
In this article, we’ll walk-though two other important SQL aggregate function, SQL COUNT and COUNT_BIG. In the previous article of this series, we covered how to retrieve data, join tables, work with dates and times, use window functions, filter data, and much more.
This article addresses the following commonly asked questions:
- What are aggregate functions in SQL Server?
- What are the roles of aggregate functions in SQL?
- Why and how is the group by clause used with aggregate functions?
- How are aggregate functions used in a where clause?
Introduction
Aggregate functions are also a type of calculation; the calculations are defined on a set of values and return a single value. An aggregate calculation summarizes values from entire groups of rows. Except for the SQL COUNT function, aggregate functions ignore null values.
Aggregate functions are widely used with the GROUP BY clause in the SELECT statement. All aggregates are deterministic functions. In short, it returns the same value each time when it is operated with a specific set of the input values.
The basic SQL aggregated functions are:
SUM | Calculate totals of a given specified field |
AVG | Calculate averages of a specified field |
COUNT/COUNT_BIG | Count the number of records |
MIN | Get the minimum value of a specified field |
MAX | Get the maximum value of a specified field |
In this article, we will take a look at the SQL COUNT and SQL COUNT_BIG aggregate functions. Both functions operate in a similar way but it differs only in the return type. The aggregate function, COUNT, always returns an integer but whereas COUNT_BIG returns type is a bigint data type.
Now let’s take a look at aggregating data. By aggregating data, we are using a collection of built-in functions in SQL that summarize, or roll-up the provided data-set.
The basic aggregate functions that we’ve are MIN, MAX, AVG, SUM and COUNT. And there are some more analytical ones that will be discussed in another article. The listed aggregate functions are the most common ones and it is supported by nearly every RDBMS currently available in the market. They’re very simple and self-explanatory.
For the most part, we aggregate data because we want to summarize the results, converting raw data into useful, actionable information. Without aggregation, we’d potentially get millions of rows of data that we couldn’t ever possibly summarize in day-to-day lives.
Let us take a look at the SQL COUNT aggregate function in detail. The SQL COUNT function provides a count of rows. There are different ways to actually enhance that, and let’s say you wanted to see a count of distinct things, you can add some other logic to these to actually make them more advanced.
- To get a number of rows, use COUNT (*). In this way, it returns all the items that include NON –NULL, NULL and duplicate values
- In any other case such as COUNT(expression) evaluates for the specified expression and returns an aggregated count of items in the group for the number of non-null values in that group
- On using the distinct keyword in the SQL COUNT function ensure to evaluate for an expression and returns the unique combination of non-null values
Note: By default, the SQL COUNT function is deterministic. When it is used with OVER and ORDER BY clauses, it is non-deterministic in nature.
Demo
Let us see a few examples to understand the SQL COUNT function better.
How to use COUNT, COUNT (EXP) and COUNT (DISTINCT) in SQL
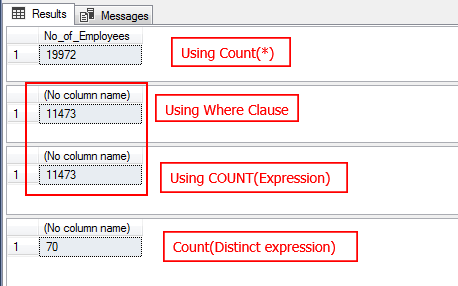
In the following example, if you’d like to know the number of employees, you can use the count (*) function in the SQL query. The COUNT(*) function counts all the rows from Person.Person table. When we use an expression in the COUNT(Middlename), this returns the number of rows with a MiddleName value that is not null. In this case, the COUNT doesn’t include null values in its total.
|
1 2 3 4 5 6 7 8 9 |
SELECT COUNT(*) No_of_Employees FROM Person.Person; SELECT COUNT(*) FROM Person.Person WHERE MiddleName IS NOT NULL; SELECT COUNT(MiddleName) FROM Person.Person; SELECT COUNT(DISTINCT Middlename) FROM Person.Person; |
In the output you can see that the total number of MiddleName is less than the total number of rows, then you know you have some null values in some of the rows.
COUNT(*) will include all Non-NULLs and NULLs but COUNT(columnName_or_Exp) won’t include NULLs. It means COUNT (any_non_null_value_column) will always give the same number as COUNT (*).
|
1 2 3 |
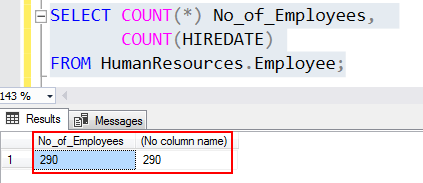
SELECT COUNT(*) No_of_Employees, COUNT(HIREDATE) FROM HumanResources.Employee; |
In this case, COUNT (HIREDATE) and COUNT (*) results are 290 and it is same.
