
One of the paramount ways to guard data within a database is to utilize database encryption. However, no one encryption solution is perfect for all databases. Which encryption solution you select totally depends on the requirements of your application. Note that more powerful encryption for larger amounts of data requires a healthy amount of CPU. So, be prepared in the event that that introduction of encryption increases the system load.
This article will start with the divergence of hashing and encryption, and give all the details of the HashBytes function used in T-SQL
In addition, I’ll discuss …
- Details about the function with syntaxes and clear examples
- How to store and check passwords with hashbytes function
- How to deal with the restriction of the return value 8000 bytes limit
- Some restrictions such as Collation difference, or data type with Unicode data
Hashing versus Encryption
There are two main methodologies to safeguard your data: hashing and encryption. Encryption is accomplished via one of several different algorithms that return a value that can be decrypted through the correct decryption key. Each of the different encryption options provides you with a different strength of encryption. As I have mentioned earlier, the stronger level of encryption you use, the greater the CPU load on the Microsoft SQL Server.
However, if we can talk about hashing values, we are mainly referring to hashing algorithms. Hashing algorithms provide us a one-way technique that has been used to mask data, in which we have a minimal chance that someone could reverse the hashed value back to the original value. And with hashed techniques, every time you hash the original value you get the same hashed value.
Supported algorithms
Microsoft SQL Server has supported the same hashing values from Microsoft SQL Server 2005 to Microsoft SQL Server 2008 R2. You can use MD2, MD4, MD5, SHA, or SHA1 to create hashes of your data. These algorithms are limited up to 20 bytes only.
In SQL Server 2012, we have an enhancement in this function and now it supports SHA2_256, SHA2_512 algorithms that can generate 32 and 64 bytes hash codes for the respective input.
Beginning with SQL Server 2016, all algorithms other than SHA2_256, and SHA2_512 are deprecated. Older algorithms (not recommended) will continue working, but they will raise a deprecation event.
The HashBytes function in T-SQL
Hashing can be created, regardless of the algorithm used, via the HashBytes system function. A hash is an essential calculation based on the values of the input, and two inputs that are the same ought to produce the same hash.
Syntax
If we talk about the syntax for SQL Server, Azure SQL Database, Azure SQL Data Warehouse, and Parallel Data Warehouse the below images describe the syntax in detail.
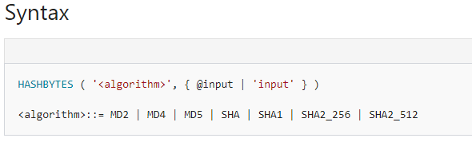
The key word in syntax
‘<algorithm>’
In this, we have to initiate the hashing algorithm to be used to hash the input. This is a mandatory field with no default. And its also requires a single quotation mark. Starting with SQL Server 2016, all algorithms other than SHA2_256, and SHA2_512 are deprecated. Older algorithms (not recommended) will continue working, but they will raise a deprecation event.
@input
In this, we have to specify a variable that contains the data to be hashed. @input is varchar, nvarchar, or varbinary.
‘input’
this specifies an expression that evaluates to a character or binary string to be hashed.
The output conforms to the algorithm standard: 128 bits (16 bytes) for MD2, MD4, and MD5; 160 bits (20 bytes) for SHA and SHA1; 256 bits (32 bytes) for SHA2_256 and 512 bits (64 bytes) for SHA2_512.
