
When creating a hash index in a memory optimized table we need to define a value for the bucket count. Think twice before set a random value, you may pay the price later… On this article we will explain the effects of a bad defined bucket count and how to monitor it.
After two articles we’ve reached the last key point to monitor on In-memory OLTP environments. We are talking about the BUCKET! And no…this is not related to the ice bucket challenge 🙂
The purpose of monitor the bucket usage state is a performance matter and we will check it in detail later in this article. To bring some background, let’s review some points…
Indexes on memory optimized tables
Every memory-optimize table must have, at least, one index and a maximum of 8 indexes (this is a limit of SQL Server 2014). As the data in memory is not stored in some specific order, the indexes are “connecting” the data through pointers, building a linked list of rows.
With the introduction of the in-memory technology, two new types of index came on board:
- Memory-optimized RANGE indexes (Bw-tree indexes).
- Memory-optimized HASH indexes.
During this article, we will be focusing on Hash Indexes, where actually the bucket count should be provided and where the possible problem is present.
Hash Index
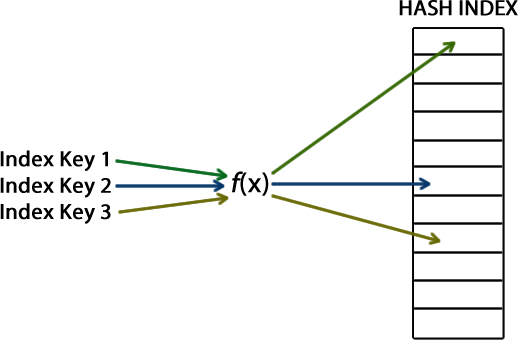
To describe a HASH Index in a simple sentence, we could say the following: “A hash index is a collection of buckets organized in an array “. And that’s pretty much this!
This kind of index is optimized for point-lookup operations, unlike the range indexes.
When creating a hash index, we need to provide an index key. This index key will be used by a hash function which is going to generate a hash value and be mapped to a corresponding bucket in the hash index. The hash function is deterministic, therefore, for a single input value it will return (output) the same hash value. In other words, the same index key is always mapped to the same bucket in the hash index.
The following picture shows the relation between all the mentioned components: a certain index key is used as input by a hash function f(x) which is going to generate a hash value and assign this to a bucket in the hash index.
We already introduced the word “bucket” in the previous explanation, and this is the point where we want to reach here. When creating a hash index, we need to provide a value for the BUCKET_COUNT as the following example – Note: remember that we need to create all the indexes when creating a table, so far this is the only option that we have…

The value provided as bucket count is critical and needs to be well planned, as neither a HIGH or a LOW value are acceptable. To determine a correct value for the bucket count is not an easy task… Microsoft says that on most of the cases the best is set a value “between 1 and 2 times the number of distinct values in the index key”, but it depends…Each case is a case!
For who is managing the SQL Server instance, monitor the current BUCKET UTILIZATION is essential, as we care about the server performance… As said before, the final user is our QoS indicator, if everything is performing well, our service is seen as good 🙂
Why the bucket count is so important?
To answer this question I usually make an analogy with a fisherman… Let’s pretend that a guy wake up and thinks “From now I’m going to leave the IT world and I want to be a fisherman! I’ll be rich selling fish!”.
As every newbie, he cast into the unknown and bought a thousand buckets in order to separate every species of fish in a single place. What an organized guy!!
On his first day, he was just learning and fished only a few different kinds of fish. Guess what happened? A lot of buckets were empty! But that’s ok… Was just the first day 🙂
However this overestimation cannot be ignored… He was having side-effects caused by the number of unused buckets. The logistic was not easy, as the place was packed of buckets… to reach a particular bucket, he needed to pass over a few of empty ones. This was making his business be slow.
The same happens with the hash index: a high number of buckets may slow down the operations, and we are also using memory space for nothing, as each bucket needs 8 bytes.
After some days, he realized that he was being very ambitious. He is just a greener… Why that much buckets? Maybe there aren’t even a thousand of distinguished species of fish on that place…
In the next day, he came with only 3 buckets, as usually he fishes only 3 different species of fish: Codfish, Salmon and Sardine (yes, this is a special place to fish :p ). How unlucky is this person…poor guy! Just that day he fished Codfish, Salmon, Sardine, Flounder and Herrings. Five different species! This day he even fished a tire…
What was the problem? He had only three buckets and 5 distinguished species of fish, so he had to mix two different species in the same bucket. When someone approached him to buy a certain fish, he needed to go to the bucket and start seeking for the correct fish. Not an efficient way to serve a customer, right?
Jumping again to the hash index, we have the same problem here. If we have less buckets than distinct values, we will have HASH COLISIONS. This means that for two, or more, key values we will have the same result. The same bucket will be reused for distinct keys and tis will generate performance problems.
So, the moral of the story is that we need to set a value big enough to cover all the possibilities but extremely excessive, in order to avoid performance problems.
How to Monitor?
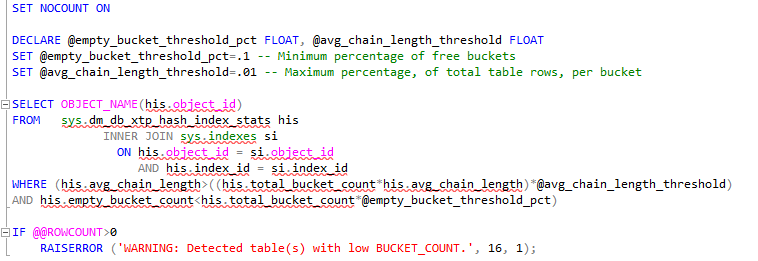
We can use t-sql to verify the state of the buckets, the DMV sys.dm_db_xtp_hash_index_stats is great to be used by this purpose:

With experience working in Portugal, Holland, Germany and United Kingdom, he's always available to learn and share his knowledge, in order to contribute to SQL Server community,
View all posts by Murilo Miranda
- Understanding backups on AlwaysOn Availability Groups – Part 2 - December 3, 2015
- Understanding backups on AlwaysOn Availability Groups – Part 1 - November 30, 2015
- AlwaysOn Availability Groups – Curiosities to make your job easier – Part 4 - October 13, 2015