
As you may already have figured out, the default settings in SQL Server are not always the best. Such is the case when you are working with new user databases; usually you get a single data (*.mdf) and transaction log (*.ldf) file. The data file resides within the PRIMARY file group; the only one we have so far, and it will store all of our databases objects, system objects, user tables, user stored procedures and all other objects. In some cases this default configuration may be good enough for you, but let us cover why would you prefer a different configuration in your production environment.
Working with multiple files and filegroups allows you to achieve higher throughput and to be more flexible when designing your environment.
An added benefit is that additional system PFS, GAM and SGAM pages can be latched within the memory avoiding contention,although most commonly it affects the TempDB system database. In addition the possibility exists to spread your data files between numerous disk drives achieving higher IO operations.
Utilizing the approach for using multiple FILEGROUPs, you have the possibility to split your data between multiple files within the same Filegroup, even when using table partitioning. In addition to that, you can use the additional filegroups to optimize your database throughput and achieve more flexible backup and restore process. The DBCC CHECKDB command in latest versions also allows you to perform checks on Filegroup level instead of only on the individual user database.
Upon creating a new database the SQL Server usually leaves you with a single Filegroup,PRIMARY, and two files, a single data file and a log file.
|
1 2 3 4 5 6 7 8 |
CREATE DATABASE [February] CONTAINMENT = NONE ON PRIMARY ( NAME = N'February', FILENAME = N'C:\MF\February.mdf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) LOG ON ( NAME = N'February_log', FILENAME = N'C:\MF\February_log.ldf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) |
Let us create an additional Filegroup and then place a new data file in it:
|
1 2 3 4 5 6 7 8 |
USE [master] GO ALTER DATABASE [February] ADD FILEGROUP [MAIN_FILEGROUP] GO ALTER DATABASE [February] ADD FILE ( NAME = N'February_Data', FILENAME = N'C:\MF\February_Data.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [MAIN_FILEGROUP] GO |
At the moment any new user object we create will go to the currently default Filegroup;PRIMARY. However, as we have already mentioned we would like to leave the PRIMARY filegroup only for the default system objects and all new user objects to be created within our ‘MAIN_FILEGROUP’ for example. To change this behavior we need to set the filegroup ‘MAIN_FILEGROUP’ as default. To do so we modify the filegroup as follows:
|
1 2 3 4 5 6 |
USE [February] GO IF NOT EXISTS (SELECT name FROM sys.filegroups WHERE is_default=1 AND name = N'MAIN_FILEGROUP') ALTER DATABASE [February] MODIFY FILEGROUP [MAIN_FILEGROUP] DEFAULT GO |
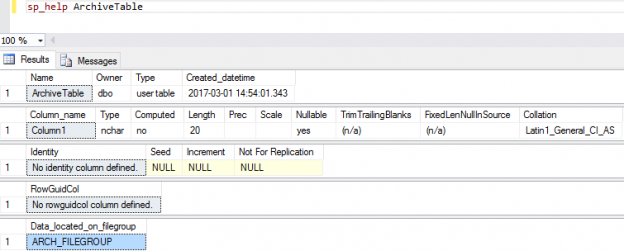
The new table ‘UserTable’ we’ve created is automatically created within the ‘MAIN_FILEGROUP’:
If within our user database we have more than one filegroup and we need to create a user object in a filegroup that is not the default one, we must specify this upon the creation of the object.
The following user table will be created within filegroup ARCH_FILEGROUP by stating this with the ‘ON’ statement.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE [February] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[ArchiveTable]( [Column1] [nchar](10) NULL ) ON [ARCH_FILEGROUP] GO |
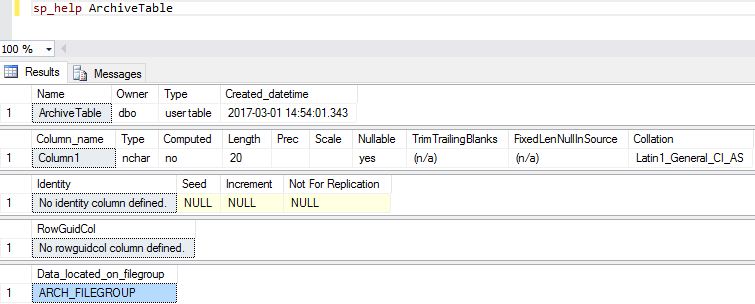
Not all user databases that we have to work with come configured the best way possible, usually as applications become more complex and databases become bigger we need to tune our environment. One of the options we have is distributing the data between different filegroups and files. However we would need to migrate the user objects from one place to another.
The problem of migrating a table from one filegroup to another can be solved in two different ways.
The first and the not-so-pretty solution is simply to create a new table in the target filegroup, to migrate all data from the old table to the new table and then to switch their names.