The below image depicts all supported algorithms with their respective lengths
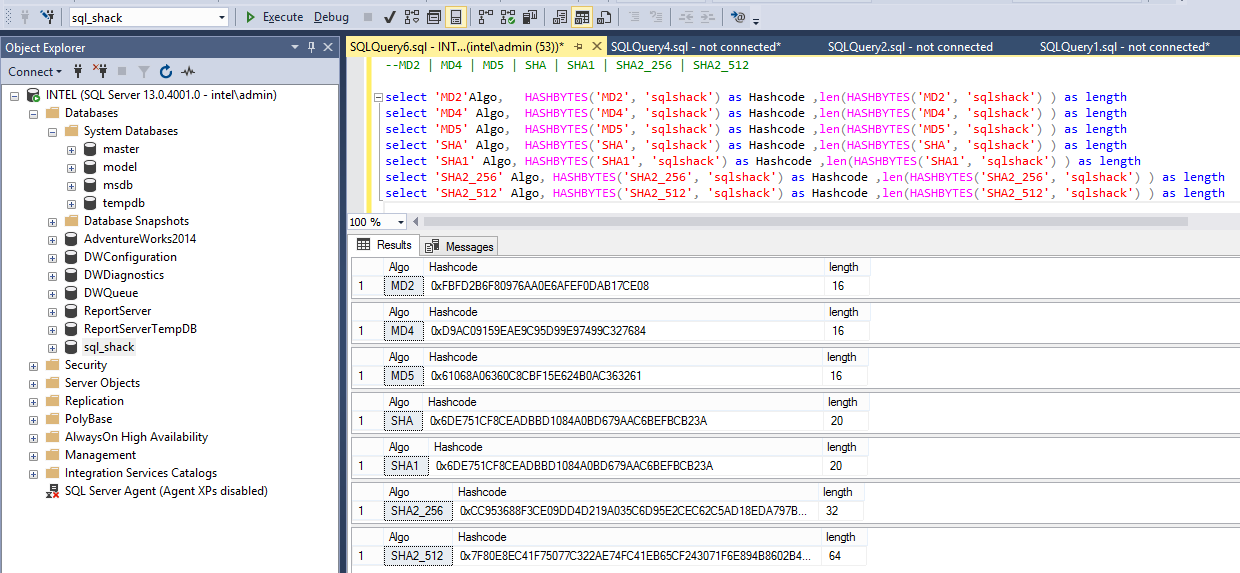
The HashBytes function accepts two values: the algorithm to use and the value to get the hash for.
The HashBytes system function does not support all data types that Microsoft SQL Server supports before SQL server 2016. The biggest problem with this lack of support is that the HashBytes function doesn’t support character strings longer than 8000 bytes (For SQL Server 2014 and earlier, allowed input values are limited to 8000 bytes.)
To be more specific, when using ASCII strings with the CHAR or VARCHAR data types, the HashBytes system function will accept up to 8000 characters. When using Unicode strings with the NCHAR or NVARCHAR data types, the HashBytes system function will accept up to 4000 characters. We will provide a solution how to come up with this particular restriction.
HashBytes < 2014
I will now explain the HashBytes function as it existed before 2014, not allowing large string in SQL Server and its solution.
Let’s quickly look at the example.
|
1 2 3 |
CREATE TABLE dbo.Sql_Shack_Demo (Filed NVARCHAR(MAX)); INSERT into Sql_Shack_Demo Select Replicate('Temp',50001) SELECT hashbytes('MD2',Filed) From Sql_Shack_Demo |
The above code will throw the exception “String or binary data would be truncated.” as shown below:

To overcome the limitation, I have come up with a solution, a SQL function, to break down the string into multiple sub-parts and apply the hashing separately and later re-constitute them back into a single string
The script is as below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
Create Or Alter FUNCTION [dbo].[Get_HASH_val_for_Large_String] ( @St_val nvarchar(max) ) RETURNS varbinary(200) AS BEGIN Declare @Int_Len as integer Declare @varBina_Val as varbinary(20) Declare @Max_len int = 3999 Set @Int_Len = len(@St_val) if @Int_Len > @Max_len Begin ;With hashbytes_val as ( Select substring(@St_val,1, @Max_len) val, @Max_len+1 as st, @Max_len lv, hashbytes('SHA1', substring(@St_val,1, @Max_len)) hashval Union All Select substring(@St_val,st,lv), st+lv ,@Max_len lv, hashbytes('SHA1', substring(@St_val,st,lv) + convert( varchar(20), hashval )) From hashbytes_val where Len(substring(@St_val,st,lv))>0 ) Select @varBina_Val = (Select Top 1 hashval From hashbytes_val Order by st desc) return @varBina_Val End else Begin Set @varBina_Val = hashbytes('SHA1', @St_val) return @varBina_Val End return NULL END |
Now we execute scripts and the error has vanished.
