
In a software development life cycle, Code Review plays an integral role in improving the product quality. Having a Code Review Checklist is indispensable since it ensures that the best practices are followed and reviews are performed consistently. It is essential for developers to be aware of the coding guidelines while working on their code changes. Catching a bug early in the process is inexpensive and easier to resolve, than compared with a bug caught later in the game. Having all the common mistakes added to the checklist document is a great way to create awareness and ensure good code quality over a period of time.
Note: To learn why database management requires a systematic approach, please read Different Stakeholders, Different Views: Why Database Management Requires a Systematic Approach article.
In this article, we will look at a few of the SQL Server Code Review Guidelines which you can incorporate into your day to day database development work. A code review checklist can sometimes become pretty overwhelming, hence I have tried to mention 10 important guidelines which you can adhere to.
Verify that you have selected the most efficient data type
It is essential that you choose the best data type to store your data, which aligns with your business requirements. An improper selection of datatype leads to bad database design and can potentially result in performance issues. SQL Server provides a wide range of data types which you can choose from. You must ensure that you allocate the right amount of disk space for your data. Remember that the bigger the data type you use, the more storage it takes.
One great tip while selecting your data types is to be aware of the fixed data type (CHAR) vs dynamic one (VARCHAR). Let me explain it with a simple example –
CHAR(20) uses 20 characters for storing, irrespective of the fact that you actually have to store a value of less than 20 characters.
VARCHAR(20) is flexible and uses only the storage that is required. Hence if you have strings which are varying in size, it is recommended to use variable datatype, and in the process can save a lot of storage space.
Doing your due diligence while selecting your data types can save you from lot of rework and performance bottlenecks at later stages of your application development. I would highly recommend you to carefully review the data types for your database objects.
Verify that the working data set is minimal in size
Looking at your Business requirements, always try to figure out the data you want to fetch from the database. There is no need to extract additional information from the database and pass it back to the client application, which will not be used. Not only does it create more overhead and resource wastage, it also considerably slows down the speed.
Always try to avoid SELECT * operation and use explicit column list as far as possible.
Not only the columns, you should also try to have less rows in your working result set by adding filter criteria. A SELECT statement without a WHERE clause should be avoided, since it would lead to a bigger result set – causing table scan operations and hence leading to performance issues. Once you have narrowed down your data columns, make sure to use a WHERE clause and have additional search conditions to further reduce your result set size.
Looking at the below two SQL queries, it is advisable to use Query 2 over Query 1 –
|
1 2 3 4 5 6 7 8 |
SELECT * FROM [AdventureWorks2008].[HumanResources].[Employee] SELECT LoginID, JobTitle FROM [AdventureWorks2008].[HumanResources].[Employee] WHERE OrganizationLevel = 2 |
Verify that the naming conventions are clear and meaningful
To create a maintainable application, you need to make your code tell its own story. This can be easily achieved by giving understandable and meaningful names to your variables, tables, views, functions, stored procedures and other database objects. This helps in making the code self-explanatory and minimizes the need for explicit commenting.
From an application readability and maintenance perspective, comments are indispensable. It is always a good practice to add concise comments, when you are working on a complex Business functionality. This will help another developer to understand why the change was made. But make sure not to over comment – let the code tell its own story. If you are unit testing your stored procedures, then let the Unit tests do the talking. Unit Tests, unlike comments, can never be outdated – they will give you an immediate feedback when the functionality breaks/changes.
I would highly recommend to verify the comments and naming conventions during the review process. Business Requirements changes often, and so does the code. Hence it is essential that the associated comments are updated as well – because if the comments and code are not in sync with each other, it can cause lot of confusion and increase your technical debt over a period of time.
Verify the security of your SQL Server data
Data Security is a critical issue and we should always ensure that our data is protected. Generally we store sensitive information like personal phone number, email, bank account details, and credit card information in our database tables. From a security perspective, we need to make sure that the personally-identifiable information(PII) are secured from unauthorized access, either by encryption or implementing customizable masking logic.
While reviewing the SQL code, try to check for possible scenarios which are susceptible to SQL Injection
attack – a security vulnerability issue where malicious code in inserted into strings and passed to SQL server instance for execution.
If you dynamically build your SQL queries by concatenating strings and not use parameterized queries or stored procedures, you are susceptible to SQL Injection attack. Hence I would suggest you to review your ad hoc SQL queries, and evaluate if it can be converted into a stored procedure.
