
This article is about many different SQL data types that we use when working with SQL Server. We will start with a quick overview and go through some stuff like categories of data types, what objects we can work with, and how to create our own custom data types.
SQL data types overview
To kick things off, let’s talk about what is a data type. If I had to define it, I’d say that data type determines the kind, size, and range of data that can be stored in an object. So, this brings us to a question of objects that have data types:
- Columns
- Variables
- Expressions
- Parameters
These four SQL data types of objects are of the highest importance. Columns are obviously for tables. Every time we create a variable, we also need to assign a data type to it. In addition to those, we have expressions and parameters to conclude the list of objects that are going to hold data and therefore we need to specify what kind of data they will contain.
Moving on, let’s see the three categories of data types:
- Built-in data types
- User-defined alias data types
- User-defined common language runtime (CLR) data types
There is not much to say about the first category. These are data types that we’re all used to. Below is a chart that lists well known built-in data types and their ranges:
Data category | SQL data type | Size | Value range |
Exact numeric | Bit | 1 | 1, 0, or NULL |
Tinyint | 1 | 0 to 255 | |
Smallint | 2 | -2^15 (-32,768) to 2^15-1 (32,767) | |
Int | 4 | -2^31 (-2,147,483,648) to 2^31-1 (2,147,483,647) | |
Bigint | 8 | -2^63 (-9,223,372,036,854,775,808) to 2^63-1 (9,223,372,036,854,775,807) | |
Smallmoney | 4 | – 214,748.3648 to 214,748.3647 | |
Money | 8 | -922,337,203,685,477.5808 to 922,337,203,685,477.5807 | |
numeric[ (p[ ,s] )] | 5-17 | ||
decimal [ (p[ ,s] )] | 5-17 | ||
Approximate numeric | Float | 4-8 | – 1.79E+308 to -2.23E-308, 0 and 2.23E-308 to 1.79E+308 |
Real/float(24) | 4 | – 3.40E + 38 to -1.18E – 38, 0 and 1.18E – 38 to 3.40E + 38 | |
Character strings | char [ ( N ) ] | N | N = 1 to 8000 non-Unicode characters bytes |
nvarchar [ ( N | max ) ] | N or 2^31-1 | N = 1 to 8000 non-Unicode characters bytes Max = 2^31-1 bytes (2 GB) non-Unicode characters bytes | |
Text | 2^31-1 | 1 to 2^31-1 (2,147,483,647) non-Unicode characters bytes | |
Unicode character strings | nchar [ ( N ) ] | N | N = 1 to 4000 UNICODE UCS-2 bytes |
nvarchar [ ( N | max ) ] | N or 2^31-1 | N = 1 to 4000 UNICODE UCS-2 bytes 1 to 2^31-1 (2,147,483,647) UNICODE UCS-2 bytes | |
Ntext | 2^30-1 | Maximum size 2^30 – 1 (1,073,741,823) bytes | |
Binary strings | binary [ ( N ) ] | N | N = 1 to 8000 bytes |
varbinary [ ( N | max) ] | N or 2^31-1 | N = 1 to 8000 bytes Max = 0 to 2^31-1 bytes | |
Image | 2^31-1 | 0 to 2^31-1 (2,147,483,647) bytes | |
Other data types | Uniqueidentifier | 16 | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (hex decimal) |
Timestamp | 8 | binary(8) or varbinary(8) | |
rowversion | 8 | binary(8) or varbinary(8) | |
xml | 2^31-1 | xml( [ CONTENT | DOCUMENT ] xml_schema_collection ) | |
sql_variant | 8016 | data type that stores values of various SQL Server-supported data types | |
Hierarchyid | 892 | 6*logAn bits where n is child node | |
Cursor | |||
Table | |||
Sysname | 256 | ||
Date and time | Date | 3 | 0001-01-01 through 9999-12-31 |
time [ (fractional second precision) ] | 3 to 5 | 00:00:00.0000000 through 23:59:59.9999999 | |
Smalldatetime | 4 | Date: 1900-01-01 through 2079-06-06 Time: 00:00:00 through 23:59:59 | |
Datetime | 8 | Date: January 1, 1753, through December 31, 9999 Time: 00:00:00 through 23:59:59.997 | |
datetime2 [ (fractional seconds precision) ] | 6 to 8 | Date: 0001-01-01 through 9999-12-31 Time: 00:00:00 through 23:59:59.9999999 | |
datetimeoffset [ (fractional seconds precision) ] | 8 to 10 | Date: 0001-01-01 through 9999-12-31 Time: 00:00:00 through 23:59:59.9999999 Time zone offset: -14:00 through +14:00 | |
Spatial | Geography | 2^31-1 | |
Geometry | 2^31-1 |
- Note: Text, Ntext, and Image SQL data type will be removed in a future version of SQL Server. It is advisable to avoid using these data types in new development work. Use varchar(max), nvarchar(max), and varbinary(max) data types instead.
