
In this article, we will learn the basics of working with views in the Azure Database for PostgreSQL.
Introduction
The fundamental data object that hosts data in a database management system is a table. Reading and writing data from tables in a database is the most fundamental thing, that anyone who has worked with databases would have done. Data consumption tools source data from tables, but generally the recommended practice is not to query the tables directly. On one end, the table is considered the fundamental block of data storage and on the other end the recommended practice of not query it directly raises the question of the rationale behind it. One of the reasons for it is to allow change management in tables without affecting the consumers who are sourcing data from it. Consider that a table with a large volume of data and equally varied consumers like reports, ETL jobs, application APIs and other such tools directly sourcing data from it. When the schema of the table would change, all the downstream consumers consuming data from it would be impacted. The consumers who need the updated schema with newer attributes anyway need to update the data pipelines, but consumers who intend to continue with the same schema would get impacted too though they have nothing to do with the new schema or additional attributes. In such cases, in architectural terms, a façade is introduced between tables that host data and consumers that consume data from these tables. The practical form of façade in a database can be a view, a stored procedure, or a similar class of database objects.
A view can be considered as a dataset that has a pre-determined schema, the data is derived based on a specific criterion and is the source from one or more underlying tables. When a view is queried for data, it, in turn, queries the underlying tables and presents the intended dataset. At times, when the volume of data is very large, a view may start impacting query performance. In those cases, data from the underlying tables with the intended logic that makes up the view is physically stored in another table. This specific construct is called a materialized view. As the data from the source table gets updated, this materialized view needs to be refreshed from time to time to keep the data update in the materialized view, unlike a regular view. Azure’s offering of PostgreSQL database is Azure Database for PostgreSQL and it offers the same features as well.
Views in Azure Database for PostgreSQL
As we would be working with Azure Database for PostgreSQL, we would first need an Azure account with the required privileges to operate on the PostgreSQL database. It is assumed that this account and setup are already in place. Assuming that one has already logged into the Azure portal and navigated to the Azure Database for PostgreSQL service dashboard, we need to create a new instance of PostgreSQL if one is not already in place. We can click on the Create button to invoke the wizard for creating a new database instance. This would bring the four options to select a flavor of PostgreSQL that meets our needs. For our scenario, we can use the most basic version of Azure Database for PostgreSQL i.e., Single Server as shown below.
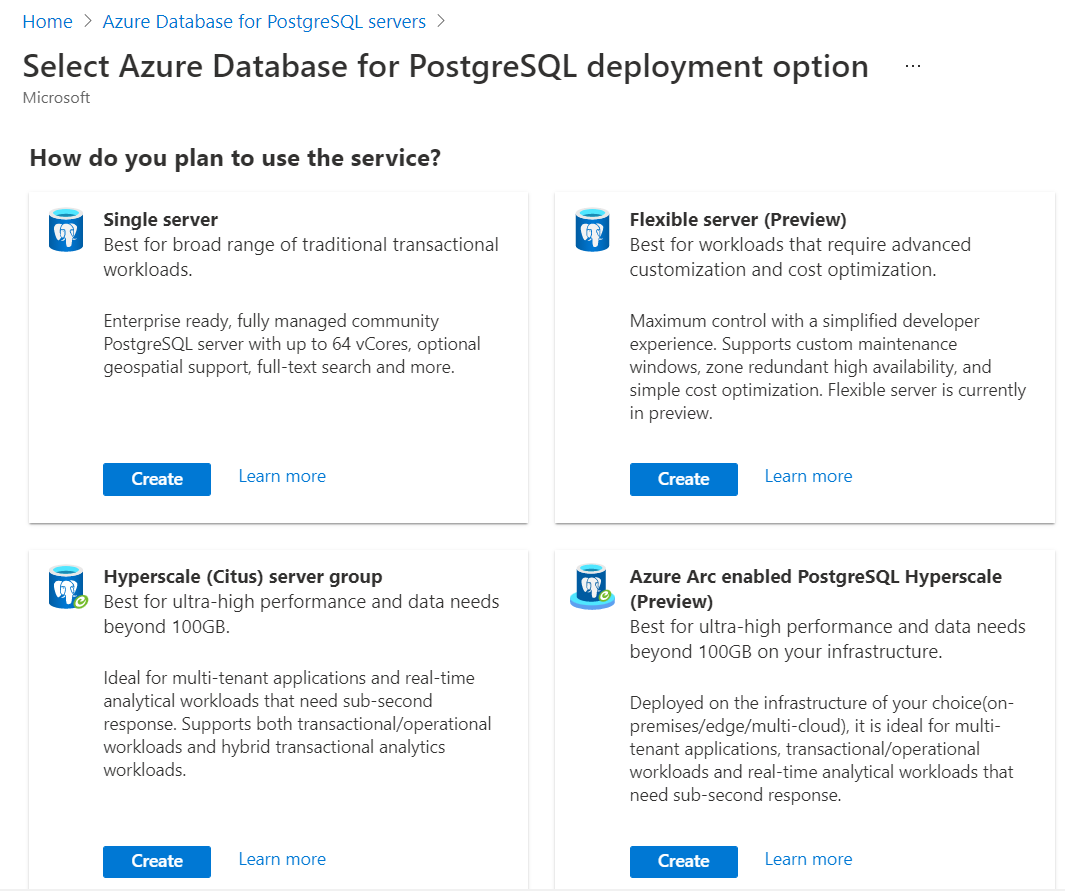
Follow the wizard and provide the necessary details required to create a new instance of Azure Database for PostgreSQL – Single Server. Once created, it would allow to navigate to the dashboard of the instance. From the dashboard, we would be able to manage and access the various features of this instance including the endpoint address of this instance. To operate on this instance, we would need an editor that can be used with PostgreSQL. One of the most famous editors that are commonly used with PostgreSQL is pgAdmin. We can use the same with Azure Database for PostgreSQL as well. It is assumed the pgAdmin or the like of this tool is already installed, set up and configured to connect with the instance that we created in the above step. One may need to configure the firewall settings of the instance to allow incoming traffic from the local machine where pgAdmin would be installed to this instance on Azure.
