
Introduction
There are many situations in a DBA’s life that lead him or her to monitor space growth over time in SQL Server. In short, we often want to know which tables are growing the most and how much they grow.
For that reason, it’s preferable to develop a solution that will help us in that particular task and this is exactly what this article is about. The main components will include
- In following, we will first define to which extent we can go in table size monitoring and discuss some situations that should be part of the solution we want to build.
- Then, we will design the table that will host collected data and could be used in all the situations this solution is built for.
- We’ll also define a table that will contain the list of objects that the solution has to monitor. This will change the object size monitoring task to a simple INSERT statement in that table.
- Once those two tables are created, we will then consider the stored procedure that we will use to actually collect desired data and create a SQL Server Agent Job to automate the call to that procedure.
- Finally, we will generate test data for that table so that we can answer the question “which are the fastest growing tables?”
Considerations/Analysis
Which database objects?
We are interested in monitoring database object size, not database size itself. In order to do that, we should first list out which database objects can actually take space in our database’s datafiles.
The first object type that everybody has in mind is the table object as a table contains data and data takes space no matter the way it’s logically structured: as a heap or as a clustered index. We could get back space information by building a query using sys.allocation_units system view.
But that’s not all, as a table can be partitioned. A table is partitioned based on a key criterium that makes SQL Server put the row in one table partition instead of another. In many situations, this key criterium is date-based so that some partition keeps a static size while one particular partition becomes larger. If you are not used to table partitioning, we invite you to read SQL Server’s documentation about the subject. We won’t implement size monitoring for this kind of allocation unit, but let the door open for future developments.
Moreover, both table and table partitions are created using an enumeration of columns, each set of these columns is referred to as a record or a row. These columns are defined with a given data type (INT, BOOLEAN, VARCHAR (256), TEXT…). While some of these data types have fixed size, like INT or BOOLEAN, there are other data types that takes more or less space in the database based on its contents. For instance, it’s the case for VARCHAR data type. Based on this consideration, we could want to monitor space consumption for a particular column. This is totally achievable using SQL Server’s DATALENGTH built-in function, which returns the number of bytes used to represent any expression.
Furthermore, there is another kind of object that take space and is related to tables. It’s a table index and its extension: the partitioned table index. Both contain a subset of each records that are stored in a particular table. They could be considered too in our solution as they can be seen as an extension of a given table and the more indexes are built for a particular table, bigger is the actual amount of space consumed for that table. Nevertheless, we won’t cover this case in this article, but let the door open for further development in that way.
To sum up, we will define a solution that is able to monitor space usage for:
- Tables
- Table columns
We will let the door open for future development for:
- Table partitions
- Table partition columns
- Indexes
- Index partitions
We won’t consider at all database and filegroup space consumption monitoring.
Statistics collection
The following information is absolutely necessary for size collection:
- Number of rows (for allocation units, not columns)
- Total space consumption in database
- Actual space consumption in database (for columns, no difference is made between actual and total space consumptions)
About statistics collection for rows:
- We’ll allow user the capability to filter the rows that should be considered to compute statistics. In that case, for a fixed size data type, the most useful information should be the number of rows. This could be useful, for instance, when a table has a status column that takes different values and we would want to monitor how many items are in the “in wait” status over time.
Automation and dynamic behavior
Recording the size of an object just once is not really useful. Regularly taking snapshots as part of collection process is our goal. But, we won’t stay behind our computer and run it by ourselves, even at midnight on Sunday. We need to automate this collection and that’s where SQL Server Agent becomes very handy. We can define and schedule a SQL Server Agent Job to regularly do the task for us.
But, based on the object(s) we want to monitor, we might be willing to pick their space consumption once an hour while, for another one, this collection could be done once a day. A solution could be to run the same job every time and only take data of interest for the collection that occurs once in a day, but this would lead to waste of space and server resources consumption (23/24 records took in a day should just go to the trash).
So, we will need to schedule our SQL Server Agent Job as regularly as possible (for instance, every 5 minutes) and to create a table in which we would keep track of collection parameters to answer the questions of which object and how often to collect:
This will also bring another plus-value to the solution: the capability to dynamically start a new collection, change the collection recurrence settings or simply stop the collection with simple INSERT, UPDATE, DELETE queries.
Now we have everything on hand to start designing our solution…
Centralized management considerations
In the case we would want to have a central server from which we would fire the task and to which we would store results, our solution must have a reference to the name of the server instance from which data is extracted. The same goes for the parameter table discussed above.
However, this feature will be kept for further developments and won’t be developed here. It will however be kept in mind in current implementation…
Collection solution design
For consistency, we will create a database schema called SpaceSnap using following query:
|
1 2 3 4 |
USE <Your_DBA_database> ; CREATE SCHEMA [SpaceSnap] AUTHORIZATION [dbo] ; |
Every object that is specific to this solution will be stored in that schema.
Destination table design
Now, let’s talk about the table that will store collection results. We will call this table [SpaceSnap].[ObjectSpaceHist]. This table needs to keep track of the moment at which data has been inserted. For that reason, we will define a column called SnapDate of DATETIME2 data type.
