
Descripción
A menudo tenemos la necesidad de ver definiciones de objetos en SQL Server, ya sean tablas, desencadenadores o claves externas. Las herramientas integradas son buenas para un objeto aquí y allá, pero son muy incómodas si usted está buscando generar sentencias para un gran número de objetos.
Presentaremos muchas diferentes vistas del sistema que proveen información valiosa acerca los objetos dentro de SQL Server. Esto nos permitirá entender cómo localizar y usar información acerca de nuestros datos y luego poder realizar tareas extremadamente útiles, como crear copias de nuestro esquema, validad la corrección o generar un esquema para propósitos de pruebas.
Antecedentes y Propósito
Poder mostrar rápidamente la sentencia CREATE para un objeto puede ser extremadamente útil. No sólo esto nos permite revisar nuestro esquema de base de datos, sino que nos permite usar esa información para crear copias de algunas o todas esas estructuras. ¿Por qué quisiéramos hacer esto? Hay muchas buenas razones, algunas de las cuales mostraré aquí:
- Rápidamente ver la definición de un solo objeto.
- Validación Automatizada de Esquema.
- Generar un script de creación a ser usado para construir esos objetos en otro lugar.
- Usar los scripts de creación de múltiples bases de datos para comparar/contrastar objetos.
- Ver todos los objetos dentro de una tabla en un solo script.
- Ver todo o algunos de los objetos en una base de datos basados en una entrada personalizada.
- Generar scripts de creación para uso en el control de versiones.
SQL Server Management Studio le permite hacer clic derecho en cualquier objeto que es visible desde el árbol de la base de datos y generar una sentencia de creación desde ahí, de esta manera:
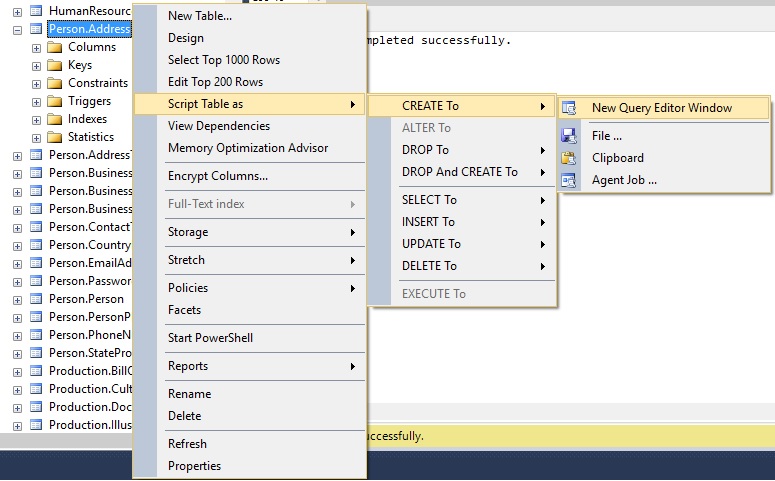
El TSQL resultante es como sigue:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
USE [AdventureWorks2014] GO /****** Object: Table [Person].[Address] Script Date: 5/8/2016 3:48:12 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [Person].[Address]( [AddressID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL, [AddressLine1] [nvarchar](60) NOT NULL, [AddressLine2] [nvarchar](60) NULL, [City] [nvarchar](30) NOT NULL, [StateProvinceID] [int] NOT NULL, [PostalCode] [nvarchar](15) NOT NULL, [SpatialLocation] [geography] NULL, [rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL, [ModifiedDate] [datetime] NOT NULL, CONSTRAINT [PK_Address_AddressID] PRIMARY KEY CLUSTERED ( [AddressID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO ALTER TABLE [Person].[Address] ADD CONSTRAINT [DF_Address_rowguid] DEFAULT (newid()) FOR [rowguid] GO ALTER TABLE [Person].[Address] ADD CONSTRAINT [DF_Address_ModifiedDate] DEFAULT (getdate()) FOR [ModifiedDate] GO ALTER TABLE [Person].[Address] WITH CHECK ADD CONSTRAINT [FK_Address_StateProvince_StateProvinceID] FOREIGN KEY([StateProvinceID]) REFERENCES [Person].[StateProvince] ([StateProvinceID]) GO ALTER TABLE [Person].[Address] CHECK CONSTRAINT [FK_Address_StateProvince_StateProvinceID] GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Primary key for Address records.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'AddressID' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'First street address line.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'AddressLine1' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Second street address line.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'AddressLine2' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Name of the city.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'City' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Unique identification number for the state or province. Foreign key to StateProvince table.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'StateProvinceID' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Postal code for the street address.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'PostalCode' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Latitude and longitude of this address.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'SpatialLocation' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'ROWGUIDCOL number uniquely identifying the record. Used to support a merge replication sample.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'rowguid' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Default constraint value of NEWID()' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'CONSTRAINT',@level2name=N'DF_Address_rowguid' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Date and time the record was last updated.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'COLUMN',@level2name=N'ModifiedDate' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Default constraint value of GETDATE()' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'CONSTRAINT',@level2name=N'DF_Address_ModifiedDate' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Street address information for customers, employees, and vendors.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Primary key (clustered) constraint' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'CONSTRAINT',@level2name=N'PK_Address_AddressID' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'Foreign key constraint referencing StateProvince.StateProvinceID.' , @level0type=N'SCHEMA',@level0name=N'Person', @level1type=N'TABLE',@level1name=N'Address', @level2type=N'CONSTRAINT',@level2name=N'FK_Address_StateProvince_StateProvinceID' GO |
Wow…esa una salida bastante grande para una sola tabla. Si todo lo que necesitábamos era algo de información acerca de esta tabla, y no nos importó la salida grande, entonces esto sería generalmente adecuado. Si estábamos buscando scripts de creación de esquema para un esquema entero, una base de datos o algún otro largo segmento de objetos, entonces este enfoque se volvería pesado. Hacer clic derecho cien veces no es mi idea de diversión, y tampoco es algo que pueda ser automatizado fácilmente.