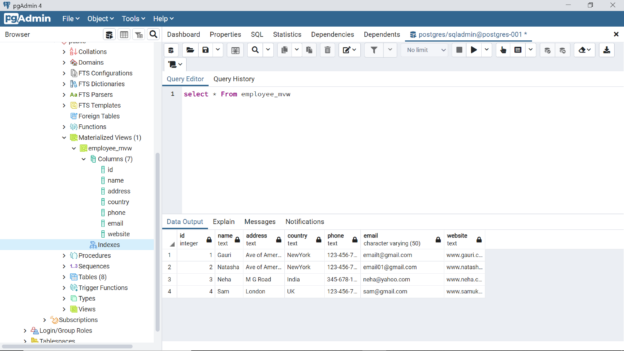
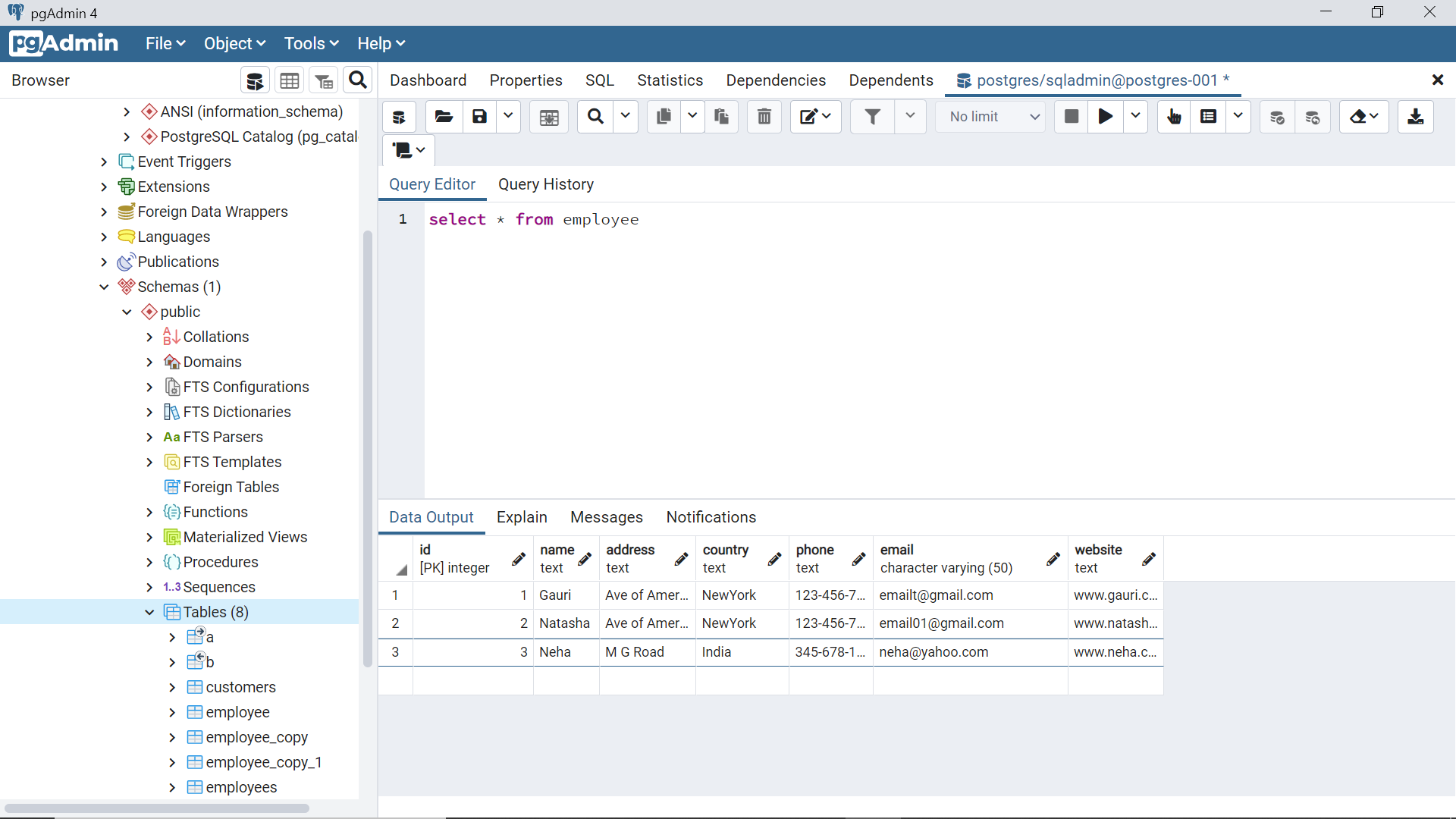
Once we are connected to this instance, we can start focusing on creating views. As tables are the underlying source of data that are referenced by views, we firstly need at least one table in place. We can use the regular SQL query language or even using the graphical interface of pgAdmin and create a new table with some fields. Once the table is created, we need to populate it with few records so that we can use this data to visualize the difference between how a regular view operates versus a normalized view. When one such table is in place, we would be able to query it as shown below. In this case, we have an employee table with few fields and some records in it.