Note
You could read in my article SQL Server DateTime data type considerations and limitations and understand why it’s preferable to use DATETIME2 data type instead of DATETIME.
There are other columns that make sense to create for that table:
- One to store the name of SQL Server instance from which data is extracted. We’ll call it ServerName
-
The information about the object we want to monitor. This will be materialized by following columns:
- DatabaseName will hold the name of the database in which the object is located
-
ObjectType will allow to know which type of object a record is about. Acceptable values for this record are:
- TABLE
- TABLE COLUMN
- TABLE PARTITION
- TABLE PARTITION COLUMN
- SchemaName and ObjectName together will store the actual fully qualified name of a database table (or index)
- PartitionName column could be used to store the name of a table partition
- ColumnName will store the name of a particular column wanted to be monitored
- RowFilter will store an expression that can be added in a WHERE clause
-
We need to store following collection statistics:
- RowsCount column will store the total number of rows based on object statistics
- TotalSizeMb will store the total size used on disk for that object, expressing in megabytes
- UsedSizeMb will store the actual size used by the object. The ratio between this column and TotalSizeMb could help in the investigation of a data fragmentation.
- Finally, we need to refer to ensure uniqueness of each record. To do so, we’ll add a column called ObjectUniqueId that is computed based on object information listed above. To keep space consumption as small as possible, this value will use HASHBYTES built-in function and SHA-1 algorithm.
Putting everything together, this gives following T-SQL creation statement for [SpaceSnap].[ObjectSpaceHist] table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
CREATE TABLE [SpaceSnap].[ObjectSpaceHist] ( SnapDate DATETIME2 NOT NULL, ServerName VARCHAR(512) NOT NULL, DatabaseName VARCHAR(256) NOT NULL, ObjectType VARCHAR(32) NOT NULL, SchemaName VARCHAR(256) NOT NULL, ObjectName VARCHAR(256) NOT NULL, PartitionName VARCHAR(256) NULL, ColumnName VARCHAR(256) NULL, RowFilter VARCHAR(4000) NULL, RowsCount BIGINT NULL, TotalSizeMb decimal(36, 2) NOT NULL, UsedSizeMb decimal(36, 2) NOT NULL, ObjectUniqueId AS CAST( HASHBYTES( 'SHA1', ServerName + DatabaseName + ObjectType + SchemaName + ObjectName + ISNULL(PartitionName,'') + ISNULL(ColumnName,'') + ISNULL(RowFilter,'') ) AS VARBINARY(20) ) PERSISTED NOT NULL ) ; |
We can also define its primary key:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
ALTER TABLE [SpaceSnap].[ObjectSpaceHist] ADD CONSTRAINT [DF_ObjectSpaceHist_PartitionName] DEFAULT ('') FOR [PartitionName] ; ALTER TABLE [SpaceSnap].[ObjectSpaceHist] ADD CONSTRAINT [DF_ObjectSpaceHist_ColumnName] DEFAULT ('') FOR [ColumnName] ; ALTER TABLE [SpaceSnap].[ObjectSpaceHist] ADD CONSTRAINT [DF_ObjectSpaceHist_SnapDate] DEFAULT (SYSDATETIME()) FOR [SnapDate] ; GO |
The script to create this table is called « Table.SpaceSnap.ObjectSpaceHist.sql » and can be found at the end of this article.
Parameter table design
Now, let’s talk a little bit about the table which will contain the list of objects we want to monitor. We will call it [SpaceSnap].[MonitoredObjects].
We will design this table so that it can be used by other collection processes related to space monitoring by just adding a BIT column telling the process to whether consider this object or not and maybe process dependent columns. This solution will follow the same principle and MonitoredObjects table will be created with a SnapSpace Boolean column.
This table will obviously use same column names as [SpaceSnap].[ObjectSpaceHist] table for representing the information about the object we want to monitor. It will also use the HASHBYTES built-in function to uniquely identify a record in that table and build an index on this.
Moreover, we need parameters to tell our collection process when it ran for the last time and when it should run again. To do so, this table will have following columns too:
- LastSnapDateStamp – will contain the last time collection process considered the object
- SnapIntervalUnit and SnapIntrvalValue – will tell that it should consider this object with SnapIntrvalValue amount of SnapIntervalUnit. For instance, 5 would be a candidate for SnapIntrvalValue and ‘HOUR’ for SnapIntervalUnit.
We could eventually add two columns for fast check of aggregate values on how much data space and how many rows are created in a simple day on average. These columns would bear following names respectively AvgDailySpaceMb and AvgDailyRowsCount.