Next, we have what we mentioned at the beginning, and those are user-defined alias data types that allow us to create our own data types based on the built-in list above.
The last category is user-defined common language runtime (CLR) data types that allow us to create our own data types using the .NET Framework. This is a bit more complicated than the above and requires programming skills to build an assembly, register that assembly inside the SQL Server, create a new SQL data type based on that assembly and then we can start using the newly created data type in SQL Server.
SQL data types considerations
Let’s move on to the next section which is basically just theory, but definitely something that you should think about when storing data either permanently or temporarily.
Conversion
As a database developer, one of the most common routines when writing code is converting. Conversion takes place when data from an object is moved, compared or combined with data from another object. These conversions may happen automatically, what we call Implicit conversion in SQL Server or manually that is known as Explicit conversion which basically means writing code specifically to do something. A useful rule of thumb is that explicit conversion is always better than implicit conversion because it makes code more readable. Now that we’re talking about conversions, also worth mentioning is the stuff that can help us out with the explicit conversion like CAST and CONVERT functions used to convert an expression of one SQL data type to another.
GUID
GUID is an acronym for Globally Unique Identifier. It is a way to guarantee uniqueness and it’s one of the biggest SQL data types. The only downside of GUID is the 16 bytes in size. Therefore, avoid indexes on GUIDs as much as possible.
NULL vs. NOT NULL
If you stick with SQL Server defaults, that could lead to some data integrity issues. You should always try to specify the nullability property whenever you’re defining columns in tables. Back to the basics, null means unknown or missing which basically means it’s not 0 or an empty string, and we cannot do the null comparison. We cannot say null = null. This is a no can do. There’s a property called ANSI_NULLS that we can set and control this comparison with null values.
Sparse columns
This type of column is just a regular column in SQL Server except for a property that is set to on and it tells SQL Server to optimize that column for null storage.
SQL data type guidelines
First of all, always use the right data type for the job. This is a lot bigger than most people think. It can have a significant impact on efficiency, performance, storage and further database development.
If we take the first two, the query optimizer is going to generate an execution plan depending on what data types are used. A very simple example could be if we’re using the bigint data type where we could be using the smallint – well then, we are most likely just slowing down the query. Choosing the right SQL data type will ultimately result in query optimizer working more efficiently.
It a good idea to provide documentation for yourself and others using the database on data types going into the objects. It goes without saying, but avoid deprecated data types, always check Microsoft’s latest documentation for the news and updates. If there’s a slight chance that you’re going to work with non-English data, always use Unicode data types. Furthermore, use the sysname data types for the administrative scripts over the nvarchar.
SQL data type examples
Let’s jump over to SSMS and see how we can work with some of the data types mentioned in the previous sections. We’ll go through conversions, sparse columns, and alias data types.
