
What are SQL Server statistics?
SQL Server statistics are a collection of distinct values in a specific table column or columns, collected by SQL Server by sampling table data.
SQL Server statistics are created automatically by Query Optimizer for indexes on tables or views when the index is created. Usually, additional statistics are not needed, nor the existing ones require modification to achieve best performance.
Data sampling depends on a number of table rows and the type of information stored. For example, let’s look at a table that stores uninstallation information. The column where the uninstallation reason is saved is filled by selecting one of the options offered in the drop-down list: ‘doesn’t work as expected’, ‘bugs found during evaluation’, or ‘trial expired’. In other words, there is a limited number of possible values. Sampling this column is quick, easy, and doesn’t require a large percentage of table data to be sampled. If there are 1,000 uninstallations logged, sampling 10 to 20 records (1 to 2 percent) will provide the correct statistics, i.e. the correct number of the distinct uninstallation reasons.
If you leave a possibility to enter an optional uninstallation reason, besides these three distinct values, it is possible that users will type the uninstallation reason, such as: too expensive, too complicated to use, etc.
Let’s say that 900 out of 1,000 uninstallation reasons were selected from the drop-down list, and for the remaining 100 uninstallations, the users entered custom reasons where no two reasons are the same. That means that there are 103 distinct uninstallation reasons in the table.
Sampling 1 percent of the uninstallation records will not provide the correct statistics. It will show maximally 10 distinct values, while in fact there are 103 distinct values. Therefore, the SQL Server statistics will be inaccurate if the same sampling percentage is used.
How SQL Statistics affect SQL Server performance?
One of the parameters used in query optimization and selecting an optimal query execution plan is how unique the data is. This information is provided by SQL Server statistics.
If incorrect statistics are used, SQL Server will use wrong estimates when selecting an execution plan and select a plan that needs a lot of time to be executed.
On the other hand, when the estimated number of distinct values is correct, query execution plans chosen on these estimates will perform well.
That’s why it is important to have up-to-date information on data distribution in table columns. Statistics are created on index columns, but also on non-index columns that are used in the query predicates (WHERE, FROM, or HAVING clauses).
SQL Server statistics become inaccurate when databases are in use and many transactions occur. A typical symptom of inaccurate statistics is a query that runs well and then, without any obvious reasons, becomes very slow.
The problem troubleshooting starts with analyzing the slow query. If the difference between the estimated and actual number of rows in a query execution plan is higher than 10%, the statistics are obsolete. How the performance will be affected depends on the query and execution plan. The same obsolete statistics can have different effect on two different queries.
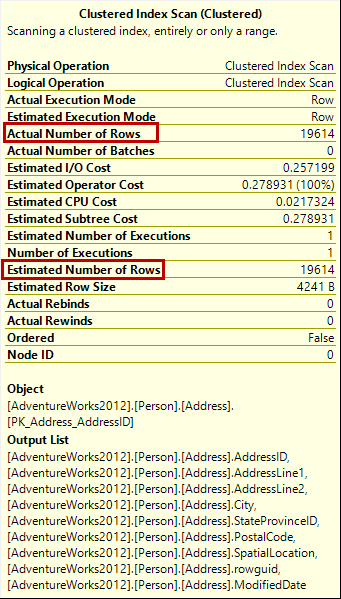
There is no dynamic management view that can indicate inaccurate statistics. We’ll show the methods for working with SQL Server statistics that can help you determine whether the statistics are obsolete or not.
Working with SQL Server statistics
SQL Server statistics are shown in SQL Server Management Studio Object Explorer, in the Statistics node for the specific table or view.
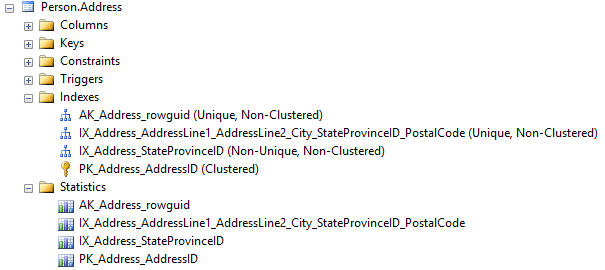
Note that each index shown in the Indexes node has a corresponding SQL Server statistics.
