
This article will show how to deploy the Hyperscale (Citus) server group of Azure Database for PostgreSQL and explore its configuration options.
Introduction
Relational databases typically host data in different types of database objects on a single server. As the data volume and the data consumption needs grow, the database server is also required to scale. To meet the scalability needs, typically the first response is to increase the database capacity in terms of compute and storage. This method is known as the scale-up method. When volumes grow very large (to the scale of hundreds of gigabytes to terabytes), the scale-up methods start to reach a breakpoint or becomes a bottleneck, where a limit is reached to scale to performance. The other method often employed and is also considered as one of the most efficient methods for scalability, is the scale-out method. In this approach, data is distributed across a group of servers also known as nodes which participate as a member of a cluster. As the scalability requirements increase, more nodes can be added as well as removed from this cluster to meet the performance requirements. As these nodes keep scaling up and down elastically, the database management system or software needs to be able to manage data distribution across these nodes (also known as sharding).
PostgreSQL is an open-source and one of the most popular relational databases that are typically used for OLTP systems. One important feature of this database is that it’s supported by a large community, and with it comes several extensions that can be applied on the PostgreSQL server to use it for a variety of different applications. Examples of such extensions are AppOS, HypoPG, OpenFTS, PostGIS, TimescaleDB (PostgreSQL for time-series), etc.
One such PostgreSQL extension is Citus – which transforms PostgreSQL into a distributed database that enables usage of Postgres in a scale-out or cluster model. With Citus, the PostgreSQL server can be used for high transaction throughputs, processing time-series or IoT data, building analytical warehouses as well as for real-time analytics. Managing such dynamic infrastructure on which PostgreSQL, as well as Citus extension operates, can be quite challenging. Azure recently launched the Citus flavor of PostgreSQL in the form of Azure Database for PostgreSQL – Hyperscale server group. This can be compared to the likes of Azure Synapse or AWS Redshift. In this article, we will learn how to deploy the Hyperscale server group of the Azure Database for PostgreSQL and explore its configuration options.