Conversion
Cast, Convert and Parse functions convert an expression of one SQL data type to another. Below is an example query that can be used on a sample “AdventureWorks” database against the “TransactionHistory” table. It’s grabbing “ProductID” and “TransactionDate” from which we can use that date of the transaction to see how conversion works:
|
1 2 3 4 5 6 |
SELECT th.ProductID, th.TransactionDate, CAST(th.TransactionDate AS NVARCHAR(30)) AS CastDate, --CAST: ANSI SQL std CONVERT(VARCHAR(10), th.TransactionDate, 110) AS ConvertDate, --CONVERT T-SQL specific PARSE('20 October 2019' AS DATETIME USING 'en-US') AS ParseDate -- Convert string to int/datetime FROM Production.TransactionHistory th; |
Here is the result set of various SQL data types:
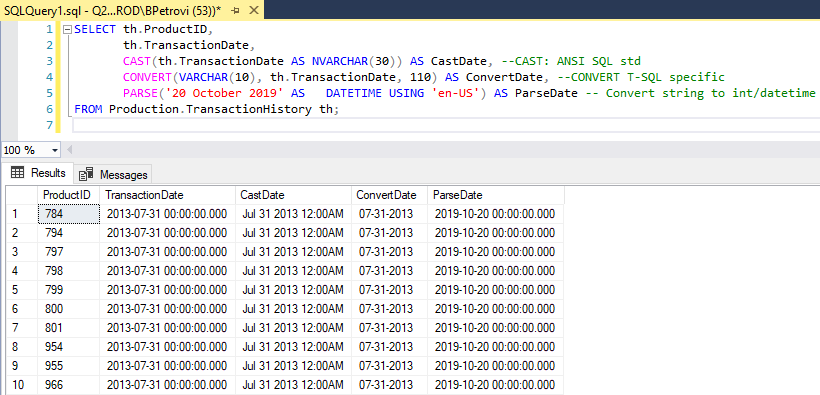
We used the Cast function against TransactionDate to convert values to a nvarchar to a length of 30. Next, we used Convert to do the same thing but then we also specified the format 110 which gives us a specific date style. Last, we used Parse which essentially works the same, but we can apply culture to it.
Let’s take a closer look at the result set and see what we got:
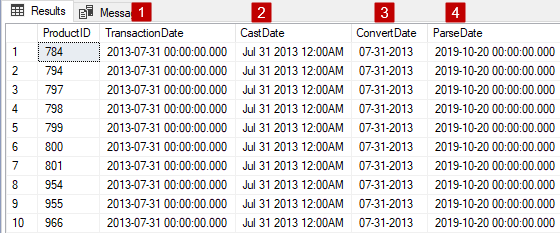
- Here we have the date and time of the transaction as it sits within the database (datetime data type)
- Here is what it looks like when we cast it as a text representation
- Converting does the same thing but in this case, we’re specifying how the Convert function will translate expression (110 = mm-dd-yyyy)
- Parsing in this case, just translates requested data using specific culture (en-US)
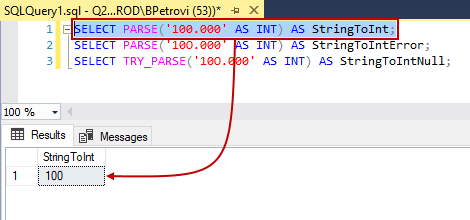
Next, let’s see some extra stuff that we can do with the Parse function. Parse is great with converting strings to dates and integers. For example, if we execute the Select statement below, it will grab the string 100.000 and turn it into an integer:
|
1 |
SELECT PARSE('100.000' AS INT) AS StringToInt; |
Here is the result set:
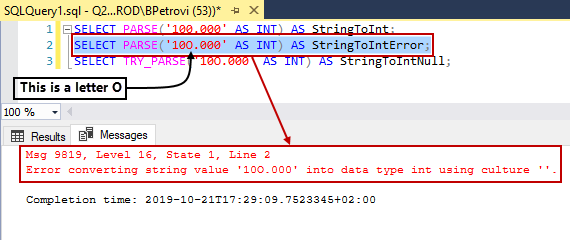
Now, let’s say that we want to do the same thing again but for some reason, the integer has a character in it that SQL Server cannot convert to an integer:
|
1 |
SELECT PARSE('10O.000' AS INT) AS StringToIntError; |
Here is the error message that it throws:
Msg 9819, Level 16, State 1, Line 2
Error converting string value ’10O.000′ into data type int using culture ”.
