

In this article, we will discuss the Fuzzy joins in the SQL Server Machine Learning using R scripts.
Introduction
VLOOKUP is a popular function in Microsoft Excel for performing vertical lookups and search the values across a worksheet. You can perform both exact match and approximate match on Excel. For example, look at the following excel table.
- On the left-hand side, we have a table that holds quantity and unit price for specific quantities
- In the right, we want to retrieve the value for a specific quantity. There is no exact quantity specified in the table. Therefore, we use the VLOOKUP function with an approximate match
- It checks for the next largest value in the lookup table using an approximate match. For the first value 58, it checks for the largest value that is less than the lookup value. In this example, the largest value is 40$ for the 50 quantity that is less than the lookup value of 58
- Similar to quantity 850, it returns a unit price of 15$ (for quantity 600)

Suppose you have a web page where users right comments in the text box. You are performing data analysis. However, there are few spelling mistakes, and you want to perform the approximate match or fuzzy lookup in another dataset. Similarly, you have a product catalog database. Your users search for a product; however, they might not type the exact keyword for the product name. Using the fuzzy joins, we can return the user the products with an approximate match to the product names.
SQL Server Machine Learning using R scripts enables you to execute the R language queries inside the SQL Server. In the previous articles, we explored a few use-cases of the machine learning language. In the previous articles, we explored the R scripts for the below topics.
- Working with images in SQL Machine Learning R Script SQL Server
- Web Scraping
In this article, we perform the fuzzy joins using the R scripts.
Environment details
This article uses the following SQL Server environment for demonstration purposes. You should follow Machine learning articles and be familiar with the R environment for SQL Server.
- Install SQL Server 2017 or 2019 with machine learning component R services
- Install the latest version of SQL Server Management Studio. You can navigate to Microsoft docs and download it
- Enable the R script execution using the sp_configure command
You can refer article An overview of SQL Machine Learning with R scripts for detailed instructions.
Fuzzy joins using the SQL Server Machine Learning using R scripts
R language uses custom modules for performing specific tasks. By default, the R service in SQL Server comes with preloaded few modules. However, to extend the R scripts features, you can download and install custom libraries.
In this article, we use the following modules. To install these libraries, navigate to C:\Program Files\Microsoft SQL Server\MSSQL15.INST1\R_SERVICES\bin and install packages.
dplyr: It provides useful commands for data manipulation. Execute the following commands for installing it in your SQL Machine Learning R Script SQL Server
Installation Command: install.packages(“dplyr”)

qdapDictionaries: It provides a useful collection of text analysis dictionaries and word lists
Installation Command: install.pacakges(“qdapDictionaries”)
fuzzyjoin: We use the fuzzyjoin library to join tables together with the matched columns. It is useful for string comparison and calculating distances
Installation Command: install.packages(“fuzzyjoin”)
You can refer to fuzzyjoin documentation for more details


In the later part of the screen, you see the unpacked and installed packages for fuzzyjoin() library.
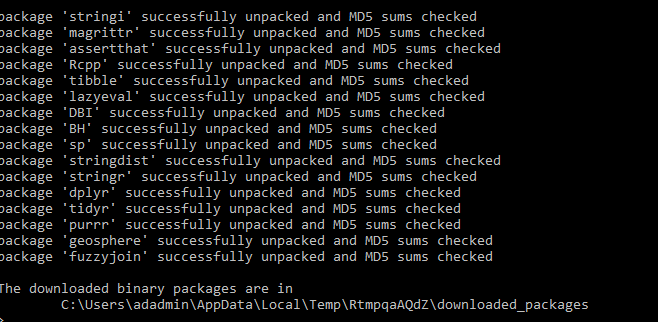
Once we have installed the library, you can verify it within an R script. Load the package, and the print(PackageVersion) displays the fuzzyjoin package version.
The R script uses the sp_execute_extetnal_script stored procedure for executing the R scripts.
|
1 2 3 4 5 6 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(fuzzyjoin) print (packageVersion("fuzzyjoin")) ' |
It returns the fuzzyjoin package is 0.1.2. It validates the package is installed successfully, and we can call it from the SQL Server script.

