
Las tablas Temporales de SQL Server son un tipo especial de tablas que son escritas en la base de datos TempDB y actúan como tablas regulares, proveyendo un espacio de trabajo apropiado para procesamiento intermedio de datos antes de grabar el resultado a una tabla regular, ya que puede vivir a lo largo de la edad de la conexión de la base de datos.
Las tablas temporales pueden ser usadas para mejorar los procedimientos almacenados al acortar el tiempo de transacción, permitiéndole preparar los registros que usted modificará en la tabla temporal, luego abrir una transacción y realizar los cambios.
Hay cuatro tipos principales para las tablas temporales:
Una tabla Temporal Local la cual es nombrada comenzando con un símbolo # (por ejemplo, #TempShipments), y puede ser referenciada sólo por la sesión actual de la base de datos y descartada por su desconexión.
Una tabla Temporal Global la cual es nombrada comenzando con ## (por ejemplo, ##TempShipments), que puede ser referenciada por cualquier proceso en la base de datos actual y descartada cuando la sesión de la base de datos original que creó la tabla temporal se desconecta o hasta que la última sentencia que fue referenciada por la tabla temporal deje de usarla, ya que cualquier que tenga acceso a la base de datos de sistema TempDB cuando esa tabla temporal global es creada, podrá usar esa tabla.
Una tabla Temporal Persistente la cual es nombrada comenzando con un prefijo TempDB como TempDB.DBO.TempShipments.
Y una Tabla Variable que comienza con un prefijo @ (por ejemplo, @TempShipments).
El Motor de Base de Datos de SQL Server puede distinguir entre las mismas tablas temporales creadas mientras que ejecuta el mismo procedimiento almacenado muchas veces simultáneamente anexando un sufijo numérico generado por el sistema al nombre de la tabla temporal. Es por esto que el nombre de la tabla temporal local no puede exceder 116 caracteres.
Aunque tanto las tablas temporales como las tablas variables son almacenadas en la base de datos TemDB, hay muchas diferencias entre ellas, como ser:
Tablas temporales que son creadas usando la sentencia CREATE TABLE T-SQL, pero las tablas variables son creadas usando la sentencia T-SQL DECLARE @name Table.
Usted puede alterar las tablas temporales después de crearlas, pero las tablas variables no soportan ninguna sentencia DDL como la sentencia ALTER.
Las tablas temporales no pueden ser usadas en Funciones Definidas por el Usuario, pero las tablas variables pueden.
Las tablas temporales cumplen con transacciones explícitas definidas por el usuario, pero las tablas variables no puede participar en tales transacciones.
Las tablas temporales soportan añadir índices agrupados y no agrupados después de la creación de una tabla temporal, e implícitamente definiendo la restricción de la clave Primaria o clave única durante la creación de las tablas, pero las tablas variables soportan sólo añadir tales índices definiendo la restricción de la clave Primaria o Única durante la creación de las tablas.
Las tablas temporales pueden ser eliminadas explícitamente, pero las tablas variables no pueden ser eliminadas explícitamente, tomando en consideración que ambos tipos son eliminados automáticamente cuando la sesión en la cual son creadas está desconectada.
Las tabas temporales pueden ser tablas temporales locales al nivel del lote o procedimiento almacenado en el cual la tabla declarada o tablas globales temporales donde pueden ser llamadas desde afuera del lote o alcance del procedimiento almacenado, pero las tablas variables pueden ser llamadas sólo dentro del lote o procedimiento almacenado en el cual son declaradas.
En adición a eso, las estadísticas a nivel de columna de SQL Server son generadas automáticamente contra las tablas temporales, ayudando al Optimizador de Consultas de SQL Server a generar el mejor plan de ejecución, obteniendo el mejor desempeño cuando se consulta a una tabla temporal. Pero usted debería tomar en consideración que modificar tablas temporales muchas veces en su código puede llevar a estadísticas desactualizadas. Esto requeriría actualizar manualmente estas estadísticas o habilitar la Marca de Seguimiento 2371. En este artículo veremos cómo podemos beneficiarnos de la habilidad de añadir índices agrupados y no agrupados en las tablas temporales.
