
In sequence of the first article of the In-Memory OLTP Series that explained the main pillars, database creation and a briefly overview of the checkpoint files, now we will take a look into the table creation and data types allowed in the In-Memory OLTP feature in SQL Server 2014.
Table Creation
Before start to create tables In-Memory is extremely important to understand some key points that will make difference in how you manage these tables in your environment. Remember that the memory-optimized tables resides entirely in memory and there is a limit of 256 GB of RAM.
Rows in the memory-optimized tables are versioned which means that each row can have multiple versions that is maintained in the same table structure, this new capability is called to “multi-version concurrency control (MVCC)”.
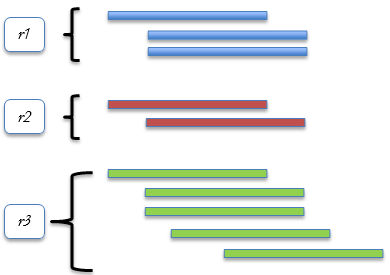
Figure 1. Multi-Version Concurrency Control (MVCC).
The table r1 has 3 versions, r2 has 2 versions & r3 has 5 versions. This versions make the in-memory table structure different than the disk-based tables that is not allowed to storage row version in the same structure of the data pages & extents.
Disk-Based Vs. In-Memory Table Structure
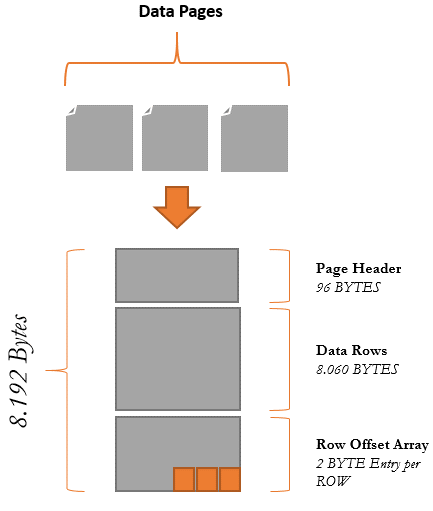
Figure 2. Disk-Based Table Structure.
Page Header
The page header occupies 96 BYTES and this piece is responsible to store the header of the data page.
Data Rows
The data rows occupies 8.060 BYTES and this area is responsible to store the data rows. The number of rows that will be stored in this place depends of the different data types that you have in that table, columns with fixed or non-fixed values will determine the space consumed in the part of the data page.
Row Offset Array
Rows that are added inside of the page has a 2-byte entry in this array. The row offset array have the function to indicate the logical order of the rows in a page that doesn’t means that the rows are ordered conform the physical stored in the disk.
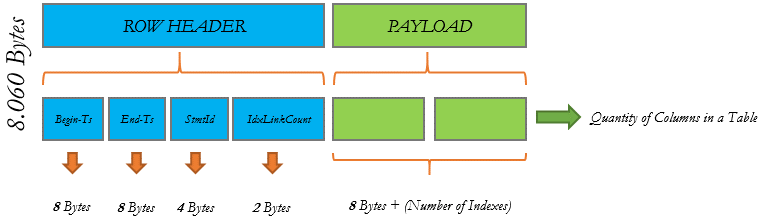
Figure 3. In-Memory Table Structure.
Begin-Ts
Insert timestamp of the row when the COMMIT operation occur.
End-Ts
Delete timestamp of the row when the COMMIT operation occur.
SmtId
Unique number for a transaction used to identify the row that was created.
IdxLinkCount
Count used to identify the quantity of indexes that are pointing to this row.
Comparing Disk-Based & In-Memory Tables Storage Style
In a Disk-Based Table model, data pages are requested from disk, loaded into the memory and them accessed by the request. The access on disk is one of the most expensive operations that SQLOS (Access Methods Layer) needs to handle because the disk access in the most of the cases are random and also depends of some circumstances to execute the fast read. Statistics, amount of data, fragmentation and disk speed impact directly in how SQL Server will respond and load the data pages into the Buffer Pool area.