Deploying Azure Database for PostgreSQL – Citus server Model
In the preview version of the Azure Database for PostgreSQL HyperScale edition, there are several features in preview like Columnar Storage, Read Replicas, Managed pgBouncer (connection pooling), Managed pgAudit (logging), and others. One striking feature that saves cost is the ability to deploy a server group using only the coordinator node i.e. the leader node which manages other worker nodes in the server group. This allows scaling the server group as the requirements scale without incurring the upfront cost. In this exercise, we will stand up a 2-node cluster group so we can explore how nodes participate in the server group.
It’s assumed that one has required access to administer the Azure Database for PostgreSQL service. Navigate to the Azure portal and click on All Services. Under the database category, we will find Azure Database for PostgreSQL. Click on it to navigate to the dashboard page.
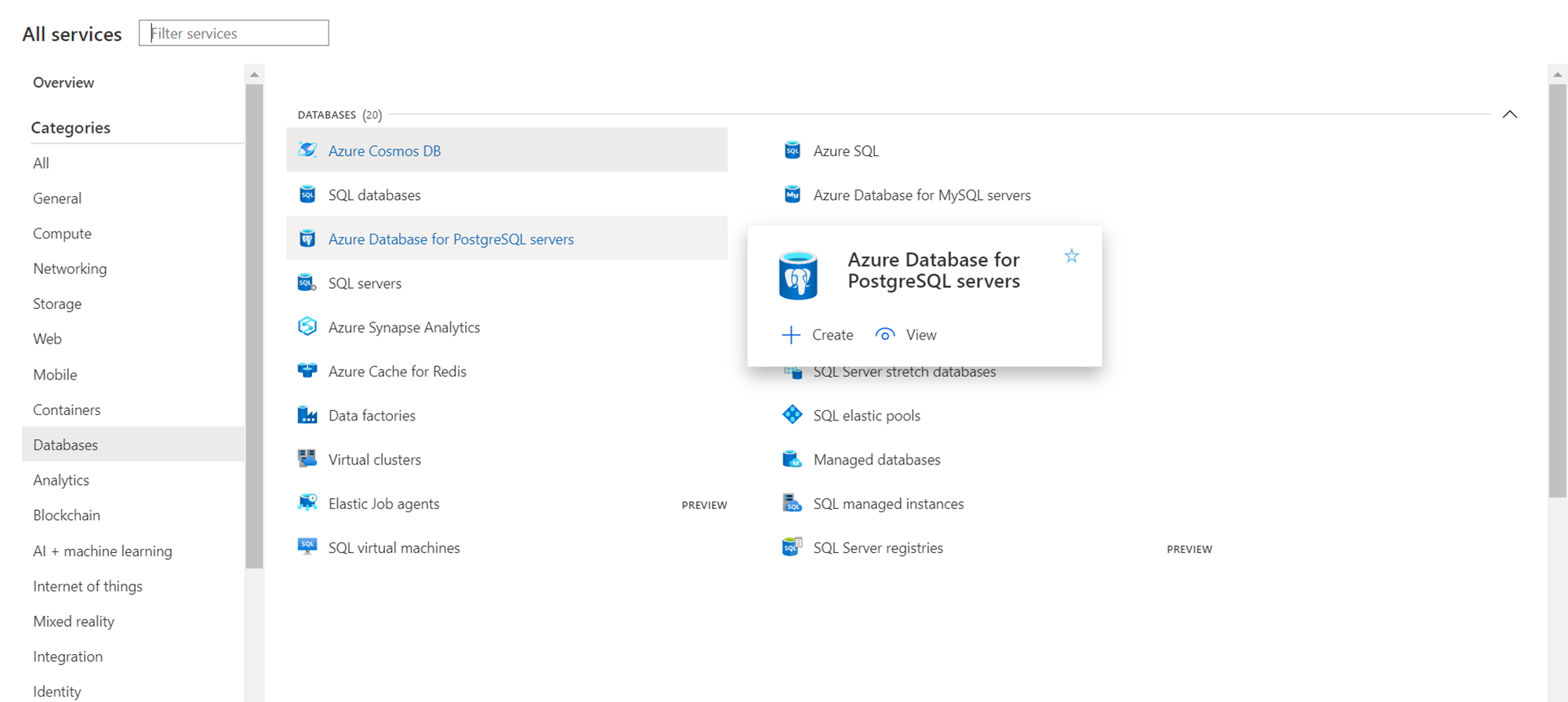
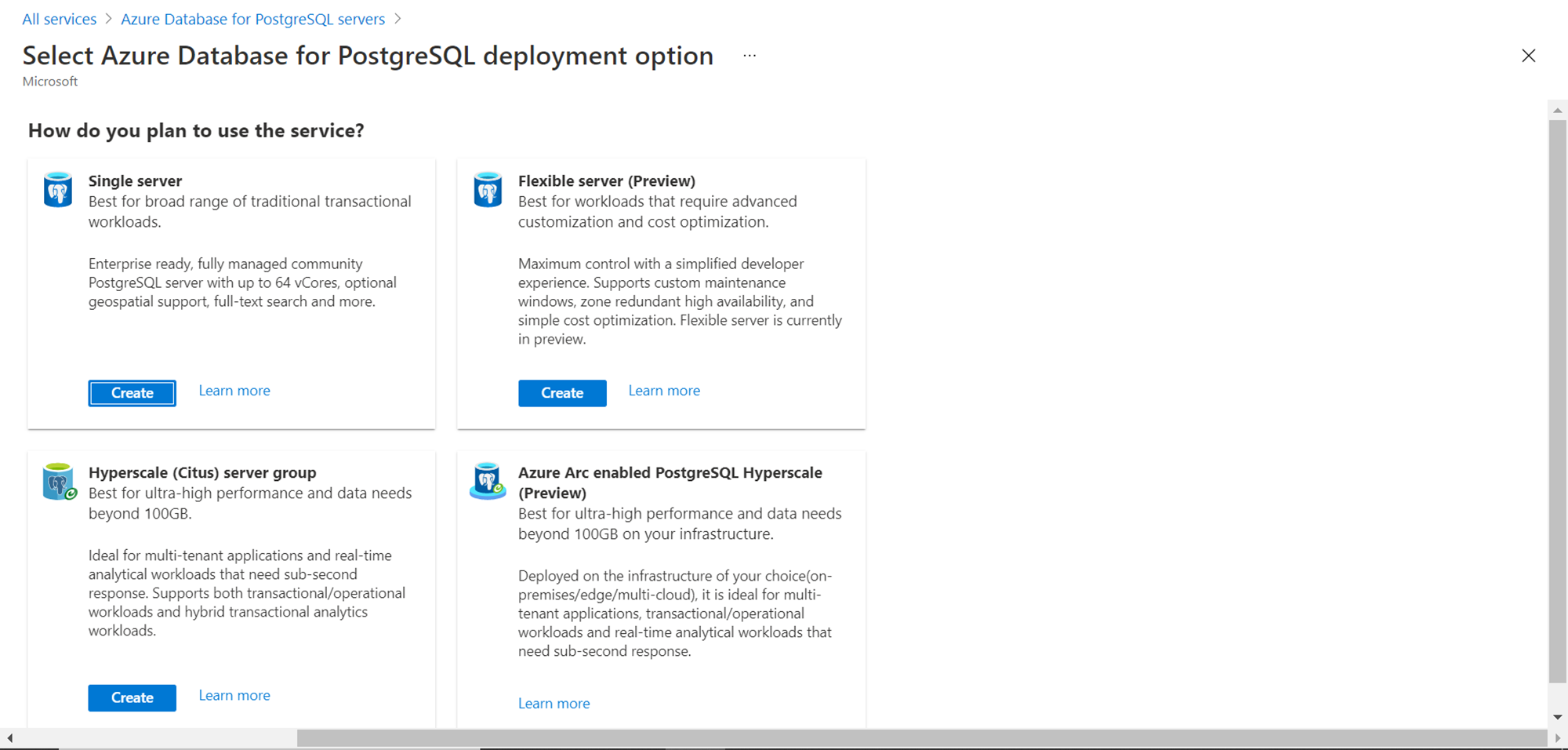
On the dashboard page, we should be able to find a button titled “Create Azure Database for PostgreSQL server”. Click on it and that would invoke a new wizard for database creation. There would be four options out of which we need Hyperscale (Citus) server group. Click on the Create button in the Hyperscale section.
On the first page, we need to fill up the basic details like the Azure Subscription as well as the Resource Group in which the server group would be hosted. If you do not have an existing resource group, consider creating a new one.
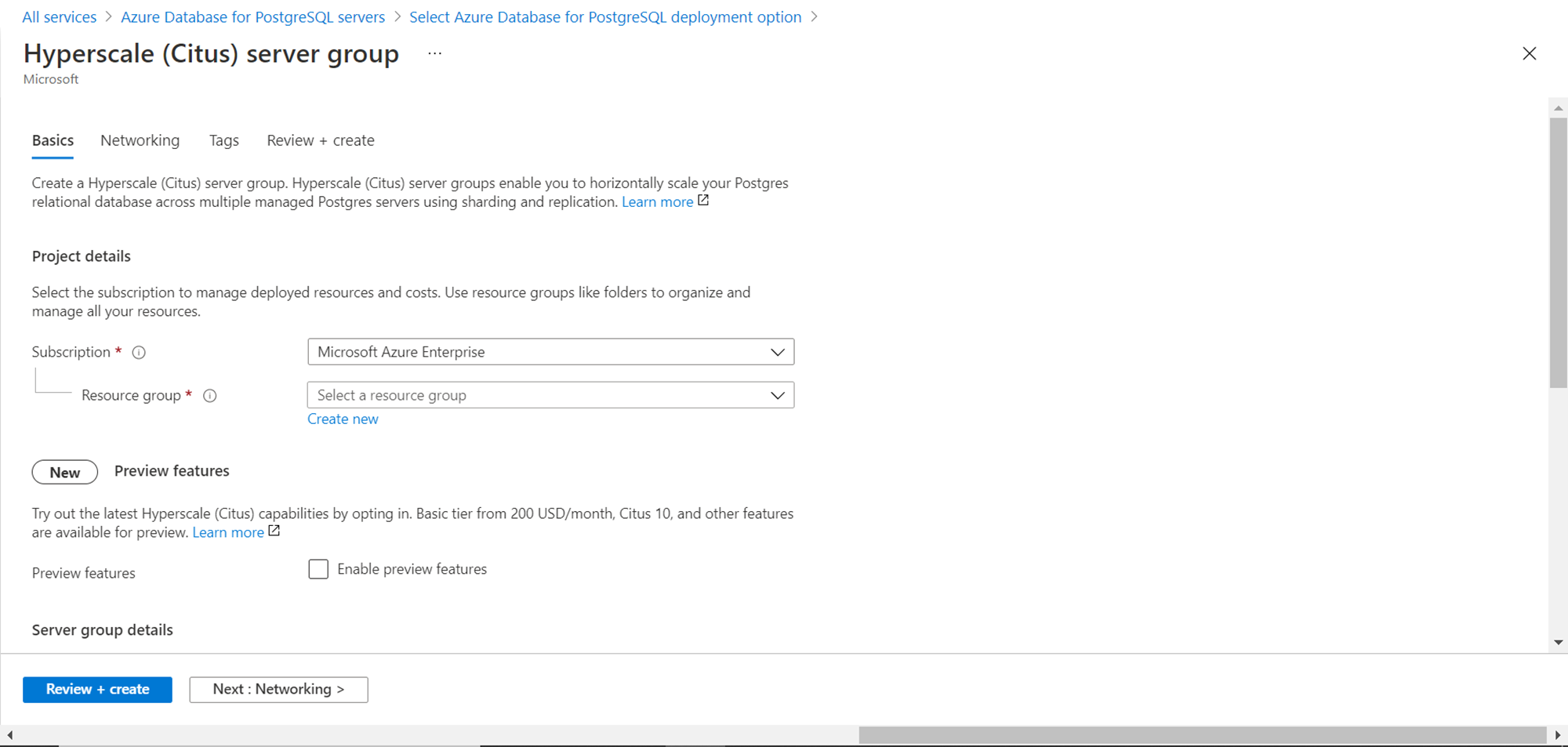
As the Hyperscale (Citus) capabilities are new, one has to opt-in for using the preview features. The basic tier without any work code i.e. with only the coordinator node would cost starting $200 per month. Click on the checkbox titled “Enable preview features”. Then we need to provide basic details for the server group like the name of the server group and the location in which the server group would be hosted. The default region is East US. The default compute + storage tier limit is up to 20 worker nodes and 1280 vCores. This is a soft limit and can be extended when required by contacting technical support. The default version as of the draft of this article is 13 but can be changed as well if required.