|
1 2 3 |
CREATE TABLE dbo.Sql_Shack_Demo (Filed NVARCHAR(MAX)); INSERT into Sql_Shack_Demo Select Replicate('Temp',50001) SELECT dbo.Get_HASH_val_for_Large_String (Filed) From Sql_Shack_Demo |

I hope this will help you whenever you may need to generate hashes for larger strings in SQL Server versions prior to 2014
Checking and storing Passwords with Encryption
First of all, we have to make sure that the field or column we have used to preserve password for store the hash code is of data type varbinary. Then, use the HashBytes function in the insert statement to generate the hash for the password and store it in the column. Below is the salient example of storing a password in hash code with SHA2 512 algorithm and comparing the hash-coded password in a select statement.
Example
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE TABLE [dbo].[Users_detail]( [ID] [int] NOT NULL, [Name] [nvarchar](20) NOT NULL, [Password] [varbinary](150) NOT NULL ) ON [PRIMARY] GO Insert into Users_detail values (1, 'sql_shack_User1', HASHBYTES('SHA2_512', 'Sanya')) Insert into Users_detail values (2, 'sql_shack_User2', HASHBYTES('SHA2_512', 'Luna')) GO Select * from Users_detail GO CREATE or alter FUNCTION Password_Check ( @v1 varchar(500) ) RETURNS varchar(7) AS BEGIN DECLARE @result varchar(7) Select @result =( CASE when [Password] = HASHBYTES('SHA2_512', @v1) THEN 'Valid' ELSE 'Invalid' END ) from Users_detail where [Password] = HASHBYTES('SHA2_512', @v1) RETURN @result END GO SELECT [dbo].[Password_Check] ('Sanya') |
Some restrictions
We should review some gray areas before uses it.
First, we have to take care of the collation; if the collation is different, the output will be different.
Second, the column definition, if we used same data type but the length is different, then there should be the same result. To elaborate in depth, review below example of VARCHAR(50) and VARCHAR(100), we can test the output:
