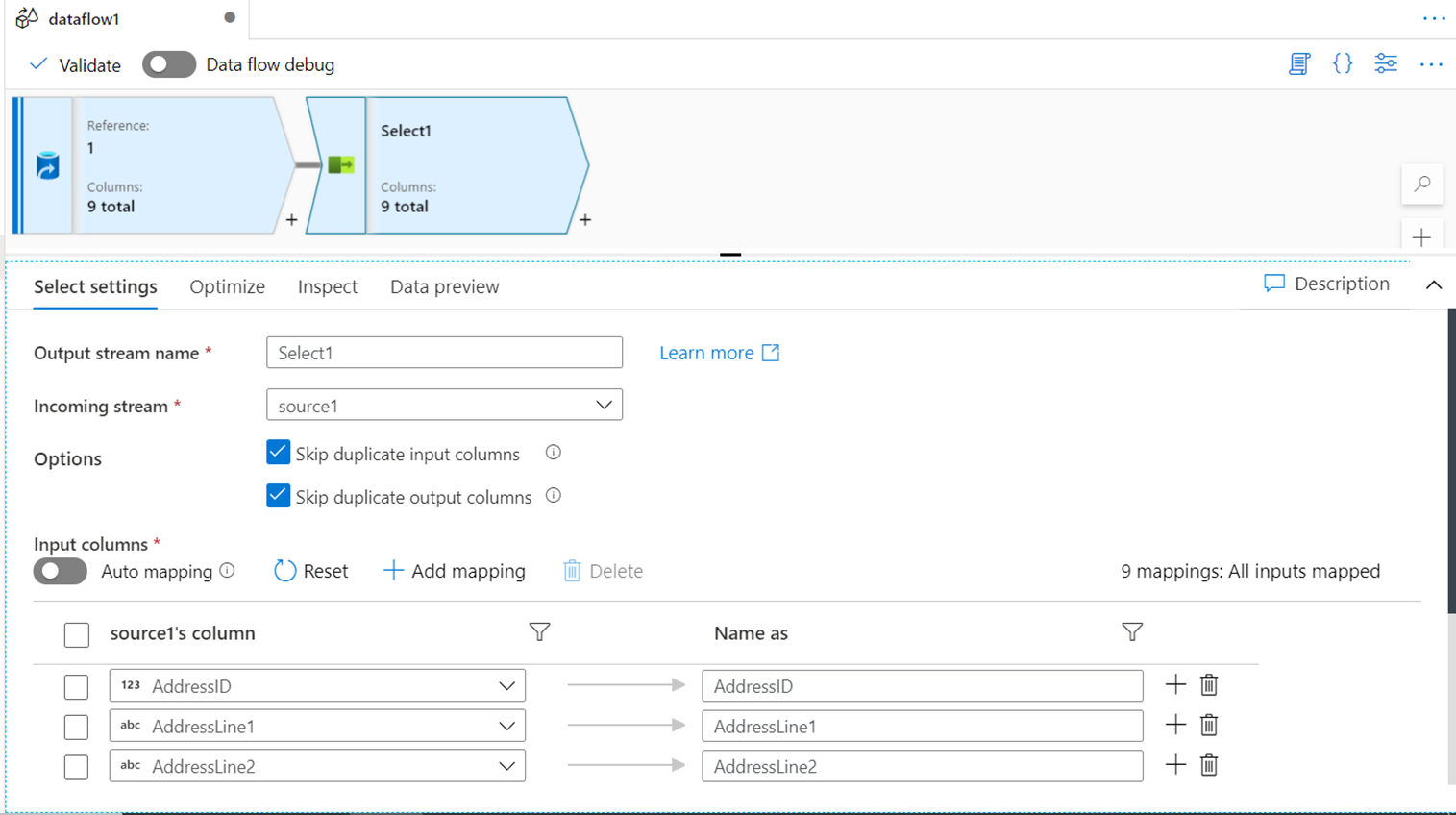
AGGREGATE
Most of the ETL data pipelines involve some form of data aggregations typically while loading data into a data warehouse or an analytical data repository. One of the obvious mechanisms of aggregating or rolling up data in SQL is by using the GROUP BY clause. This functionality can be exercised by using the Aggregate transform in Azure Data Factory. While the group is the most common way of summarizing data but it’s not the only way. Different types of aggregation calculations can be created as well for custom calculations based on a certain condition. To address this scenario, the Aggregate tab (shown below) can be used where such custom calculations can be configured.