Algo de la salida puede ser personalizado. Por ejemplo, si yo quería apagar el codificado de propiedades extendidas, podía hacerlo vía las opciones de SSMS como sigue:
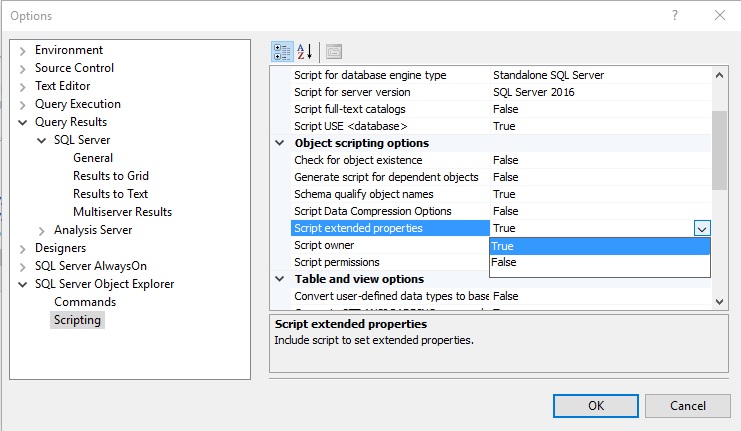
Mientras que este menú permite bastante personalización para la salida de codificación, la idea de tener que retornar a este menú cuando sea que quisiera cambiar lo que tengo de salida parece un poco lento. Mientras que hacer clic a través de los menús es fácil, es lento y manual, ambos atributos que generalmente no me gusta incorporar en mi día de trabajo 🙂
Siempre estoy buscando maneras de automatizar y acelerar procesos torpes o lentos —especialmente aquellos que dependen de cualquier elemento significativo de labor manual. Típicamente, mientras más estamos haciendo a mano como parte de procesos de rutina, más grande es la posibilidad de que algo salga mal. Somos humanos, y mientras que me considero un experto en hacer clic derecho, si tuviera que hacer eso cien veces cada lunes para validar alguna porción de esquema, no está claro si cometería un error o enloquecería primero.
De cualquier manera, me gustaría proponer una alternativa a todas estas posibilidades. Usando datos recolectados de vistas del sistema, podemos hacer todo esto nosotros mismos. Una vez que hemos investigado suficiente y recolectado datos desde las vistas del sistema, podemos crear un procedimiento almacenado usando esos procesos de recolección y automatizar todo en una llamada de procedimiento almacenado con un puñado de parámetros.
Lo que sique es una introducción a estas vistas, cómo usarlas para recolectar información útil acerca de nuestra base de datos y los objetos dentro.
Usando Metadatos del Sistema para Entender Nuestra Base de Datos
SQL Server provee una gran variedad de vistas del sistema, cada una de las cuales provee una vasta matriz de información acerca de objetos dentro de SQL Server. Esto nos permite aprender acerca de los atributos de tablas, ajustes del sistema o ver qué tipos de esquemas existen en cualquier base de datos.
Este análisis se enfocará en las estructuras primarias que hacen a cualquier base de datos y que hospedan nuestros datos: esquemas, tablas, restricciones, índices y desencadenadores. También veremos propiedades extendidas para mostrar nuestra habilidad para aprender acerca de componentes menos usados (pero potencialmente útiles) dentro de SQL Server.
Esquemas y Tablas
Los esquemas y tablas son fáciles de entender. Desde una base de datos podemos ver una lista de esquemas así:
|
1 2 3 |
SELECT * FROM sys.schemas; |
Correr esta consulta lista todos los esquemas dentro de nuestra base de datos. Los esquemas son útiles para organizar objetos de la base de datos y/o aplicar seguridad más granular a diferentes tipos de datos. Cuando se la ejecuta en AdventureWorks, los resultados de la anterior consulta son:
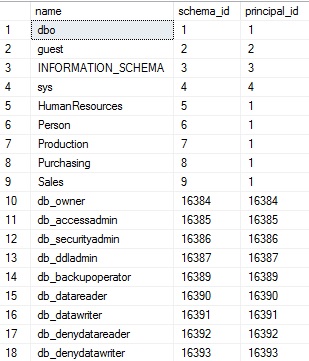
Los resultados son simplemente una lista de nombres de esquemas dentro de la base de datos. La vista contiene el nombre de esquema, su ID y el ID de su dueño. Los roles de la base de datos aparecen en la lista también. Mientras su inclusión puede parecer confusa, eliminarlos es fácil cuando combinamos esta vista con otras vistas de interés. Esta vista contiene todas las entidades que son capaces de tener otras desde el contexto de los esquemas de la base de datos. Algunos de los esquemas anteriores son familiares, como dbo (el esquema por defecto en SQL Server), y los específicos de AdventureWorks, como Sales, Purchasing, o HumanResources.
