
Background
On occasion, I’ll see waits that exceed what I expect well above normal and a few of them have some architecture and standards to consider following when troubleshooting, though like most waits’ issues, there can be other underlying factors that are happening as well. In this article, I investigate the three waits ASYNC_NETWORK_IO and WRITELOG. In general, waits vary by environment and server, so before reading this article an immediate question to ask is, “Do you know what’s normal for yours?” When a wait suddenly spikes, or if the architecture is designed in a manner that should prevent a specific wait from consuming time, and yet you see that the wait does, I would be concerned. In addition, because applications and environments differ by architecture, you may want to consider other troubleshooting steps, as these may not apply to your situations.
Discussion
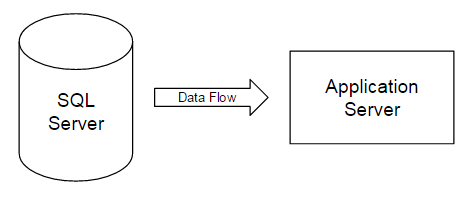
ASYNC_NETWORK_IO. In a multi-server application or ETL environment, this wait almost always occurs when one server is architected better than another server – whether better in that case is more hardware horsepower, a later edition of a database, or a .NET application that can’t keep up with the SQL Server. SQL Server has to wait on the other resource to respond – for an example using ETL, an load batch from SQL Server is sent to a MongoDB server, but the MongoDB server struggles to process the batch quickly thus SQL Server waits on the processing of the MongoDB server. An unrelated analogy would be someone trying to place low-limit orders in a market experiencing a rapid upswing – the market outruns orders like these because of how fast it trends upward. In the image below where we have data flowing from server one (SQL Server) to server two (Application Server), server two can dictate the speed of server one if it lacks the resource power to receive data fast enough:
WRITELOG. I’ve caught this wait type in two common scenarios, though it’s important to know how this can occur. Before writing a record to disk, log operations first occur on a memory block called the log buffer, and in administration and development, we’ll often see situations where a record that is inserted is also updated while the record is still in memory. This wait reflects the latency between the memory flush to disk.
Useful tips and questions
For troubleshooting ASYNC_NETWORK_IO problems, my solutions depend on how much permissions and (or) access I have to the second server which is struggling to maintain the performance level of the first server and how much I can match its power to the first server. Assuming that I cannot and I only can fine tune the first server:
I will reduce the SQL statements to a point where the second server can keep up the speed of the second server. In a sense, I become the governor. In testing loads, there is often a threshold at which a load can hit the “Goldilocks”-point of just right in that below and above that point receive less speed. As an example in median environments, I often start in batches of 25,000-40,000 for loads because that’s generally been a sweet spot. However, in larger environments, that’s way too low as a starting point, so it significantly varies.
I’ll re-evaluate the time relative to the second server’s resource use. It is possible that the second server is already receiving a batch of data from a load from other servers and the delay is caused by other applications, loads, client use, etc. As an example, in one case, moving a load post a massive delete helped increase performance, as the massive delete (which wasn’t optional) used many of the server’s resources while other applications were connecting that were performing other CRUD operations. Since the second server had to have that bottleneck for that period of time, the load from the first server after the massive delete finished saw a huge performance increase. When architecting a solution for ETL, maintenance, or any other additional tasks, consider that timing can be a deciding factor. In some cases with ASYNC_NETWORK_IO, the second server is busier than the first.
I will re-evaluate my transforms on the second server, most notably for ETL processes in this case. I’ve seen a lot of ETL flow that extract data on one server, transform on another server, and load on yet another set of servers. Let’s assume that my first extract server has a lot of resources and that the second server is my bottleneck; relative to the environment, I might do some or all transforms on the first server to reduce the impact on my second server, especially if the post-transform sees a reduction in data. As an example of this, rare precious metals, prices are not always available for the London, Hong Kong and New York markets so a transform task take the prices that are available along with the high and low differences between these markets (if applicable) with the final table possessing only four columns instead of the full set. That reduction of the data set means that loading data from one server to another server will be smaller. In addition, in some cases, I can reduce resources by performing transforms in the .NET layer instead of using T-SQL; T-SQL is a set based language, and performs poorly on individual records, which some transforms require. In these cases, I’ll stick to PowerShell and (or) C#.
The assumptions in the above techniques assume that I cannot increase any hardware power on the second (or receiving) server. Regardless of the environment, development must match the relative power of each server involved in a process; it makes no sense to have an application server that can only handle one fourth of what a SQL Server is able to send, if the full amount of what SQL Server is sending will be needed as soon as possible. In an environment like that, since what SQL Server sends is required, the application server must match it, otherwise the end user will suffer.
For troubleshooting WRITELOG, the three common issues I see are memory bottlenecks, lingering checkpoints, and per-record writes, which are incredibly costly. Some troubleshooting tips for these three issues:
For memory bottlenecks outside of vertical scaling, I will optimize expensive queries that use memory ineffectively where possible. As an example of this, running a replication’s distribution history cleanup may be costly to memory (note the fall in PLE and spike in memory), so relative to the time of the bottleneck, adjusting schedules for tasks, maintenance, ETL, etc may help.
With checkpoints lingering, I typically use a PowerShell script that terminates quickly (very short timeout) and runs a checkpoint. The key to avoiding these lingering checkpoints – which can occur – is to avoid allowing them to run forever. They may not be able to run due to other resources using the log. I’ve seen checkpoints that run for hours because they’re blocked by one transaction, and either the blocking transaction needs to be re-evaluated, or the checkpoint needs to try for a short period of time. We can always run checkpoints at a more appropriate time.
Similar to .NET application creating and disposing an object on each loop (slow practice), if we commit one transaction at a time in a batch insert the cost will be greater than committing the batch as a whole. Anytime I see a batch transaction, I immediately look for any explicit declaration of BEGIN/COMMIT/ROLLBACK, because it may be the culprit if it’s not explicitly declared. Similar to the above point on network, if I want to commit one record at a time because I don’t want a full batch to fail, I’ll wrap my logic inside of .NET since that will be much faster at object at a time rather than allowing T-SQL to handle it.

In an ideal environment, my drives for different reasons are separate due to the read and write volume on the disks. Do I delineate my disks for data, log and tempdb? Be very careful about keeping log files on the same disks as “everything else” as a disk must be able to keep pace with writes and reads. Another recommendation I’ll make related to this point – scale out your disks for log use ahead of time and be very careful about relying on automated log growth; I heavily scrutinize any person or environment with automatic log growth.
In this configuration example, the log is pre-grown to 51200MB and restricted to that growth. I’ve seen a few other situations, one of which was no disk space (how does memory flush to disk when there’s no disk space remaining), though these generally are rarer than the above cases. Like with all waits troubleshooting, each environment may experience differing reasons for the same waits.

Final thoughts
These tips provide some useful techniques for ASYNC_NETWORK_IO and WRITELOG wait types, and are by no means every troubleshooting possibility available, though they have been useful in reducing these waits. The more you understand your architecture, the more you’ll identify the weak points and you can either strengthen these – as systems are only as strong as their weak points – or you can design around them, if strengthening is not an option.

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020