
Introduced on SQL Server 2014, the new brand feature In-Memory OLTP a.k.a “Hekaton” is a Main-Memory Database Engine. Developed by Microsoft Research & Paul Larson (Database Research Group at MSFT) this feature have the ability to manage and held tables entirely In-Memory. In this Series we will pass through for all the new concepts and components that makes this New Engine the most excited acquisition of the new SQL Server Version (120).
Constructed to break myths in the DBMS (Database Management Systems) Hekaton (Hekatonkheires) is a mythological creature with “Hundred Hands and Fifty Heads” and the reason for Microsoft gives his name is because they want to achieve midway 10x-100x of performance, for clarification 10x faster, means that the engine must execute 90% fewer instructions, going further, 100x faster means that SQL Server needs to executes 99% fewer instructions which means a drastic code reduction.
The databases systems were designed assuming that the Main Memory (RAM) is expensive and data needs to reside on disk. But now this assumption is no longer valid. The scenario changed over these years, and now in the 21st century the hardware became cheap and the price of the memory is still decreasing. Today is possible to store an entirely database In-Memory, even if the size of the database is greater than 1TB (Terabyte), the reason underneath this, is the x64 architecture that allows a maximum memory of 8 TB in the Windows Server Operate Systems (SO). Traditional Disks are measured in Ms (Microseconds) when the Main-Memory (RAM) is measured in Ns (Nanoseconds), what makes the Main-Memory more attractive and fast for the data access layer perspective.
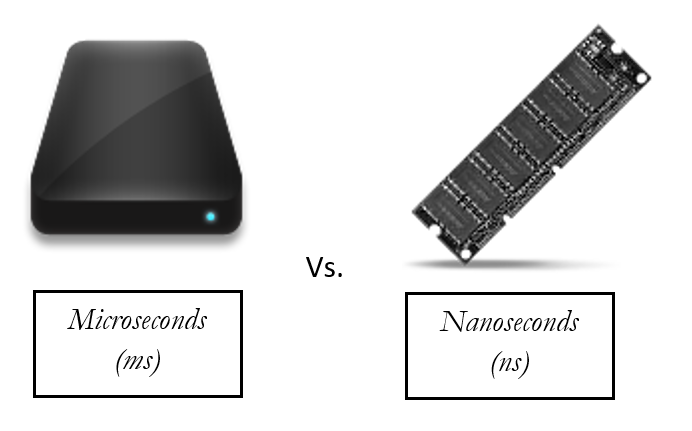
Figure 1. Disk vs. Memory
Like was mentioned before this is a new feature that was built-in the SQLOS (SQL Server Operate System) layer totally optimized to work with the tables entirely In-Memory. In this Series you will understand all the topics bellow and how they work making this the main pillars of this new technology that spent more than 4 year to be developed.
- Memory
- Optimized for Main-Memory (RAM)
- Hash & Range Index
- No Buffer Pool
- Stored on FileStream Technology
- Concurrency
- MVCC – Multi-Version Concurrency
- No Locks / Lock Manager / Spinlocks
- Compilation
- Compiled in C and Visual C
- Called By DDL’s
- More CPI – Cycles per Instruction in CPU
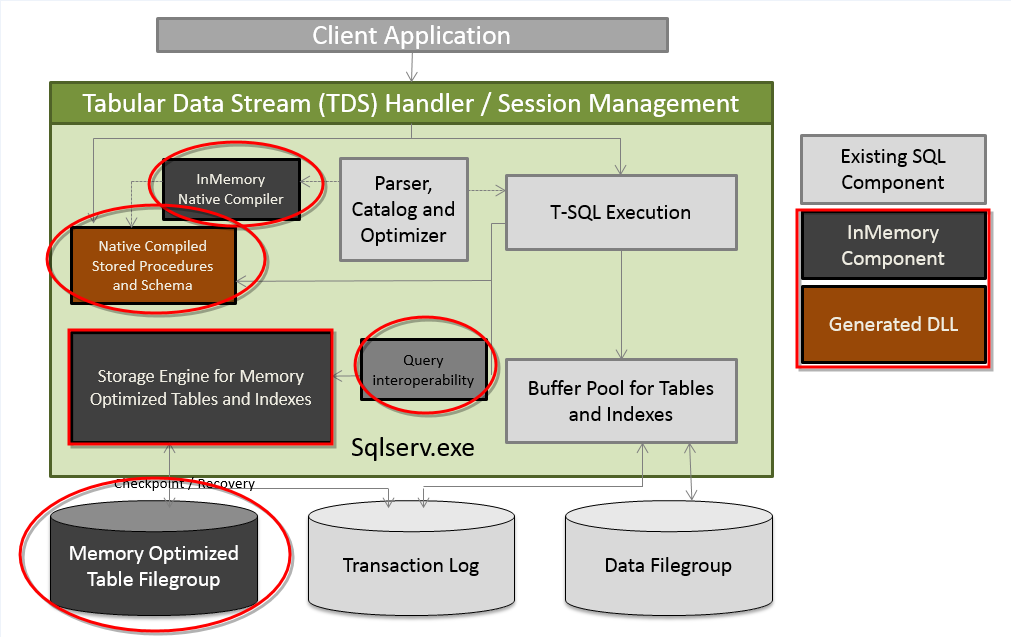
Figure 2. In-Memory Architecture Integrated with SQLOS (SQL Server Operate System)
The highlighted places are the components that were added in the engine and I will describe shortly how they work.
- Query Interoperability