Las tablas representan nuestro mecanismo de almacenamiento principal y por lo tanto es muy importante para nosotros. Podemos ver mucha información acerca de ellos como sigue:
|
1 2 3 4 |
SELECT * FROM sys.tables WHERE tables.is_ms_shipped = 0; |
Añadir la selección en is_ms_shipped filtrará cualquier tabla de sistema. Si usted quisiera la lista completa de todas las tablas, incluyendo los objetos del sistema, siéntase libre para comentar u omitir este filtro. Los resultados son como sigue:

Hay varias columnas ahí, ¡incluyendo otras 2.5 páginas que están fuera de la pantalla a la derecha! Ellas incluyen diferentes pedazos de metadatos que serán útiles bajo una variedad de circunstancias. Por el bien de nuestro trabajo aquí, simplemente nos limitaremos a recolectar nombres de tablas y esquemas para aquellos que no son tablas de sistema. Podemos combinar nuestras dos vistas anteriores para listar los esquemas y las tablas juntos.
|
1 2 3 4 5 6 7 8 |
SELECT schemas.name AS SchemaName, tables.name AS TableName FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id WHERE tables.is_ms_shipped = 0 ORDER BY schemas.name, tables.name; |
Schema_id puede ser usado para combinar estas vistas juntas y conectar los esquemas con las tablas:
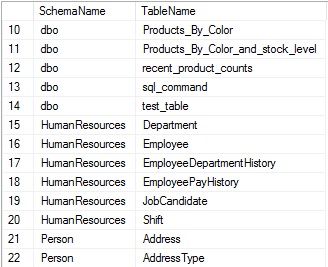
Añadir alias a cada columna es útil, dado que los nombres de cada una son “name”, lo cual no es una manera terriblemente descriptiva de diferenciar entre nombres de tablas y esquemas. Más adelante en este artículo, dado que retornamos información acerca de muchos otros tipos de objetos, darles alias con nombres amigables mejorar grandemente la legibilidad y la habilidad de entender los resultados rápida y fácilmente. Ordenar por nombres de esquemas y tablas también nos permite navegar más fácilmente a través de los resultados.
Columnas
Las columnas contienen cada atributo de una tabla. Entenderlos es imperativo para entender el contenido de una tabla y los tipos de datos que almacenamos ahí. La siguiente consulta añade sys.columns a nuestra consulta existente, lo cual provee información adicional acerca de cada columna, la tabla a la que pertenecen y el esquema al que la tabla pertenece:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, columns.name AS Column_Name, ROW_NUMBER() OVER (PARTITION BY schemas.name, tables.name ORDER BY columns.column_id ASC) AS Ordinal_Position, columns.max_length AS Column_Length, columns.precision AS Column_Precision, columns.scale AS Column_Scale, columns.collation_name AS Column_Collation, columns.is_nullable AS Is_Nullable, columns.is_identity AS Is_Identity, columns.is_computed AS Is_Computed, columns.is_sparse AS Is_Sparse FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id INNER JOIN sys.columns ON tables.object_id = columns.object_id; |
Las columnas son combinadas con las tablas usando el object_id de la tabla, el cual es referenciado por cualquier columna contenida. La consulta anterior retorna muchos más nombres de columnas, incluyendo detalles acerca de cada columna que es útil cuando averiguamos qué tipo de datos contiene cada una. Los resultados comienzan a pintar una figura más clara de nuestros datos:
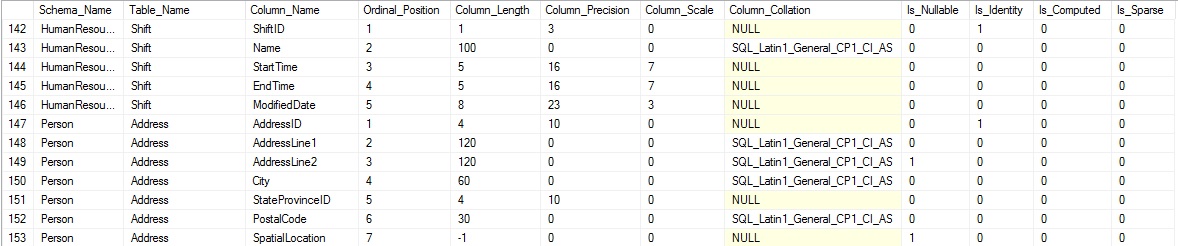
La posición ordinal nos dice el orden de la columna, lo cual es útil cuando estamos insertando en una tabla, o determinando el orden lógico para los datos. Otras columnas proveen información adicional, como el tamaño de la columna, el estado respecto del valor null, el estado de identidad ¡y más!