Verify that your application has good Resource Management
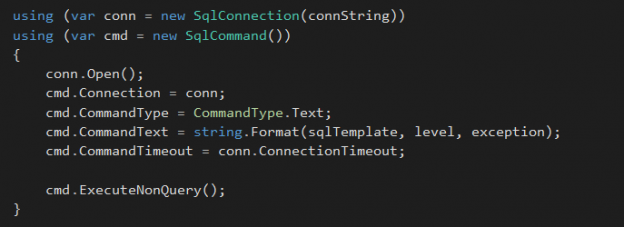
Lot of client applications use ADO.NET to connect to the database, execute commands and retrieve data. By using Data Provider for SQL Server, you will be able to open and close connections, fetch data and update them. Two important sections of a data provider are:
- SQLConnection object – used to establish a connection with the SQL Server database
- SQLCommand object – used to prepare a stored procedure or ad-hoc SQL statement that you want to execute on a database
Once you are done with executing commands and retrieving data, you need to make sure to release all the associated objects. In C#, you can utilize the USING block to timely close/release your connection and command objects. I would recommend to verify this during the review process, so that you can prohibit any memory leaks and performance issues in your application.
Same applies to your database objects. It is always a good practice to cleanup resources – drop your temporary tables, close and deallocate cursors – which will ensure that you are releasing the current data and associated locks.
Use stored procedures over ad hoc SQL for better Performance and Maintainability
There are multiple benefits of using stored procedures in your database development work. Stored procedures helps in caching the execution plans and reusing it. Even ad hoc queries can reuse the execution plan, but a slight change in parameter values will force the Optimizer to generate a new execution plan.
Also using stored procedures will reduce network traffic and latency, hence improving application performance. Over the network, what gets passed from the client application to the database server is something like –
EXEC [dbo].[sp_Get_Next_Order_Number]
Now compare that to passing a complete ad hoc query over the network and the additional overhead it will create!
With a Stored Procedure, Maintainability is easier since you have a single place to modify code, if requirement changes. Stored procedure encapsulates logic, hence the code can be changed centrally and reused, without affecting the various clients using it. This won’t be possible if you have ad hoc queries written throughout your application.
Be aware of deprecated features and make sure not to use them in any of your new code
With every release of a SQL Server version, Microsoft announces the ‘Backward Compatibility’ with prior versions. This is typically categorized into 4 primary categories — Deprecated, Discontinued, Breaking and Behavior changes. If a feature is listed as Deprecated, then it indicates that Microsoft is stating its disapproval in the usage of that feature in any future development work.
You can view all the deprecated features in SQL Server 2016 here. These features are scheduled to be removed in a future version of SQL Server and hence during the review process make sure that you are not using it in new application development work.
One such deprecated feature which lot of legacy applications still use are the data types NTEXT, TEXT and IMAGE. You should avoid using these data types in new development activities and also plan to modify applications that currently use them. Instead, you can use NVARCHAR() , VARCHAR() and VARBINARY().
Another deprecated syntax is the use of old-style join syntax –
|
1 2 3 4 5 6 |
select a.id, substring(b.name,1,40) as 'table name', count(colid) as 'count' from syscolumns a, sysobjects b where a.id = b.id group by a.id, b.name |
The usage of explicit JOIN syntax is recommended in all cases –
|
1 2 3 4 5 6 7 |
select a.id, substring(b.name,1,40) as 'table name', count(colid) as 'count' from syscolumns a inner join sysobjects b on a.id = b.id group by a.id, b.name |
Implement structured error handling to capture runtime errors
Error handling in your SQL code is critical. Sometimes you might need to inform the caller application if there is an issue and in other cases you might need to handle the error at your end and not throw an error back to the client application. In the first scenario, you can use a THROW statement with an error number. Whereas in the second scenario, you can use the TRY..CATCH construct.
I would suggest to leverage the TRY…CATCH construct in your code to prevent the application from throwing a runtime error. It is as simple as putting all your SQL code inside the TRY block – and then when an error occurs the control is automatically transferred to the CATCH block, where you have the authority to decide how to handle the error. Another point worth mentioning here is that inside your CATCH block, you will have access to additional error functions like ERROR_NUMBER, ERROR_LINE, ERROR_MESSAGE, ERROR_SEVERITY, ERROR_PROCEDURE and ERROR_STATE.
Find below a simple demonstration –
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BEGIN TRY SELECT 9 / 0; -- Divide by Zero END TRY BEGIN CATCH SELECT ERROR_LINE() AS 'Line' , ERROR_MESSAGE() AS 'Message' , ERROR_NUMBER() AS 'Number' , ERROR_SEVERITY() AS 'Severity' , ERROR_STATE() AS 'State'; END CATCH; |

Verify your Indexing strategy to ensure high performance
As you implement new Business requirements and write more TSQL code, it is imperative that you will need to create new indexes.