To create a simple view that accesses this data from the employee table, we can use the CREATE VIEW statement as shown below. We specify the name of the view in the CREATE VIEW statement, followed by the query logic in the AS part of the statement. Here we are exposing the entire table with all fields and entire data through this view. One can filters the data vertically as well as horizontally using the desired logic.
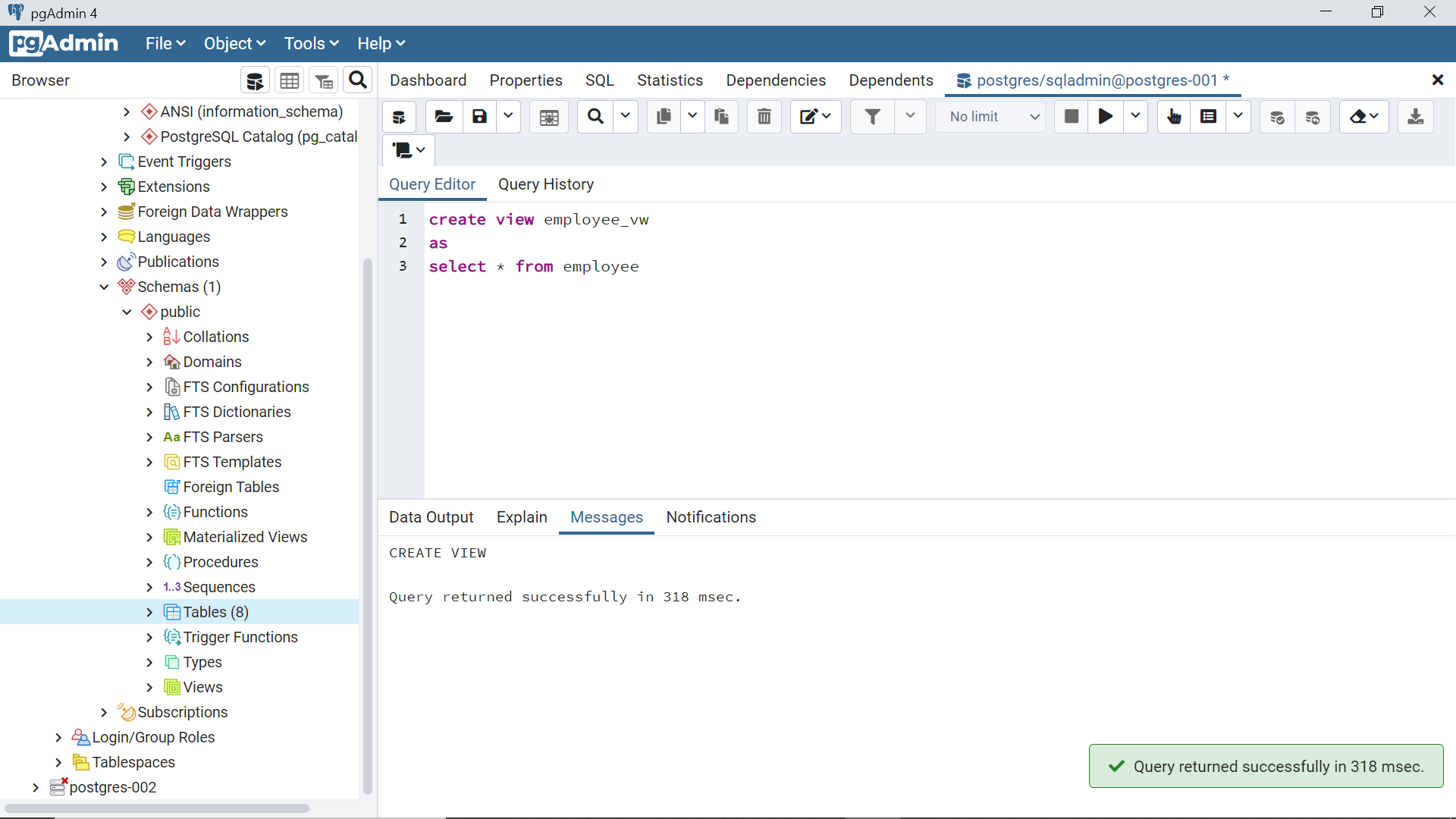
To create a materialized view, one needs to use the word “materialized” in the CREATE VIEW statement as shown below. The rest of the aspects of creating a materialized view is identical to creating a regular view.