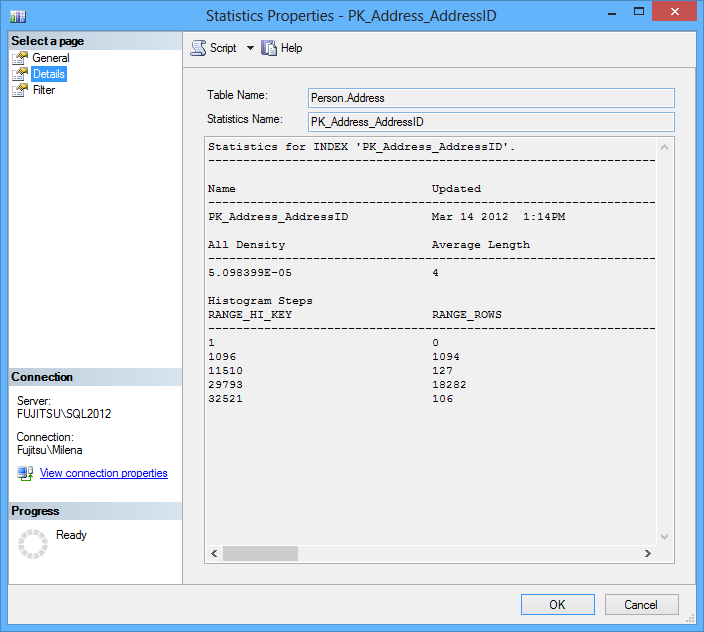
Double-clicking the statistics opens the SQL Server statistics properties.

Besides seeing SQL Server statistics for the specific index column, this dialog enables statistics modification by adding and removing the statistics columns (which is recommended only for advanced users) and updating the statistics.
The Details tab shows more detailed info.
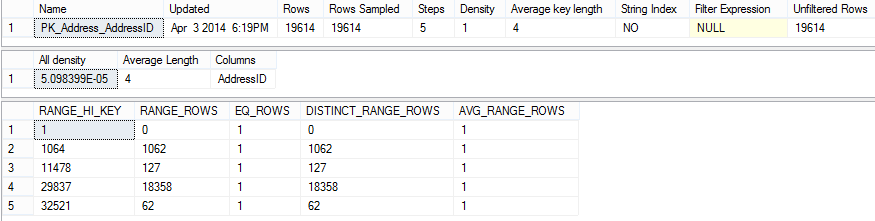
All density is calculated as 1/total number of distinct rows. In this example, where the statistics is created for the identity AddressID column, all column values are distinct, so the number of table rows is equal to the number of distinct rows, and the density is:
1/19,614 = 0.00005098099 = 5.098399102681758e-5
Average length is shown in bytes and it represents the space needed to store a list of the column values.
RANGE_HI_KEY shows the upper bound column value for a histogram step.
RANGE_ROWS shows an estimated number of rows for which the value falls within a histogram step.
In this example, there are zero rows that have key value lower than 1; 1,094 rows with values between 1 and 1,096; 127 rows with values between 11,510 and 1,096, etc.
For testing purposes, you can use a query such as
|
1 2 3 4 |
SELECT Count (*) FROM Person.Address WHERE AddressID < 11510 and AddressID > 1096 |
The information shown in the Statistics Properties dialog can also be obtained using the DBCC SHOW_STATISTICS command.