A more elegant solution is to use the possibilities of the CREATE INDEX T-SQL Command. Note that ALTER INDEX command cannot be used to repartition an index or move it to a different filegroup.
|
1 2 3 4 5 6 7 8 9 10 11 |
USE [February] GO DROP INDEX [CL_IX_U_Column1] ON [dbo].[ArchiveTable] WITH (ONLINE = OFF) GO CREATE UNIQUE CLUSTERED INDEX [CL_IX_U_Column1] ON [dbo].[ArchiveTable] ( [Column1] ASC ) ON [MAIN_FILEGROUP] GO |
The action above can be achieved by utilizing both clustered and non-clustered indexes. However when working with heaps we would need to temporary create an index only for the purpose of migrating the table.
Here we are creating a new index on a heap table which purpose is only to point the user object to a new filegroup. Once this index is created we can immediately drop it being confident that dbo.heap_table will now reside in the ‘MAIN_FILEGROUP’.
|
1 2 3 4 5 6 7 8 9 |
USE [February] GO CREATE NONCLUSTERED INDEX [CL_IX_Column1] ON [dbo].[heap_table] ([column1] ASC ) ON [MAIN_FILEGROUP] DROP INDEX [CL_IX_Column1] ON [dbo].[heap_table] GO |
In order to better design your database structure it is really important to understand how SQL Server works with multiple files within a filegroup.
By default the SQL Server uses a proportional fill strategy across all of the files within each filegroups. When new data is added it is not just written to the first file up until it is full, but new data is spread depending on the free space you have within your files.
A very simple example is when you have two data files within the same filegroup; data_file_1.ndf and data_file_2.ndf. The first file has 100MB free space and the second has 200MB free. When new data is added, the SQL Server first checks the free space allocations within the two files. Then, based on the free space information it has it will allocate one extend in data_file_1.ndf and two extends in data_file_2.ndf and so on. By using this simple striping algorithm both files should be full usually at the same time.

Sooner or later all files within a filegroup will be fully utilized and if automatic file growth is enabled the SQL server will expand them one file at a time in a round-robin manner. It will start expanding the first file and as soon it is full it will move the second file. It will expand it and write data to it, as soon it is full it will move to the next;data_file_3.ndf and so on, starting from the data_file_1.ndf again.
In the SQL Server 2014 there was the possibility to use trace flag T1117, which changes the behavior of file growth. In a filegroup containing multiple files, if a single file needs to grow it forces all other files to grow as well. Although this works great for the system database TempDB in combination with trace flag T1118 it was not a common configuration due to being a server wide setting.
Starting with SQL Server 2016 the defaults for TempDB system database are as its using trace flags T1117 and T1118 without affecting other user databases – it is achieved by introducing new filegroup level settings.
Within SQL Server 2016 an additional ALTER DATABASE setting at the FILEGROUP level has been introduced. The default one – ‘AUTOGROW_SINGLE_FILE’ works exactly as explained above – utilizing the round-robin algorithm. For filegroups having more than one file the new option ‘AUTOGROW_ALL_FILES’ can be enabled which forces an file expand to happen on all files within the filegroup.
In order to enable it we would need to alter the database:
|
1 2 3 |
ALTER DATABASE February MODIFY FILEGROUP MAIN_FILEGROUP AUTOGROW_ALL_FILES |
DBCC CHECKFILEGROUP allows us to perform a CHECKDB operation only on a single filegroup, the following will check only the PRIMARY filegroup:
|
1 2 3 4 5 |
DBCC CHECKFILEGROUP WITH NO_INFOMSGS GO |
To perform a check on one of the additional file groups we would need information about the group ID:
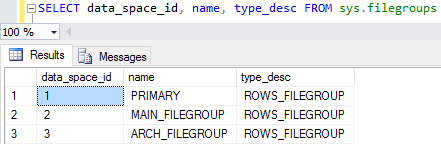
To perform check on the MAIN_FILEGROUP we need to specify this using the group ID – 2:
|
1 2 3 4 5 |
DBCC CHECKFILEGROUP (2) WITH NO_INFOMSGS GO |
SQL Server databases with multiple filegroups can be restored in stages using piecemeal restore. The piecemeal restore works quite similar as the normal restore operation utilizing the three phases; data copy, redo and undo. You can perform a restore of one of your filegroups while your database and the other filegroups remain online.Please keep in mind that when recovering the PRIMARY filegroup your database should be offline.
References
- DBCC CHECKFILEGROUP (Transact-SQL)
- SQL 2016 – It Just Runs Faster: -T1117 and -T1118 changes for TEMPDB and user databases
- Performing Piecemeal Restores

View all posts by Kaloyan Kosev
- Performance tuning for Azure SQL Databases - July 21, 2017
- Deep dive into SQL Server Extended events – The Event Pairing target - May 30, 2017
- Deep dive into the Extended Events – Histogram target - May 24, 2017