
This article talks about centralizing reference tables in Azure Data Studio during the database development process for ease of deployments to multiple environments such as dev, test and production.
Additionally, the readers who are also interested in Azure Data Studio tool are going to understand the importance of having a solid database development strategy for reference data management which is often overlooked or remains unnoticed. The role of reference data for any database development and testing is undeniable but at the same time, the strategy to manage reference data centrally is also very crucial to avoid any conflict that may occur.
About Reference Tables
There is always some room for reference tables in any database design because without them the database does not make much sense. Let us quickly understand them.
What is a Reference Table?
A Reference Table is a table that contains the information for the main table. In other words, the reference table contains a specific set of data to be used by other tables.
What is Reference Data?
The data that a reference table contains is known as reference data.
What is the difference between Reference Data and Reference Table?
Technically, the reference table refers to the structure (column name, data type, etc.) and reference data means the information contained by that structure (blue, green, white, etc.).
What is Reference Table Management?
Reference table management is a way of managing a reference table such that it does not lose its quality from environment to environment and serves as a key for populating reference data to any target environment for any purpose that helps in preserving the standard of reference data.
Example of a Reference Table
A reference table can be any table that contains information for other tables for example we can say Color is a reference table that contains different types of colors such as blue, white, green, etc. Now this table can be used in another table called Watch to define different watches having different colors. Please remember you can simply create a reference table in Azure Data Studio just like the way you create any other table.
The reference table is illustrated as follows:
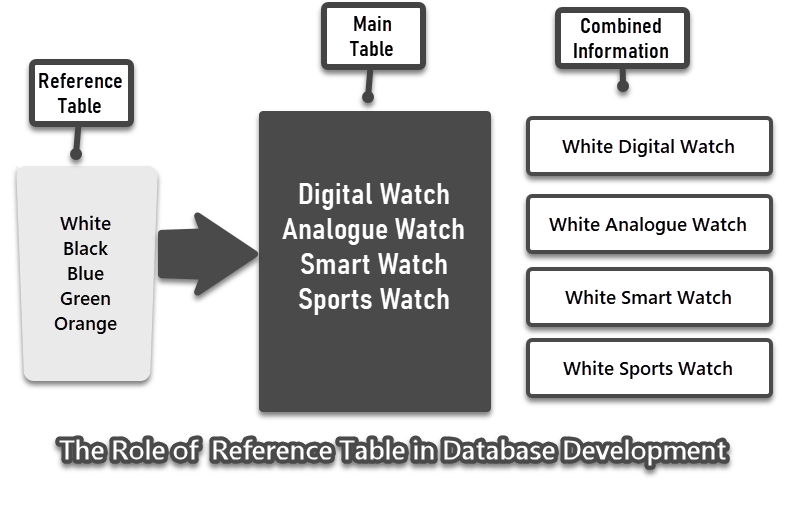
Database Development Strategy for Centralizing Reference Tables
Let us now talk about the core strategy, we have, to centralize a reference table or a group of reference tables belonging to our database of interest.
We only have to think of a way to control the reference table before it gets deployed to multiple environments for multiple purposes. In other words, we would like to centrally manage the reference table design and data so that it can be easily ported from one environment to another environment.
Environments of Interest
We are mainly interested in the following three types of environments:
- Dev (development environment)
- Test (test environment)
- Prod (production environment)
Now central management of reference data means we must be able to set up the above environments from a single central place that also holds the single source of truth for that information.
The SQL Database Project Way
One of the ways to get control over the flow of reference tables and reference data is to switch to state-based development which means you should build your database fromSQLSQL Database Project because then it is the responsibility of the Database Project to build, manage and publish reference tables to multiple environments and this is one of the core specialties of choSQLng SQL Database Project. In other words, you should define your reference tables solSQL in a SQL Database Project and then it is going to be managed from there.
Reference Data Structure and Data Scripts
If you have decSQLd to use SQL Database Project for your reference tables and data management then you may put your reference tables as data scripts to be executed by Database Project deployments to populate reference tables once they are created.