The fuzzyjoin package can perform several kinds of fuzzy joins of data. You can refer to fuzyjoin package documentation for detailed information
- difference_inner_join: Numeric values within some tolerance
- stringdist_inner_join: Strings similar to Levenshtein/cosine or Jaccard distance metrics
- regex_inner_join: A regular expression in matching one column with another
- distance_inner_join: The Euclidean or Manhattan distance across multiple columns
- geo_inner_join: Geographic distance as per longitude and latitude
- interval_inner_join: Overlap intervals ( Start, end)
- genome_inner_join: Genomic intervals including chromosome ID and start, end pairs
In this article, we use stringdist_inner_join package for performing the fuzzy join. We can find a list of common misspellings and their correct spellings in Wikipedia.

The fuzzyjoin package has a list of these common misspellings. The below R script prints sample data for the misspelling and the correct spelling.
|
1 2 3 4 5 6 7 8 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(fuzzyjoin) library(dplyr) data(misspellings) print (misspellings) ' |
In the output, it extracts the misspellings and correct spellings similar to listed in the Wikipedia.

Further, we can use the qdapDictionaries library for the collection of text analysis dictionaries and word lists. Now, we load the words from the dictionary using the tbl_df function.
|
1 2 3 4 5 6 7 8 9 10 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(fuzzyjoin) library(dplyr) library(qdapDictionaries) words <- tbl_df(DICTIONARY) data(misspellings) print(words) ' |
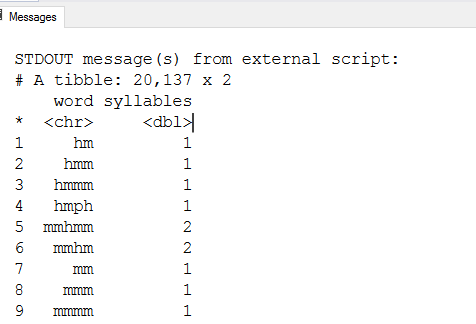
In the below R script, we do the following tasks.
- We used the set.seed() function for random numbers and sample 100 records from that using the sample_n() function
- Later, we use the stringdist_inner_join function for matching the data frames with a max_dist parameter value equals to 1. It returns the word with a maximum close to the correct word
- The Pipe (%>%) Operator forwards the result of the expression in the following expression or function
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(fuzzyjoin) library(dplyr) library(qdapDictionaries) words <- tbl_df(DICTIONARY) data(misspellings) set.seed(1000) sub_misspellings <- misspellings %>% sample_n(100) joined <- sub_misspellings %>% stringdist_inner_join(words, by = c(misspelling = "word"), max_dist = 1) print (joined) ' |
The script returns the misspellings, word, correct spelling along with the syllables. The syllables defines the number of vowels in the correct spelling. For example, the word reference has three vowels; therefore, it has value 3 in the syllables column.
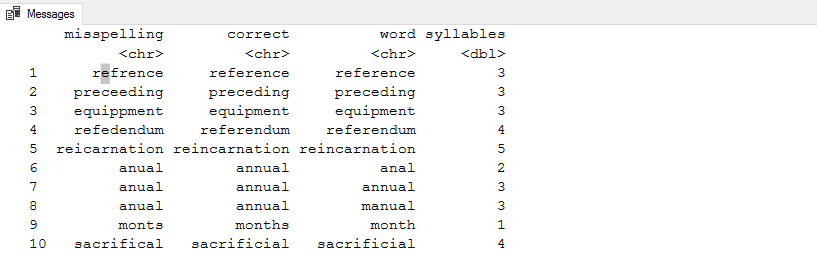
If we rerun the above R script with max_dist=2, observe the output. It returns many possible matches for a word. For example, the word reference gets a match with the deference, preference, reference, retrench.