Definir restricciones de CLAVE PRIMARIA Y CLAVE ÚNICA durante la creación de tablas temporales permitirá al Optimizador de Consultas de SQL Server a estar siempre dispuesto para usar estos índices. Incluso así, estos índices evitan insertar valores no únicos a estas columnas, lo cual no es el mejor caso en todos los escenarios y podría requerir valores no únicos. En este caso, es mejor definir explícitamente un índice agrupado o no agrupado que podría ser configurado como un índice no único. Añadir índices a las tablas temporales mejorará su desempeño si el índice es elegido correctamente, de otro modo, puede causar degradación en el desempeño. También, no toda tabla temporal necesita añadir índices, ya que eso depende de muchas cosas, como la manera que esta tabla temporal será llamada, combinada con otras tablas enormes o si será parte de un procedimiento almacenado complejo.
Comencemos nuestra demostración en la cual probaremos el desempeño de llenar y recuperar datos desde tablas temporales que contienen registros de 100k, sin ningún índice, con un índice no agrupado y con un índice agrupado. Nos concentraremos en revisar el tiempo consumido por cada caso y el plan de ejecución generado. Para evaluar el tiempo consumido, establezca su valor a GETDATE () y al final de cada ejecución imprimiremos la diferencia de fecha (en milisegundos) entre el tiempo actual y el tiempo de inicio.
El siguiente script creará las tres tabas mencionadas anteriormente; la tabla temporal sin índice, la tabla temporal con un índice no agrupado y la tabla temporal con el índice agrupado, y las llenará con registros de 100k desde la tabla de pruebas CountryInfo, luego recuperará estos registros de las tablas:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