Indexing is generally the easiest way to improve the performance of your SQL Server queries. However if not designed right, it might hurt your application performance negatively as well. For instance, if you have an OLTP system, then you should review all the newly created indexes carefully to determine if they are really needed. Limiting the number of indexes is important as well, else it will slow down the Data Manipulation operations like INSERT/DELETE/UPDATE. Not to forget the additional disk space the indexes consume.
You can also think of using an automated tool like Database Tuning Advisor for your application in a Test Environment to review the indexing suggestions. Based on your analysis of the recommendations, you can create the necessary indexes. Do not blindly create all the indexes which the tool recommends.
One final thing which you should review after creating a new index is whether the index actually served its purpose. You can generate the execution plan of the query and quickly verify if the table scan/index scan operation is now replaced with an index seek operation.
Performance Optimization is a feature and needs to be continuously monitored and reviewed
One last thing which constitutes the crux of code review is Performance Optimization. You should be looking at the SQL queries and stored procedures written and the time they take to execute. Keep in mind that your data will grow over the period of time, so a query running fast currently does not indicate that it is optimal.
For medium or large sized queries, you should generate the execution plan and look out for expensive operators, table scans, index scans, key lookups, missing indexes and more. These are good indicators as to what you need to tune for boosting your database performance.
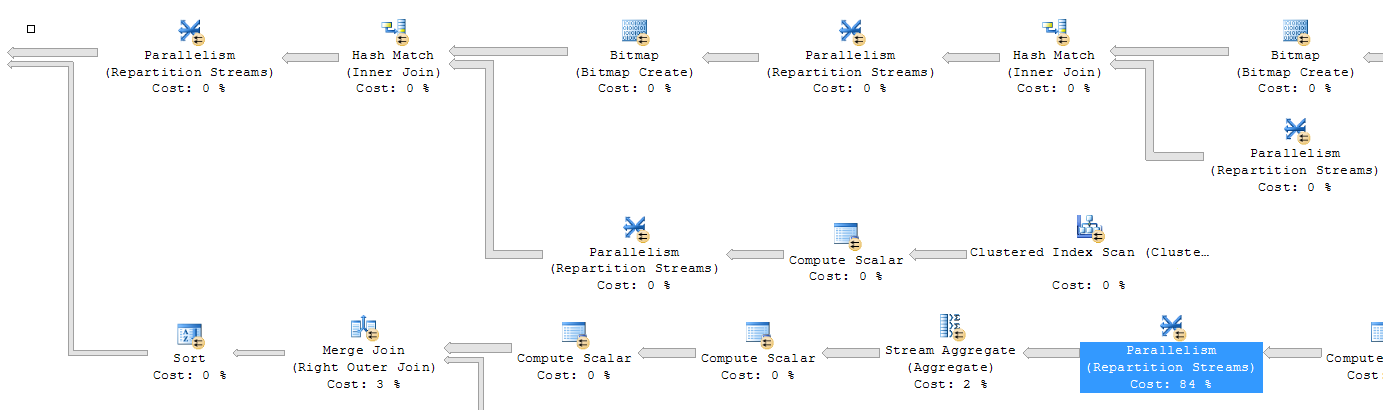
Looking at the execution plan extract above, we can easily see the Parallelism operator consuming the highest cost. As you can notice, each operator’s contribution to the overall query cost is displayed as a percentage value. Also the arrow width between operators is an indication of the number of rows affected by an operator. Generally to improve query performance, you can add a filter condition to your query to reduce the number of rows. Once done, this will reflect in the execution plan with a decreased arrow width.
Conclusion
To summarize, having a Code Review process in place has multiple benefits like consistent application design, identification of issues early in the process, awareness of best practices among team members and improvement of the overall code quality. If you do not have a Code Review checklist available, you can use this as a baseline document, and add to it based on your specific environment. If you already have a code review checklist with you, do let me know in the comments below few of the other guidelines which you follow.

Samir is a frequent speaker at conferences such as PASS Summit, IT/Dec Connections, CodeStock, SQL Saturdays and CodeCamps. He is the Co-Chapter Lead of the Steel City SQL Server UserGroup, Birmingham, AL. He is the author of www.dotnetvibes.com
View all posts by Samir Behara
- What’s new in SQL Server Management Studio 17.4; SQL Vulnerability assessment and more - December 26, 2017
- Review of SQL Cop for SQL unit testing - September 29, 2017
- Querying Microsoft SQL Server 2012/2014 – Preparing for Exam 70-461 - September 8, 2017