Here is corresponding T-SQL creation statement for our [SpaceSnap].[MonitoredObjects] table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
CREATE TABLE [SpaceSnap].[MonitoredObjects] ( ServerName VARCHAR(512) NOT NULL, DatabaseName VARCHAR(256) NOT NULL, ObjectType VARCHAR(256) NOT NULL, SchemaName VARCHAR(256) NOT NULL, ObjectName VARCHAR(256) NOT NULL, PartitionName VARCHAR(256) NULL, ColumnName VARCHAR(256) NULL, SnapRowFilter VARCHAR(4000) NULL, SnapIntervalUnit VARCHAR(64), SnapIntrvalValue SMALLINT, LastSnapDateStamp DATETIME2, AvgDailySpaceMb decimal(36, 2), AvgDailyRowsCount BIGINT, SnapSpace BIT NOT NULL, isActive BIT NOT NULL, ObjectUniqueId AS CAST( HASHBYTES( 'SHA1', ServerName + DatabaseName + ObjectType + SchemaName + ObjectName + ISNULL(PartitionName,'') + ISNULL(ColumnName,'') + ISNULL(SnapRowFilter,'') ) AS VARBINARY(20) ) PERSISTED NOT NULL ) |
Full creation script is can be found in the Downloads section of this article. It is called Table.SpaceSnap.MonitoredObjects.
Collection process design
Collection stored procedure interface
Now that the foundations have been laid, it’s time to build our collection process. This will be materialized by the creation of a stored procedure. This procedure will be called [SpaceSnap].[CaptureObjectUsage] and will do the job, no matter the situation that needs to be handled.
So, this procedure will have a set of common parameters like those we’ve seen in table definitions:
- @DatabaseName
- @ObjectType
- @ObjectSchemaName
- @ObjectName
- @PartitionName
- @ColumnName
To allow dynamic behavior, we’ll also add parameters that will tell stored procedure where it should store results of its collection. For that reason, we’ll add following parameters to its signature:
- @DestinationDatabaseName
- @DestinationSchemaName
- @DestinationTableName
For testing purpose (and maybe also for further developments to a centralized collection solution), we will let user the capability to get back collection results instead of let these results go to a table. This will be done using a boolean parameter called @ReturnCollectionResults.
In fact, the process defined in this stored procedure will be a little more complex than just « read from an object list table and proceed ». Actually, we’ll define a parameter to this procedure that will influence the collection. We’ll call this parameter @CollectionMode. It could be set to one of following values:
-
DATABASE
In this mode, it will collect space consumption information for all tables in the specified database (Parameter @DatabaseName)
-
SCHEMA
In this mode, we will collect space consumption information for all tables in the given schema of specified database (Parameters @DatabaseName and @ObjectSchemaName).
-
OBJECT
In this mode, use all specified information about a particular object for which this stored procedure should collect details.
-
PARAMETERIZED
In this mode, only records from parameter table will be used. As this mode is especially designed for automation, the @ReturnCollectionResults parameter won’t be considered and a destination table is mandatory.
Because we design processes as dynamic as possible, we’ll also define three parameters corresponding to the name of database, schema and table from which our stored procedure should read to proceed. These parameters are called, respectively:
- @ParameterDatabaseName
- @ParameterSchemaName
- @ParameterTableName
This mode will recursively call [SpaceSnap].[CaptureObjectUsage] stored procedure. For that reason, we will also define a @_RecLevel to tell stored procedure the depth of recursivity in which we are and in case of debugging, display messages with padding.
Furthermore, we could be willing to run our procedure multiple times but keep the same collection time in order to reference the results of a batch (instead of a procedure run). For that reason, we’ll use a parameter called @_CollectionTime.
Finally, there is a @Debug parameter that, when sets to 1, is used to tell the stored procedure to be more talkative during its execution.
Complete signature for our stored procedure will then be:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
ALTER PROCEDURE [SpaceSnap].[CaptureObjectUsage] ( @CollectionMode VARCHAR(256), @DatabaseName VARCHAR(256) = NULL, @ObjectType VARCHAR(256) = 'TABLE', @ObjectSchemaName VARCHAR(256) = NULL, @ObjectName VARCHAR(256) = NULL, @PartitionName VARCHAR(256) = NULL, @ColumnName VARCHAR(256) = NULL, @RowFilter VARCHAR(4000) = NULL, @ParameterDatabaseName VARCHAR(256) = NULL, @ParameterSchemaName VARCHAR(256) = 'SpaceSnap', @ParameterTableName VARCHAR(256) = 'MonitoredObjects', @ReturnCollectionResults BIT = 0, @DestinationDatabaseName VARCHAR(256) = NULL, @DestinationSchemaName VARCHAR(256) = 'SpaceSnap', @DestinationTableName VARCHAR(256) = 'ObjectSpaceHist', @_RecLevel INT = 0, @_CollectionTime DATETIME2 = NULL, @Debug BIT = 0 ) |
Here is recap table that maps collection modes and object-related parameters.
In this table,
- Yes means the parameter is considered.
- No means it’s not considered.