Tipos de Datos
Este es un gran inicio, pero podemos aprender más. Sys.types nos dice más acerca del tipo de dato para cada columna, y cómo puede ser directamente combinada a nuestra consulta previa usando user_type_id. El tipo resultante, cuando se combina con el tamaño, precisión y escala, no dice exactamente acerca del tipo de datos de una columna y cómo está definida:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, columns.name AS Column_Name, UPPER(types.name) AS Column_Data_Type, columns.max_length AS Column_Length, columns.precision AS Column_Precision, columns.scale AS Column_Scale FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON columns.user_type_id = types.user_type_id; |
Para evitar que nuestros resultados estén muy desordenados, he removido algunas de las columnas previamente discutidas:
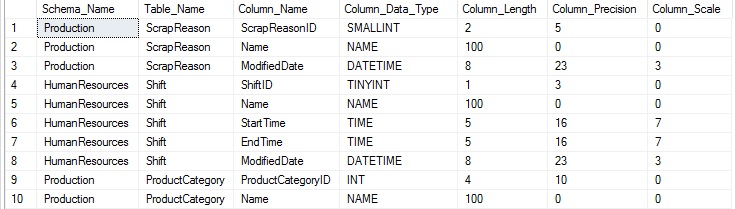
La información adicional nos provee con un nombre de tipo familiar, como DATETIME o INT, lo cual puede incluir tipos de datos de usuario personalizados, como NAME. Ahora tener un entendimiento básico acerca de lo que está en una tabla, y podemos ahora ahondar en atributos adicionales.
Detalles de la Columna Identidad
Uno de los atributos previamente identificado en sys.columns era is_identity, o cual nos dijo si una columna era identidad o no. Si es, también queremos saber la semilla y el incremento de la columna, lo cual nos dice cómo se comportará es identidad. Esto puede ser conseguido combinando sys.columns a sys.identity_columns:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, columns.name AS Column_Name, UPPER(types.name) AS Column_Data_Type, CAST(identity_columns.seed_value AS BIGINT) AS Identity_Seed, CAST(identity_columns.increment_value AS BIGINT) AS Identity_Increment FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON columns.user_type_id = types.user_type_id LEFT JOIN sys.identity_columns ON columns.object_id = identity_columns.object_id AND columns.column_id = identity_columns.column_id; |
Note que la combinación de sys.identity_columns requiere usar object_id,, lo cual indica la tabla a la que pertenece, y también column_id, el cual especifica el ID único de la columna dentro de esa tabla. Para referenciar más fácil y precisamente cualquier columna de forma única, debemos usar object_id y column_id. Los resultados de la consulta anterior muestran la información adicional añadida al final del conjunto de resultados:
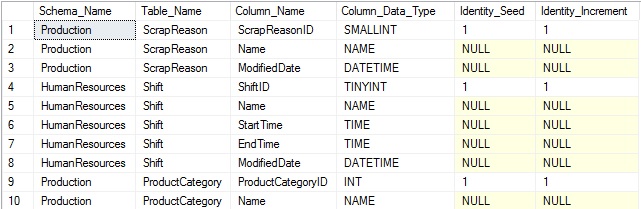
Los resultados no son terriblemente emocionantes. IDENTITY(1,1) es la definición más comúnmente usada para una columna identidad, pero hemos obtenido conocimiento adicional que será útil posteriormente.
Restricciones por Defecto
Una columna puede tener una sola restricción por defecto asociada con ella. Si una está definida, saber su nombre y valor es útil para entender el comportamiento de la columna. A menudo, una por defecto indica una regla de negocios o necesidad de datos para asegurar que la columna no es NULL, o es al menos siempre poblada con algo de valores flexibles importantes. Podemos recolectar esta información desde sys.default_constraints asi:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, columns.name AS Column_Name, UPPER(types.name) AS Column_Data_Type, default_constraints.name AS Default_Constraint_Name, UPPER(default_constraints.definition) AS Default_Constraint_Definition FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON columns.user_type_id = types.user_type_id LEFT JOIN sys.default_constraints ON schemas.schema_id = default_constraints.schema_id AND columns.object_id = default_constraints.parent_object_id AND columns.column_id = default_constraints.parent_column_id; |
Note que mientras que esta nueva vista está combinada en un esquema, tabla y columna, la combinación en esquema es innecesaria ya que ya estamos combinando esa vista vía sys.tables. Sin importar eso, está incluida para propósitos de documentación y compleción. Los resultados de la consulta muestran todas las columnas, pero si una por defecto está definida, esa información también está provista:
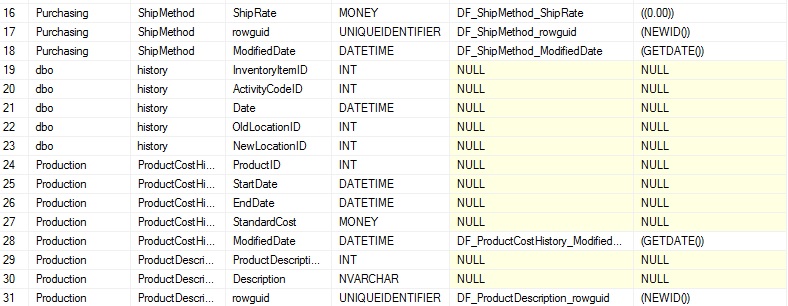
Podemos notar una variedad de restricciones por defecto que toman valores de la fecha actual, cero y un nuevo identificador único GUID, aunque muchos otros tipos pueden existir con cualquier valor que elija asignarles. NULL indica que una columna no tiene una restricción por defecto asignada a ella. Si elegimos combinar a sys.default_constraints usando un INNER JOIN, entonces filtraríamos todas las filas sin restricciones por defecto, dejando atrás sólo el conjunto de columnas con valores por defecto definidos.