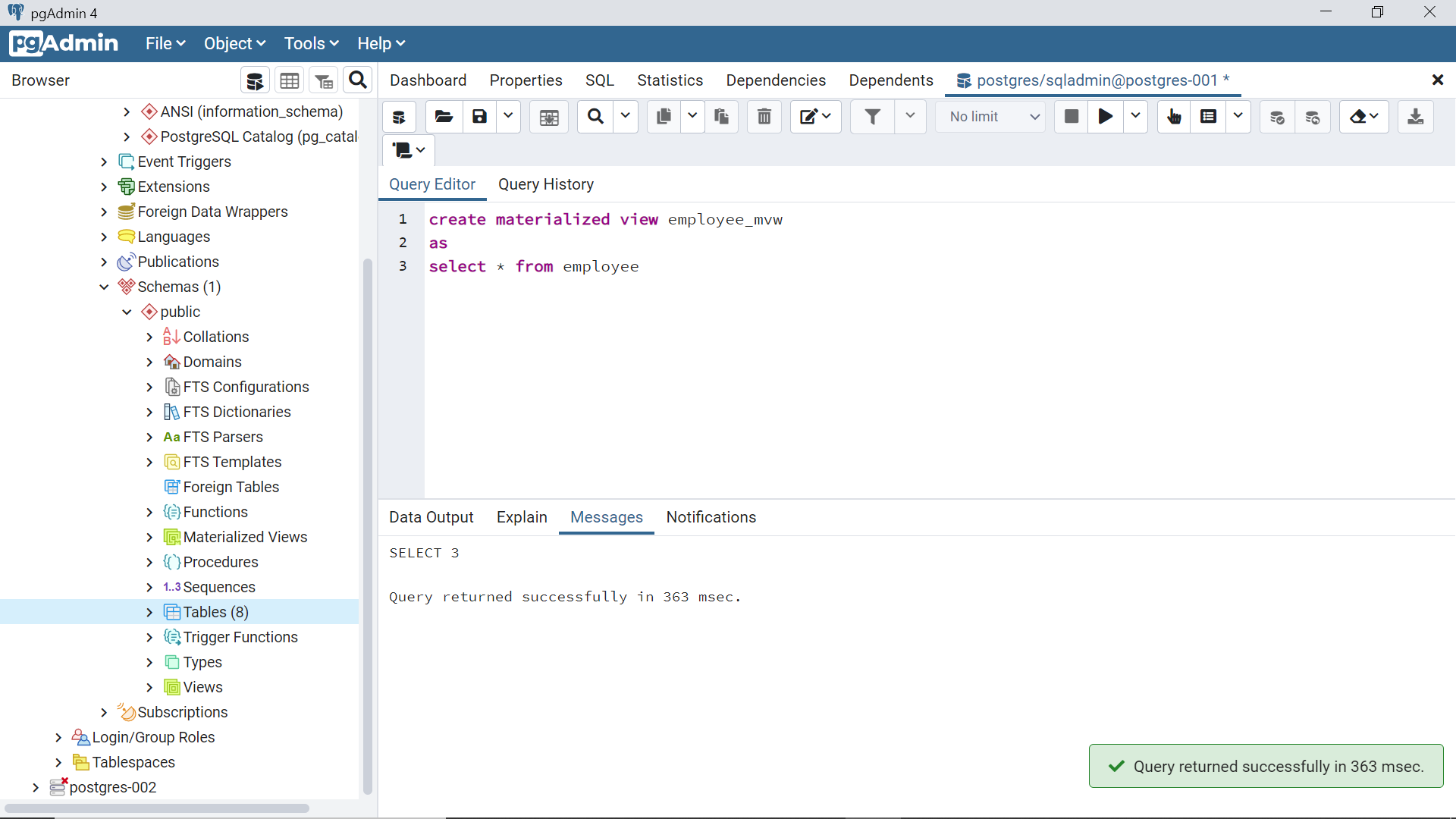
We can test the view by query it like a regular table using the SELECT statement and the result is as shown below. It would fetch the data from the underlying table mentioned in the definition of the view.
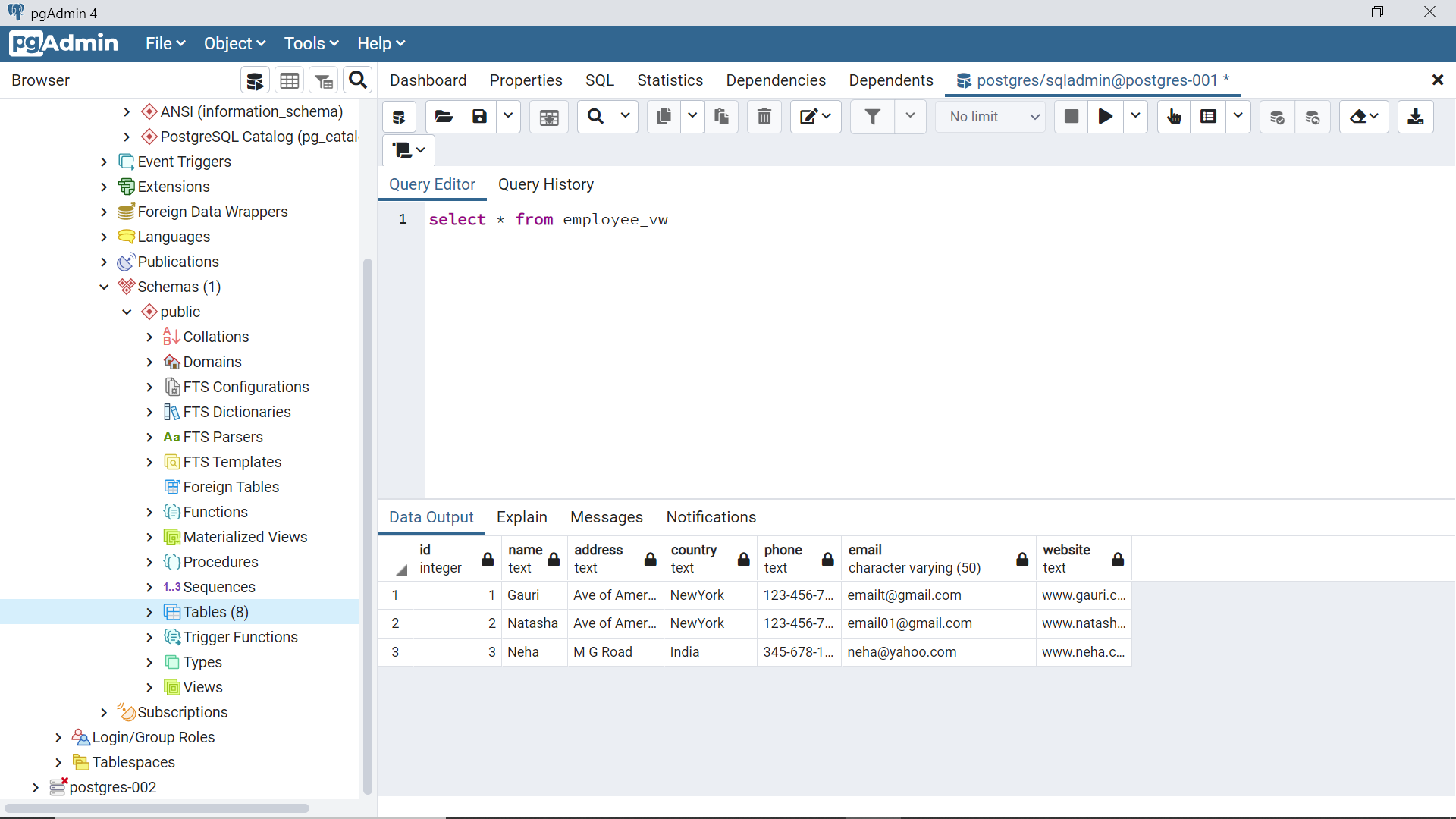
The materialized view would also show the same data but the difference here is that materialized view would not fetch data from the underlying tables. It physically stores data in a separate and independent data construct. It can be thought of as an independent table. By default, any changes made to the employee table would have no impact on the materialized view created from it.
