
This article explores the process of table partitioning in Azure SQL Database and explains how it differs from on-premises SQL Server.
Introduction
The table partitioning divides the large tables into multiple smaller logical tables. These smaller tables enable better data management and avoid the requirement of creating individual tables. These logical tables are unknown to end-users, and they can query the partitioned table like one logical table.
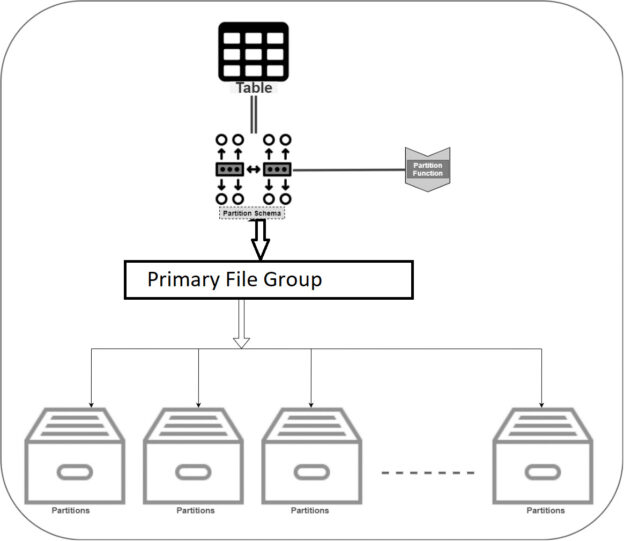
The following diagram depicts the table partitioning process in SQL Server. The main component of partitioning is as below:
- Partition function: The partitioning function defines the boundary for each partition.
- Partition Scheme: The partitioning scheme maps the table partitions to different filegroups.
-
Partition column: The partition function partitions data based on a column. You can use any data types except
ntext, text, image, xml,
varchar(max), nvarchar(max), or varbinary(max).
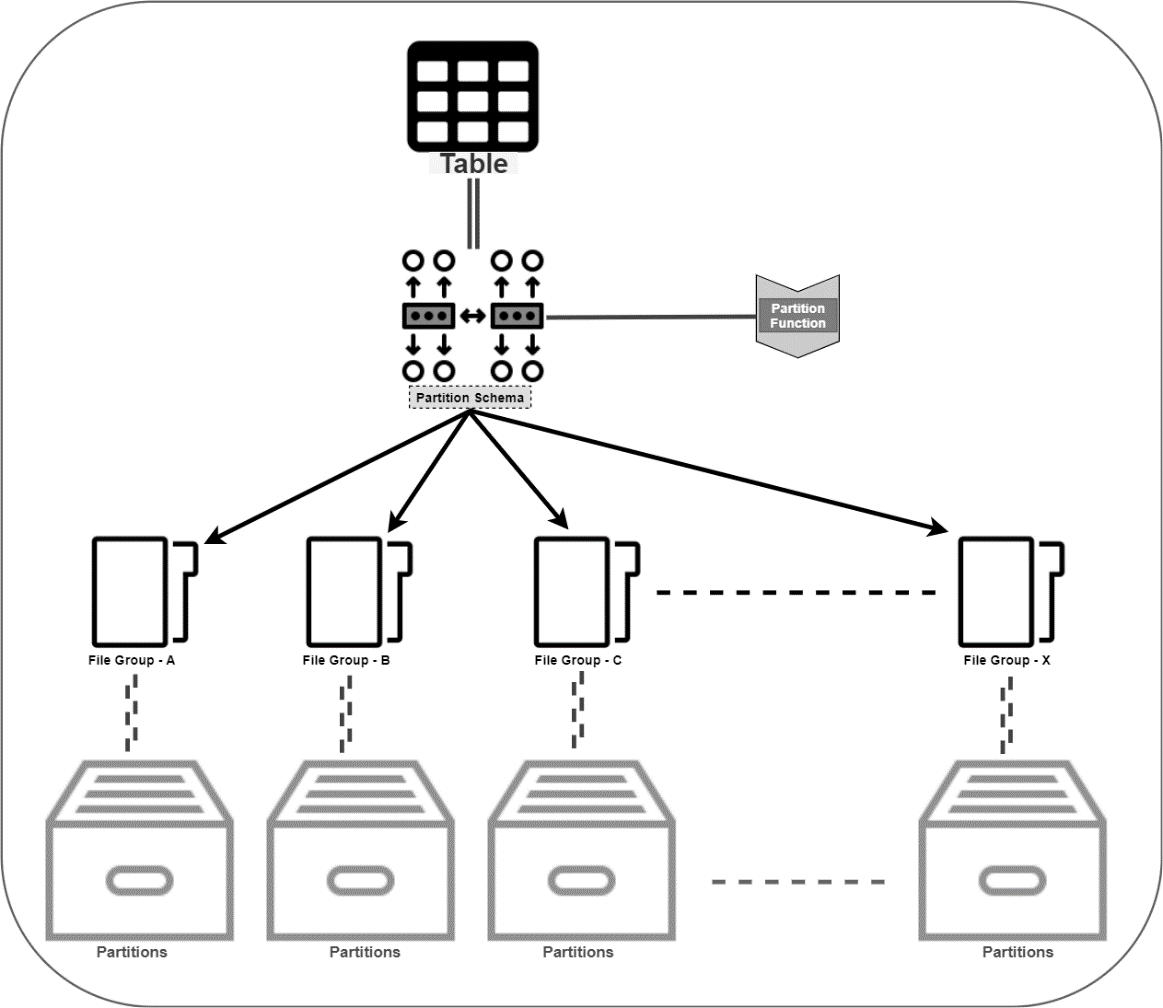
Usually, in the on-premises SQL Server database, we use the following approach for table partitioning.
