
This article explores Persist sampling rate feature for automatic SQL Server statistics update.
Introduction
DBA should always focus on the optimal database performance as it is directly related to the application’s performance. Therefore, the database administrators proactively configure, monitor, and maintain database configurations. Indexes help DBA to optimize queries based on the user data requirements.
SQL Server Statistics are helpful for cost optimization of various query execution plans. It is a collection of the distinct value that SQL Server collects using the sampling of table data. You can face high resource utilization (CPU, Memory, IO), inefficient query plan, inadequate operators such as Index scan, deadlocks, blocking. SQL Server uses statistics to choose the required index, data traverse mechanism and builds an optimal, cost-effective query execution plan.
SQL Server has multiple options for effective maintenance of statistics. This article explores statistics options with persisting sampling rates for Azure Database.
If you are new to SQL Server statistics, I would recommend you to go through the following articles.
- SQL Server Statistics and how to perform Update Statistics in SQL: This article gives information about statistics and different ways to update them
- SQL Server Update Statistics using database maintenance plans: This article guides you in creating database maintenance plans for updating the statistics
- Gathering SQL Server indexes statistics and usage information: This article guides you for index maintenance and identifying index usage stats
- SQL Server Statistics in Always On Availability Groups: You can get information about the statistics mechanism for SQL Server Always On Availability Groups databases
Note: In this article, I use SQL Server 2017 CU23 (Version 14.0.3381.3) and Azure SQL Database for demonstration


Automatic index maintenance SQL Server statistics
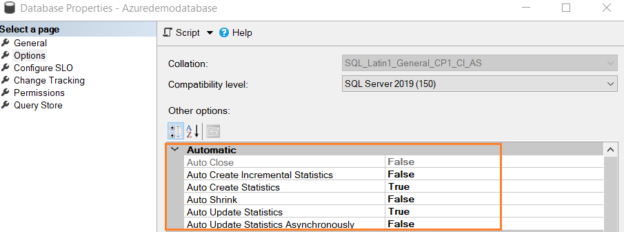
Each SQL Server database has the following properties for automatic statistics maintenance. It is applicable for all SQL Server versions, including Azure SQL Databases.
Connect to a SQL instance, select any database, and view its properties. The following figure shows SQL Server Statistics options available in Azure SQL Databases.
- AUTO_CREATE_STATISTICS
- AUTO_UPDATE_STATISTICS
- AUTO_UPDATE_STATISTICS_ASYNC
Let’s understand the Auto-create and Auto-update statistics in detail with practical demonstration.
AUTO_CREATE_STATISTICS
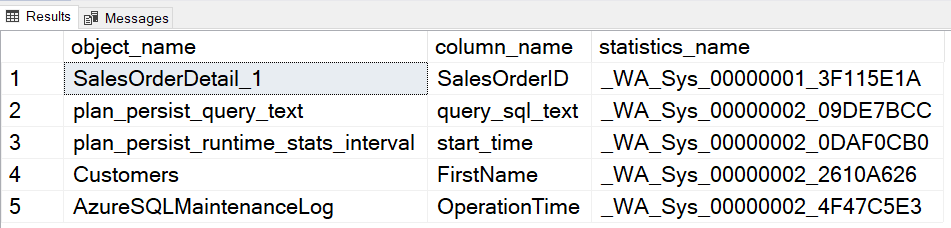
The AUTO_CREATE_STATISTICS creates statistics on the individual (single) columns in the query predicates. These statistics are created on the columns that do not have a histogram. SQL Server uses a prefix _WA for each auto-created statistic for the query predicate column.
You can run the following query to retrieve a list of auto-created SQL Server Statistics.
|
1 2 3 4 5 6 7 8 9 |
SET ROWCOUNT 5 SELECT OBJECT_NAME(s.object_id) AS object_name, COL_NAME(sc.object_id, sc.column_id) AS column_name, s.name AS statistics_name FROM sys.stats AS s INNER JOIN sys.stats_columns AS sc ON s.stats_id = sc.stats_id AND s.object_id = sc.object_id WHERE s.name like '_WA%' AND OBJECT_NAME(s.object_id) NOT LIKE 'sys%' ORDER BY s.name; |
AUTO_UPDATE_STATISTICS
The SQL Server Statistics get out of date due to frequent DML operations. The query optimizer updates the statistics automatically based on the predefined threshold. This threshold is based on a table cardinality (number of data rows).
The following table highlights the recompilation threshold starting from SQL Server 2016.
|
Table Type |
Table Cardinality(n) |
Number of modifications ( Recompilation threshold) |
|
Temporary |
n<6 |
6 |
|
Temporary |
6<=n<=500 |
500 |
|
Permanent |
n<=500 |
500 |
|
Temporary or Permanent |
n>500 |
MIN ( 500 + (0.20 * n), SQRT(1,000 * n) ) |
Example:
- Table record count: 5 million
-
Recompilation threshold =
- Value1: Min(500 + (0.20 * 5,00,000))= 100,500
- Value2: SQRT( 1000 * 5,00,000) = 70710
- Min( Value1, Value2) = 70710
As per the calculations, SQL Server updates statistics every 70,710 modifications. Automatic SQL Server Statistics update might not work efficiently for your workload. Therefore, usually, DBA add SQL Server statistics update as part of their regular database maintenance activities using database maintenance plans or T-SQL scripts. To update the statistics manually, you can run the UPDATE STATISTICS command. You can refer to Microsoft documentation for more details on it.
For the older versions SQL 2014 or lower, the calculation remains the same except for cardinality >500.
Formula: 500 + (0.20 * n)
As per this formula, SQL Server updates statistics for every 100,500 modifications.
Demonstration of SQL Server statistics updates
Let’s perform a quick demo for the statistics update. Execute the following script to create a sample table and inserts records into it.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE dbo.DemoTable( Id INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, [Name] VARCHAR(200) NULL ); Go CREATE NONCLUSTERED INDEX IX_DemoTable_Name ON dbo.DemoTable([Name]); Go INSERT INTO dbo.DemoTable(Name) Select a.name from sys.objects a CROSS join sys.objects b |
As shown below, it inserted 421201 rows in the [demotable].