USE SQLShackDemo GO set nocount on go DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithNoIndex ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) INSERT INTO #TempWithNoIndex SELECT TOP 100000 * FROM [dbo].[CountryInfo] SELECT * FROM #TempWithNoIndex WHERE CountyCode='JFK' PRINT '#TempWithNoIndex' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithNoIndex GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithNonClusterIndex ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) INSERT INTO #TempWithNonClusterIndex SELECT TOP 100000 * FROM [dbo].[CountryInfo] CREATE NONCLUSTERED INDEX ix_tempNCIndexAft ON #TempWithNonClusterIndex ([CountyCode],[RowVersion]); SELECT * FROM #TempWithNonClusterIndex WHERE CountyCode='JFK' PRINT '#TempWithNonClusterIndex' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithNonClusterIndex GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithClusterIndex ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) CREATE CLUSTERED INDEX ix_tempCIndexAft ON #TempWithClusterIndex ([CountyCode],[RowVersion]); INSERT INTO #TempWithClusterIndex SELECT TOP 100000 CountyCode,RowVersion FROM [dbo].[CountryInfo] SELECT * FROM #TempWithClusterIndex WHERE CountyCode='JFK' PRINT '#TempWithClusterIndex' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithClusterIndex GO |
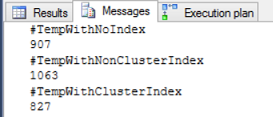
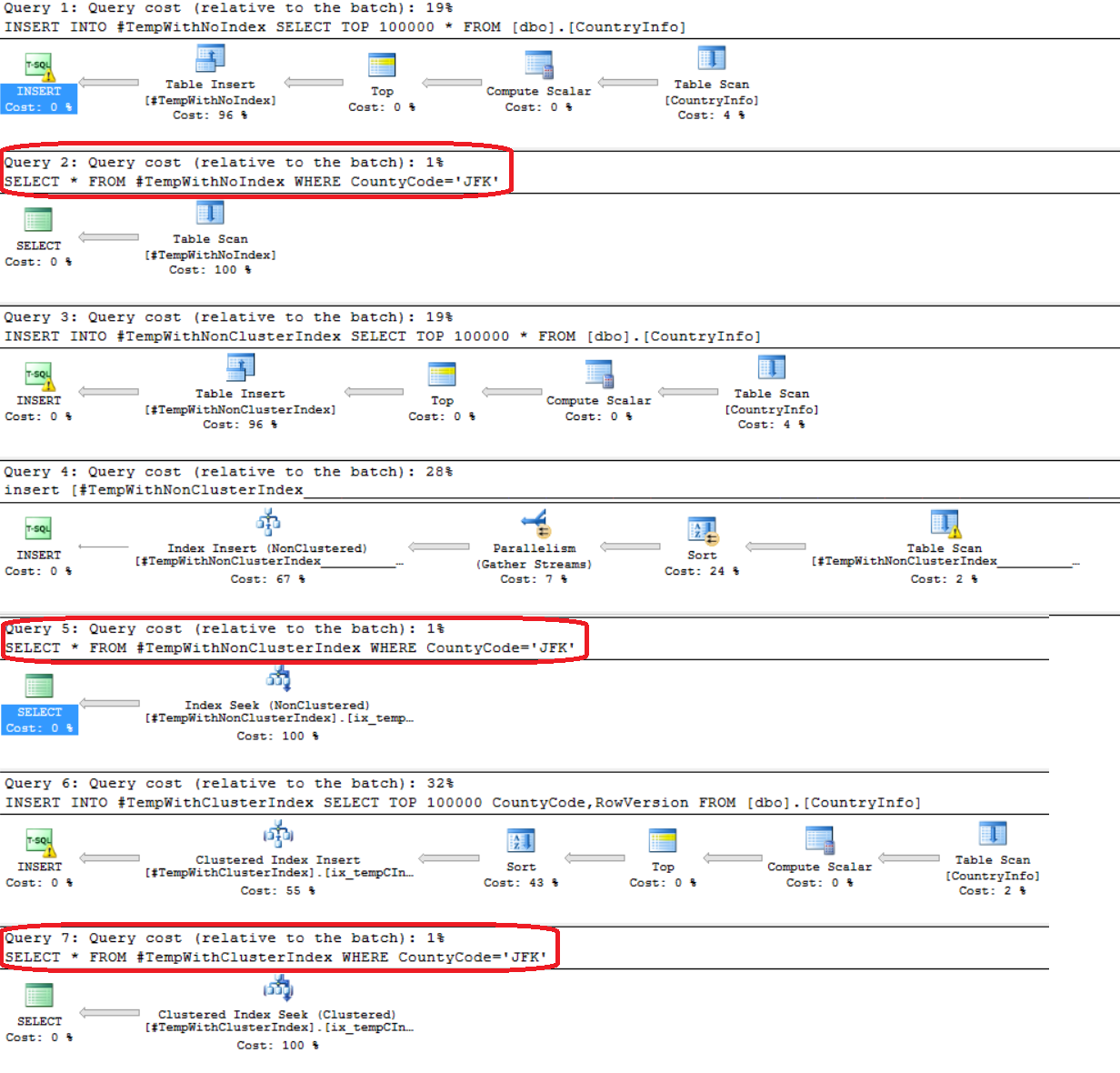
Después de ejecutar el script previo, el resultado nos mostrará que, en nuestro caso, añadir un índice no agrupado es peor que tener la tabla sin índice, 1.2 veces el tiempo en nuestro caso, pero añadir un índice agrupado mejorará el desempeño general 1 vez en nuestro caso, dado que la comparación e nuestro caso es en milisegundos:
Revisando el plan de ejecución generado después de la ejecución, veremos que, ya que no tenemos combinaciones con grandes tablas o consultas complejas, los datos recuperados desde las tres tablas consumen la misma cantidad de recursos (1%) y difieren en el operador que es usado para recuperar los datos; Table Scan en el caso de la tabla temporal sin índice, Index Seek en el caso de la tabla temporal con índice no agrupado y Clustered Index Seek en el caso de la tabla con índice agrupado.