This is typically a two-step process:
- You define your reference table in the database project
- You define your reference data as a data script that can populate your reference table once the project is deployed to any desired environment
Handling Reference Data Differences in Different Environments
One of the biggest challenges in keeping a reference table inside your database project is to understand how to deal with the situation when you have a difference of reference data in different environments.
For example, you begin with a reference table that contains information about different two colors blue and green and in an ideal scenario you would like to have these two rows in each of the environments but what if you find blue, green, yellow in dev and blue, green, orange in test and blue, green, red in Production. In other words, what is the strategy to reconcile reference data if you find three different versions in three different environments?
For example, if you say you are managing reference tables through a database project then having a decent set of rows works because production may pick new reference data on the fly so we have to limit ourselves to dev and test that they should have consistent reference data and for production we only add the standard rows while keeping newly added data unaffected there.
Well, at the end of the day it entirely depends on your business requirements and preferences but keeping the surface facts in mind why would you like to restrict adding new reference data on the Production server since it is almost always a natural process unless you have exceptions.
Let us build the project in Azure Data Studio and see for ourselves how it goes then.
Developing Centralized Reference Tables and Reference Data Strategy in Azure Data Studio
You can develop a quick reference table and data strategy by following these simple steps:
- Creating a new SQL Database Project
- Creating a Reference Table in the database project
- Creating a Reference Data folder structure in the database project
- Adding a Data Script to populate the Reference Table to the Reference Data folder
- Adding a Post Deployment Script
- Calling the Data Script in the Post Deployment Script
- Running a Build to see all is fine
- Publishing the Project to multiple environments (databases)
- Checking the Reference Table and Reference Data
Prerequisites
Please go through the following articles if you are not already familiar with SQL Database Project and the required tool:
- Declarative Database Development in Azure Data Studio (sqlshack.com)
- Two ways to build SQL Database Projects in Azure Data Studio (sqlshack.com)
This article assumes that you have fulfilled the requirements (required extensions have been added) to start using SQL Database Project in Azure Data Studio.
Creating a new SQL Database Project
Please open Azure Data Studio, right-click on the Projects sidebar and click Create new:
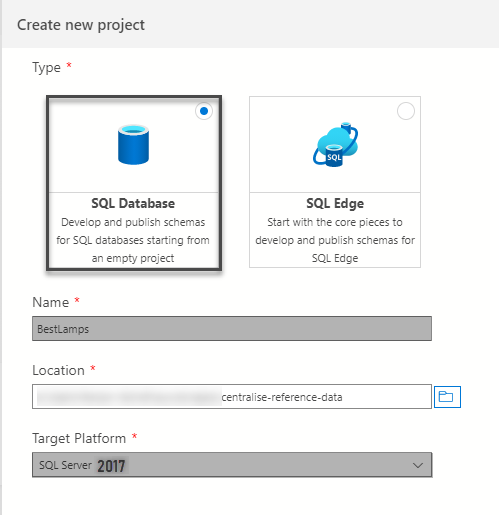
Create a fresh SQL Database Project named BestLamps using the following settings as a general guideline while you are free to choose the Target Platform and location that suits your requirements:
The SQL Database Project built in Azure Data Studio is ready to be used now.
Creating a Reference Table in the database project
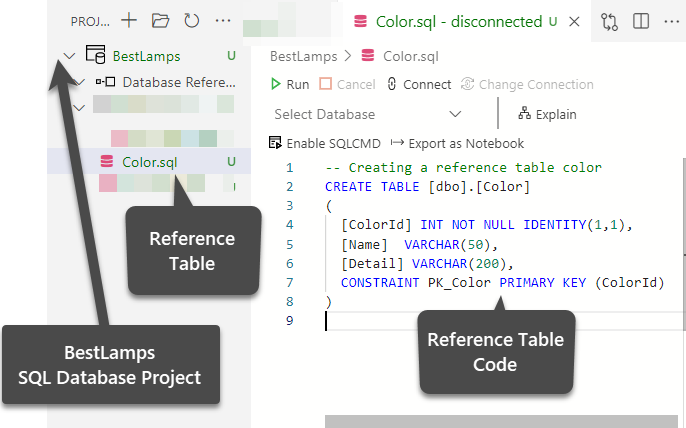
The next step is to create a reference table in the project, so right-click on the Project (BestLampts) and click on Add Table followed by inputting the table name as Colors.