SURROGATE KEY
In a data warehousing scenario, typically in slowly changing dimensions (SCD) where one cannot use the business key as the primary key as the business key can repeat as different versions of the same record are created, surrogate keys are created that act as a unique identified for the record. Azure Data Factory provides a transform to generate these surrogate keys as well using the Surrogate Key transform.
PIVOT
Converting unique values of rows from a field as columns is known as pivoting of data. Pivoting data is a very common functionality and is available from most basic data tools like Microsoft Excel to all different types of databases. Typically, when dealing with data that is in a nested format, for example, data hosted in JSON files, there is a need to modulate the data into a specific schema for reporting or aggregation. In such cases, one can use the PIVOT transform. The settings to configure the pivot transform are as shown below.
UNPIVOT
Unpivot transform is the inverse of pivot transform where it converts columns into rows. In pivot, the data is grouped as per the criterion, and in this case, the data is ungrouped and unpivoted. If we compare the settings shown below versus the settings of pivot transform, there are near identical.
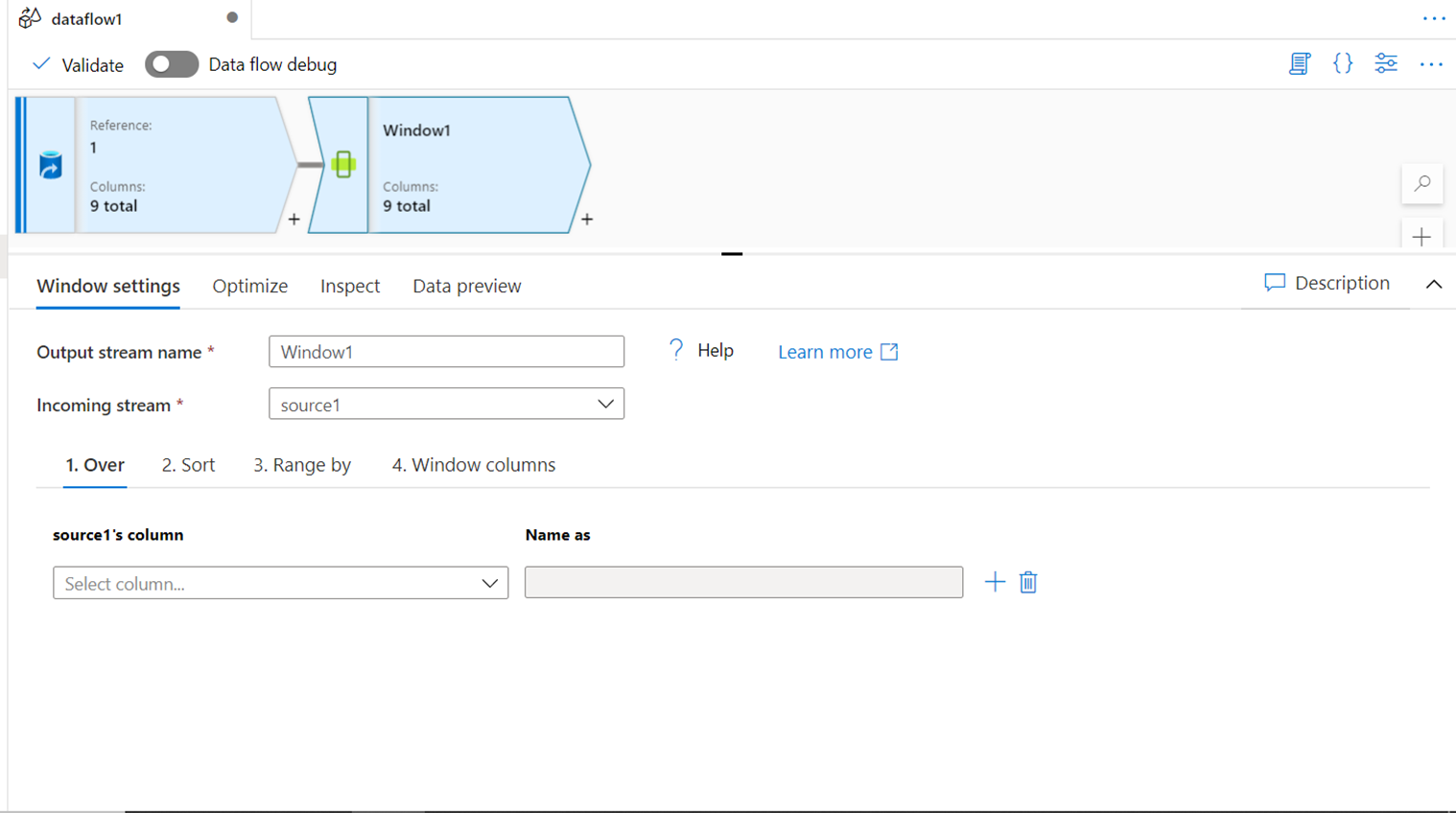
WINDOW
The Window transform supported creating aggregations using windowing functions like RANK for example. It allows building complex aggregations using custom expressions that can be build using well knows windowing functions like rank, denserank, ntile, etc. If you have used window functions in any database, you would find it very easy to understand the graphical interface shown below that enables configuring similar functionality using this transform.