También, usted puede derivar desde el plan de ejecución que la tabla con índice no agrupado tomó más tiempo (1063 ms) y recursos (47% de toda la ejecución) durante el proceso de inserción de tabla, opuesto a la tabla con índice agrupado, la inserción tomó menos tiempo (827 ms) y recursos (32% de toda la ejecución):
En el script previo creamos un índice no agrupado después de llenar la tabla temporal y el índice agrupado antes de llenar la tabla temporal. ¿Pero es diferente cuando creamos el índice antes o después de llenar la tabla temporal? Para contestar esta pregunta, realicemos la siguiente prueba en la cual revisaremos el tiempo consumido en todos los casos; añadir un índice no agrupado antes de llenar la tabla temporal, añadir un índice no agrupado después de llenar la tabla temporal, añadir un índice agrupado antes de llenar la tabla y añadir un índice agrupado después de llenar la tabla temporal:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
USE SQLShackDemo GO set nocount on GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithNonClusterIndexBefore ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) CREATE NONCLUSTERED INDEX ix_tempNCIndexBef ON #TempWithNonClusterIndexBefore ([CountyCode],[RowVersion]); INSERT INTO #TempWithNonClusterIndexBefore SELECT TOP 100000 * FROM [dbo].[CountryInfo] PRINT '#TempWithNonClusterIndexBefore' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithNonClusterIndexBefore GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithNonClusterIndexAfter ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) INSERT INTO #TempWithNonClusterIndexAfter SELECT TOP 100000 * FROM [dbo].[CountryInfo] CREATE NONCLUSTERED INDEX ix_tempNCIndexAft ON #TempWithNonClusterIndexAfter ([CountyCode],[RowVersion]); PRINT '#TempWithNonClusterIndexAfter' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithNonClusterIndexAfter GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithClusterIndexBefore ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) CREATE CLUSTERED INDEX ix_tempCIndexBef ON #TempWithClusterIndexBefore ([CountyCode],[RowVersion]); INSERT INTO #TempWithClusterIndexBefore SELECT TOP 100000 * FROM [dbo].