- This component connects the Disk-Tables and In-Memory Tables. When SQL Server Engine receives the request with an inner join between this both table types, he’s the responsible to request the data from the Memory Optimized Filegroup and the Data Filegroup (.mdf), putting together all this pieces and returning the result set for the requestor.
- Storage Engine for Memory Optimized Tables and Indexes
- The storage structure for memory-optimized tables is different from disk-based tables, there are new key attributes that differs this two access inside of the engine.
- Hekaton Storage Engine
- Manages user data and indexes, providing transactional operations about the new hash and range indexes.
- Hekaton Compiler
- Responsible to compile the new Natively Stored Procedures to native code.
- Hekaton Runtime System
- Small component that integrates the SQL Server resources with the functionalities needed to In-Memory Tables and Natively Stored Procedure.
- Hekaton Storage Engine
- The storage structure for memory-optimized tables is different from disk-based tables, there are new key attributes that differs this two access inside of the engine.
- Memory Optimize Table File Group
- In-Memory table have two possible options, the SCHEMA (Non-Durable) and SCHEMA_AND_DATA (Durable). Using the SCHEMA option SQL Server doesn’t persist anything in disk, this way if server restarts, all the data is lost in this process just remaining the metadata of the table. Using the SCHEMA_AND_DATA, SQL Server needs to guarantee the ACID clause and for this he store the changes in the .ldf file and the data in the special Filegroup called “Memory Optimized”.
- The new stored procedure – “Natively Stored Procedure” is invoked by this compiler allowing the business logic faster than the “Interpreted Stored Procedure”. And the reason beneath is because, when codes of T-SQL are executed inside of any DBMS (Database Management Systems), they need to pass to an “Interpreter” phase that converts the T-SQL in machine code. Using the Native Compiled the code is already converted to a machine code and persisted in a .DDL file in the system, what makes Hekaton shines when pass for this Native Compiler.
- In-Memory Native Compiler
- Tables and Stored Procedures are compiled in .DDL and accessed using this module of the compiler.
|
1 2 3 4 5 |
SELECT name, description FROM sys.dm_os_loaded_modules WHERE description = 'XTP Native DLL' |
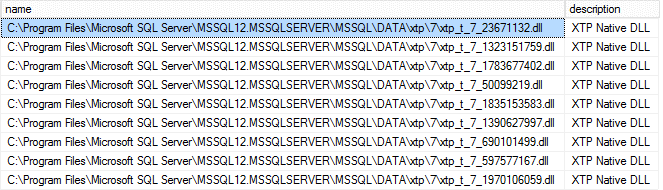
Figure 3. In-Memory Tables and Stored Procedures loaded into memory on the server
Database Creation
Creating memory-optimized tables needs to have at least one MEMORY_OPTIMIZED_DATA filegroup in the database. This special filegroup will store the Data & Delta files pairs responsible to maintain and recover the memory-optimized tables.