- An underlined Yes means it’s considered as mandatory.
| @CollectionMode | @DatabaseName | @ObjectType | @ObjectSchemaName | @ObjectName | @PartitionName | @ColumnName | @RowFilter |
| DATABASE | Yes | Yes | No | No | No | No | No |
| SCHEMA | Yes | Yes | Yes | No | No | No | No |
| OBJECT | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| PARAMETERIZED | No | No | No | No | No | No | No |
Collection stored procedure steps
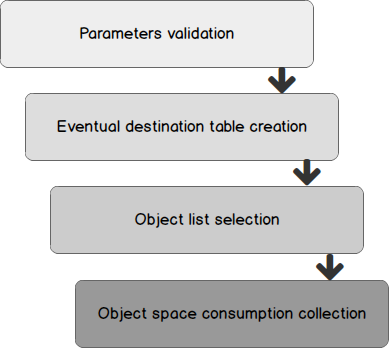
This stored procedure will be divided into a few steps that are listed below:
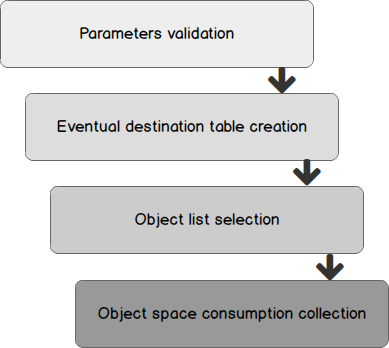
The interesting steps of this procedure are “Object List Selection” and “Object Space Consumption Collection”, so we will focus on them. There is a distinction to make between PARAMETERIZED collection mode and the others: the former will read from a table and call [SpaceSnap].[CaptureObjectSpaceUsage] as many times as there are rows in parameters table that need a collection to occur while the latter will only focus on the actual collection.
PARAMETERIZED collection mode implementation
This collection mode will be implemented as follows:
- Create a temporary table that will generate necessary commands for calling [SpaceSnap]. [CaptureObjectSpaceUsage], telling this procedure that it’s a recursive call.
- Insert the list of objects that need a collection into a temporary table so as the T-SQL statement to run our procedure recursively.
-
Loop until all records in that temporary table has been analyzed
- Call generated [SpaceSnap].[CaptureObjectSpaceUsage] using sp_executesql.
- Check for success and keep error for debug
- If successful, update parameters table so that we won’t consider these objects in another run if they do not have to be considered.
In order to only get records in parameter table for which a collection must run, we will use following criterium:
Either:
- it’s a new record in table, meaning that LastSnapDateStamp column value is NULL
or
- the difference between the value of this column and current time (based on the SnapInterValUnit column value) is above 95% of the value for SnapIntrValValue column. This 95% is empirical and could be different.
In plain T-SQL, this condition is:
|
1 2 3 4 5 6 7 8 9 10 11 |
p.LastSnapDateStamp IS NULL OR 1 = CASE WHEN upper(p.SnapInterValUnit) = 'YEAR' AND DATEDIFF(DAY,p.LastSnapDateStamp,SYSDATETIME())/365.0 >= .95 * p.SnapIntrValValue THEN 1 WHEN upper(p.SnapInterValUnit) = 'DAY' AND DATEDIFF(DAY,p.LastSnapDateStamp,SYSDATETIME()) >= .95 * p.SnapIntrValValue THEN 1 WHEN upper(p.SnapInterValUnit) = 'HOUR' AND DATEDIFF(MINUTE,p.LastSnapDateStamp,SYSDATETIME()) /60.0 >= .95 * p.SnapIntrValValue THEN 1 WHEN upper(p.SnapInterValUnit) = 'MINUTE' AND DATEDIFF(SECOND,p.LastSnapDateStamp,SYSDATETIME()) /60.0 >= .95 * p.SnapIntrValValue THEN 1 WHEN upper(p.SnapInterValUnit) = 'SECOND' AND DATEDIFF(SECOND,p.LastSnapDateStamp,SYSDATETIME()) >= .95 * p.SnapIntrValValue THEN 1 ELSE 0 END |
Implementing collection modes other than PARAMETERIZED
Actually, when collecting space consumption for table or table partition in another mode than PARAMETERIZED, these two steps are performed at the same time, in a single T-SQL query based on procedure’s parameters.
Why?
- In order to take advantage on SQL Server set-based processing capabilities, which makes collection run faster and less resources-consuming than if it were running in a procedural approach, and dynamic SQL.
- Because all the objects that are considered are all in the same database. For that reason, we can only consider existing objects on the fly.
This means that, for these kinds of collection, [SpaceSnap].[CaptureObjectUsage] stored procedure will dynamically build a query with following structure, based on the value set by caller to its parameters:
|
1 2 3 4 5 6 7 8 9 10 11 |
USE <value of @DatabaseName>; WITH ObjectsOfInterest AS ( <ObjectsSelection> ) INSERT INTO <DestinationTable> SELECT <DestinationTableColumnNames> FROM ObjectsOfInterest <JOIN to system Tables/views> |
The <ObjectSelection> will consider all the objects that are defined in sys.tables and add a WHERE clause corresponding to the mode user asked for:
- Nothing – DATABASE collection mode
- Equality on schema identifier – SCHEMA collection mode
- Equality on object identifier – OBJECT collection mode for tables.
- …
In contrast, space consumption collection for table or table partition columns has to be procedural as it needs to:
- Check the table exists
- Optionally check the partition exists
- Check the column exists
- Run a query against the table or partition using DATALENGTH built-in function as follows:
|
1 2 3 4 |
SELECT SUM(DATALENGTH(<ColumnName)) / 1024.0 / 1024.0 FROM <Object2Consider> |
- Run a query against the table or partition using COUNT_BIG built-in function in order to set RowsCount column.