[CountryInfo] PRINT '#TempWithClusterIndexBefore' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithClusterIndexBefore GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithClusterIndexAfter ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) INSERT INTO #TempWithClusterIndexAfter SELECT TOP 100000 CountyCode,RowVersion FROM [dbo].[CountryInfo] CREATE CLUSTERED INDEX ix_tempCIndexAft ON #TempWithClusterIndexAfter ([CountyCode],[RowVersion]); PRINT '#TempWithClusterIndexAfter' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithClusterIndexAfter GO |
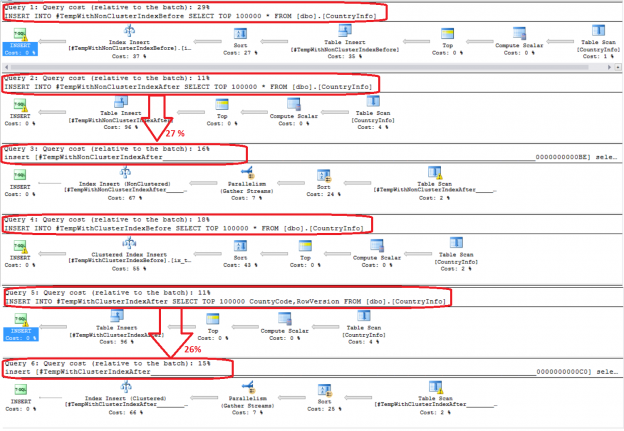
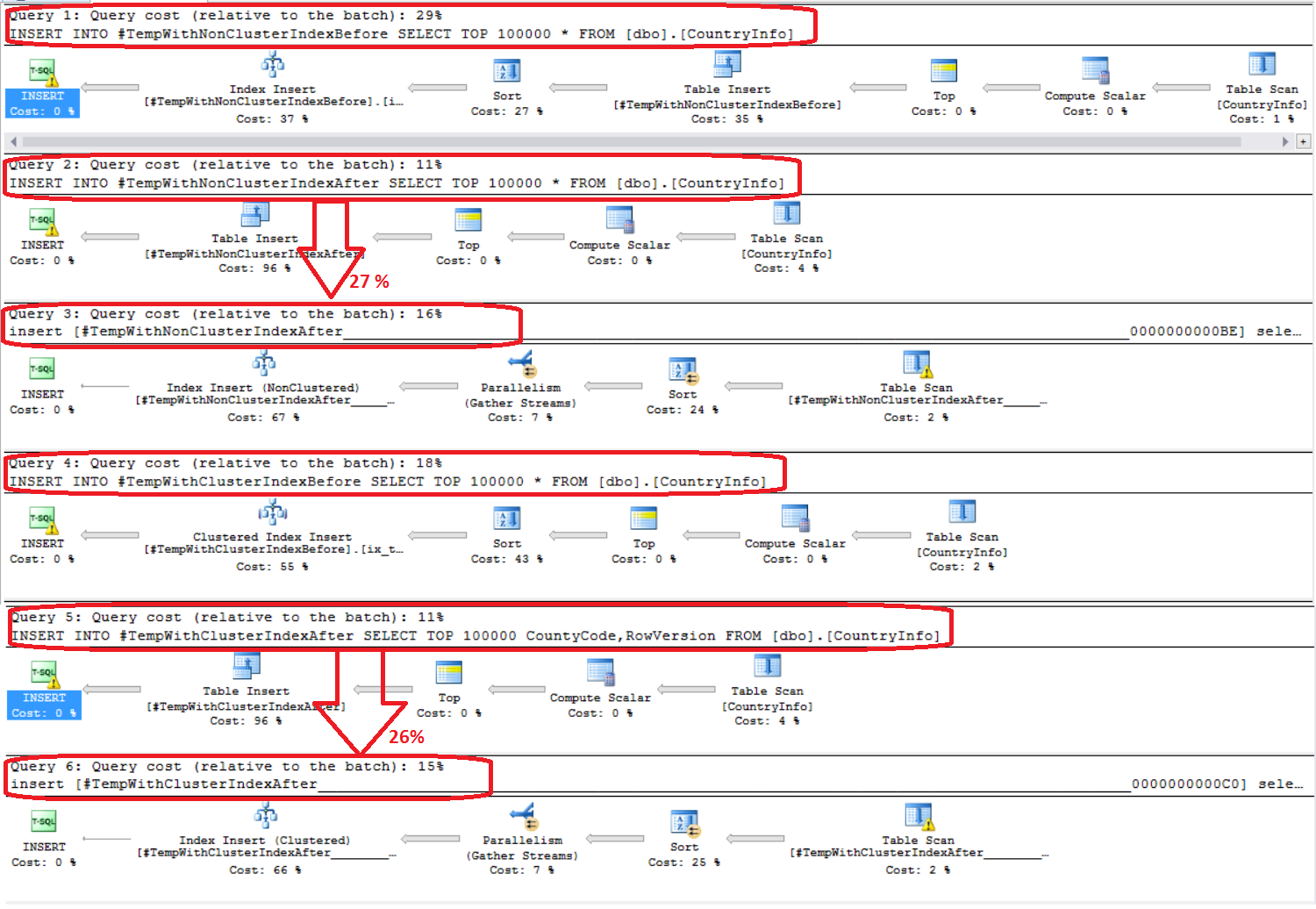
Está claro en el resultado generado de ejecutar el script previo que es mejor crear el índice no agrupado después de llenar la tabla, ya que es 1.2% más rápido, y crear el índice agrupado después de llenar la tabla, ya que es 2.5% más rápido, debido al mecanismo que es usado para llenar las tablas y crear los índices:

Revisando el plan de ejecución, el resultado no mostrará que crear el índice agrupado antes de la inserción consume 18% de toda la ejecución, cuando crearlo después de la inserción consumirá 26% de toda la ejecución. Por un lado, crear los índices no agrupado después de la inserción consume 27% de recursos comparado con el 29% que es consumido creándolo antes del proceso de inserción:
Conclusión
En SQL Server, las tablas temporales que son almacenadas en la base de datos TempDB son ampliamente usadas para proveer un lugar apropiado para el procesamiento intermedio de datos antes de grabar el resultado a la tabla base. También son usadas para acortar la duración de transacciones de ejecución larga con un bloqueo mínimo de tablas base tomando los datos, procesándolos y finalmente abriendo una transacción para realizar el cambio en la tabla base. Este enfoque es aplicable para añadir índices agrupados y no agrupados a las tablas temporales, los cuales pueden mejorar el desempeño en recuperar datos de estas tablas si los índices son elegidos correctamente.
Enlaces útiles
- TempDB:: Variable de tabla versus tabla temporal local
- Controlando el comportamiento de Autostat (AUTO_UPDATE_STATISTICS) en SQL Server
- CREATE INDEX (Transact-SQL)
- Crear índices no agrupados
- DECLARE @local_variable (Transact-SQL)

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019