RANK
Once the data is channeled into different streams, validated with different source and destination repositories, calculated, and aggregated using custom expressions, towards the end of the data pipeline, one would typically sort the data. With this, there may be a need to rank the data as per a specific sorting criterion. The Rank transform in Azure Data Factory facilitates this functionality with the options shown below.
![]()
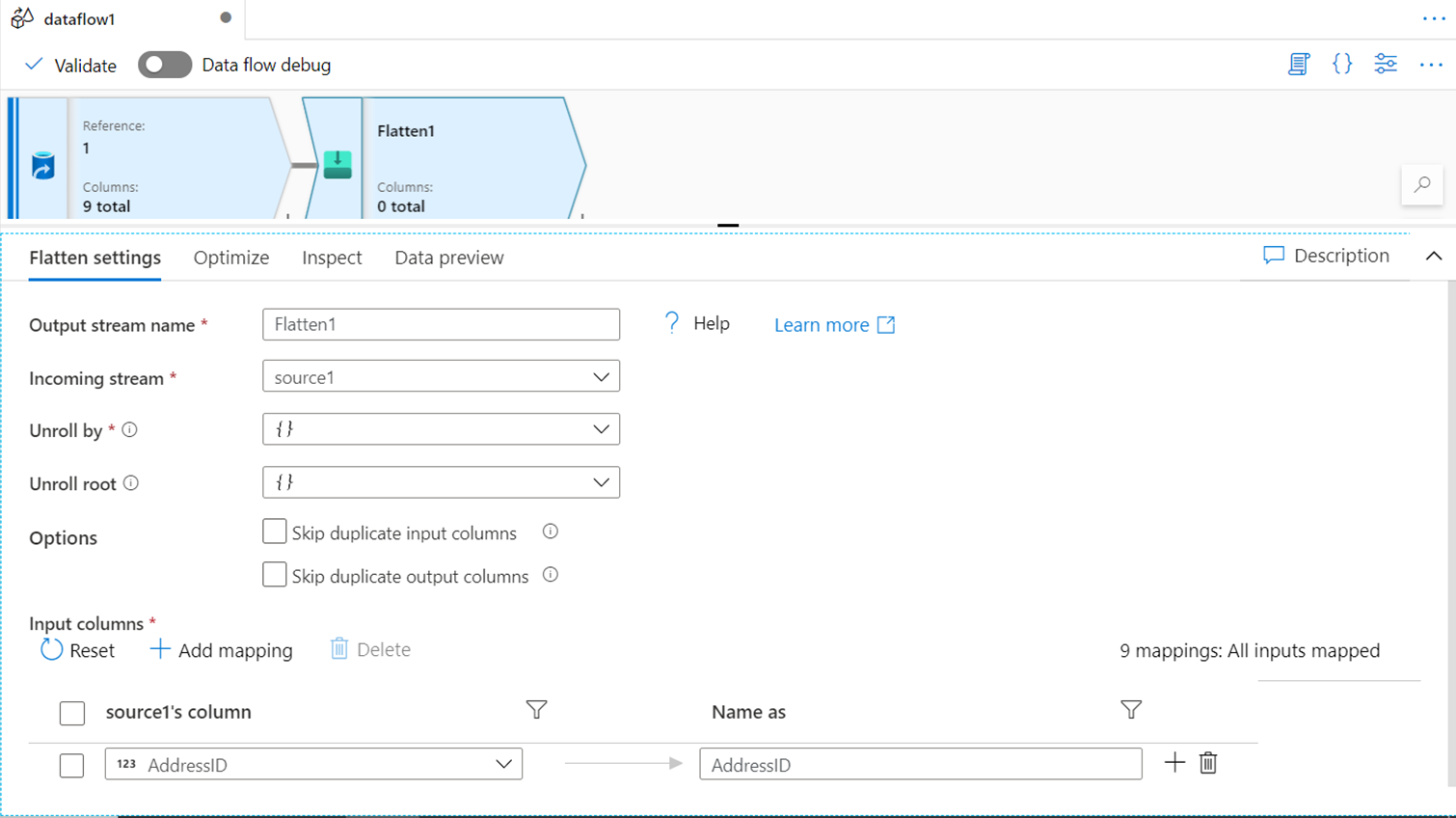
FLATTEN
At times when data is hierarchical or nested, and the requirement is to flatten the data into a tabular structure without further optimizations like pivoting or unpivoting, an easier way to flatten the data in Azure Data Factory is by using the flatten transformation. This transform converts the values in an array or any nested structure to flattened rows and column structures.