Columnas Computadas
De manera similar a las restricciones por defecto, una columna puede tener sólo una definición computada asociada con ella. A una columna computada no le pueden asignar valores, y en lugar de eso es automáticamente actualizada en base a cualquier definición que es creada para ella. La información en esto puede ser encontrada en sys.computed_columns y combinada de vuelta a sys.columns usando object_id y column_id:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, columns.name AS Column_Name, UPPER(types.name) AS Column_Data_Type, UPPER(computed_columns.definition) AS Computed_Column_Definition FROM sys.schemas INNER JOIN sys.tables ON schemas.schema_id = tables.schema_id INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON columns.user_type_id = types.user_type_id LEFT JOIN sys.computed_columns ON columns.object_id = computed_columns.object_id AND columns.column_id = computed_columns.column_id; |
Esta nueva vista hereda todas las columnas en sys.columns, añadiendo unas pocas piezas adicionales de información. De estas, nos enfocaremos en la definición, la cual nos dice en TSQL cómo esa columna es poblada:
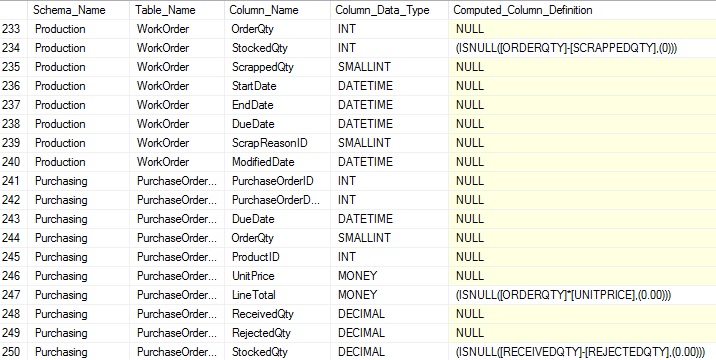
Dado que sys.computed_columns contiene toda la información sys.columns, no es necesario incluir sys.columns cuando también estamos consultándola si todo lo que nos importa son las columnas con valores computados definidos ellas. Si queremos incluir todas las columnas dentro de la definición computada siendo opcional, entonces el LEFT JOIN entre ellas es requerido. Cualquier columna sin filas en sys.computed_columns resultará en un NULL en la consulta anterior, indicando que esa no tiene una definición de columna computada.
Índices y Definiciones de Claves Primarias
Una tabla puede tener sólo una clave primaria asociada con ella, pero esta definición es suficientemente importante para que queramos siempre capturarla, sin importar en qué columnas esté, o si también es un índice agrupado o no. Los detalles acerca de las claves primaras, así como los detalles acerca de otros índices, pueden ser encontrados en sys.indexes. Esta vista también contiene datos pertinentes a otros índices en la tabla. Por tanto, podemos recolectar información acerca de todos los índices, incluyendo las claves primarias en una sola operación:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
WITH CTE_INDEX_COLUMNS AS ( SELECT INDEX_DATA.name AS Index_Name, SCHEMA_DATA.name AS Schema_Name, TABLE_DATA.name AS Table_Name, INDEX_DATA.is_unique, INDEX_DATA.has_filter, INDEX_DATA.filter_definition, INDEX_DATA.type_desc AS Index_Type, STUFF(( SELECT ', ' + columns.name + CASE WHEN index_columns.is_descending_key = 1 THEN ' DESC' ELSE ' ASC' END FROM sys.tables INNER JOIN sys.indexes ON tables.object_id = indexes.object_id INNER JOIN sys.index_columns ON indexes.object_id = index_columns.object_id AND indexes.index_id = index_columns.index_id INNER JOIN sys.columns ON tables.object_id = columns.object_id AND index_columns.column_id = columns.column_id WHERE INDEX_DATA.object_id = indexes.object_id AND INDEX_DATA.index_id = indexes.index_id AND index_columns.is_included_column = 0 ORDER BY index_columns.key_ordinal FOR XML PATH('')), 1, 2, '') AS Index_Column_List, STUFF(( SELECT ', ' + columns.name FROM sys.tables INNER JOIN sys.indexes ON tables.object_id = indexes.object_id INNER JOIN sys.index_columns ON indexes.object_id = index_columns.object_id AND indexes.index_id = index_columns.index_id INNER JOIN sys.columns ON tables.object_id = columns.object_id AND index_columns.column_id = columns.column_id WHERE INDEX_DATA.object_id = indexes.object_id AND INDEX_DATA.index_id = indexes.index_id AND index_columns.is_included_column = 1 ORDER BY index_columns.key_ordinal FOR XML PATH('')), 1, 2, '') AS Include_Column_List, Is_Primary_Key FROM sys.indexes INDEX_DATA INNER JOIN sys.tables TABLE_DATA ON TABLE_DATA.object_id = INDEX_DATA.object_id INNER JOIN sys.schemas SCHEMA_DATA ON TABLE_DATA.schema_id = SCHEMA_DATA.schema_id) SELECT Index_Name, Schema_Name, Table_Name, is_unique, has_filter, filter_definition, Index_Type, Index_Column_List, ISNULL(Include_Column_List, '') AS Include_Column_List, Is_Primary_Key FROM CTE_INDEX_COLUMNS WHERE CTE_INDEX_COLUMNS.Index_Type <> 'HEAP'; |
Esta consulta recolecta datos de índice básicos, como si es una clave agrupada, filtrada o primaria. También usa XML para jalar los detalles de la columna índice en una lista separada por comas, para un uso posterior fácil. Recolectar todos estos datos de una vez es eficiente y convenientes, y evita la necesidad de retornar por listas de columnas, o revisar cualquier propiedad para un índice posteriormente.