- Create secondary filegroups and add data files into each filegroup.
- Define logical boundary for each partition using partition function.
- Create a partition scheme for mapping the partitions with filegroups.
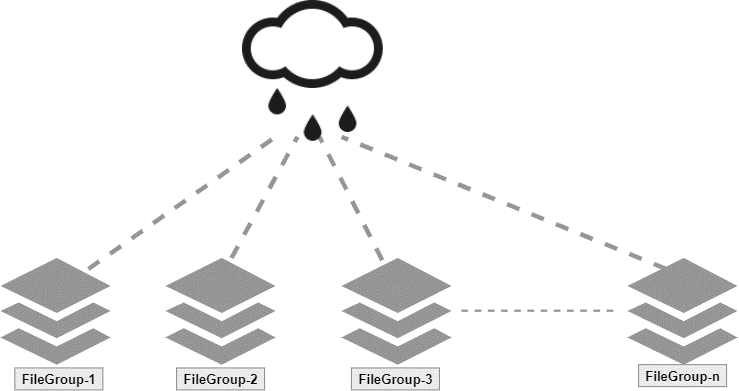
The idea behind different filegroups and data files is to optimize the storage. You can place the operational data
or partition data file on a faster disk while putting archive or less frequent usable data into the comparatively
slow disk to balance the storage cost without compromising the application performance.
Let’s explore how partitioning is different in the Azure SQL Database.
Azure SQL Database Table Partitioning
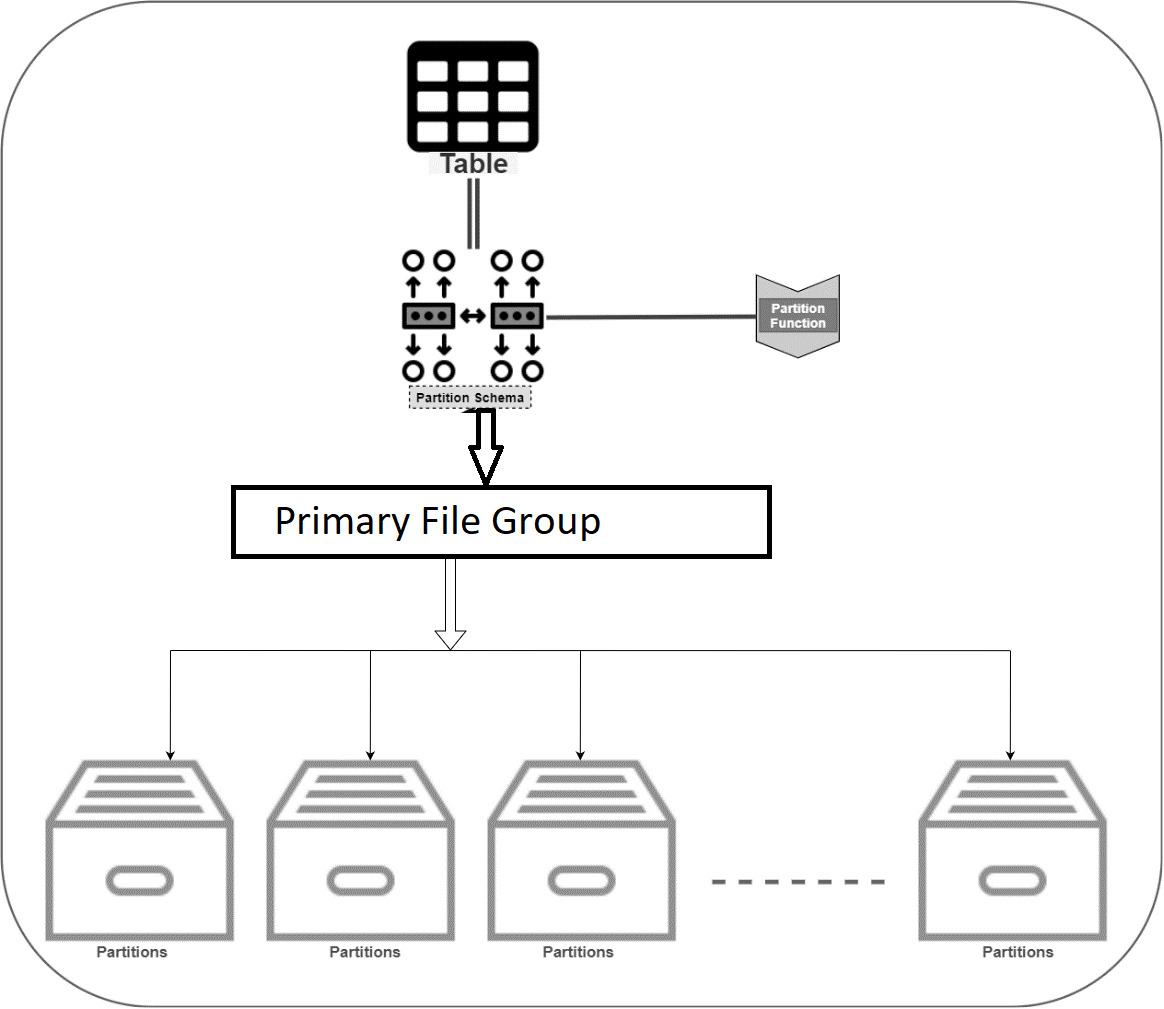
Azure SQL Database offers a PaaS solution for Microsoft SQL Server. Microsoft manages these databases; therefore, you have certain limitations in performing administrative activities. For example, you cannot add multiple data files and filegroups in Azure SQL DB.