How to use COUNT with other aggregates in SQL
In the following example, you can see the use of multiple columns. In this case, you count on orderDate and count_big on subtotal and also you see a mix of other aggregates such as the sum of the subtotal.
|
1 2 3 4 5 |
SELECT COUNT(DISTINCT YEAR(SOH.OrderDate)) NO_Of_Distinct_Years, COUNT_BIG(SOH.SubTotal) Total_No_Of_Records, SUM(SOH.SubTotal) AS TotalSales FROM sales.SalesOrderHeader SOH JOIN sales.SalesOrderDetail SOD ON SOH.SalesOrderId = SOD.SalesOrderId; |

How to use COUNT with GROUP BY clause
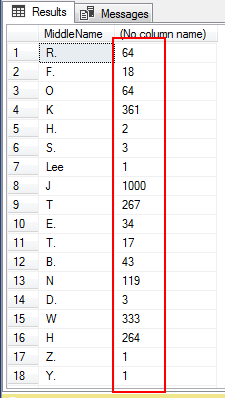
This example returns a number of the same occurrence of the MiddleName values of the Person.Person table.
|
1 2 3 4 5 |
SELECT COUNT(*), MiddleName FROM Person.Person GROUP BY MiddleName; |
The following output we can see the MiddleName is same for many employees.
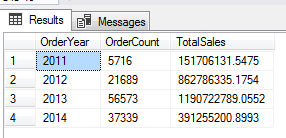
Let’s take another example. To summarize year wise order details based on OrderDate and Total Sales, run the following the SQL.
|
1 2 3 4 5 6 7 |
SELECT YEAR(SOH.OrderDate) OrderYear, COUNT_BIG(SOH.OrderDate) OrderCount, SUM(SOH.SubTotal) AS TotalSales FROM sales.SalesOrderHeader SOH JOIN sales.SalesOrderDetail SOD ON SOH.SalesOrderId = SOD.SalesOrderId GROUP BY YEAR(SOH.OrderDate) ORDER BY OrderYear; |
This is where we need to add a group by clause. We need to tell the SQL, how to actually group this aggregation together. I’ll add the group by, and then order date, the field that we’re going to actually group by.
How to use COUNT with over by clause
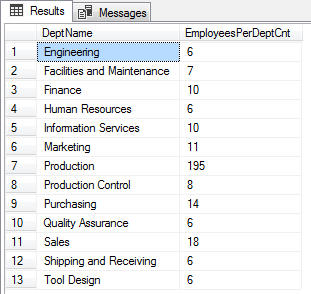
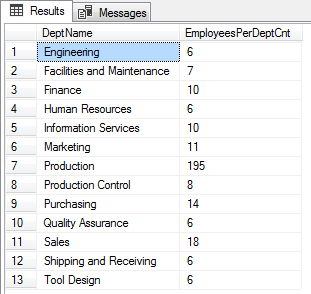
This example uses CTE and COUNT functions with the OVER clause to return those departments which have more than 5 employees at least.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
WITH CTE as ( SELECT distinct Name DeptName ,COUNT(ed.BusinessEntityID) OVER (PARTITION BY ed.DepartmentID) AS EmployeesPerDeptCnt FROM HumanResources.EmployeePayHistory ep JOIN HumanResources.EmployeeDepartmentHistory ed ON ep.BusinessEntityID = ed.BusinessEntityID JOIN HumanResources.Department AS d ON d.DepartmentID = ed.DepartmentID WHERE ed.EndDate IS NULL ) select * from CTE where EmployeesPerDeptCnt >5 |
Here is the output of the above SQL.
How to use COUNT with HAVING clause
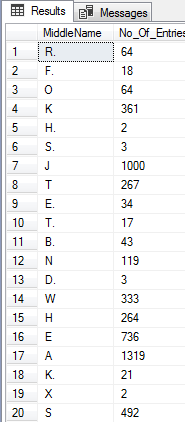
This example returns the duplicate entries of the field MiddleName from the Person.Person table. The SQL COUNT function is used in conjunction with GROUP BY and HAVING clause, this set the condition in the select statement for the specific group. In this case the condition is set on the MiddleName field
|
1 2 3 4 |
SELECT MiddleName, COUNT(*) No_Of_Entries FROM Person.Person GROUP BY MiddleName HAVING COUNT(*)>1. |
Now, the having clause takes an aggregation, and then applies a filter after it’s been aggregated. In this case, the count the number of MiddleName, aggregate it at the level that we’ve specified and only return results where that number is greater than one 1.
Here is the output that displays a duplicate MiddleName.
Summary
So far, we’ve discussed how to use the SQL COUNT and COUNT_BIG functions more efficiently in day-to-day business. In this article, we’ve reviewed several pointers that discuss how to: find missing data; duplicate rows; format data; summarize data and deal with suspicious data.
Hope you like this article. Feel free to comment below.

My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021