|
1 2 3 |
DBCC SHOW_STATISTICS ("Person.Address", PK_Address_AddressID); |
As already explained, Query Analyzer automatically creates index statistics when a table or view index is created. To create statistics for a non-index column used in a query predicate, make sure that the database AUTO_CREATE_STATISTICS option to on. The default option value is True
In SQL Server Management Studio:
- In Object Explorer right-click the database
- In the context menu, select Properties
- Open the Options tab
- In the Automatic section, change the Auto Create Statistics option value
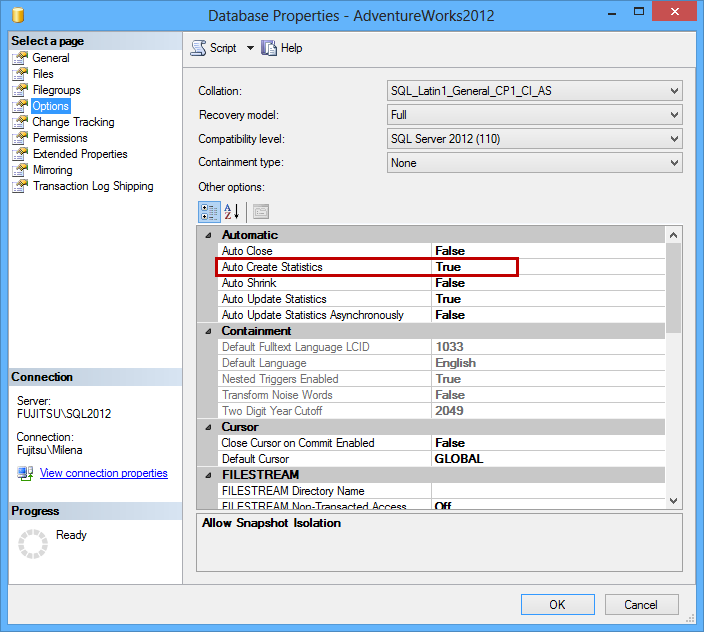
The same can be done using T-SQL
|
1 2 3 4 |
ALTER DATABASE AdventureWorks SET AUTO_CREATE_STATISTICS ON |
sp_autostats is a stored procedure that shows the automatic statistics update parameter value, for a table, index, statistics object, or indexed view.
|
1 2 3 |
EXEC sp_autostats [Person.Address] |

The information shown is the same as in the Statistics Properties dialog shown above.
The same stored procedure can also be used to change the automatic statistics update parameter value. To disable the AUTO_UPDATE_STATISTICS option for all statistics on the Person.Address table execute.
|
1 2 3 |
EXEC sp_autostats 'Person.Address', 'OFF' |
The result is the same as when using SET AUTO_CREATE_STATISTICS ON, as shown in the example above.
The Stats_Date function shows the date of the most recent statistics update. In the following example, we will use it on the records obtained from the sys.stats catalog view that contains a row for every SQL Server statistics in the database.
Querying just the sys.stats view doesn’t return useful information.
|
1 2 3 4 |
SELECT * FROM sys.stats |
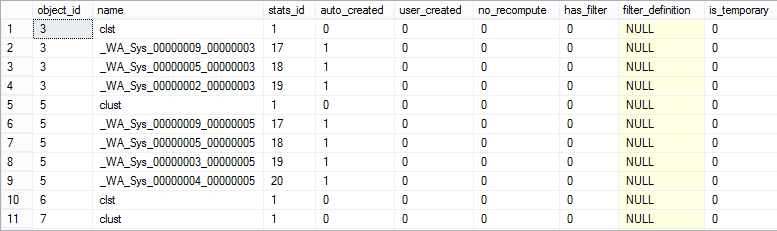
Using the Stats_Date function on the specific table or view object ID provides the date and time of the most recent statistics update.
|
1 2 3 4 5 |
SELECT name, STATS_DATE(object_id, stats_id) as LastUpdated FROM sys.stats WHERE object_id = OBJECT_ID('Person.Address'); |
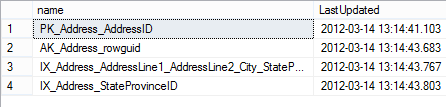
Although this information looks more useful at a first glance, it still doesn’t tell much. It doesn’t show whether the statistics are obsolete or not. The same last date can indicate valid statistics for some tables and obsolete for others. It depends on data changes that occurred after the last statistics update.
In this article, we explained what SQL Server statistics were, why and how they affect SQL Server performance, and how to see, modify, or update them. In the next part of this article, we will give recommendations for preventing SQL Server performance problems caused by inaccurate SQL Server statistics.

She has been working with SQL Server since 2005 and has experience with SQL 2000 through SQL 2014.
Her favorite SQL Server topics are SQL Server disaster recovery, auditing, and performance monitoring.
View all posts by Milena "Millie" Petrovic
- Using custom reports to improve performance reporting in SQL Server 2014 – running and modifying the reports - September 12, 2014
- Using custom reports to improve performance reporting in SQL Server 2014 – the basics - September 8, 2014
- Performance Dashboard Reports in SQL Server 2014 - July 29, 2014