Now, run the following script to check the statistics details:
- Total number of rows
- last Statistics update timestamp
- sampling percent
- Number of modification since last stats
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT stats.name AS StatisticsName, OBJECT_SCHEMA_NAME(stats.object_id) AS SchemaName, OBJECT_NAME(stats.object_id) AS TableName, [rows] AS [Rows], last_updated AS LastUpdated, rows_sampled as [NumberofSamplingrows], modification_counter, (rows_sampled * 100)/rows AS SamplePercent, persisted_sample_percent PersistedSamplePercent FROM sys.stats INNER JOIN sys.stats_columns sc ON stats.stats_id = sc.stats_id AND stats.object_id = sc.object_id INNER JOIN sys.all_columns ac ON ac.column_id = sc.column_id AND ac.object_id = sc.object_id CROSS APPLY sys.dm_db_stats_properties(stats.object_id, stats.stats_id) dsp WHERE OBJECT_NAME(stats.object_id)='DemoTable' |
The following figure shows the NULL in most of the columns. The reason behind this is that no stats update was performed. We did not update stats manually or modified the SQL Server rows to update stats based on the threshold.

Let’s run a select statement and view the statistics counter values.
|
1 |
Select * from DemoTable where [name]='Address' |
SQL Server automatically updated the stats for the index. It uses 49% sample percent and 20378 sampling rows.

Update Statistics with Full Scan
The query optimizer often does not create an optimized plan due to the low sampling percent, especially for a huge table. In these cases, you can update statistics manually using the UPDATE STATISTICS WITH FULL SCAN query. I have often seen query performance issues resolves if you have updated indexes statistics with the full scan.
|
1 |
UPDATE STATISTICS Demotable IX_DemoTable_Name WITH FULLSCAN |
With the full scan, the number of sampling rows equals the number of rows in the table. It is an optimized way for the query optimizer to use the latest statistics for a better decision. You can see value as 100 in the column – [SamplePercent].

The modification counter value is zero because we did not perform any value update for the [demotable]. Now, run the following query to perform an update to 10,000 rows.
|
1 2 |
Set rowcount 10000 Update DemoTable set[name]='A' |
The following figure shows the value of modification_counter value to 10,000. It equals to the number of rows updated using the UPDATE statement.

We perform a manual statistics update with the default settings. SQL Server uses the 49% sampling percent for the statistics.
|
1 |
UPDATE STATISTICS Demotable IX_DemoTable_Name |

Explore Update Statistics full Scan and Persist_Sample_Pecent
Like the previous case, if we update the records above the threshold calculation, SQL Server performs auto statistics update. Suppose we want SQL Server to update statistics with full scan once it reaches the threshold modification counter value. For this purpose, we need to focus on the last column, Persisted sample percentage.
We can force any statistics using the persisted sample percentage. The following query updates statistics [IX_DemoTable_Name] with full scan and enables persist_sample_percent counter.
|
1 2 |
UPDATE STATISTICS Demotable IX_DemoTable_Name WITH FULLSCAN, PERSIST_SAMPLE_PERCENT = ON; |
After running the above query with PERSIST_SAMPLE_PERCENT, the last column below the figure’s value shows a 100% sampling rate.
After running the above keyword, you will notice that the very last column of our very first query will now show you sample percent, which we have instructed to preserve (persist) for our statistics.

It ensures that SQL Server always uses the full scan for specified statistics and overrides the default behavior. It is applicable both for manual and automatics statistics updates.
Note: You can avoid query performance issues due to statistics with low sampling. The updating statistics with a full scan might take longer for a huge table. Therefore, you should test it on the non-prod environment and enable it only for required indexes.
- Note: The persist sampling feature is available from SQL Server 2017 CU1 and SQL Server 2016 SP1 CU4. The database must have a compatibility level of 130 or higher. You can refer to the Microsoft knowledge base article – KB4039284 for more details on it
To turn off the persist sampling for stats, you can run the update statistics to disable it.
|
1 2 |
UPDATE STATISTICS Demotable IX_DemoTable_Name WITH FULLSCAN, PERSIST_SAMPLE_PERCENT = OFF; |
- Note: This persisted sampling feature is not available at the database level. You can use it with the UPDATE STATISTICS command as described in this article
Conclusion
This article explored the enhancement feature – Persisted sampling for updating statistics with a fixed sampling and overriding the SQL Server default sampling mechanisms. You can use this feature for a table with frequent and high modification counter values. It can help resolve performance issues that you face with low sampling percent.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023