Mientras que la consulta anterior parece compleja, si removemos el XML necesario para analizar la lista de columnas, la consulta resultante sería sólo un SELECT simple desde sys.indexes, sys.tables y sys.schemas. Mientras que podemos hacer esto inicialmente, y luego añadir las listas de columnas después, recolectar todos estos datos ahora mismo simplificará nuestro TSQL y mejorará el rendimiento ya que no necesitamos realizar búsquedas adicionales de esquemas y combinaciones a esos datos una vez que esté completo.
Los resultados de la consulta anterior se ven así:

Omitimos HEAP de los resultados ya que no es necesario para la documentación explícita de tablas ya que son automáticamente implicadas en la definición de la pila. Obtenemos un conjunto grande de resultados, pero nos provee con todo lo que necesitamos para entender un índice y su propósito y uso.
Claves Foráneas
Las claves foráneas también representan listas de columnas en una tabla que referencia columnas en una tabla destino. Podemos ver información básica en una clave foránea usando la vista del sistema sys.foreign_keys:
|
1 2 3 4 5 6 7 8 9 |
SELECT foreign_keys.name AS Foreign_Key_Name, schemas.name AS Foreign_Key_Schema_Name, tables.name AS Foreign_Key_Table_Name FROM sys.foreign_keys INNER JOIN sys.tables ON tables.object_id = foreign_keys.parent_object_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id; |
Esta consulta retorna una lista de claves foráneas y las tablas fuente/destino referenciadas por ella:
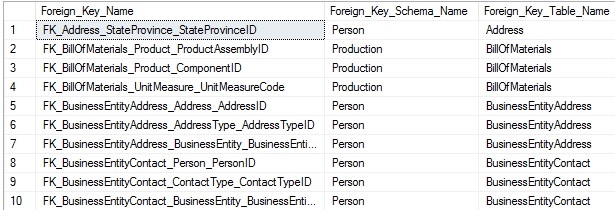
Esto es directo, pero también queremos recolectar las listas de columnas desde las tablas fuente y destino para incluirlas correctamente en nuestros datos. Una clave foránea es a menudo una relación entre una sola columna en una tabla y su columna correspondiente en otra tabla, pero podría existir entre grupos de columnas. Como resultado, debemos escribir nuestro TSQL para que pueda manejar cualquier escenario. Por ahora, veamos una lista de columnas en la cual una clave foránea es definida por una fila por columna en el conjunto de resultados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT foreign_keys.name AS Foreign_Key_Name, FOREIGN_KEY_TABLE.name AS Foreign_Key_Table_Name, FOREIGN_KEY_COLUMN.name AS Foreign_Key_Column_Name, REFERENCED_TABLE.name AS Referenced_Table_Name, REFERENECD_COLUMN.name AS Referenced_Column_Name FROM sys.foreign_key_columns INNER JOIN sys.foreign_keys ON foreign_keys.object_id = foreign_key_columns.constraint_object_id INNER JOIN sys.tables FOREIGN_KEY_TABLE ON foreign_key_columns.parent_object_id = FOREIGN_KEY_TABLE.object_id INNER JOIN sys.columns as FOREIGN_KEY_COLUMN ON foreign_key_columns.parent_object_id = FOREIGN_KEY_COLUMN.object_id AND foreign_key_columns.parent_column_id = FOREIGN_KEY_COLUMN.column_id INNER JOIN sys.columns REFERENECD_COLUMN ON foreign_key_columns.referenced_object_id = REFERENECD_COLUMN.object_id AND foreign_key_columns.referenced_column_id = REFERENECD_COLUMN.column_id INNER JOIN sys.tables REFERENCED_TABLE ON REFERENCED_TABLE.object_id = foreign_key_columns.referenced_object_id ORDER BY FOREIGN_KEY_TABLE.name, foreign_key_columns.constraint_column_id; |
Sys.foreign_key_columns nos dice las relaciones de la columna. Desde ahí, necesitamos combinar sys.tables and sys.columns dos veces: Una vez para la tabla padre y otra para la tabla de la clave foránea. Combinar esta información nos permite entender qué columnas refieren y son referidas por cualquier clave foránea. Si una clave foránea tiene múltiples columnas participando en ella, entonces será representada como múltiples filas en el conjunto de resultados:
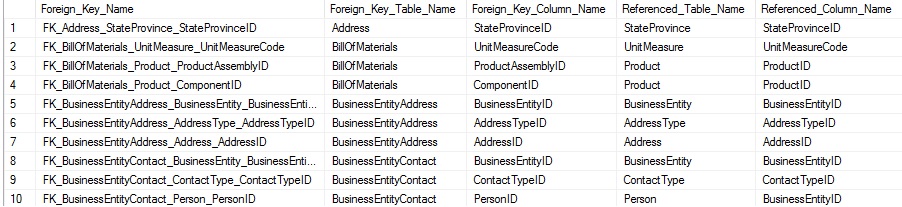
Dado que necesitamos preocuparnos acerca de dos conjuntos de datos, recolectarlo toma un poco más de trabajo, pero mucho de eso es una duplicación de conceptos que ha hemos discutido previamente.