As we saw earlier, we usually add multiple data files into separate drives for table partitioning. However, with Azure SQL DB, we cannot add multiple data files and define the partition scheme to use different filegroups.
Azure automatically optimized storage in Azure for all table partitions. Therefore, we can depict the Azure Table partition as below.
Requirements
You should create an Azure SQL database for this article demonstration. If you are not familiar with Azure SQL DB, please explore the Azure SQL category.
For this article, I have used [AzureSQLDemo] database having version 12.0.2000.8, as shown below.

Steps for partitioning SQL table in Azure SQL Database
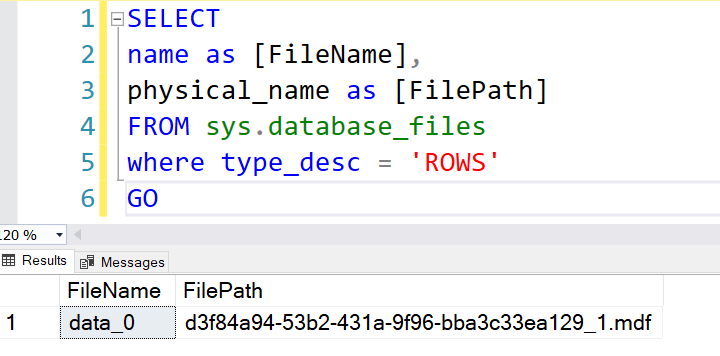
First, let’s verify the Azure DB data file and its location using the sys.database_files.
|
1 2 3 4 5 6 |
SELECT name as [FileName], physical_name as [FilePath] FROM sys.database_files where type_desc = 'ROWS' GO |
As shown, it has only one data file, and its path is encrypted because you do not get file system access in Azure SQL Database.
Let’s define a partition function and scheme before we create a partition table.