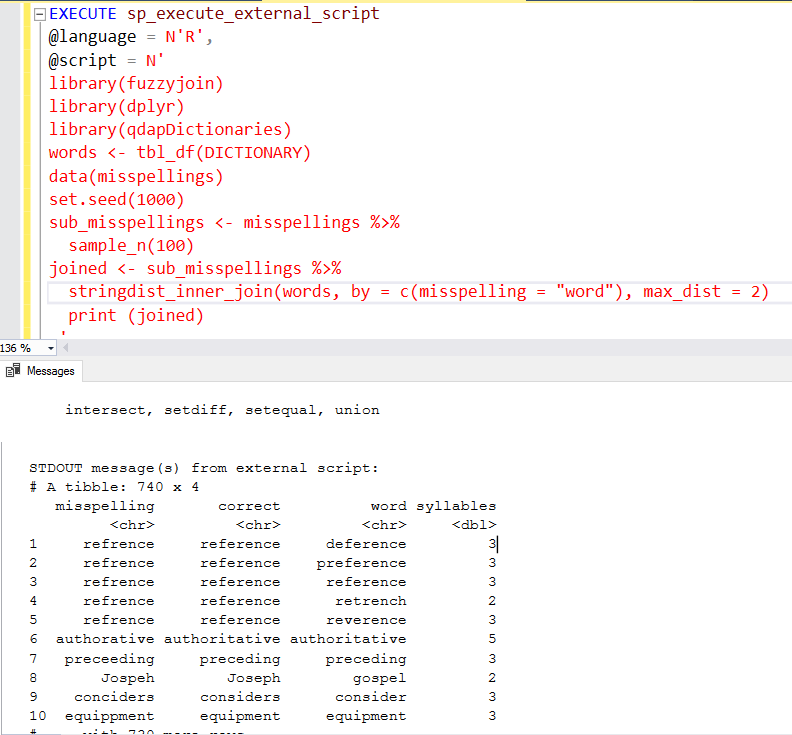
You can add the argument distance_col = “distance” in the stringdist_inner_join function to know the words distances. For example, the below R script returns the words that were two letters apart.
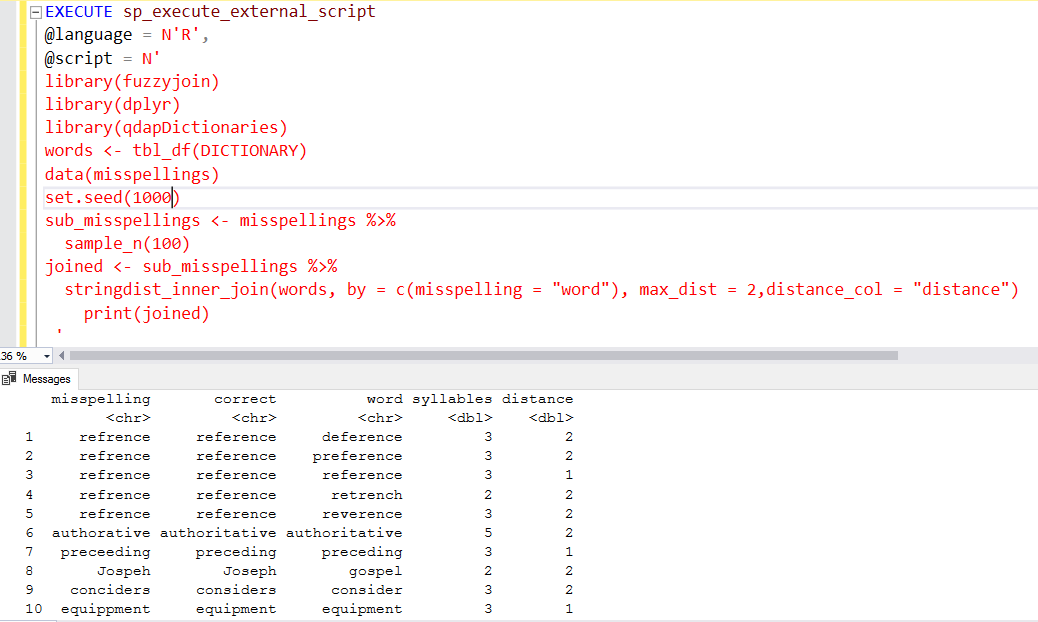
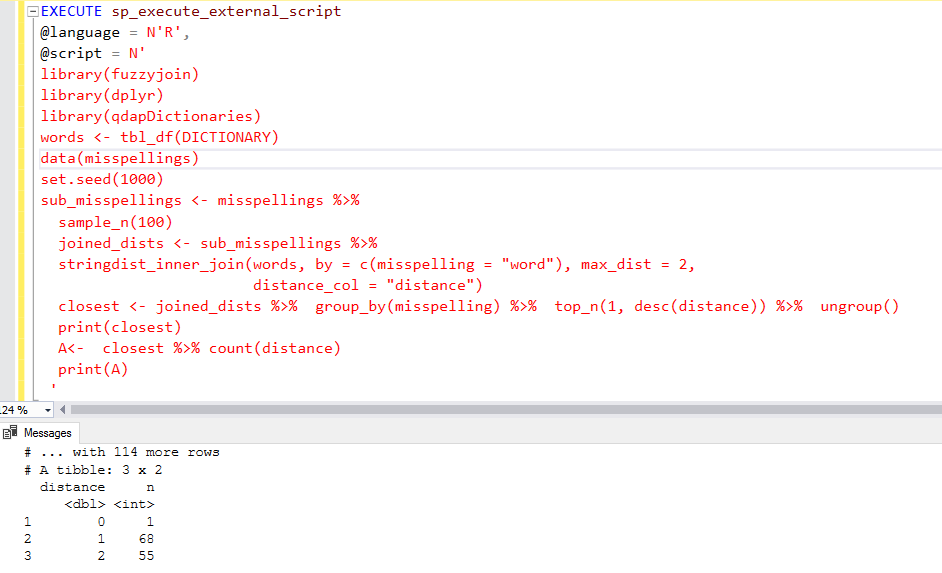
In the above image, we get a new column distance. Its value is always less than or equals to 2 because we specified the max_dist value to 2. It shows the closest matched words that were 1 or 2 letters apart.
Similarly, we can use the max_dist value to 3, and the distance function returns a value between 1 to 3.
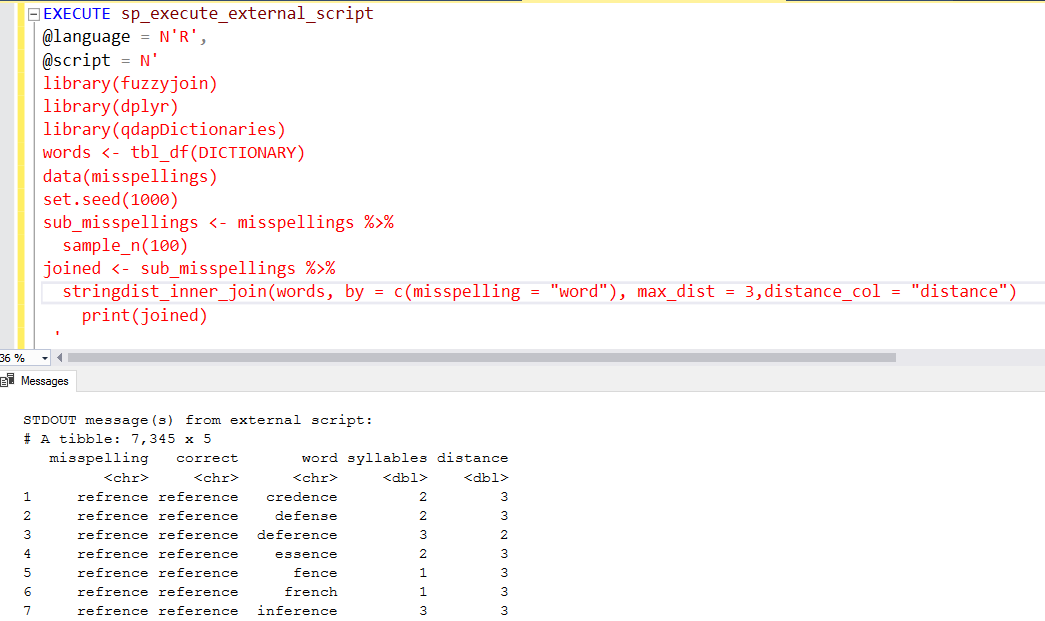
In the below R Script SQL Server, we use the group_by function for the misspellings. The Group By function takes the input of a table, groups the records and returns it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(fuzzyjoin) library(dplyr) library(qdapDictionaries) words <- tbl_df(DICTIONARY) data(misspellings) set.seed(1000) sub_misspellings <- misspellings %>% sample_n(100) joined_dists <- sub_misspellings %>% stringdist_inner_join(words, by = c(misspelling = "word"), max_dist = 2, distance_col = "distance") closest <- joined_dists %>% group_by(misspelling) %>% top_n(1, desc(distance)) %>% ungroup() print(closest) A<- closest %>% count(distance) print(A) ' |
In the output, we receive two tables. The first table returns the misspellings, correct word, syllables and the distance.