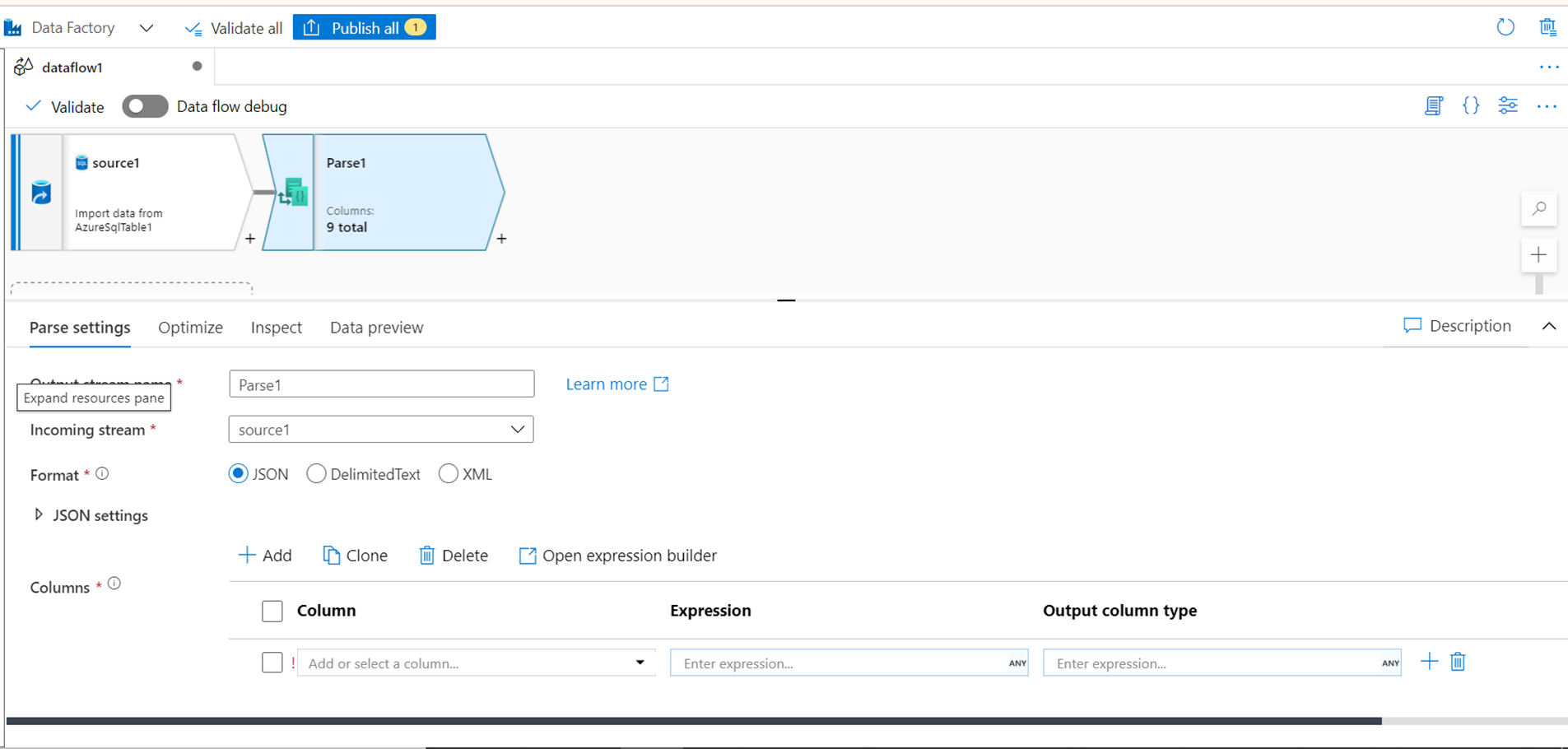
PARSE
Data is mostly read in a structured format from data repositories. But data also exists in semi-structured or document formats like XML, JSON, and delimited text files. Once the data is sourced from such format, it may require parsing the fields and data types of the fields in such data format before the rest of the transform can with used with such data. For this use-case, one can use the Parse transform using the settings shown below.