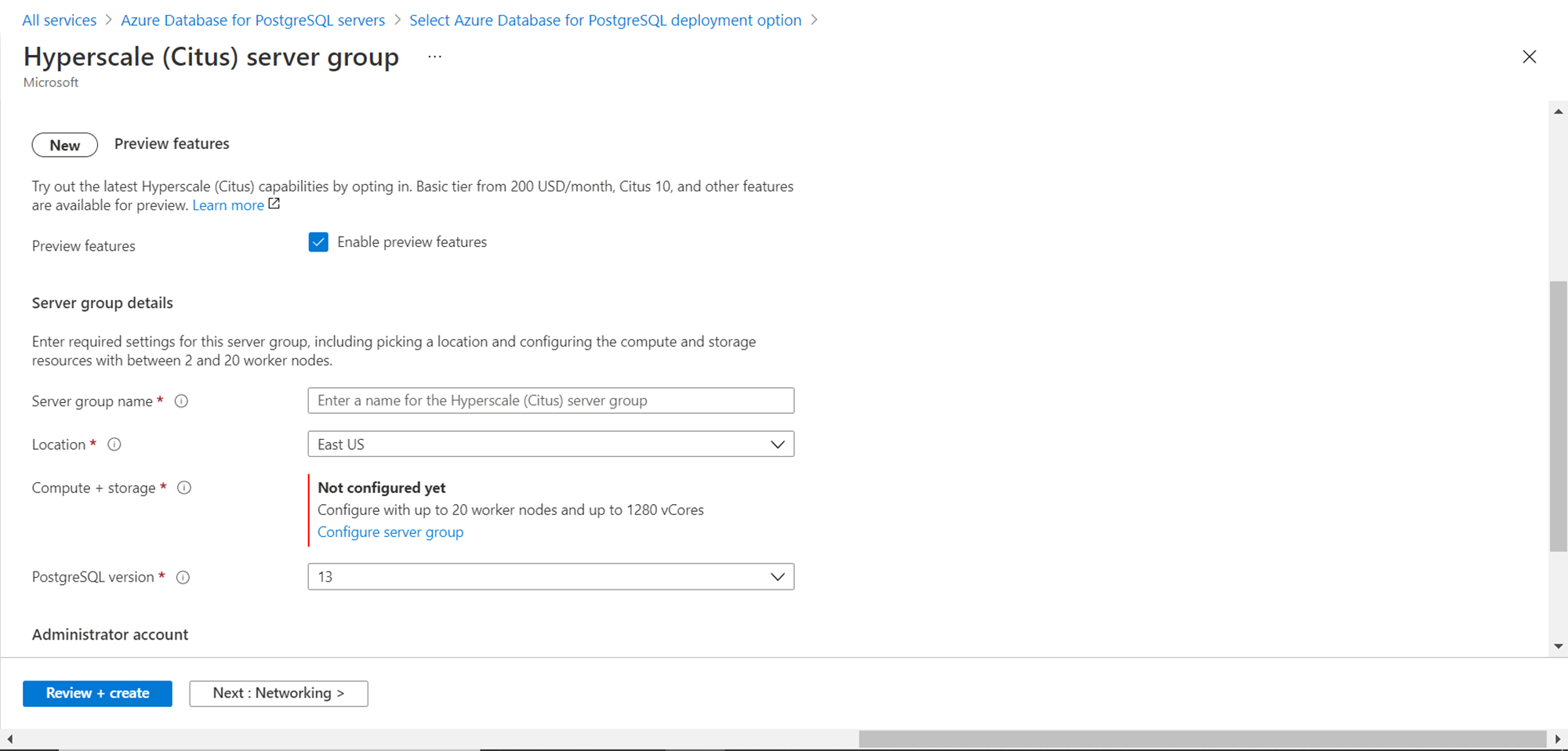
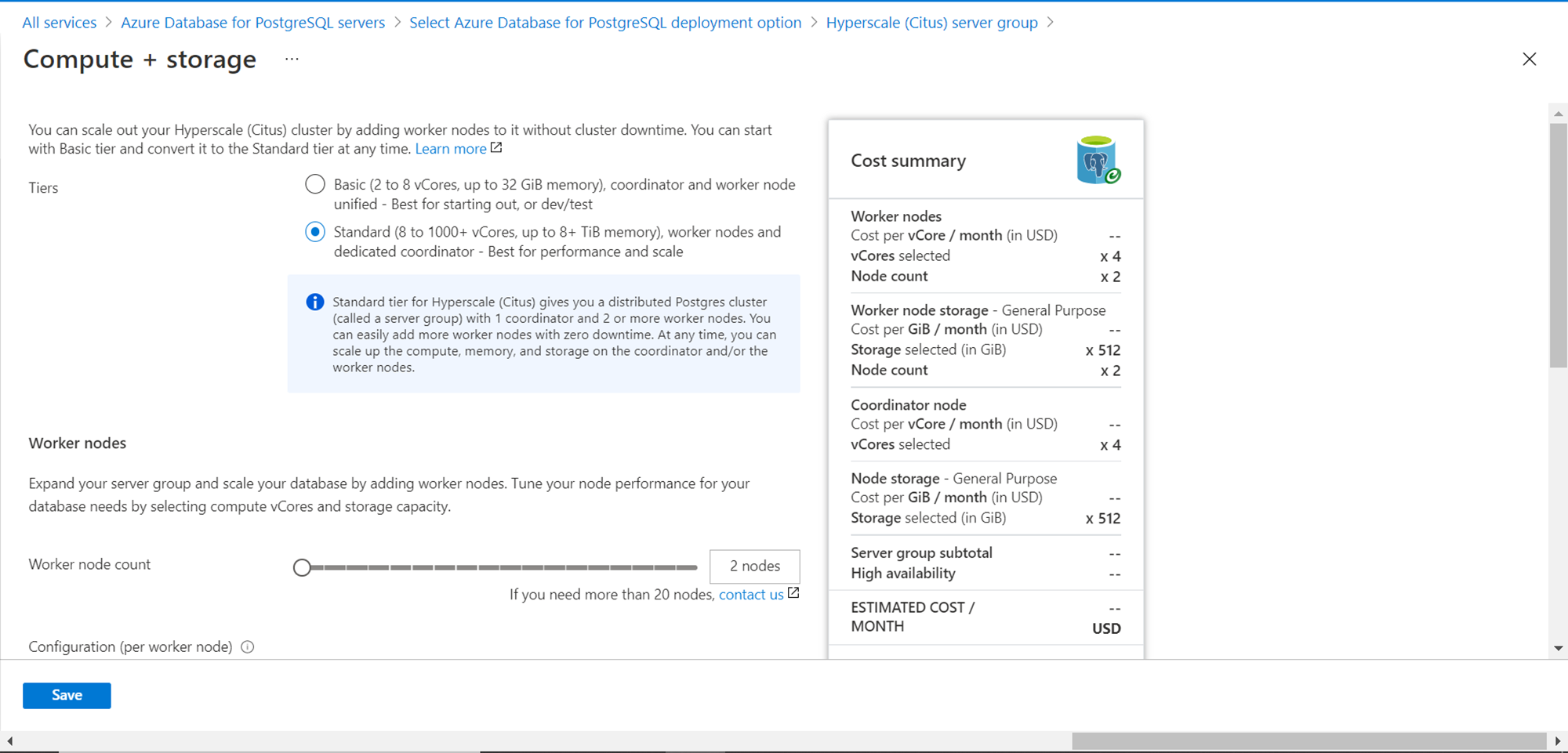
As we discussed earlier that we intend to add nodes to the server group as creating a server group without any nodes would mimic a single server or flexible server model. So, we need to change the compute + storage tier. Click on the link titled configure server group and it will look as shown below. Select the standard tier instead of the basic tier by selecting the corresponding