Restricciones CHECK
Las restricciones CHECK son relativamente simples para recolectar información. Dado que están almacenadas con sus definiciones enteras intactas, no hay necesidad de consultar los metadatos de la columna para construirlas. Sys.check_constraints puede ser consultada para ver la información acerca de las restricciones CHECK:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, check_constraints.name AS Check_Constraint_Name, check_constraints.is_not_trusted AS With_Nocheck, check_constraints.definition AS Check_Constraint_Definition FROM sys.check_constraints INNER JOIN sys.tables ON tables.object_id = check_constraints.parent_object_id INNER JOIN sys.schemas ON tables.schema_id = schemas.schema_id; |
Seleccionar la columna is_not_trustednos permite validar si la restricción fue creada con NOCHECK o no. La definición contiene los detalles exactos de la restricción como fueron ingresado cuando fue creada. Los resultados son fáciles de leer y entender:
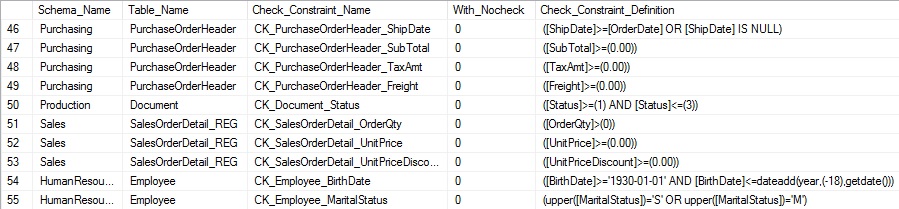
La definición en sí mismo puede ser compleja, pero nuestros esfuerzos para recolectar esta información son los mismos, sin importar cuán intrincada es la restricción CHECK.
Desencadenadores
Los desencadenadores están almacenados en una manera muy similar a las restricciones CHECK. La única diferencia es que su definición está incluida en sys.sql_modules, mientras que el nombre del desencadenador y la información de objeto están almacenados en sys.triggers. A pesar de que hay dos tablas involucradas, podemos recolectar datos en ellas en la misma manera como con las restricciones CHECK:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT schemas.name AS Schema_Name, tables.name AS Table_Name, sql_modules.definition AS Trigger_Definition FROM sys.triggers INNER JOIN sys.sql_modules ON triggers.object_id = sql_modules.object_id INNER JOIN sys.tables ON triggers.parent_id = tables.object_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id; |
Note que mientras que combinamos a sys.triggers,no retornamos ninguna columna desde esa vista. Esto es porque la definición del desencadenador provee todos los detalles de un desencadenador que sería encontrado en una sentencia CREATE TRIGGER. Sys.sql_modules contiene detalles acerca de una variedad de objetos dentro de SQL Server, como procedimientos almacenados, desencadenadores y funciones. Las definiciones dentro de esta vista son todas provistas en su integridad, incluyendo la sentencia CREATE. Como resultado, no hay necesidad de consultar metadatos adicionales, como si el desencadenador es INSTEAD OF o AFTER, o si está en UPDATE, DELETE o INSERT. Los resultados de la consulta anterior son como sigue:
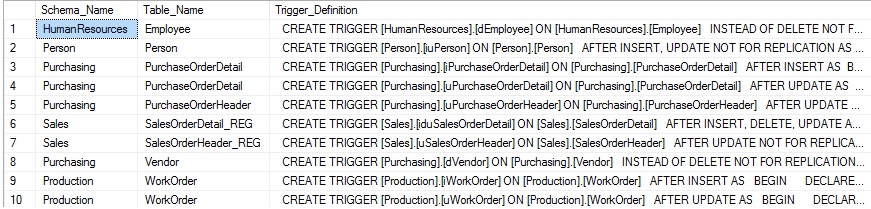
¡Los resultados son mucho más simples de lo que habíamos esperado! La definición entera es retornada en una sola columna, ¡lo cual hacer nuestro trabajo bastante fácil!
Propiedades Extendidas
Las propiedades extendidas son un poco extrañas en términos de definición y uso. Ellas pueden ser enlazadas a muchos diferentes objetos en SQL Server, como tablas, columnas o restricciones. Como resultado, necesitamos no recolectar sólo su definición, sino que también el objeto al que se relacionan. Esta es una característica que no todos usan, pero es un buen ejemplo de cómo incluso las partes más raras de SQL Server pueden ser documentadas si es necesario.