Create the table Color using the following SQL code:
|
1 2 3 4 5 6 7 8 |
-- Creating a reference table color CREATE TABLE [dbo].[Color] ( [ColorId] INT NOT NULL IDENTITY(1,1), [Name] VARCHAR(50), [Detail] VARCHAR(200), CONSTRAINT PK_Color PRIMARY KEY (ColorId) ) |
The table should start showing up in the database project now.
Creating a Reference Data folder structure in the database project
Right-click on project BestLamps and click Add New Folder followed by naming the folder as ReferenceData as shown below:
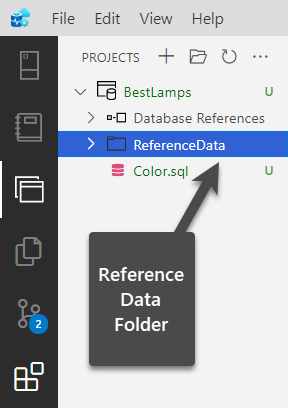
Adding a Data Script to populate the Reference Table to the Reference Data folder
Once the desired folder is created, please add a data script in the ReferenceData folder while that script must define a way to insert reference data to the reference table (Color).
Now, please remember creating a data script is a bit tricky in SQL Database Project when using Azure Data Studio as compared to doing the same thing in Visual Studio because of the limitation you may come across.
The data script is supposed to contain the insert script that populates a reference table, but it must be called within a post-deployment script as in this way we can call multiple data scripts at once (in order through post-deployment script).
Right-click on ReferenceData folder and click on Add Script to add a new script name Color.data using the following T-SQL code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- Color Reference Table Data Script -- Remove data from table color TRUNCATE TABLE dbo.Color -- Add reference data to the table color SET IDENTITY_INSERT Color ON INSERT INTO dbo.Color (ColorId,Name,Detail) VALUES (1,'Blue','This is blue color'), (2,'Green','This is green color'), (3,'Yellow','This is yellow color') SET IDENTITY_INSERT Color OFF |
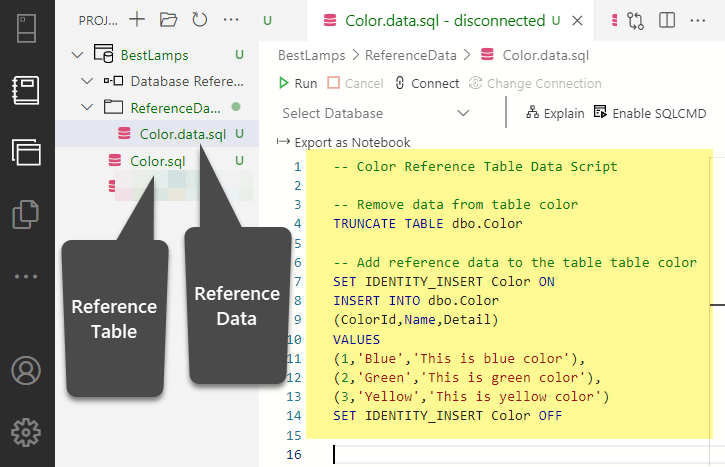
We need to change the Build property of the script to None so that it can be run by Post Deployment script and to do this we have to right click on the Project and click on Edit .sqlProj File:
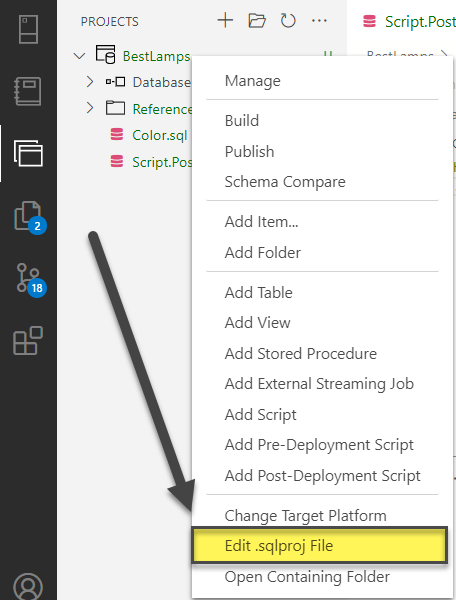
Look for the following line of code in the project file:
|
1 |
<Build Include="ReferenceData\Color.data.sql" /></ItemGroup> |
Please replace it with the following:
|
1 |
<None Include="ReferenceData\Color.data.sql" BuildAction="None" /></ItemGroup> |
Please save your changes and do as directed once you are asked to reload project after the above changes.