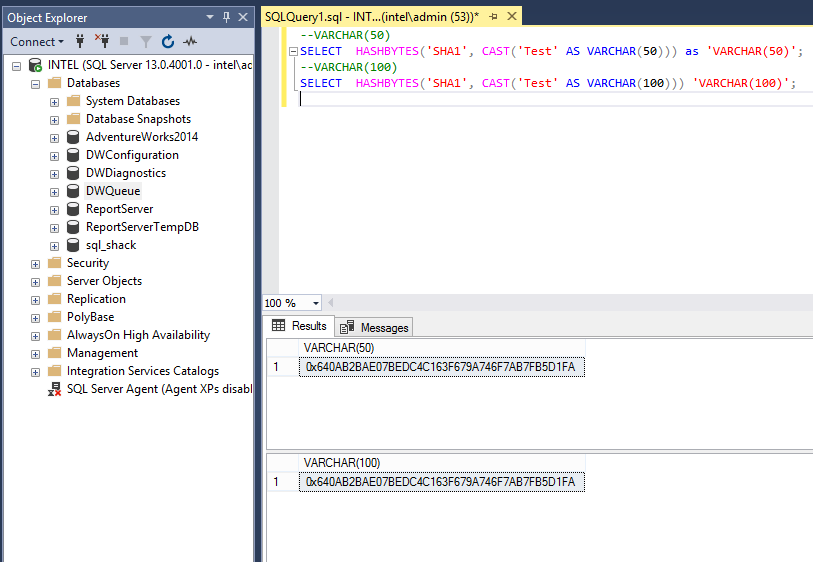
Both SELECT statements return the similar hashes value such as below:
0x640AB2BAE07BEDC4C163F679A746F7AB7FB5D1FA
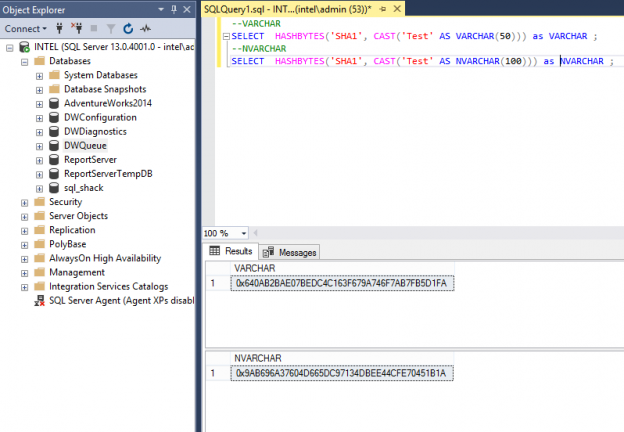
However, although, it has a similar data type, one should be aware that VARCHAR and NVARCHAR will not produce the same HashBytes value, even with the same string. To illustrate, review the following select statements.
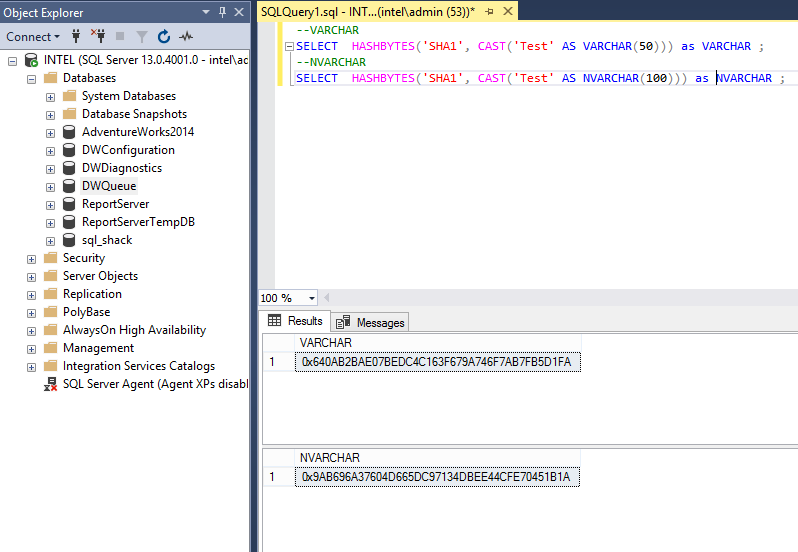
It can be noted that collations are only reviewed when we compare values between two files. The reason why the n[var]char produces a different result because it’s two bytes per character whilst the[var]char is a single byte per character.
For further understating, HashBytes, as the name implies, hashes a set of bytes, and so the two inputs return different results.
Conclusion
After reviewing all the points elaborated above it can be said that, there should be another hash for the similar values by using different algorithms.
Furthermore, it can be easily seen if something has changed while comparing the same string to itself if hashes algorithm is different than it is the exception. Especially, I prefer to use it for password protection, so, one can hash a password in the database table and then have the user enter their own version, hash it, and compare the results. In this way, the system end (front end) never knows the value. Just make sure to double check you have used same the same algorithm

In his downtime, he enjoys spending time with his family, especially with his wife. On the top of that, he loves to do wondering and exploring different places.
Say hi and catch him on LinkedIn
- SSIS Web Service Tasks - May 14, 2019
- Spatial SQL data types in SQL Server - July 11, 2018
- The HashBytes function in T-SQL - May 16, 2018