Partition function
The T-SQL script below creates a partition function [PF_Date] on the DateTime column, creating separate partitions for each month.
|
1 2 3 4 |
CREATE PARTITION FUNCTION [PF_Date] (datetime) AS RANGE RIGHT FOR VALUES ('20210201', '20210301','20210401', '20210501', '20210601', '20210701', '20210801', '20210901', '20211001', '20211101','20211201'); |
Verify the partition function using the sys.partition_functions.
|
1 2 |
SELECT * FROM sys.partition_functions WHERE name='PF_Date' GO |

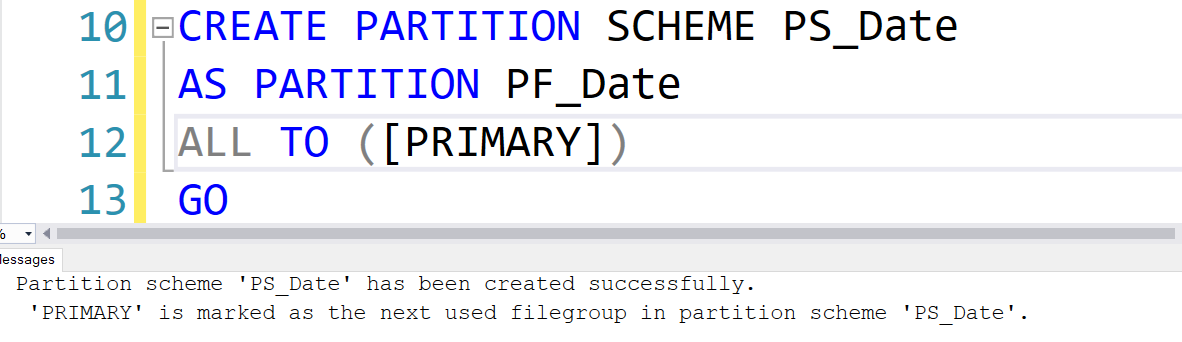
Partition scheme:
In the partition scheme, we use the argument – ALL TO PRIMARY, for mapping all partition boundaries to the primary filegroup.
|
1 2 3 4 |
CREATE PARTITION SCHEME PS_Date AS PARTITION PF_Date ALL TO ([PRIMARY]) GO |
The Partition scheme query returns the following output:
You can retrieve partition scheme information using the sys.partition_scheme.
|
1 2 |
SELECT * FROM sys.partition_schemes WHERE name='PS_Date' GO |

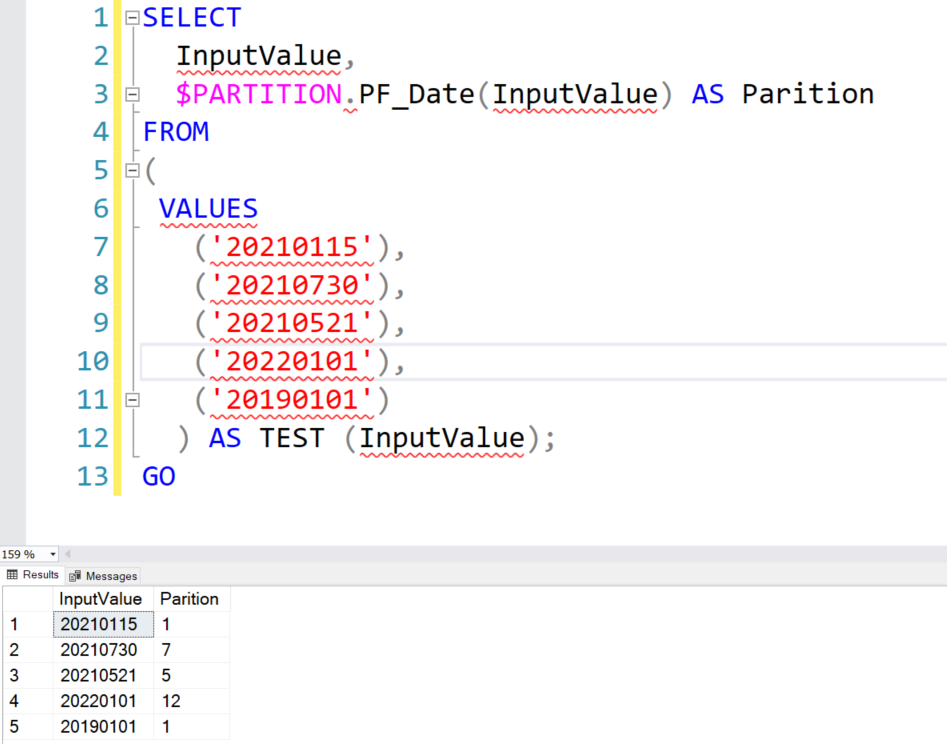
You can validate the partition function using the following query. It returns the partition number in which the data will be stored.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT InputValue, $PARTITION.PF_Date(InputValue) AS Parition FROM ( VALUES ('20210115'), ('20210730'), ('20210521'), ('20220101'), ('20190101') ) AS TEST (InputValue); GO |
Let’s understand the input value and their corresponding partition.