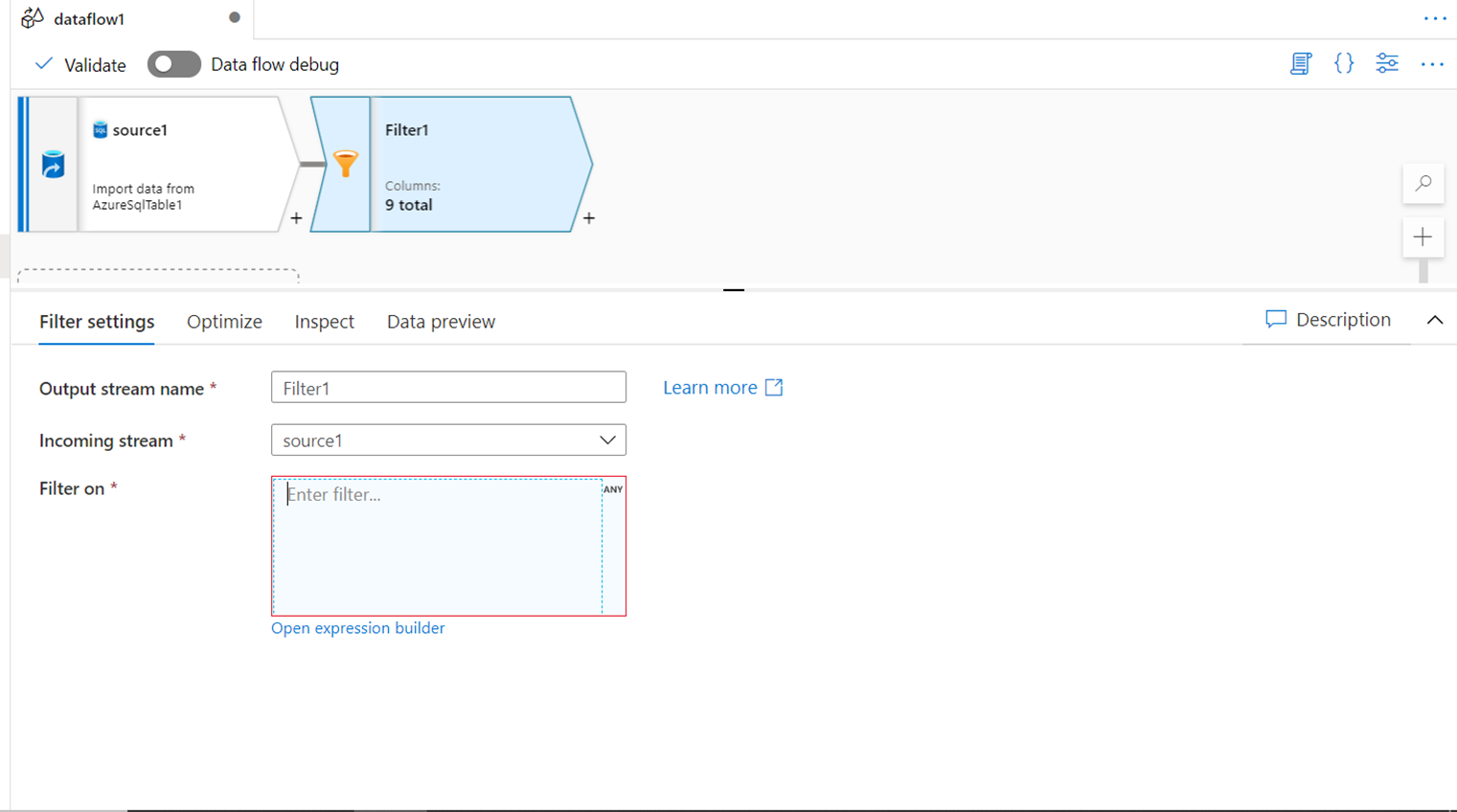
FILTER
One of the most common parts of data processing data is filtering the data to limit the scope of data and process it conditionally. The filter is one such transformation that facilitates filtering the data in Azure Data Factory.