option button. The basic tier has a limit of 2 to 8 vcores and up to 32 GiB memory, while the standard tier supports 8 to 1000 vcores. The worker node section shows the value of 2 which means that two worker nodes are part of the server group.
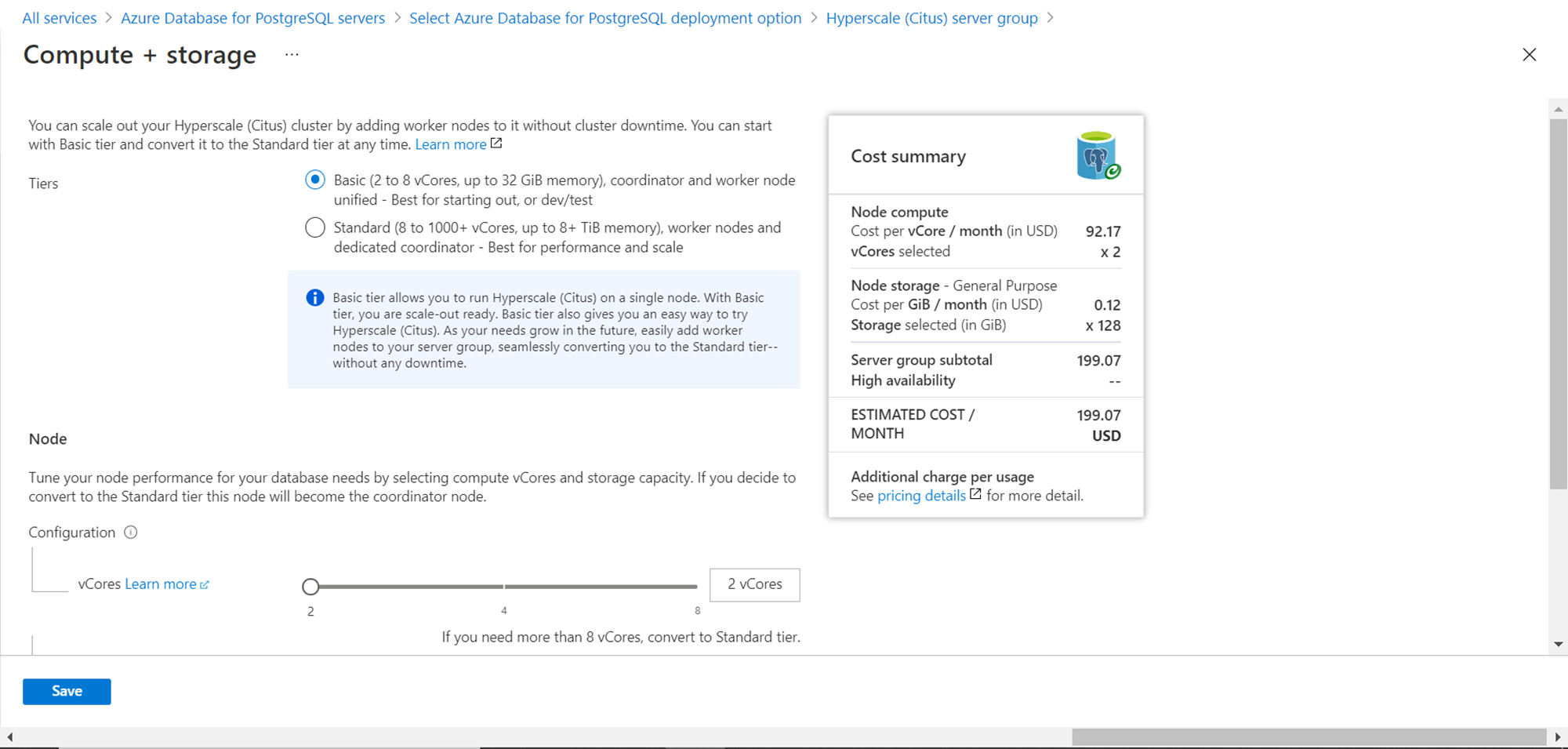
Switch back to the Basic tier and ensure that the cost is approximately $200 per month. We are going to keep this setup for a fraction of a time so it would not cost that much.