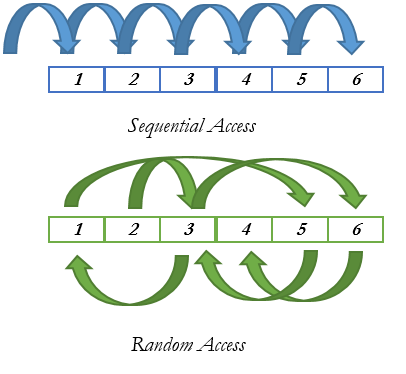
Figure 4. Random & Sequential Access on Disk.
In an In-Memory Table model, the mindset changes and we start assuming that the data is already loaded into the memory and all the COMMITs operations are written sequentially in the disk in the order of the transaction occurs, this becomes possible because of the Data Files & Delta Files that manages this situation. An INSERT operation safe the transaction in the Data File when a DELETE operation safe the transaction in the Delta Files, this mode all the access on disk becomes sequential making the disk not struggle anymore with the random access. The log record operation had an enhancement too. The in-memory tables save just the COMMIT time phase on the log record and this operation whenever possible tries to group multiple log records into one large I/O accomplishing a faster log insert because the WAL (write-ahead logging) is no longer necessary.
Table Types In-Memory
Creating memory-optimized tables is quiet similar than creating disk-based tables in a database. There are some differences in the index, data types and constraints options that memory-optimized tables can support. To create a memory-optimized table is necessary to add in the table creation phase the MEMORY_OPTIMIZED = ON clause and choose for the durability mode that you desire for memory-optimized table. There are 2 option in the table creation.
- SCHEMA_ONLY – Indicates that the schema will be durable but the data is not. These tables do not require any IO operation in the disk subsystem and the data is available only In-Memory, in a SQL Server restart or Server Shutdown the data is lost.
1234567891011121314151617USE inmem_SQLShackgoCREATE TABLE [dbo].[inmem_ProductSales]([ID] [INT] NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 5048),[Name] VARCHAR(50) NOT NULL,[Type] CHAR(2) NOT NULL,[Quantity] INT NOT NULL,[Status] CHAR(2),[UnitPrice] MONEY,[OrderDate] DATETIME) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)GO
- SCHEMA_AND_DATA – Different than the previous model, using this type the schema and the table will be persisted in disk and guarantee that the table will remain available in a SQL Server Restart or Server Shutdown.
123456789101112131415USE inmem_SQLShackgoCREATE TABLE [dbo].[inmem_InternetSales]([ID] [INT] NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 5048),[OrderData] DATETIME,[UnitPrice] MONEY,[Discount] MONEY,[UnitPrice] MONEY,[OrderNumber] INT) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)GO
Indexes & Constraint Considerations
- All the memory-optimized tables must to have at least one index to connect the rows together because data rows are not stored on pages, this way there is no pages or extents, partitions or allocation units to reference the table.
- Together with the memory-optimized tables there is now 2 new index types that will talk more about in the next posts – the hash index and range index.
Conclusion
There are some differences in the models but we can see at this stage that to memory-optimized tables are another way to improve and gain speed. Find the best tables to move is one of the most challenges that you will face as well choose the best indexes in a specific column.
In the next article of the series I will explain how to migrate the disk-based tables to memory-optimized tables using the best practices and how to find the best candidates for this process.

Luan Moreno credits his ability to solve problems to thinking critically before acting. He values working with a team because he and his clients can benefit from various perspectives and collaboration, particularly when faced with difficult issues.
When Luan Moreno first became interested in technology, he didn’t have a mentor, so he made a commitment to teaching others in the community and sharing his knowledge through blogging, speaking engagements
View all posts by Luan Moreno
- In-Memory OLTP Series – Data migration guideline process on SQL Server 2016 - January 29, 2016
- In-Memory OLTP Series – Data migration guideline process on SQL Server 2014 - January 28, 2016
- In-Memory OLTP Series – Table Creation & Types - March 13, 2015