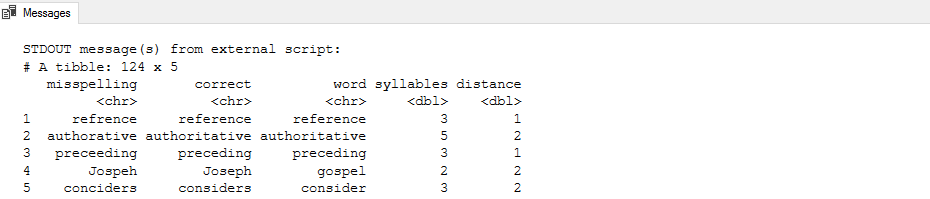
Scroll down, and you get the group_by() function output for the distances. For example, in the data set, for distance 2, it has 55 words.
Approximate match using the fuzzy join in SQL Server Machine Learning using R scripts
At the beginning of this article, we use the VLOOKUP function in Microsoft Excel for performing an approximate match. We can use the R scripts for performing the approximate match using the stringdist_left_join function from the fuzzyjoin library.
- The R script uses the fuzzyjoin and tidyverse library modules
- We use the Tibble for creating a data frame. In the first data frame, the Website contains a sheet having the lookup values. Intentionally, I specified the misspellings in the Website nibble content
- It uses another main data frame using the nibble with the data and its value
- We want to perform an approximate match from the Website data frame between the sheet and the main
- The script uses the stringdist_left_join function for the website contents and displays the output using the print function
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
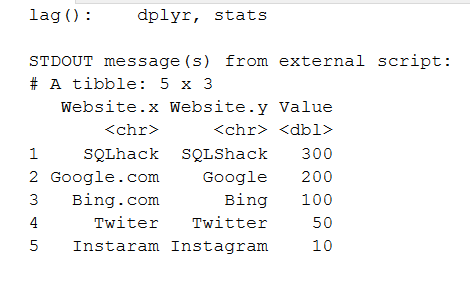
EXECUTE sp_execute_external_script @language = N'R', @script = N'library(tidyverse) library(fuzzyjoin) sheet <- tibble::tibble( Website = c("SQLhack", "Google.com", "Bing.com", "Twiter", "Instaram") ) main <- tibble::tibble( Website =c("SQLShack", "Google", "Bing", "Twitter", "Instagram"), Value = c(300,200,100,50,10) ) left_join(sheet, main, by = "Website") A<-stringdist_left_join(sheet,main, by = "Website", max_dist = 4) print(A) ' |
Look at the script output. The first row shows the misspelling SQLhack and does an approximate match with the SQLShack. It retrieves the SQLShack value similar to a VLOOKUP function.
Similarly, check Bing.com. In the primary data frame, we have a value for Bing; however, due to the approximate match, it retrieves the correct value of it.
Conclusion
In this article, we used the fuzzyjoin library in the SQL Server Machine Learning using R scripts for approximate match scenarios. It is a useful module for analyzing the text-based data set or keyword analysis.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023