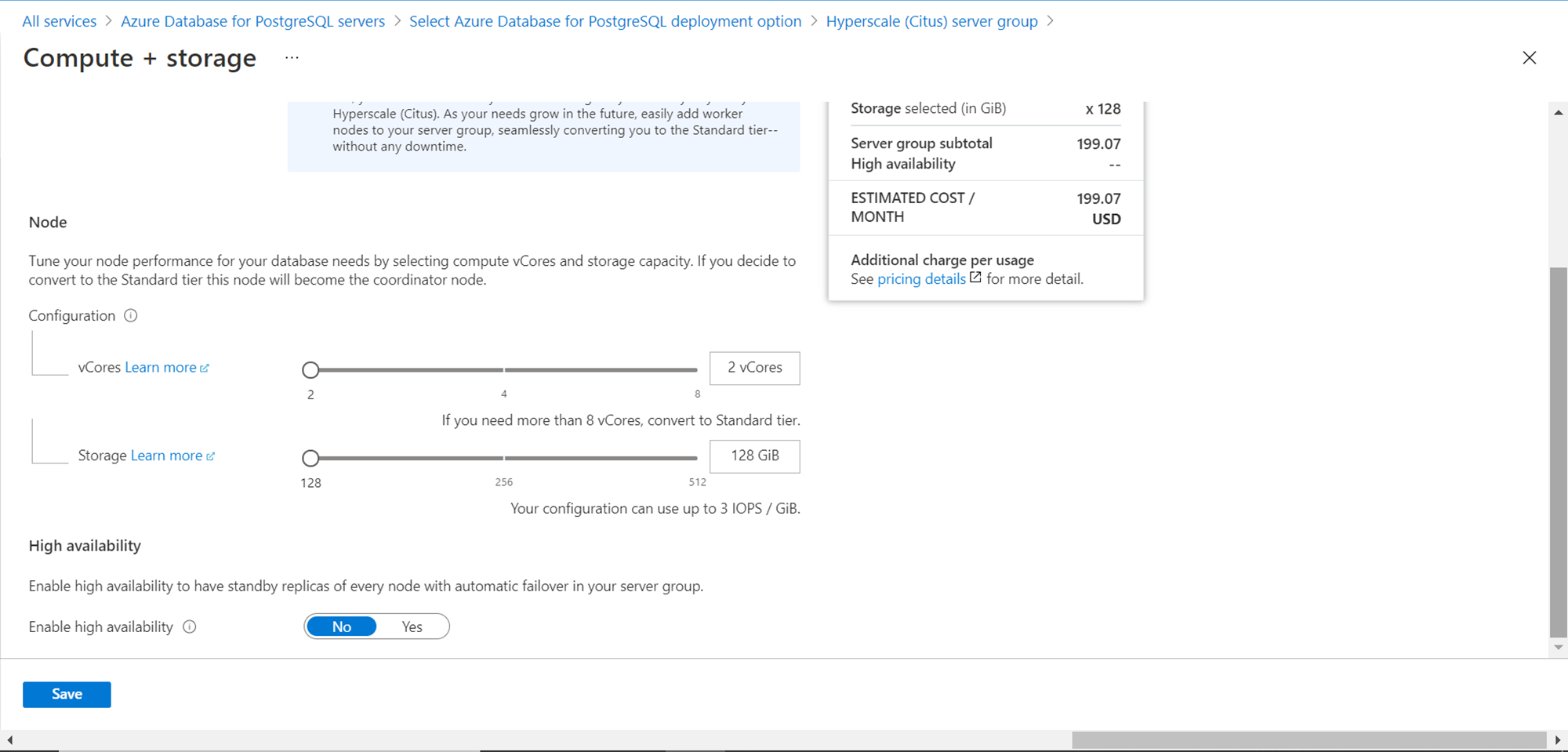
Scroll down and review the configuration details. With 2 nodes we would get 128 GiB storage per node. We have the option to turn on high availability as well. This will result in the creation of standby replicas with automatic node failover in the server group.
After saving this configuration, the next step is configuring the Network details. We will continue with the default Public access connectivity and add out client IP to the firewall rules so we can access this instance from any IDE like pgAdmin from the local machine.