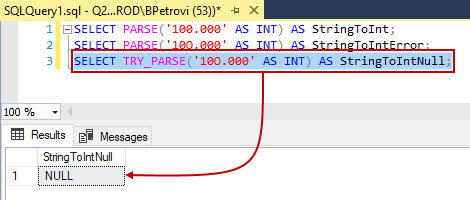
So, what we can do in this case is to use Try_Parse instead of regular Parse because if we try the same thing from above, it will return a null value rather than the error:
|
1 |
SELECT TRY_PARSE('10O.000' AS INT) AS StringToIntNull; |
Here is what it looks like:
This method can be used as an identifier if something would error out ahead of time AKA defensive coding. Tries can be applied for the other two SQL data types as well.
Sparse columns
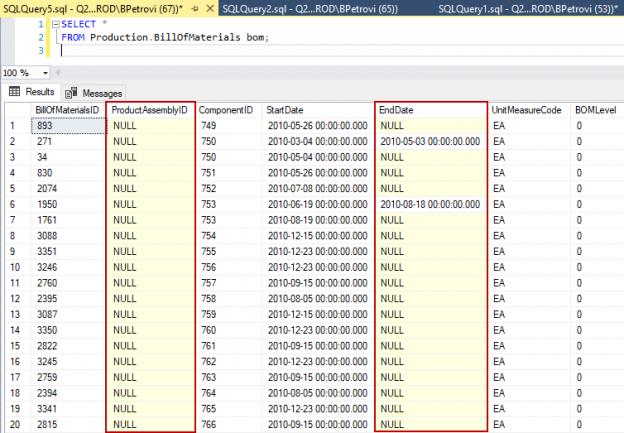
As I mentioned at the beginning, sparse columns reduce null space requirements. So, let’s jump to Object Explorer in our sample database, locate and query BillOfMaterials table to see how this works:
|
1 2 |
SELECT * FROM Production.BillOfMaterials bom; |
Notice that there are a lot of null values within the ProductAssemblyID and EndDate columns:
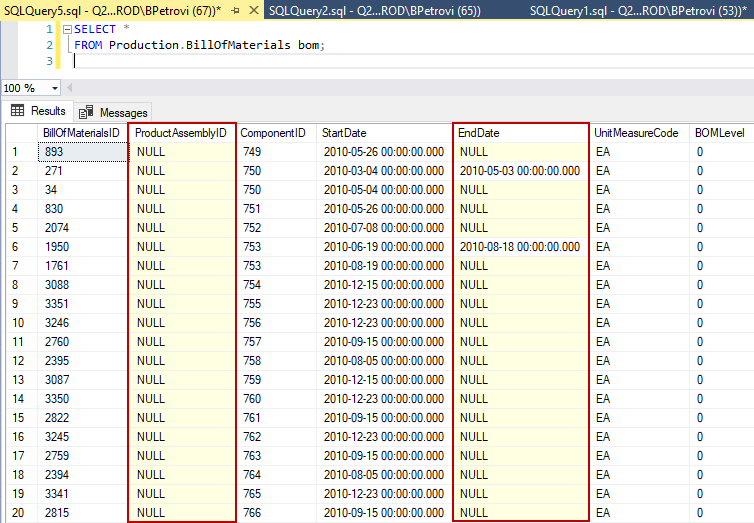
Therefore, we can say that these two are good candidates for sparse columns. So, one way to change this is to simply change the property in the designer or we can do it using the T-SQL code from below:
|
1 2 3 4 |
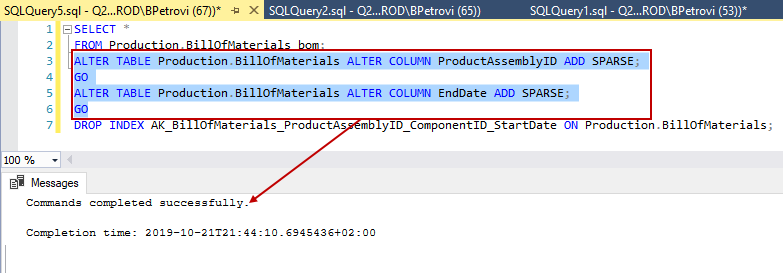
ALTER TABLE Production.BillOfMaterials ALTER COLUMN ProductAssemblyID ADD SPARSE; GO ALTER TABLE Production.BillOfMaterials ALTER COLUMN EndDate ADD SPARSE; GO |
Commands did not complete successfully the first time, so I had to lose the clustered index (line 7) and then everything went smooth:
If we go back to Object Explorer, refresh the BillOfMaterials table, we can see that those two are now marked as sparse columns:
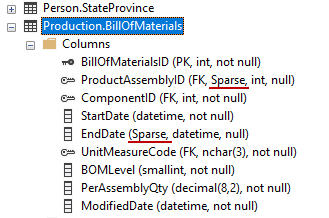