- Eventually, these two statistics computations will use the value of @RowFilter parameter.
Collection automation using a SQL
We will simply create a SQL Server Agent called “[Monitoring] Capture Object Space (PARAMETERIZED mode)”.
This job will be scheduled every minute and will run the following statement:
|
1 2 3 4 5 6 |
EXEC [SpaceSnap].[CaptureObjectUsage] @CollectionMode = 'PARAMETERIZED', @Debug = 0 ; |
Here is the creation script for such a SQL Agent Job. There is just one thing to change: the database name in which it should run. (Look for “CHANGEME”).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
USE [msdb] GO /****** Object: Job [[Monitoring] Capture Object Space (PARAMETERIZED mode)] Script Date: 25-07-17 11:13:01 ******/ BEGIN TRANSACTION DECLARE @ReturnCode INT SELECT @ReturnCode = 0 /****** Object: JobCategory [Database Monitoring] Script Date: 25-07-17 11:13:02 ******/ IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'Database Monitoring' AND category_class=1) BEGIN EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'Database Monitoring' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback END DECLARE @jobId BINARY(16) select @jobId = job_id from msdb.dbo.sysjobs where (name = N'[Monitoring] Capture Object Space (PARAMETERIZED mode)') if (@jobId is NULL) BEGIN EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'[Monitoring] Capture Object Space (PARAMETERIZED mode)', @enabled=1, @notify_level_eventlog=2, @notify_level_email=2, @notify_level_netsend=0, @notify_level_page=0, @delete_level=0, @description=N'runs SpaceSnap.CaptureObjectUsage stored procedure in PARAMETERIZED mode.', @category_name=N'Database Monitoring', @owner_login_name=N'sa', @notify_email_operator_name=N'The DBA Team', @job_id = @jobId OUTPUT IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback END /****** Object: Step [Data Collection] Script Date: 25-07-17 11:13:02 ******/ IF NOT EXISTS (SELECT * FROM msdb.dbo.sysjobsteps WHERE job_id = @jobId and step_id = 1) EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'Data Collection', @step_id=1, @cmdexec_success_code=0, @on_success_action=1, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N'TSQL', @command=N'EXEC [SpaceSnap].[CaptureObjectUsage] @CollectionMode = ''PARAMETERIZED'', @Debug = 0 ;', @database_name=N'Your_DBA_Database', -- CHANGEME @flags=4 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @job_id=@jobId, @name=N'Db Object Space Monitoring - Schedule', @enabled=1, @freq_type=4, @freq_interval=1, @freq_subday_type=4, @freq_subday_interval=1, @freq_relative_interval=0, @freq_recurrence_factor=0, @active_start_date=20170725, @active_end_date=99991231, @active_start_time=110812, @active_end_time=235959, @schedule_uid=N'55b3061f-93ee-48cb-8763-84697ca84487' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback COMMIT TRANSACTION GOTO EndSave QuitWithRollback: IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION EndSave: GO |
Test cases
Every object created here will be put into a database schema called [Testing]. Here is a T-SQL statement that will create this schema.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE TABLE Testing.TableToMonitor ( RecordId INT IDENTITY(1,1), VarcharCol VARCHAR(4000), VarcharMaxCol VARCHAR(MAX), BooleanCol BIT, DateTime2Col DATETIME2 ) ; GO INSERT INTO Testing.TableToMonitor ( VarcharCol,VarcharMaxCol,BooleanCol,DateTime2Col ) SELECT CONVERT(VARCHAR(4000), (300000)*RAND()), CONVERT(VARCHAR(MAX), REPLICATE(RAND(CHECKSUM(NEWID())), CONVERT(BIGINT, 100000000* RAND()) ) ), CASE WHEN (10-1)*RAND() > 7 THEN 0 ELSE 1 END, DATEADD(DAY,CONVERT(INT,(365)*RAND()),SYSDATETIME()) ; GO 1000 |
If we want to collect its size using presented procedure, we just need to run following statement:
|
1 2 3 4 5 6 7 8 9 10 11 |
USE [Your_DBA_Database] ; EXEC [SpaceSnap].[CaptureObjectUsage] @CollectionMode = 'OBJECT', @ObjectType = 'TABLE', @DatabaseName = 'SpaceSnapTestsDb', @ObjectSchemaName = 'Testing', @ObjectName = 'TableToMonitor ', @Debug = 0 ; |
We can check the results of collection using following T-SQL query:
|
1 2 3 4 5 6 7 8 |
select * from [Your_DBA_Database].SpaceSnap.ObjectSpaceHist where DatabaseName = DB_NAME() AND SchemaName = 'Testing' AND ObjectName = 'TableToMonitor' ; |
Running this query will show you the row corresponding to this first execution of the stored procedure.