Adding a Post Deployment Script and calling the Data Script in the Post Deployment Script
Add a post-deployment script by right-clicking on the Database Project (BestLamps) and clicking on Add Post-Deployment Script:
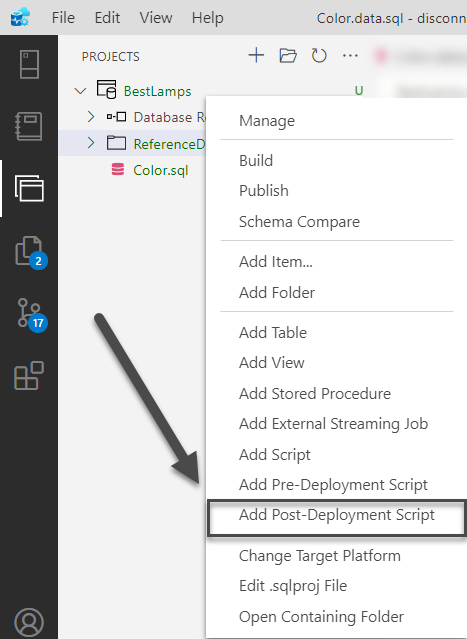
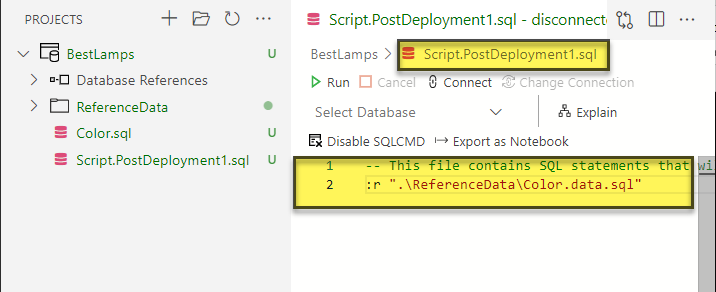
Please enable SQL CMD and type the following lines of code in the Post-Deployment Script:
|
1 2 |
-- This file contains SQL statements that will be executed after the build script. :r ".\ReferenceData\Color.data.sql" |
Running a Build to see all is fine
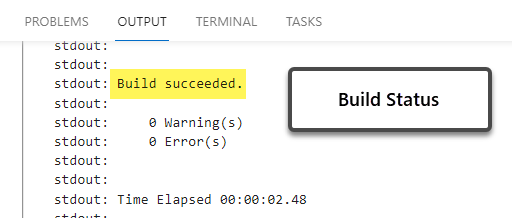
Please right-click on the Project (BestLamps) and click Build to ensure that there are no errors:
Publishing the Project to multiple environments (databases)
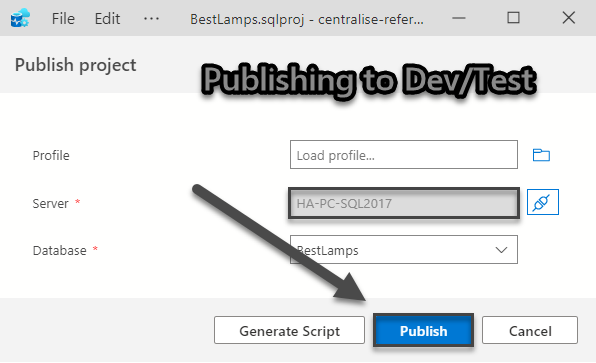
Please set the Target Platform (by right-clicking on the project and clicking Change Target Platform) that suits your requirements while in this walkthrough we are choosing SQL Server 2017.