Nice, right. One more neat thing about sparse columns is called column sets. This is useful in a situation when we have a table that contains a bunch of special-purpose columns that are rarely used like in our example ProductAssemblyID and EndDate columns or AddressLine2, MiddleName, etc. So, the idea with the column set is that SQL Server will take all those columns and give us a generated XML column that is updateable. This can lead to a performance boost of the application because SQL Server can work with the column set rather than with each sparse column individually.
So, let’s add a column set using those two examples from above using the following command:
|
1 2 3 |
ALTER TABLE Production.BillOfMaterials ADD SparseColumns XML COLUMN_SET FOR ALL_SPARSE_COLUMNS; GO |
So, if we try to add a column set but our table already has sparse columns, it will error out:
Msg 1734, Level 16, State 1, Line 9
Cannot create the sparse column set ‘SparseColumns’ in the table ‘BillOfMaterials’ because the table already contains one or more sparse columns. A sparse column set cannot be added to a table if the table contains a sparse column.
If you ever come across this, the easiest workaround is to undo sparse columns. This can be easily done in the designer. Just open it up from Object Explorer, select the column that you need, and within the column properties change the Is Parse property to No as shown below:
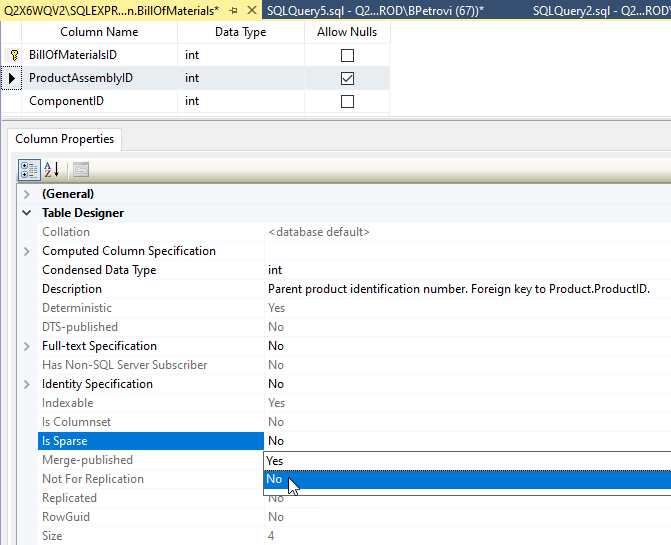
Now, if we execute the command one more time, it will be successful:
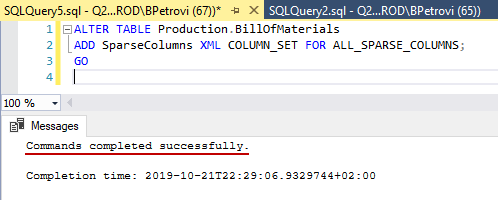
The bottom line here, don’t add sparse columns first – add column sets first and then sparse columns. That way you won’t have to do it the hard way. What’s really neat about this, our DML statements such as Select, Insert and Update can still work the old way by referencing the columns individually or we can do it using the column sets.