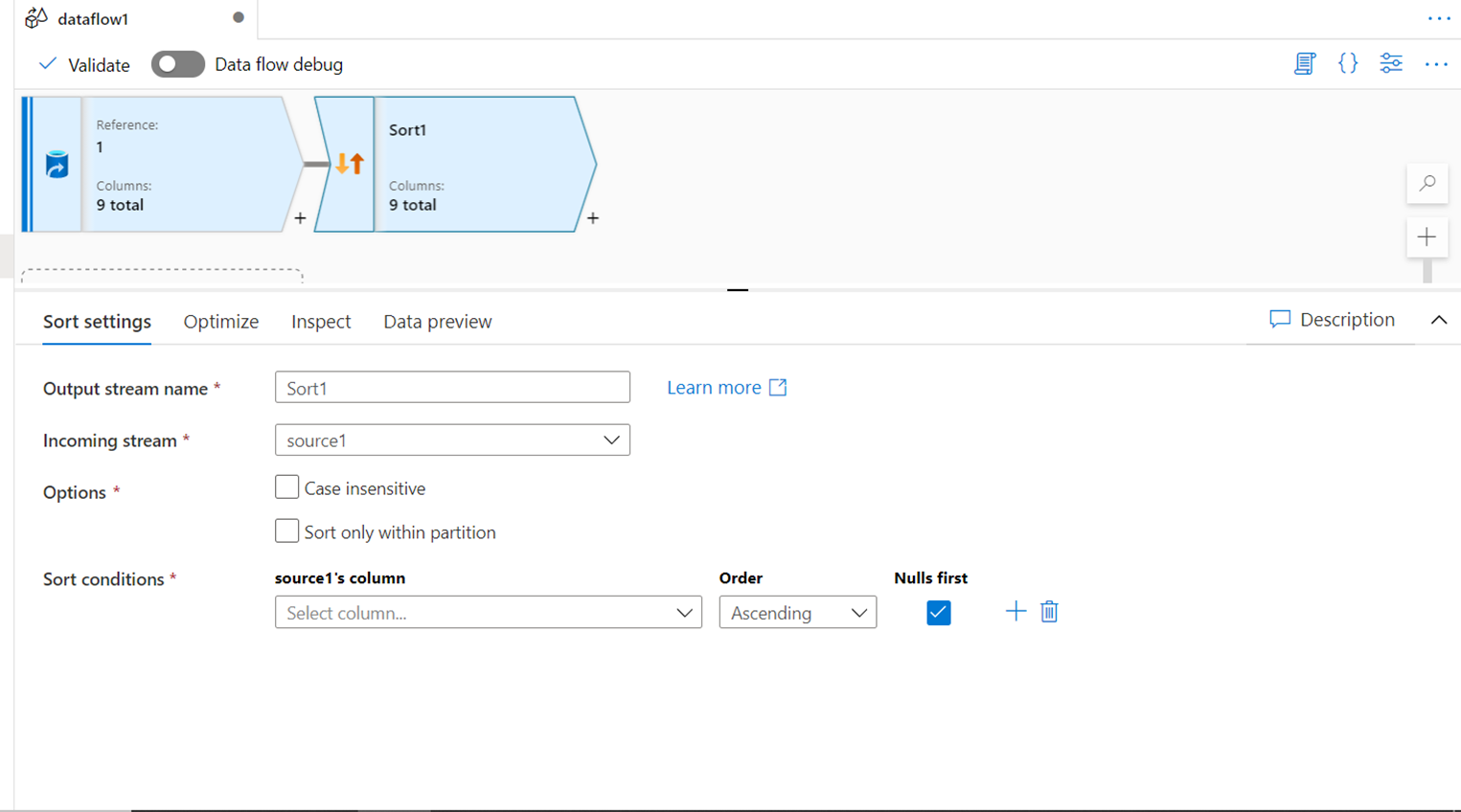
SORT
Another transform that goes together with filter transform is the sort transform. At times, certain datasets that involve time-series, it may not be possible to process it correctly without sorting. Also, when the data is ready to be loaded into the destination data repositories, it’s a good practice to sort the data and load it in a sorted manner. Sort transform can be used in such cases.
These are all the transforms available in the data transform component of Azure Data Factory to build a data flow that transforms data to the desired shape and size.
Conclusion
In this article, we covered different transforms offered by the Data Transform component of Azure Data Factory. We understood the high-level use-cases when we would consider using these transforms and glanced through the configuration settings of these transforms.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023