Column size collection
Keeping our Testing.TableToMonitor table, we will use following call to monitor size of VarcharMaxCol column.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE [Your_DBA_Database] ; EXEC [SpaceSnap].[CaptureObjectUsage] @CollectionMode = 'OBJECT', @ObjectType = 'TABLE COLUMN', @DatabaseName = 'SpaceSnapTestsDb', @ObjectSchemaName = 'Testing', @ObjectName = 'TableToMonitor', @ColumnName = 'VarcharMaxCol', @Debug = 1 ; |
If we run next query:
|
1 2 3 4 5 6 7 8 9 |
select * from SpaceSnap.ObjectSpaceHist where DatabaseName = DB_NAME() AND SchemaName = 'Testing' AND ObjectName = 'TableToMonitor' AND ColumnName = 'VarcharMaxCol' ; |
Then, we will get following results:

Different schedules in parameter table
For this step, we could let the SQL Server Agent Job we defined above run and do its job. But we recommend to disable it in order to get accurate results.
Test setup
Here is the script that will create records in parameter tables:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
USE [Your_DBA_Database] ; truncate table SpaceSnap.MonitoredObjects ; truncate table SpaceSnap.ObjectSpaceHist ; /* Following procedure will either update or insert a record in parameter table based on the value of its parameters */ exec [SpaceSnap].[MonitoredObjects_Upsert] @ServerName = @@SERVERNAME, @DatabaseName = 'SpaceSnapTestsDb', @ObjectType = 'TABLE', @SchemaName = 'Testing', @ObjectName = 'TableToMonitor', @PartitionName = NULL, @ColumnName = NULL, @SnapRowFilter = NULL, @SnapIntervalUnit = 'MINUTE', @SnapIntrvalValue = 10, @isActive = 1, @SnapSpace = 1 ; exec [SpaceSnap].[MonitoredObjects_Upsert] @ServerName = @@SERVERNAME, @DatabaseName = 'SpaceSnapTestsDb', @ObjectType = 'COLUMN', @SchemaName = 'Testing', @ObjectName = 'TableToMonitor', @PartitionName = NULL, @ColumnName = 'VarcharMaxCol', @SnapRowFilter = NULL, @SnapIntervalUnit = 'HOUR', @SnapIntrvalValue = 1, @isActive = 1, @SnapSpace = 1 ; |
And here are the contents of our parameter table after execution of the above script:

Running the test
We will simply call the [SpaceSnap].[CaptureObjectUsage] stored procedure in PARAMETERIZED mode as follows:
|
1 2 3 4 5 6 |
EXEC [SpaceSnap].[CaptureObjectUsage] @CollectionMode = 'PARAMETERIZED', @Debug = 1 ; |
If an error occurred, the stored procedure will let us know something went wrong:

If we look closely at the LogMsg contents, we’ll see that we did not set parameters appropriately.

In fact, it’s not COLUMN, but TABLE COLUMN we should have used.
This test leads us to add a check constraint to the MonitoredObjects table so that the INSERT statement will fail.
We will apply following corrective script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
exec [SpaceSnap].[MonitoredObjects_Delete] @ServerName = @@SERVERNAME, @DatabaseName = 'SpaceSnapTestsDb', @ObjectType = 'COLUMN', @SchemaName = 'Testing', @ObjectName = 'TableToMonitor', @PartitionName = NULL, @ColumnName = 'VarcharMaxCol' ; exec [SpaceSnap].[MonitoredObjects_Upsert] @ServerName = @@SERVERNAME, @DatabaseName = 'SpaceSnapTestsDb', @ObjectType = 'TABLE COLUMN', @SchemaName = 'Testing', @ObjectName = 'TableToMonitor', @PartitionName = NULL, @ColumnName = 'VarcharMaxCol', @SnapRowFilter = NULL, @SnapIntervalUnit = 'HOUR', @SnapIntrvalValue = 1, @isActive = 1, @SnapSpace = 1 ; |
As table size collection succeeded, there is already a record in ObjectSpaceHist table:

And the LastSnapDateStamp column has been updated for this object. We can check this by running following T-SQL query:
|
1 2 3 4 |
select LastSnapDateStamp,* FROM SpaceSnap.MonitoredObjects |
From which we will get back following results:

If we run once again the stored procedure and it succeeds, then no results set is returned.
|
1 2 3 4 5 6 |
EXEC [SpaceSnap].[CaptureObjectUsage] @CollectionMode = 'PARAMETERIZED', @Debug = 1 ; |
And we get a record in object space history corresponding to the column but no additional record for table because the collection is asked to be every 10 minutes and we ran previous T-SQL statement before the end of this interval:

If we wait for 10 minutes, then we’ll get a new record corresponding to size collection for TableToMonitor table but no record will be found for the VarcharMaxCol column as it’s parameterized for an hourly collection.
Building an object growth report
Let’s generate some fake data to the table so that we can build a query that will report object growth for table objects only. This object growth could be expressed either in percent or in megabytes.
To generate this fake data, we will use a query built on set-based principles: we will consider several data sets that we will combine using a join clause. These sets are:
- The set of days of monitoring. In our case, we will generate 365 days of data
- The set of hours in a day (a set with numbers from 0 to 23)
- The set of tables to be monitored with initialization data (its initial number of rows, its initial total and used size and an eventually used parameter for table growth). We will create 4 tables called Table1, Table2, Table3 and Table4.