User-defined SQL data types
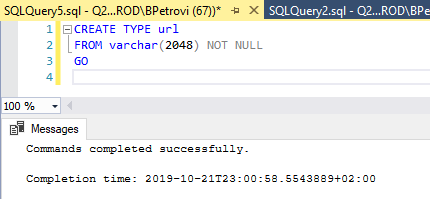
Let’s wrap things up with creating a custom data type. We’re going to create an alias data type which is based on another data type. Let’s just say that we have a need for storing URLs in our table and we want to create an actual URL data type. All we need to do is execute the code from below:
|
1 2 3 |
CREATE TYPE url FROM varchar(2048) NOT NULL GO |
URLs are just characters, so the varchar data type is perfect for this. I’ve set the max value to 2048 because of this thread that I’ve found online which states that you should keep your URLs under 2048 characters:
We can see this new SQL data type if we head over Object Explorer, under Programmability, Types, User-Defined Data Types folder:
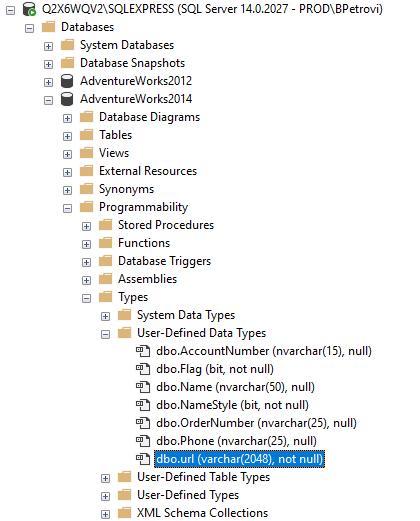
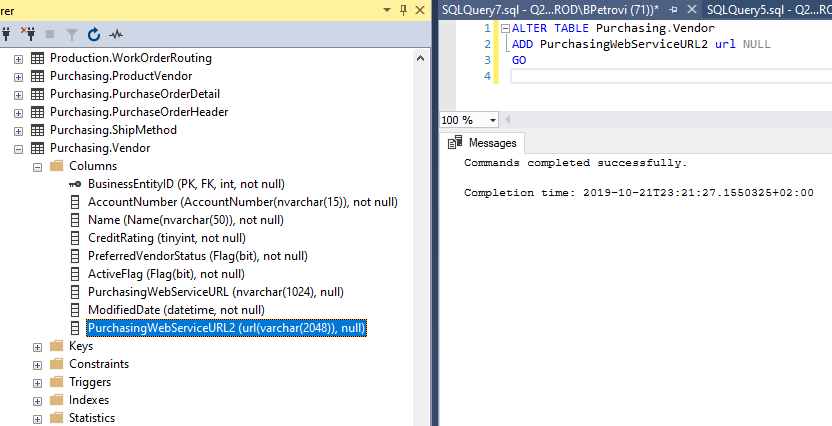
From here, we can start using the newly created data type. Just an example:
|
1 2 3 |
ALTER TABLE Purchasing.Vendor ADD PurchasingWebServiceURL2 url NULL GO |
Conclusion
In this article, we learned how to implement SQL data types. We kicked off with an overview just to get familiar with some of the built-in data types. Then we talked about some stuff to consider when working with data types and conversion using Cast, Convert and Parse functions. We also jumped into SSMS where we showed how to convert an expression of one data type to another. We went through how to work with sparse columns, and then we also saw how to create our own custom data types.
I hope this article on SQL data types has been informative for you and I thank you for reading it.

He has written extensively on both the SQL Shack and the ApexSQL Solution Center, on topics ranging from client technologies like 4K resolution and theming, error handling to index strategies, and performance monitoring.
Bojan works at ApexSQL in Nis, Serbia as an integral part of the team focusing on designing, developing, and testing the next generation of database tools including MySQL and SQL Server, and both stand-alone tools and integrations into Visual Studio, SSMS, and VSCode.
See more about Bojan at LinkedIn
View all posts by Bojan Petrovic
- Visual Studio Code for MySQL and MariaDB development - August 13, 2020
- SQL UPDATE syntax explained - July 10, 2020
- CREATE VIEW SQL: Working with indexed views in SQL Server - March 24, 2020