
Poor indexing is one of the top performance killers, and we will focus on them in this article.
What are indexes?
An index is used to speed up data search and SQL query performance. The database indexes reduce the number of data pages that have to be read in order to find the specific record.
The biggest challenge with indexing is to determine the right ones for each table.
We will start with explaining clustered and nonclustered indexes.
A table without a clustered index is called a heap, due to its unordered structure. Data in a heap table isn’t sorted, usually the records are added one after another, as they are inserted into the table. They can also be rearranged by the database engine, but again, without a specific order. When you insert a lot of rows into a heap table, the new records are written on data pages without a specific order. Finding a record in a heap table can be compared to finding a specific leaf in a heap of leaves. It is inefficient and requires time.
A heap can have one or several nonclustered indexes, or no indexes at all.
A nonclustered index is made only of index pages that contain row locators (pointers) for records in data pages. It doesn’t contain data pages, like clustered indexes.
A clustered index organizes table data, so data is queried quicker and more efficiently. A clustered index consists of both index and data pages, while a heap table has no index pages; it consists only of data pages. In other words, it is not just an index, i.e. a pointer to the data row that contains the key value, but it also contains table data. The data in the clustered table is sorted using the values of the columns the clustered index is made of.
Finding a record from a table with a proper clustered index is quick and easy like finding a name in an alphabetically ordered list. A general recommendation for all SQL tables is to have a proper clustered index
While there can be only one clustered index on a table, a table can have up to 999 nonclustered indexes
Indexes can be created using T-SQL.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE [Person].[Address]( [AddressID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL, [AddressLine1] [nvarchar](60) NOT NULL, [AddressLine2] [nvarchar](60) NULL, [City] [nvarchar](30) NOT NULL, CONSTRAINT [PK_Address_AddressID] PRIMARY KEY CLUSTERED ( [AddressID] ASC ) ON [PRIMARY] |
When you execute the select statement on a clustered table where an ascending clustered index is created, the results will be ordered ascending by the clustered key column. In this example, it’s the AddressID column.
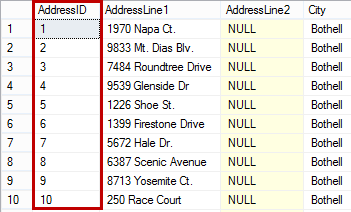
The same table, but with a descending clustered index will return the results sorted by the AddressID column descending. To create a descending clustered index, just replace ASC with DESC in code above, so the constraint syntax becomes.
|
1 2 3 4 5 6 |
CONSTRAINT [PK_Address_AddressID] PRIMARY KEY CLUSTERED ( [AddressID] DESC ) |
The select statement on this table returns the AddressID column sorted descending.
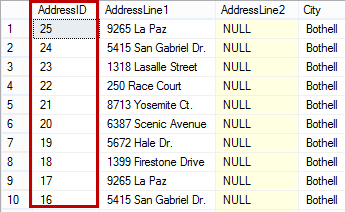
T-SQL code to create a table with a nonclustered index:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE [Person].[Address4]( [AddressID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL, [AddressLine1] [nvarchar](60) NOT NULL, [AddressLine2] [nvarchar](60) NULL, [City] [nvarchar](30) NOT NULL) CREATE NONCLUSTERED INDEX [IX_Address_StateProvinceID4] ON [Person].[Address4] ( [AddressID] ASC ) ON [PRIMARY] |
When you execute the select statement on a heap table with the same columns and data, the results returned will be unordered.
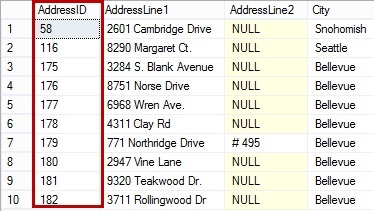