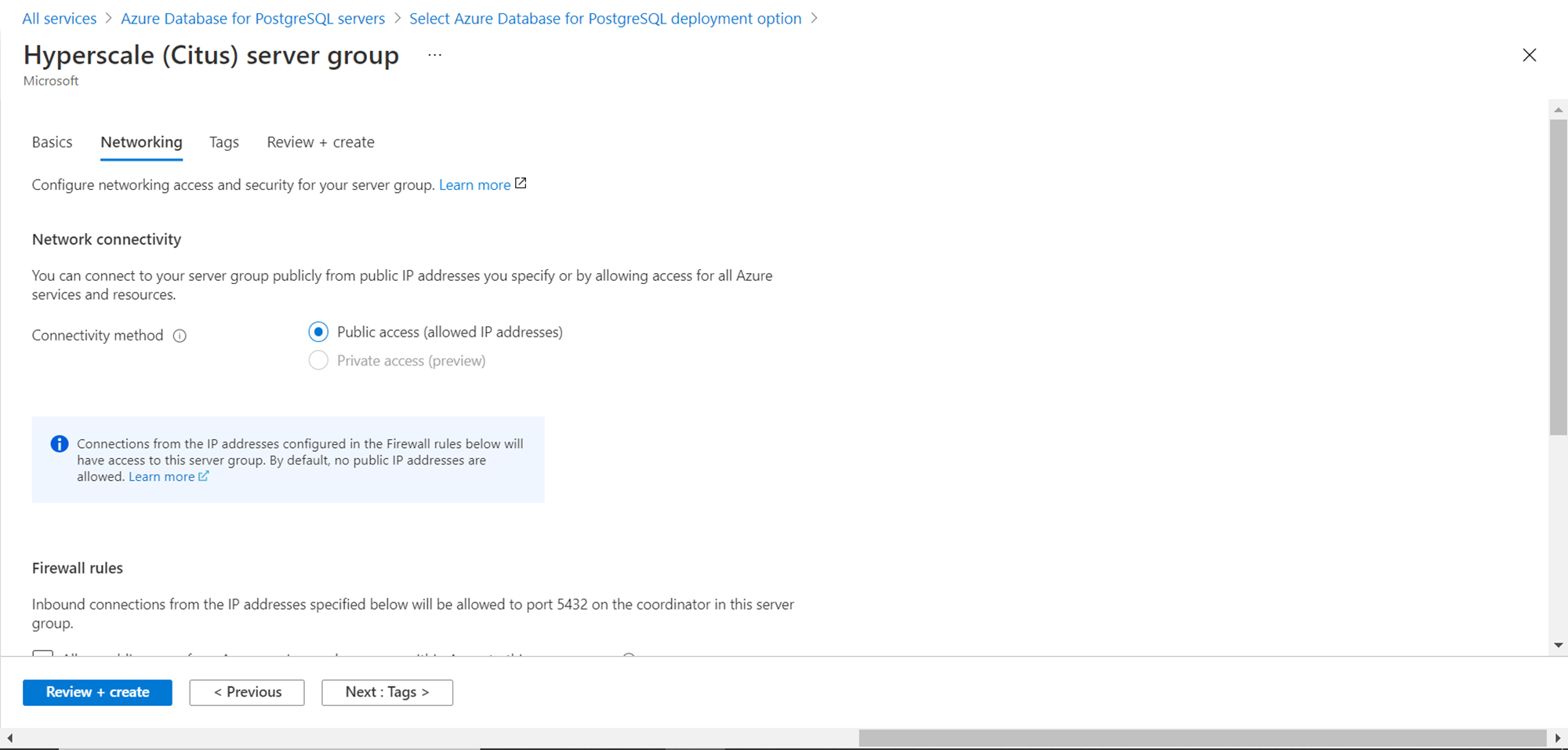
Once we are done with the Networking section, we can move on to the Tags section. As it is an optional section, we can skip it and move on to the Review section as shown below. Review all the details especially the estimated cost and then click on the Create button.
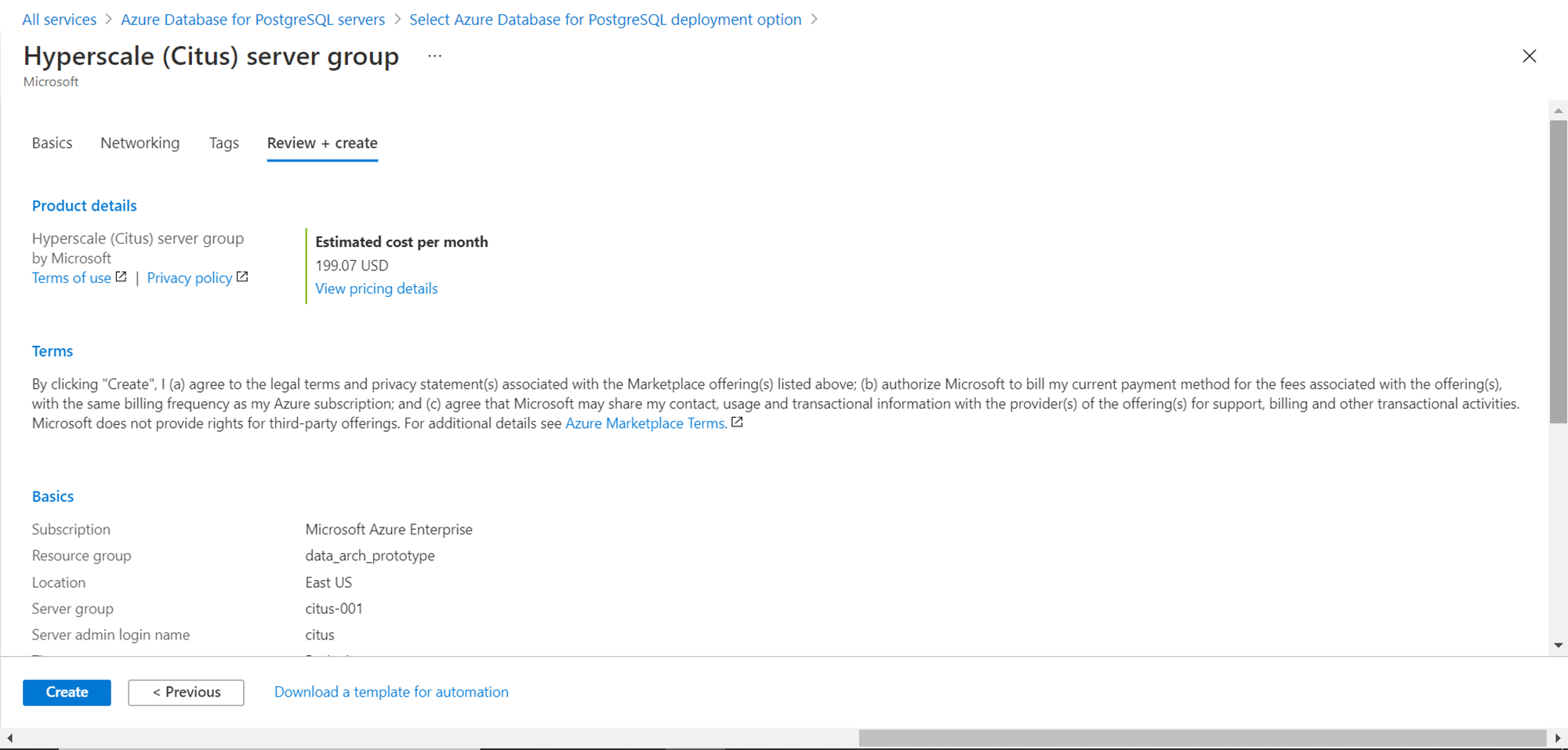
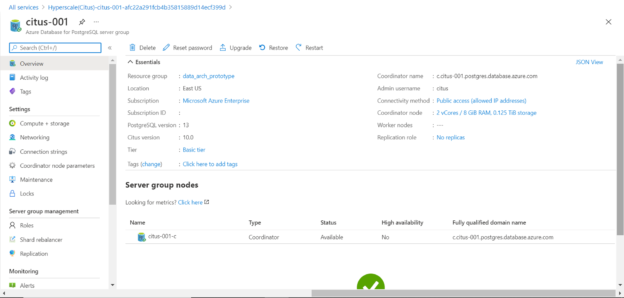
Keep in view that it can take a few minutes before the server group is created and becomes accessible. Once the deployment is successful; we can navigate to the dashboard of the instance as shown below. If we glance over the menu on the left-hand pane, we can find some unique sections like Shard rebalancer, Coordinator node parameters, etc. which are unique to this model of Azure Database for PostgreSQL Server.