Sys.extended_properties contiene toda la información básica acerca de una propiedad extendida. major_id y minor_id dentro de la vista nos proveen con información acerca de qué objeto referencia la propiedad. Dado que no sabemos precisamente qué tipo de objeto referencia cualquier propiedad extendida de entrada, necesitamos usar LEFT JOIN en todos los posibles destinos para recolectar un conjunto de resultados completo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
SELECT Child.type_desc AS Object_Type, extended_properties.name AS Extended_Property_Name, CAST(extended_properties.value AS NVARCHAR(MAX)) AS Extended_Property_Value, schemas.name AS Schema_Name, Child.name AS Object_Name, Parent.name AS Parent_Object_Name, columns.name AS Parent_Column_Name, indexes.name AS Index_Name FROM sys.extended_properties INNER JOIN sys.objects Child ON extended_properties.major_id = Child.object_id INNER JOIN sys.schemas ON schemas.schema_id = Child.schema_id LEFT JOIN sys.objects Parent ON Parent.object_id = Child.parent_object_id LEFT JOIN sys.columns ON Child.object_id = columns.object_id AND extended_properties.minor_id = columns.column_id AND extended_properties.class_desc = 'OBJECT_OR_COLUMN' AND extended_properties.minor_id <> 0 LEFT JOIN sys.indexes ON Child.object_id = indexes.object_id AND extended_properties.minor_id = indexes.index_id AND extended_properties.class_desc = 'INDEX' WHERE Child.type_desc IN ('CHECK_CONSTRAINT', 'DEFAULT_CONSTRAINT', 'FOREIGN_KEY_CONSTRAINT', 'PRIMARY_KEY_CONSTRAINT', 'SQL_TRIGGER', 'USER_TABLE') ORDER BY Child.type_desc ASC; |
En esta consulta, sys.extended_properties forma la tabla base. Sys.objects y sys.schemas están conectados usando un INNER JOIN, ya que sus metadatos se aplicarán a todas las propiedades, sin importar su tipo. Desde aquí, las combinaciones restantes nos permiten recolectar información adicional acerca del objeto referenciado en sys.objects. La cláusula WHERE limita los destinos en los que estamos interesados a los tipos de objetos que hemos discutido hasta ahora (restricciones, desencadenadores y columnas).
Los resultados de la consulta anterior se verán así:

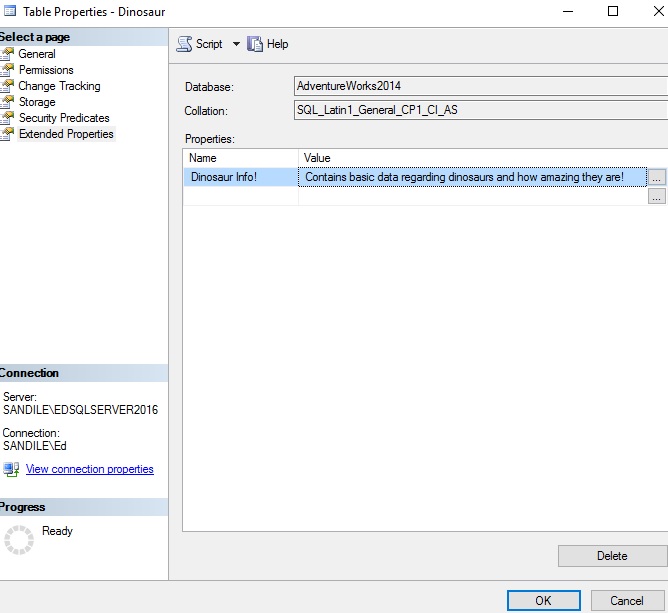
Los resultados nos dicen el nombre de la propiedad extendida, el tipo de objeto que referencia, la información acerca de ese objeto y el texto almacenado en la propiedad extendida en sí misma. Microsoft no fue muy creativo y llamó a todas las propiedades extendidas “MS_Description”. Usted puede llamar las suyas como desee, como esta tabla “Dinosaur” que yo he creado:
Conclusión
Las vistas de sistema proveen una riqueza de información acerca de nuestros datos, cómo están almacenados y las restricciones que emplazamos en ellas. Usando estas vistas, podemos recolectar información rápidamente acerca de objetos que son importantes para nosotros, como índices o claves foráneas. Con esta información, podemos reconstruir nuestro esquema en un formato que asistirá en la duplicación de esquema, el desarrollo y el control de calidad, y la comparación del esquema.
En nuestro artículo Creating the perfect schema documentation script, tomaremos todos lo que hemos discutido aquí y lo combinaremos en un script que mejorará grandemente nuestra habilidad para documentar y entender una base de datos y su estructura.
Referencias y Lecturas Complementarias
Algunas de las vistas de sistema discutidas aquí eran también presentadas en un artículo de dos partes previo acerca de buscar en SQL Server, si se desea, podríamos combinar estos scripts de tal manera que el script de búsqueda también retornada la definición. Esto podría ser una manera muy eficiente (y divertida) de encontrar objetos y sus definiciones basados en una búsqueda de palabras clave:
Searching SQL Server made easy – Searching catalog views
Searching SQL Server made easy – Building the perfect search script
Las opciones están documentadas para la codificación integrada de SQL Server aquí:
Generate SQL Server Scripts Wizard (Choose Script Options Page)
Lagunas instrucciones básicas acerca de este proceso se pueden encontrar aquí:
Generate Scripts (SQL Server Management Studio)
Finalmente, la información acerca de vistas de catálogo, las cuales proveen la base para este artículo, se pueden encontrar aquí:
Catalog Views (Transact-SQL)

En su tiempo libre, Ed juega video juegos, películas de ciencia ficción y fantásticas, viajar y ser un gran geek al nivel que sus amigos puedan tolerar.
Vea todas las entradas de Ed Pollack
- Técnicas de optimización de consultas en SQL Server: consejos y trucos de aplicación - September 30, 2019
- Todo lo que querías saber sobre SQL Saturday (pero tenías miedo de preguntar) - April 13, 2018
- Cambios del Optimizador de Consultas en SQL Server 2016 explicados - April 21, 2017