Besides using T-SQL code to create an index, you can use SQL Server Management Studio. To create an index on an existing table:
- Expand the Tables node in Object Explorer
- Expand the table where you want to create the index and right-click it
- Right-click Indexes
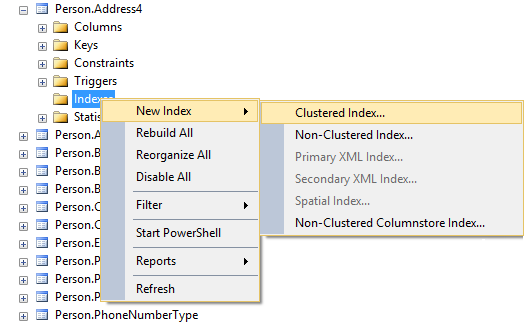
- Select New Index
Select Clustered Index or Non-Clustered Index option

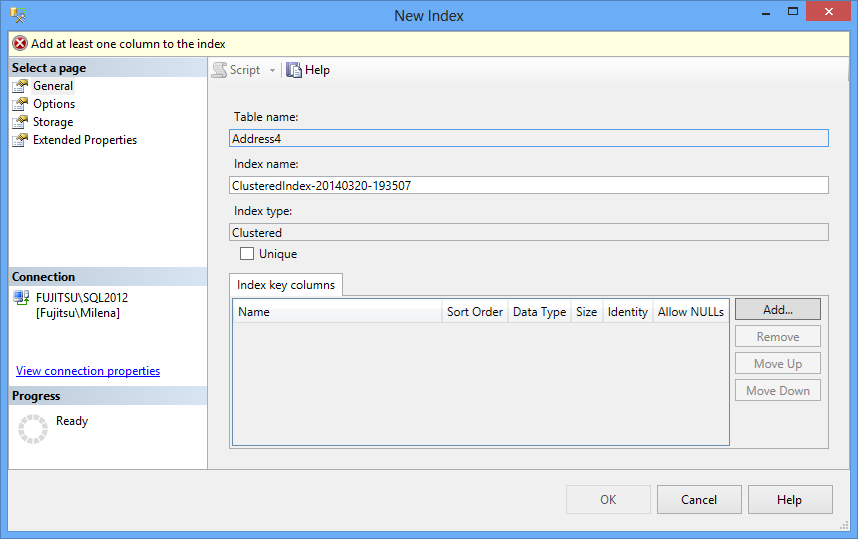
- If you selected the Clustered Index option, the following dialog is shown. The index name is generated automatically, but it’s not very descriptive, so it’s recommended to change it and add the clustered index column names, e.g. ClusteredIndex_AddressID
Click Add
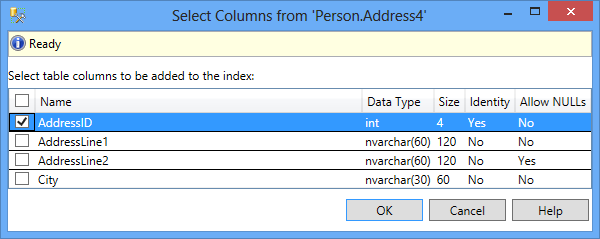
Select the column(s) you want to use as a clustered index
- Click OK. The selected column(s) will be listed in the Index key columns list
- If you want the clustered index to be unique, check the Unique check box
- Use other tabs to set index options, storage options, and extended properties
When the index in created successfully, it will be listed in the Indexes node for the specific table
The steps are similar for creating a nonclustered index
Another option to create a clustered index on the existing table using SQL Server management Studio is to:
- Right-click the table and select Design
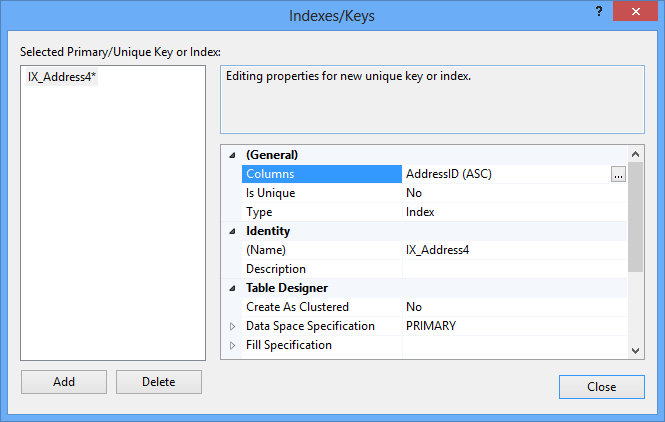
- Right-click the design grid and select Indexes/Keys
Click Add. By default, the identity column is added in the ascending order
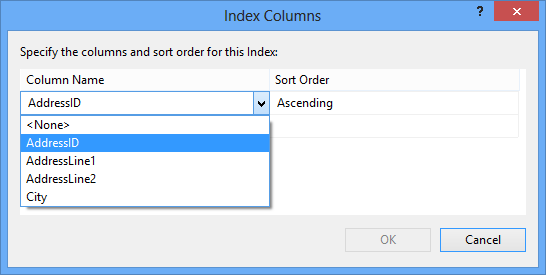
To select another column, click the ellipsis button in the Columns row and select another column and sorting order
- In the Create As Clustered column select Yes for a clustered index. Leave No to create a nonclustered index
- Again, it’s recommended to change the automatically created name in the Identity – (Name) row by a more descriptive one
- Click Close
- Click Save in the SQL Server management Studio menu to save the index
Heap or clustered SQL table?
When searching for a specific record in a heap table, SQL Server has to go through all table rows. This can be acceptable on a table with a small number of records.
As rows in a heap table are unordered, they are identified by a row identifier (RID) which consists of the file number, page number, and slot number of the row.
It’s not recommended to use a heap table if you’re going to store a large number of records in the table. SQL query execution on a table with millions of records without a clustered index requires a lot of time. Also, if you need to get a sorted results list, it’s easier to define an ascending or descending clustered index, as shown in the examples above, than to sort the unsorted results set retrieved from a heap table. The same goes for grouping, filtering by a value range.
In this article, we showed how to create clustered and nonclustered indexes using T-SQL and SQL Server Management Studio options, and pointed out the main differences between a clustered and heap table. In the next part of this article, we will explain what is considered to be bad indexing practice and give recommendations for creating indexes.

She has been working with SQL Server since 2005 and has experience with SQL 2000 through SQL 2014.
Her favorite SQL Server topics are SQL Server disaster recovery, auditing, and performance monitoring.
View all posts by Milena "Millie" Petrovic
- Using custom reports to improve performance reporting in SQL Server 2014 – running and modifying the reports - September 12, 2014
- Using custom reports to improve performance reporting in SQL Server 2014 – the basics - September 8, 2014
- Performance Dashboard Reports in SQL Server 2014 - July 29, 2014