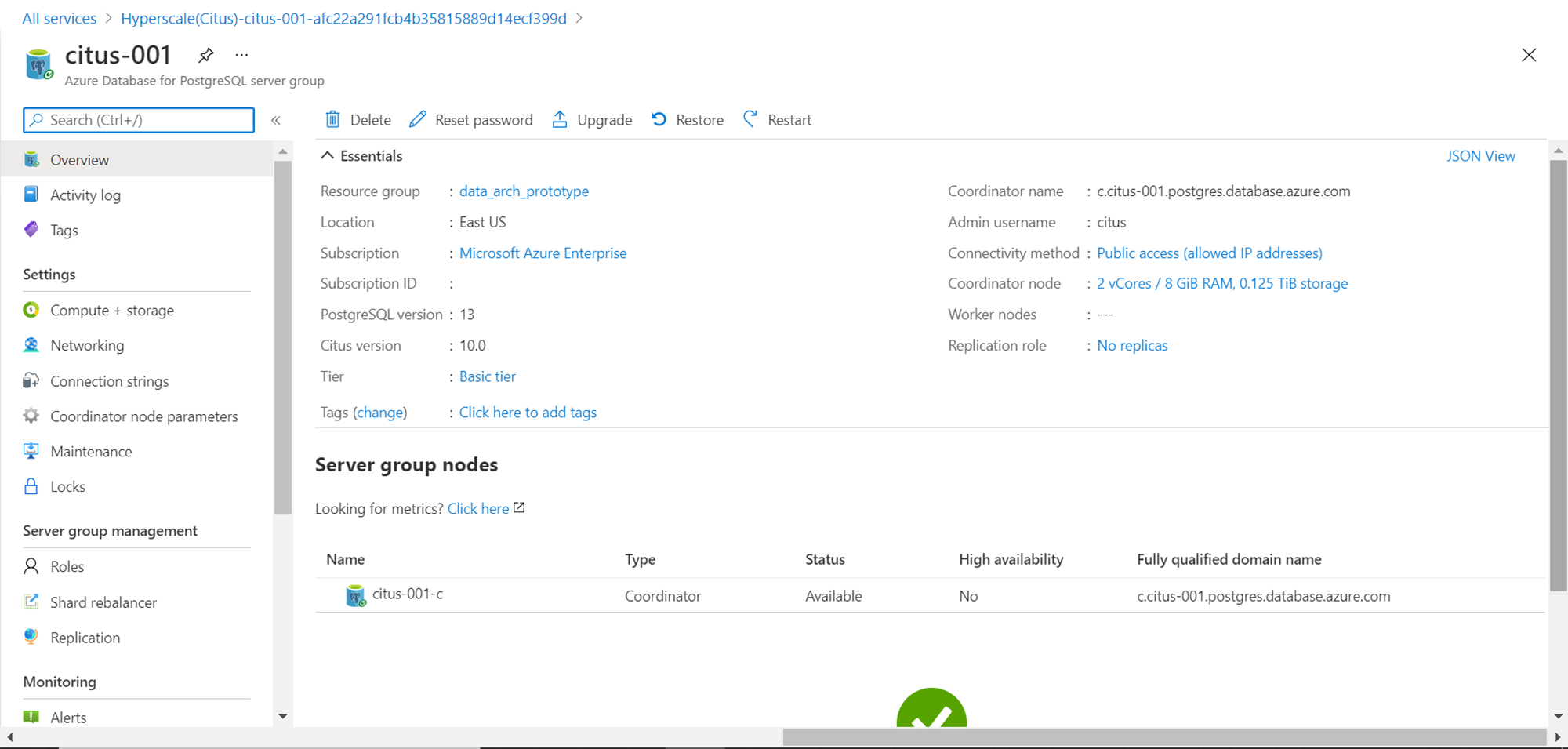
Click on Compute + Storage section and you would be able to see that if you selected Standard Tier instead of Basic tier, with a 2-node configuration, it would cost $1464.27 which is much higher than the Basic tier which would cost under $200. One can change the compute and storage capacity, and even increase or decrease the number of nodes in a worker group from this section and it would scale the capacity of the database instance horizontally i.e. scale-out.