Creating Database Using T-SQL Syntax
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
USE master GO CREATE DATABASE [inmem_SQLShack] ON PRIMARY ( NAME = N'inmem_SQLShack', FILENAME = N'C:\BaseDados\mdf\inmem_SQLShack.mdf' , SIZE = 400MB , FILEGROWTH = 150MB ), FILEGROUP [inmem_objects] CONTAINS MEMORY_OPTIMIZED_DATA ( NAME = N'inmem_data', FILENAME = N'C:\BaseDados\mdf\inmem_objects' ) LOG ON ( NAME = N'inmem_SQLShack_log', FILENAME = N'C:\BaseDados\ldf\inmem_SQLShack_log.ldf' , SIZE = 150MB , FILEGROWTH = 25% ) GO |
Creating Database Using GUI
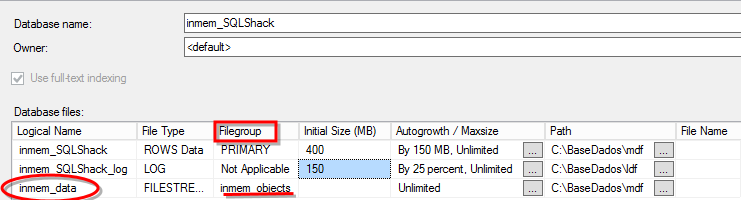
Figure 4. Creating In-Memory Database (IMDB). FileStream File Created Name – inmem_data
Figure 5. Creating Memory Optimized Data Filegroup – inmem_objects
Checkpoint Files – Data Files and Delta Files
The checkpoint operation consist in a background task that look to the previous transaction log that wasn’t been covered by the checkpoint process and convert this in a memory-optimized section. Once this process finished the checkpoint is completed logging this in the Data and Delta pair files.
- Data File – This file contains only insert versions or rows and each file cover a specific timestamp range zone.
- Delta File – Store the information about which versions has been deleted.
This files gave the possibility to break an obstacle in the database systems, all the data access becomes sequential. We will get into more details of this files and the Merge Operation in the next series posts. The files are stored in the MEMORY_OPTIMIZED_DATA that was created previously.
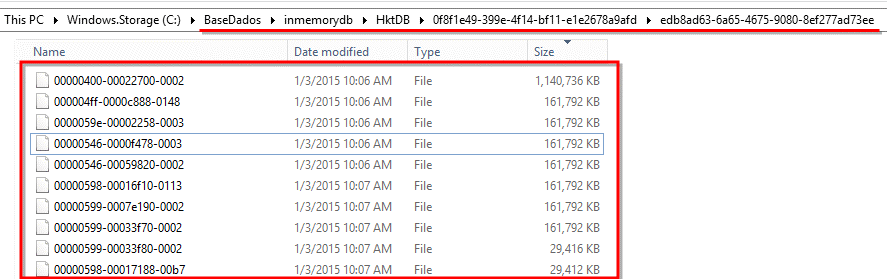
Figure 6. Checkpoint Files – Data & Delta Files
Conclusion
There are a few barriers and concepts that we need to understand, but implementing this new feature will change your scenario and vision for this new capability, and now that you have a glimpse of how this new feature can makes you go beyond in your scenario, follow this new series that will contain more than 11 articles and becomes a pro. We will dig all the necessary parts for you implement this feature and have gains never obtained before. See you next week.

Luan Moreno credits his ability to solve problems to thinking critically before acting. He values working with a team because he and his clients can benefit from various perspectives and collaboration, particularly when faced with difficult issues.
When Luan Moreno first became interested in technology, he didn’t have a mentor, so he made a commitment to teaching others in the community and sharing his knowledge through blogging, speaking engagements
View all posts by Luan Moreno
- In-Memory OLTP Series – Data migration guideline process on SQL Server 2016 - January 29, 2016
- In-Memory OLTP Series – Data migration guideline process on SQL Server 2014 - January 28, 2016
- In-Memory OLTP Series – Table Creation & Types - March 13, 2015