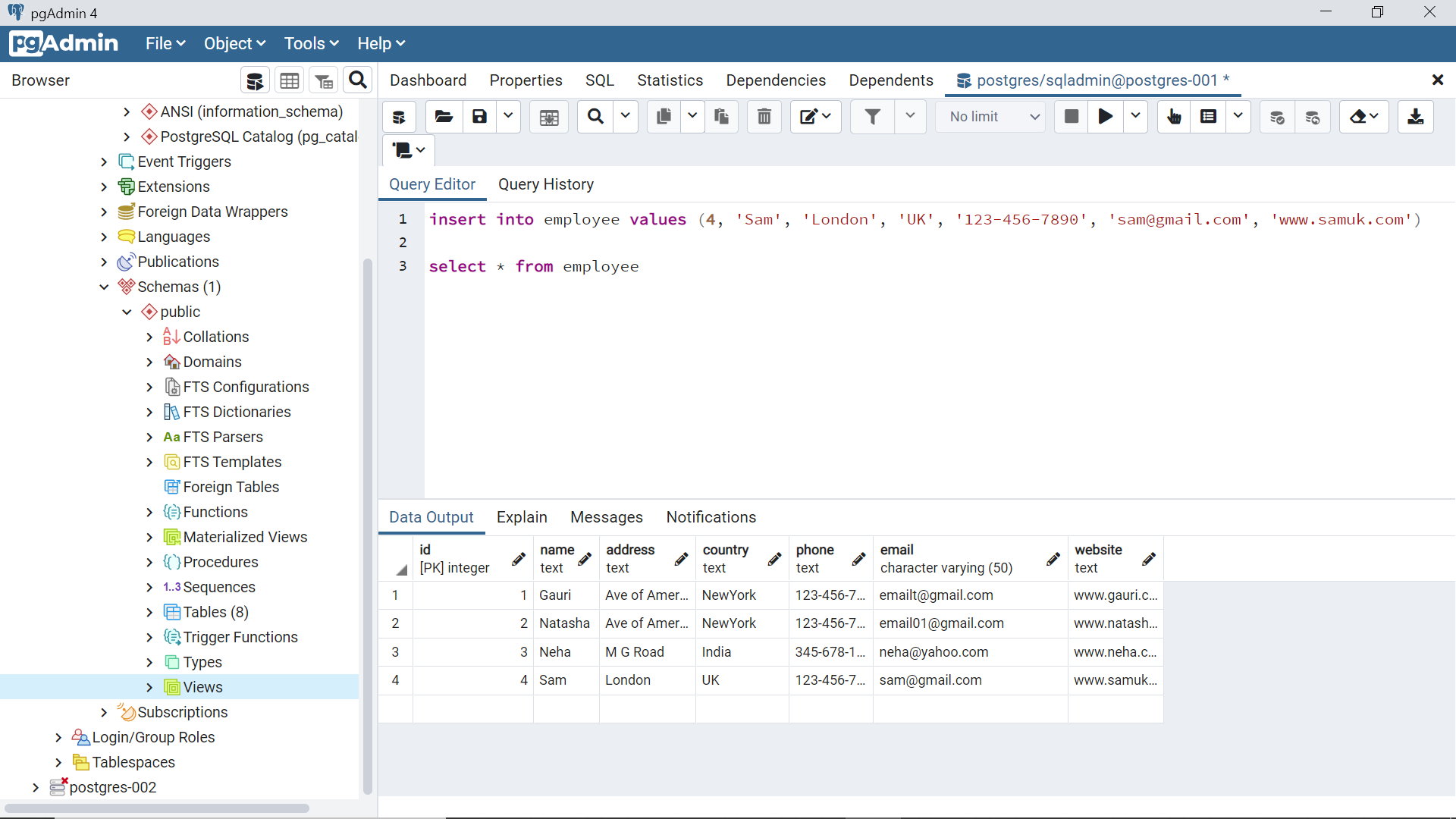
To test the impact of data changes in the base employee table, we can insert a new record in the employee table as shown below using the INSERT statement. After inserting the new record, we can query the table to ascertain that the record got inserted successfully.
Query the regular view that we created earlier using the same SELECT statement as shown below. This view would reflect the same data that exists in the base tables, as the view fetches the data from the table.