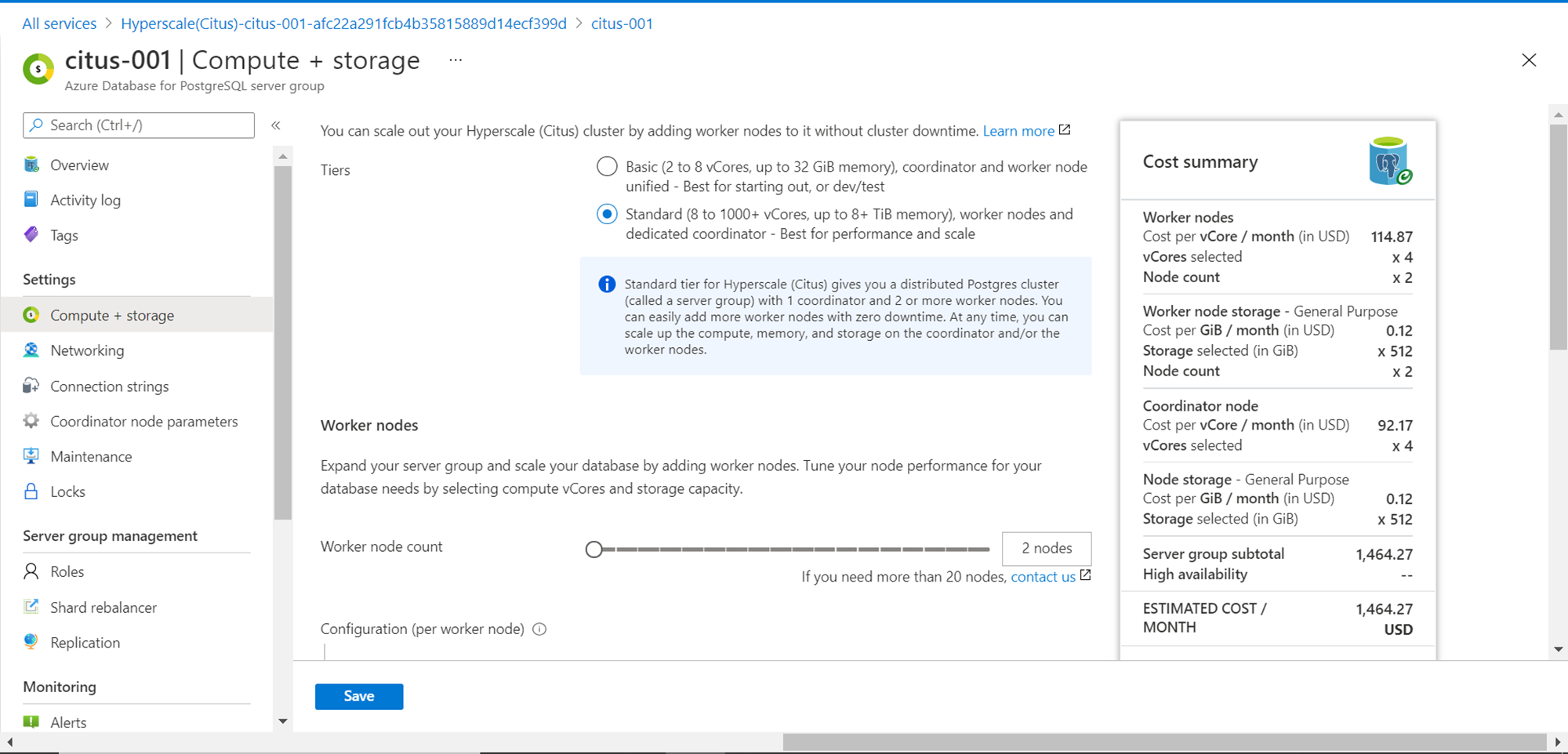
Scroll down and we should be able to customize the capacity of the coordinator node as well as worker node independently as well. Once the configuration is saved, the server configuration would start upgrading.
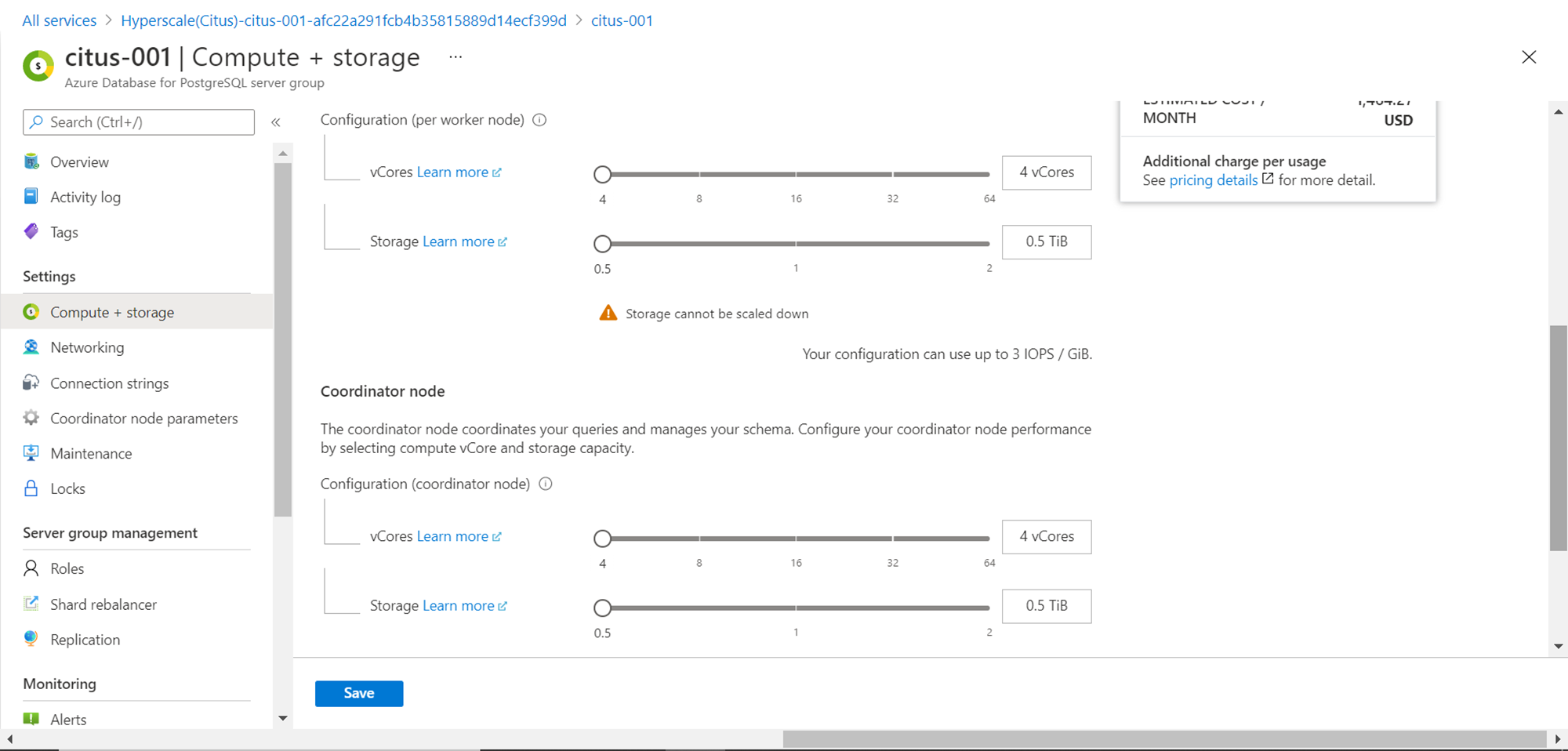
In this way, we can deploy the Azure Database for PostgreSQL Server – Hyperscale edition to create a flavor of PostgreSQL database that scales horizontally.
Conclusion
In this article, we learned about the scale-up versus scale-out approach in terms of database deployment. We learned how Citus enables Azure Database for PostgreSQL to work as a distributed database and how to deploy the flavor of PostgreSQL Server as a managed service using the Hyperscale option. Finally, we explored different configuration options to control the scalability or capacity configuration of the server.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023