Here is the query we will use:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
WITH TallyDays(D) AS ( SELECT TOP 365 ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) - 1 FROM sys.all_columns a CROSS JOIN sys.all_columns b ), TallyHours(H) AS ( SELECT TOP 24 ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) - 1 FROM sys.all_columns a CROSS JOIN sys.all_columns b ), TableObjects ( DatabaseName, ObjectType, SchemaName, ObjectName, InitialRowsCount, InitialTotalSize, InitialUsedSize, GrowthPerHourPct ) AS ( SELECT 'TestDb','TABLE','Testing','Table1',1293,7.88,7.83,2.1 UNION ALL SELECT 'TestDb','TABLE','Testing','Table2',928,7.88,7.4,3.5 UNION ALL SELECT 'TestDb','TABLE','Testing','Table3',2910,16,12.9,1.4 UNION ALL SELECT 'TestDb','TABLE','Testing','Table4',1,0.128,0.12,6 ) INSERT INTO SpaceSnap.ObjectSpaceHist ( SnapDate, ServerName, DatabaseName, ObjectType, SchemaName, ObjectName, PartitionName, ColumnName, RowFilter, RowsCount, TotalSizeMb, UsedSizeMb ) SELECT DATEADD(HOUR,H,DATEADD(DAY,D,DATEADD(YEAR,-1,GETDATE()))) as SnapDate, @@SERVERNAME as ServerName, DatabaseName, ObjectType, SchemaName, ObjectName, NULL as PartitionName, NULL as ColumnName, NULL as RowFilter, /* version 1: random growth */ --InitialRowsCount + (D * (FLOOR((RAND()*100)))) + (H * (FLOOR(RAND()*20))) as RowsCount, --InitialTotalSize + (D * (FLOOR((RAND()*10)))) + (H * (FLOOR(RAND()*20))) as TotalSizeMb, /* version 2: fixed growth */ FLOOR(InitialRowsCount * (1 + ((D *24 + H) * GrowthPerHourPct/100))) as RowsCount, InitialTotalSize * ( 1 + ((D *24 + H) * GrowthPerHourPct/100)) as TotalSizeMb, InitialUsedSize * ( 1 + ((D *24 + H) * GrowthPerHourPct/100)) as UsedSizeMb FROM TallyDays , TallyHours , TableObjects --where ObjectName = 'Table1' --order by D,H,ObjectName |
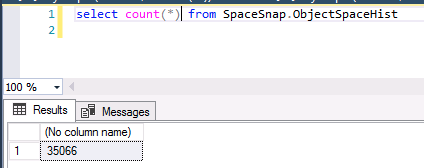
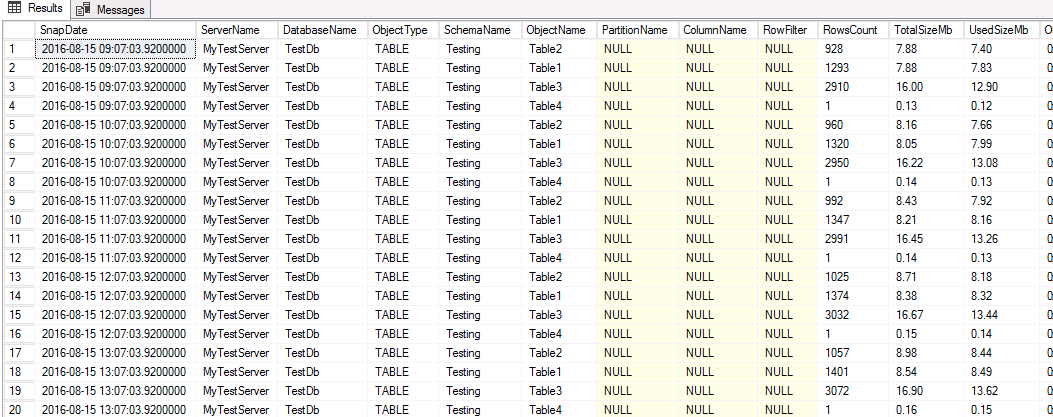
As you can see in the screen capture below, we have plenty rows in the ObjectSpaceHist table…
… and we can start building our reporting query. Let’s define what we want:
- It should list the top N (variable) tables, for example, that are growing the most
- And some statistics of growth – like a %
- User should define the starting date from which compute these statistics using a @SinceDate parameter.