- Value ‘20210115’: As per partition function, it is stored in the partition one
- Value’ 20210730′ should go in partition five
- Value ‘20220101’ should go in the last partition twelve
- Value ‘20190101’ should go in the first partition
As we have verified that the partition function and scheme are working perfectly, let’s create a SQL table using these. The T-SQL syntax for a partitioned table is similar to a standard SQL table. However, we specify the partition scheme and column name as shown below.
Data insertion to the partition table is similar to a regular SQL table. However, internally, it splits data as defined boundaries in the PS function and PS scheme filegroup.
Note: We defined the primary key on the [TimeStamp] column that creates the clustered index on the partitioned column, and it is a pre-requisite for the partitioned column.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE DemoPartitionTable ( ID int, [Timestamp] datetime PRIMARY KEY, [Sampletext] varchar(100) ) ON PS_Date ([Timestamp]); GO INSERT INTO DemoPartitionTable (id, [TimeStamp],[SampleText]) SELECT '1', '20191231','Year 2019' UNION ALL SELECT '2', '20211231','Year 2021' UNION ALL SELECT '1', '20210111','Year 2021' UNION ALL SELECT '1', '20210630','Year 2021' UNION ALL SELECT '1', '20220101','Year 2022' |
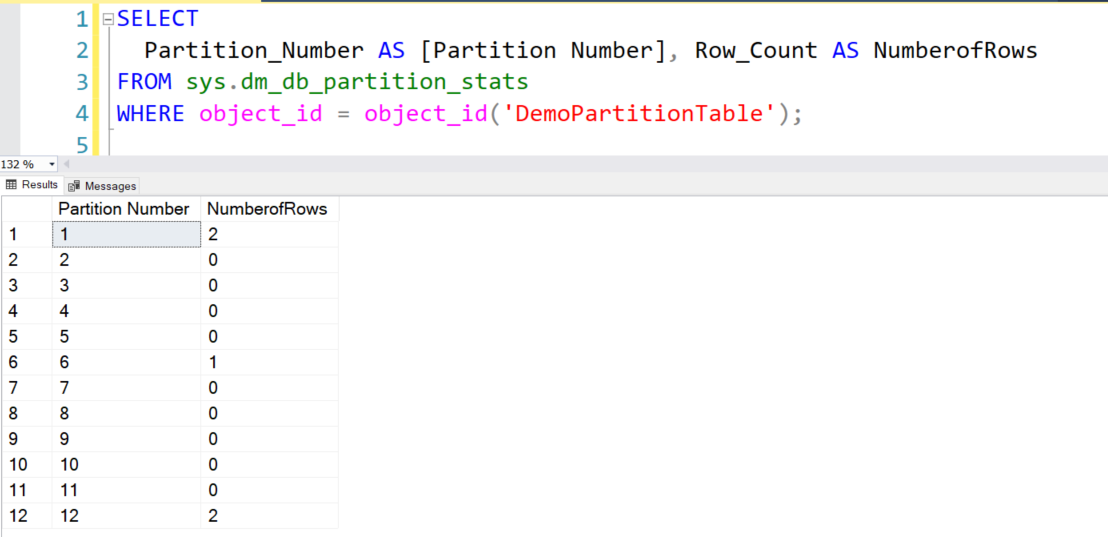
Let’s create partition number and number of rows in each partition for the Azure SQL Database table created earlier.
|
1 2 3 4 |
SELECT Partition_Number AS [Partition Number], Row_Count AS NumberofRows FROM sys.dm_db_partition_stats WHERE object_id = object_id('DemoPartitionTable'); |
You can follow the article How to automate Table Partitioning in SQL Server for automating the table partitioning in Azure SQL Database.
Reasons for Partitioning tables in Azure SQL Database
Partitioning can improve the performance of your SQL queries, especially for large tables. You can have the following benefits.
- You can use the partitioned tables to archive your historical data in the same database and table but in a separate partition. It can help you access historical data quickly while getting optimizing your current data.
- You can efficiently perform database maintenance tasks on the partitioned data. You can choose to perform maintenance on a specific partition instead of the complete table.
Conclusion
This article explored the process to partition an Azure SQL Database table. Azure DB contains all partitions in the primary filegroup. You can use partitioning for large tables where you do not access old data frequently or for archival data purposes. It can improve performance, reduce index maintenance overhead.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023