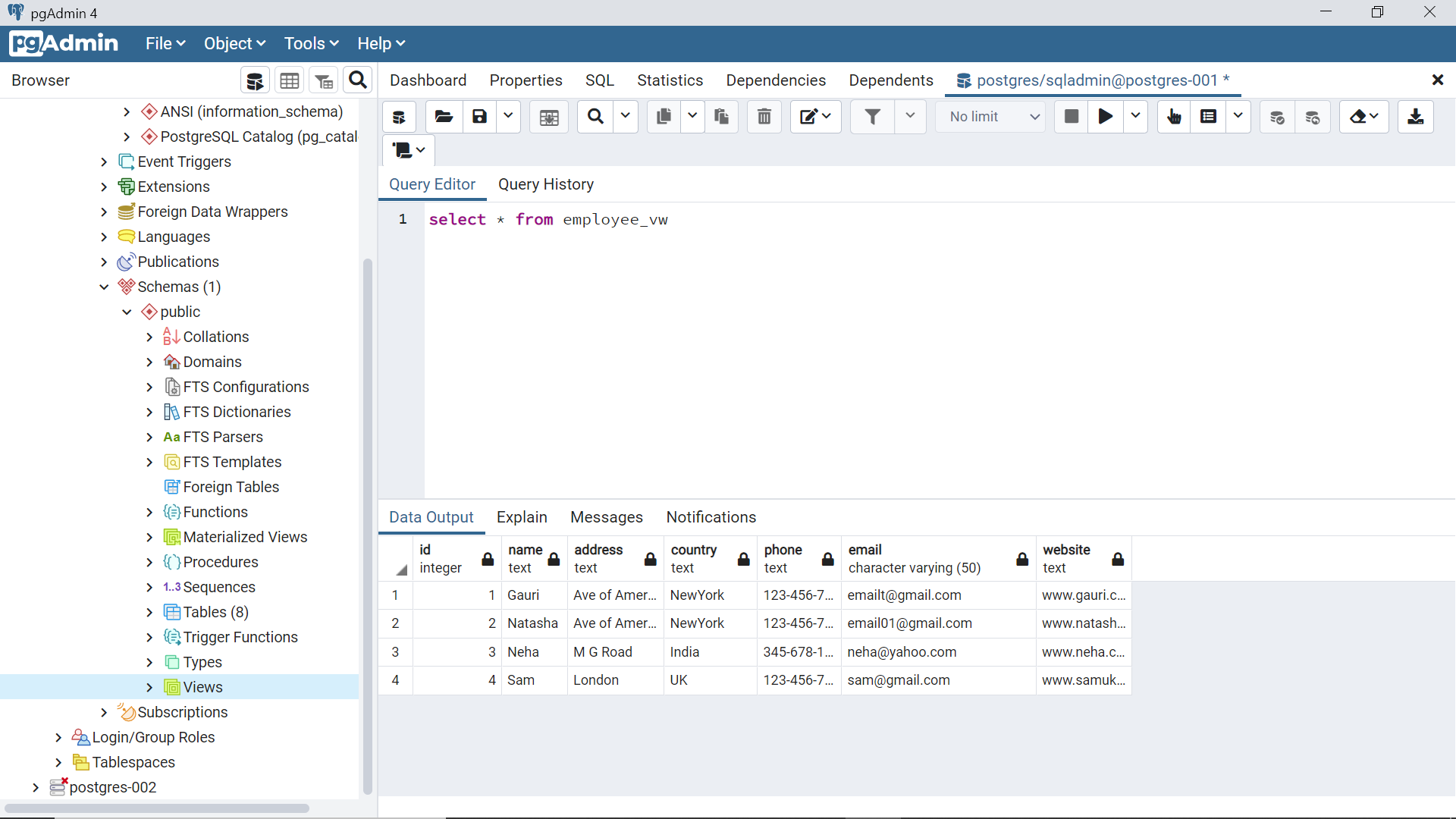
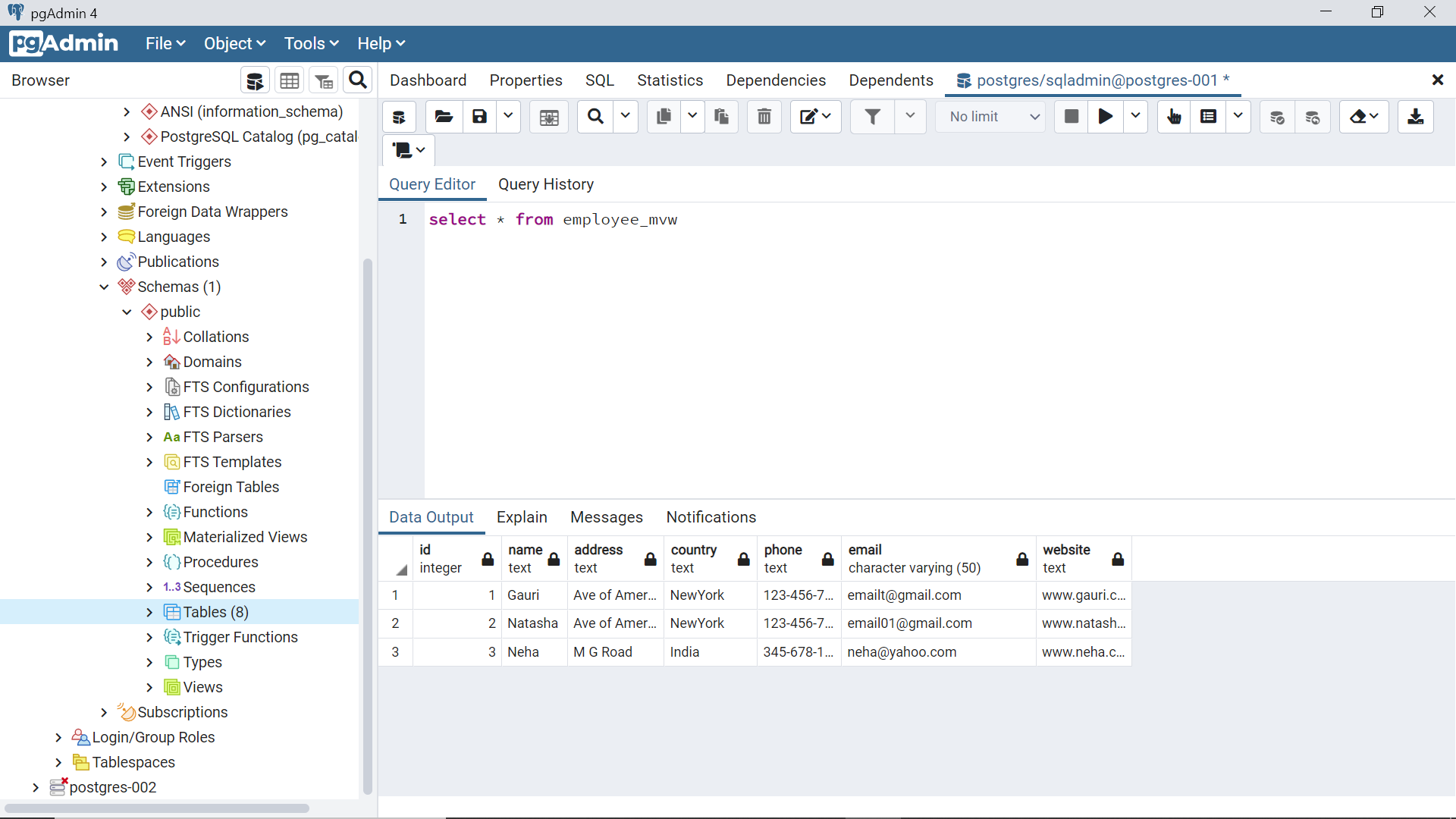
If we query the materialized view using the same way, it will not reflect the newly inserted record unlike a regular view. Materialized view needs to be refreshed explicitly to update it with the data changes from the base tables.
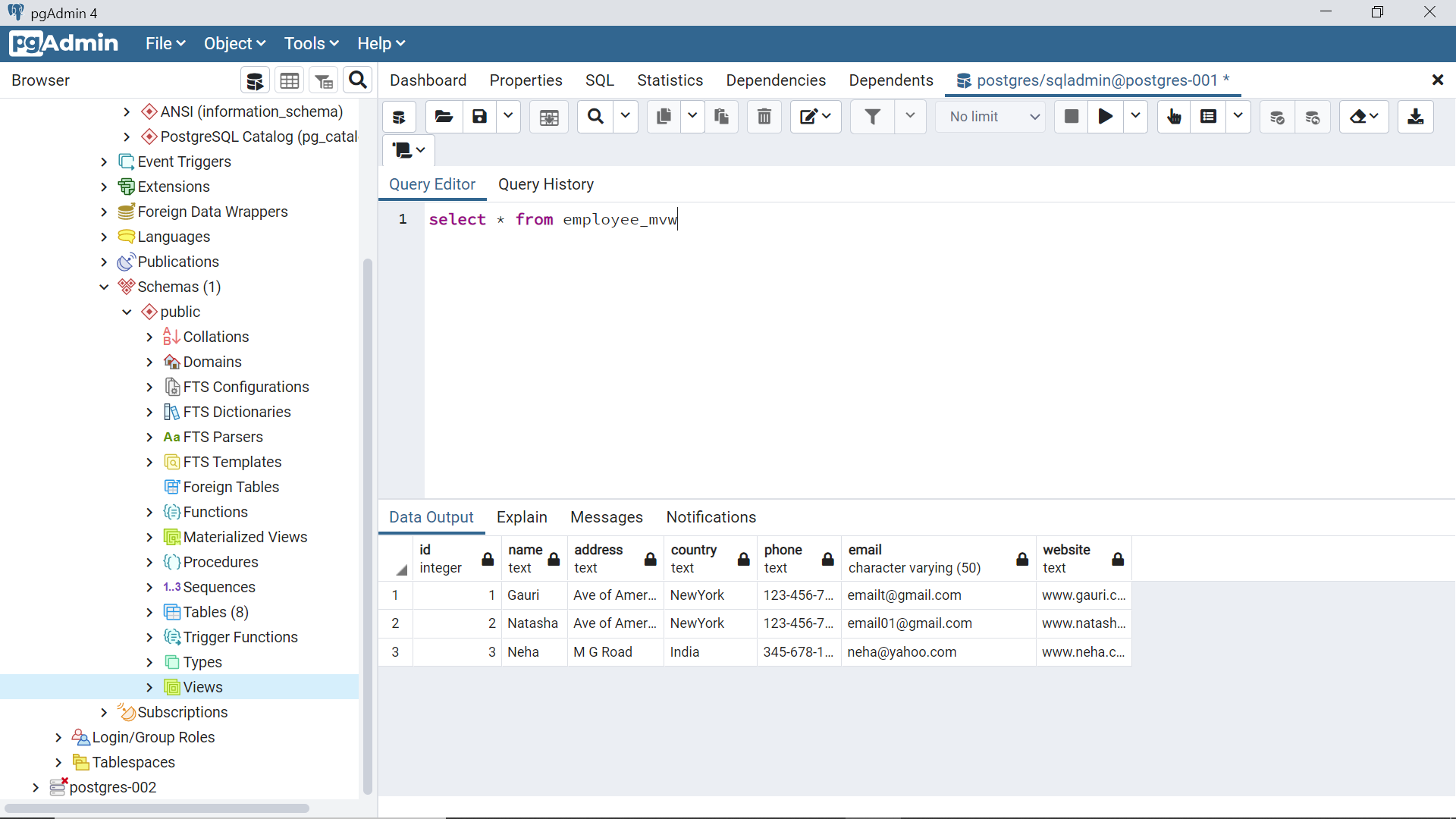
In Azure Database for PostgreSQL, this can be accomplished very easily using the REFRESH MATERIALIZED VIEW statement as shown below. In many databases, this must be done using the ETL mechanism, but PostgreSQL provides a seamless way to do it the REFRESH statement as shown below. While the materialized view is being refreshed, Azure Database for PostgreSQL may lock the entire table for querying. To avoid this, one can use the keyword CONCURRENTLY at the end of the statement, so that it will allow querying of the materialized view while it is being refreshed.