We will use the same “set-based” approach as earlier to simplify readability of the query. We will first look in SpaceSnap.ObjectSpaceHist table for the most recent space snapshot starting @SinceDate. It’s an easy query that will be found in a CTE called FirstSnap:
|
1 2 3 4 5 6 7 8 9 |
SELECT ObjectUniqueId, min(SnapDate) FROM SpaceSnap.ObjectSpaceHist WHERE SnapDate >= @SinceDate group by ObjectUniqueId |
Then, we will do the same kind of query in order to get back the most recent snapshot date. Here is the query we define as the LatestSnap CTE:
|
1 2 3 4 5 6 7 8 9 |
SELECT ObjectUniqueId, max(SnapDate) FROM SpaceSnap.ObjectSpaceHist WHERE SnapDate >= @SinceDate group by ObjectUniqueId |
Now we know both values for the interval, we can get back collected statistics from our SpaceSnap.ObjectSpaceHist table. For that, we will also define two CTEs called resp. FirstSnapData and LastSnapData. These will be built as follows:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT lsi.ObjectUniqueId, lsi.SnapDate, osh.RowsCount, osh.TotalSizeMb FROM <SnapDateCTE> lsi INNER JOIN SpaceSnap.ObjectSpaceHist osh ON lsi.ObjectUniqueId = osh.ObjectUniqueId AND lsi.SnapDate = osh.SnapDate |
Then, we can build our results by combining everything. We end up with following T-SQL script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 |
DECLARE @Top4Select INT; DECLARE @SinceDate DATETIME2; -- PARAMETER ZONE SELECT @Top4Select = 3, @SinceDate = DATEADD(DAY,-30,SYSDATETIME()) ; -- END OF PARAMETER ZONE -- truncate date (nomore hour minute seconds references) SELECT @SinceDate = CONVERT(DATETIME2,cast(@SinceDate As Date)); WITH FirstSnap ( ObjectUniqueId, SnapDate ) AS ( SELECT ObjectUniqueId, min(SnapDate) FROM SpaceSnap.ObjectSpaceHist WHERE SnapDate >= @SinceDate group by ObjectUniqueId ), LatestSnap ( ObjectUniqueId, SnapDate ) AS ( SELECT ObjectUniqueId, max(SnapDate) FROM SpaceSnap.ObjectSpaceHist WHERE SnapDate >= @SinceDate group by ObjectUniqueId ), FirstSnapData ( ObjectUniqueId, SnapDate, RowsCount, TotalSizeMb ) AS ( SELECT fsi.ObjectUniqueId, fsi.SnapDate, osh.RowsCount, osh.TotalSizeMb FROM FirstSnap fsi INNER JOIN SpaceSnap.ObjectSpaceHist osh ON fsi.ObjectUniqueId = osh.ObjectUniqueId AND fsi.SnapDate = osh.SnapDate ), LastSnapData ( ObjectUniqueId, SnapDate, RowsCount, TotalSizeMb ) AS ( SELECT lsi.ObjectUniqueId, lsi.SnapDate, osh.RowsCount, osh.TotalSizeMb FROM LatestSnap lsi INNER JOIN SpaceSnap.ObjectSpaceHist osh ON lsi.ObjectUniqueId = osh.ObjectUniqueId AND lsi.SnapDate = osh.SnapDate ), SnapData ( ServerName, DatabaseName, ObjectType, SchemaName, ObjectName, PartitionName, ColumnName, RowFilter, FirstSnapDate, FirstSnapRowsCount, FirstSnapTotalSizeMb, LastSnapDate, LastSnapRowsCount, LastSnapTotalSizeMb, GrowthInRows, GrowthInMb, GrowthInPctSize, GrowthInPctRows ) AS ( SELECT osh.ServerName, osh.DatabaseName, osh.ObjectType, osh.SchemaName, osh.ObjectName, osh.PartitionName, osh.ColumnName, osh.RowFilter, fsi.SnapDate, fsi.RowsCount, fsi.TotalSizeMb, lsi.SnapDate, lsi.RowsCount, lsi.TotalSizeMb, lsi.RowsCount - fsi.RowsCount, lsi.TotalSizeMb - fsi.TotalSizeMb, CASE WHEN fsi.TotalSizeMb = 0 THEN NULL ELSE ((lsi.TotalSizeMb / fsi.TotalSizeMb)-1)*100 END, CASE WHEN fsi.RowsCount = 0 THEN NULL ELSE ((lsi.RowsCount / fsi.RowsCount) - 1)*100 END FROM SpaceSnap.ObjectSpaceHist osh INNER JOIN FirstSnapData fsi ON fsi.ObjectUniqueId = osh.ObjectUniqueId AND fsi.SnapDate = osh.SnapDate LEFT JOIN LastSnapData lsi ON lsi.ObjectUniqueId = osh.ObjectUniqueId ) SELECT TOP (@Top4Select) * FROM SnapData order by GrowthInMb desc ; |
And here is a sample results from that script:


Downloads
- Schema SpaceSnap
- Table SpaceSnap.MonitoredObjects
- Table SpaceSnap.ObjectSpaceHist
- Procedure SpaceSnap.CaptureObjectUsage
- CRUD procedures for SpaceSnap.MonitoredObjects
- All in one ZIP bundle

I'm one of the rare guys out there who started to work as a DBA immediately after his graduation. So, I work at the university hospital of Liege since 2011. Initially involved in Oracle Database administration (which are still under my charge), I had the opportunity to learn and manage SQL Server instances in 2013. Since 2013, I've learned a lot about SQL Server in administration and development.
I like the job of DBA because you need to have a general knowledge in every field of IT. That's the reason why I won't stop learning (and share) the products of my learnings.
View all posts by Jefferson Elias
- How to perform a performance test against a SQL Server instance - September 14, 2018
- Concurrency problems – theory and experimentation in SQL Server - July 24, 2018
- How to link two SQL Server instances with Kerberos - July 5, 2018