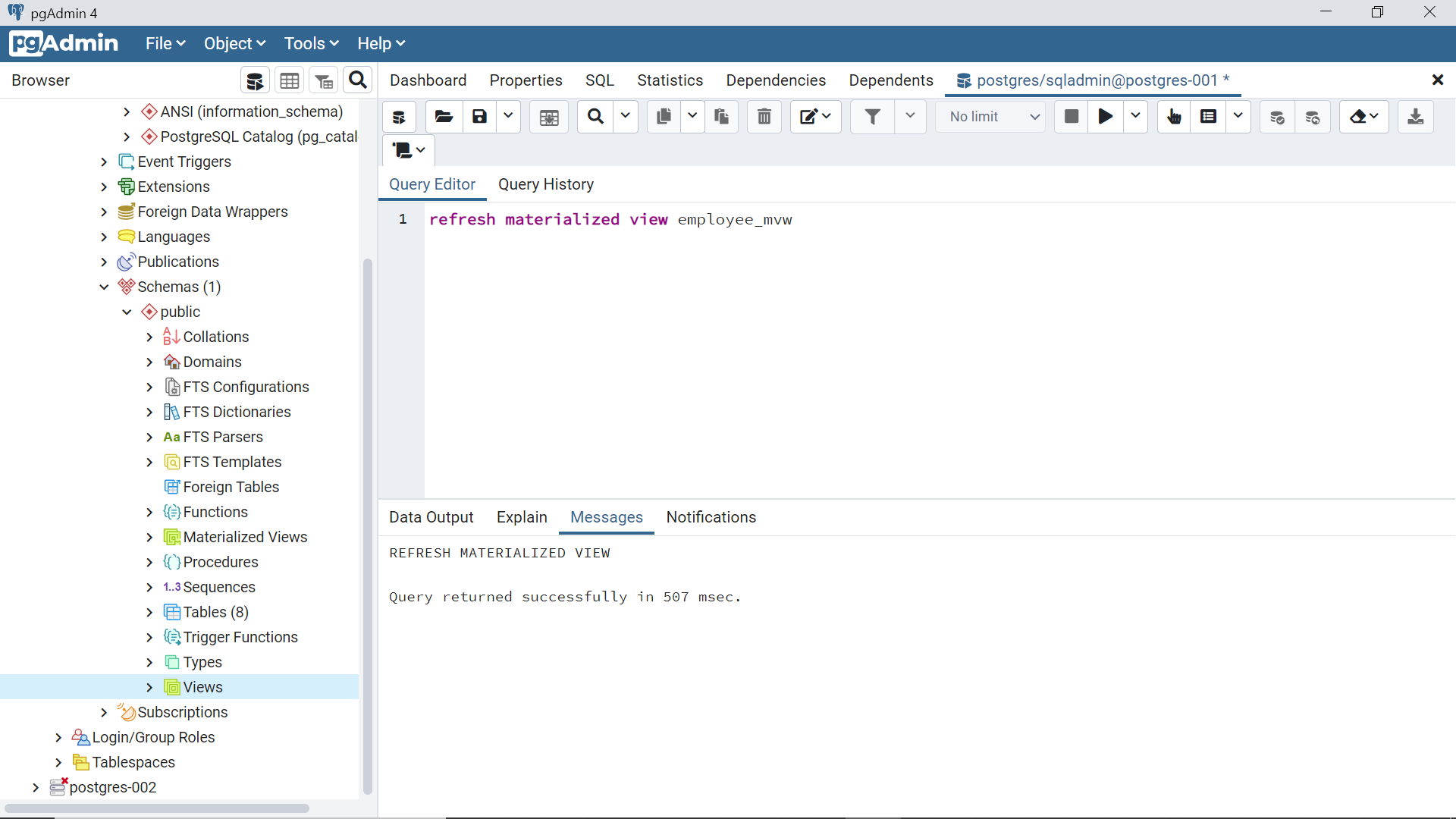
Once the view is refreshed, query it again and now we should be able to find the new record in this view as shown below.
The rest of the DDL and DML commands to operate a view or a materialized view in Azure Database for PostgreSQL is the same as operating any other database objects. In this way, we can work with two types of views in the Azure Database for PostgreSQL.
Conclusion
In this article, we learned the importance and need for views for a robust data consumption approach. We briefly discussed the way of creating a new instance of Azure Database for PostgreSQL, we created a basic table with a few records and then we learned how to create and operate a regular view as well as a materialized view.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023