Right-click on BestLamps SQL Database Project and click on Publish and then set the publish environment this could be your Dev or Test server:
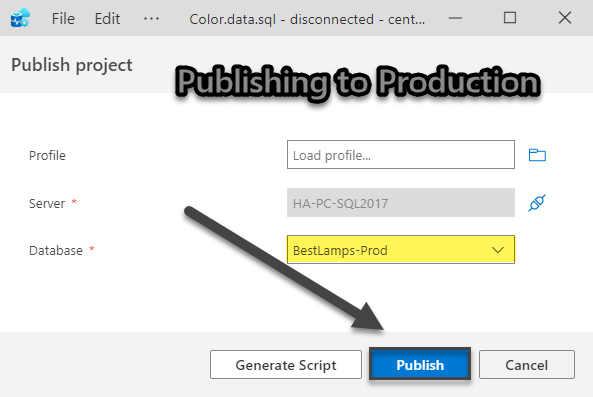
Now we can simply point to our Production server using the same Publish process in Azure Data Studio and if there is no production server, yet we can publish the production database on the same server with Prod postfix:
Checking the Reference Table and Reference Data
Finally, switch to the Server tab in Azure Data Studio and locate the recently published databases:
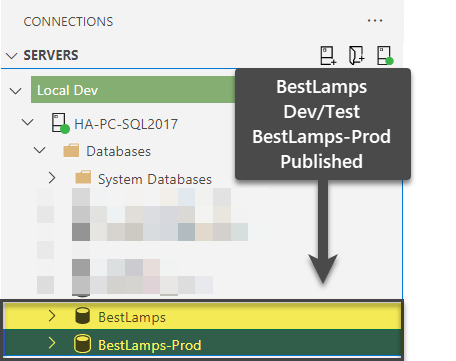
Let us query the Color table by running the following script against BestLamps as follows:
|
1 2 |
-- View Color Reference Table (data) SELECT c.ColorId,c.Name,c.Detail FROM dbo.Color c |
The output is as follows:
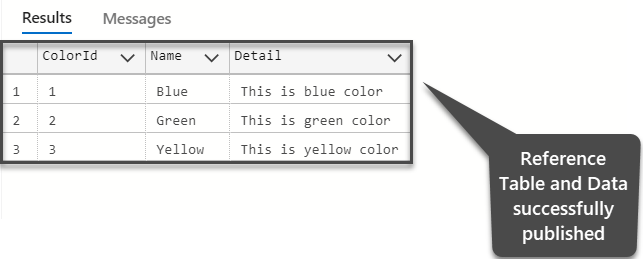
Congratulations we have successfully achieved the objective of this walkthrough which was to centralize the Reference Table and its underlying data using Azure Data Studio.
Final Word
The strategy to centralize reference data may vary from one professional scenario to another and we implemented one such method to have similar reference data rows in all the environments, but it is absolutely fine to use the schema comparison tool to resolve any difference between SQL Database Project reference data and BestLamps Production database that may happen from time to time and in that case, you have to decide whether to include or exclude Production environment.
However, please remember at the end of the day it is not the reference data strategy that just works rather it is the strategy that works and complies with your business requirements matter plus the I leave it to you to decide how big role is the choice of best tools like Azure Data Studio in helping you achieve your business objective.

He holds BSc and MSc Degrees in Computer Science and also received the OPF merit award.
He began his professional life as a computer programmer more than a decade ago, working on his first data venture to migrate and rewrite a public sector database driven examination system from IBM AS400 (DB2) to SQL Server 2000 using VB 6.0 and Classic ASP along with developing reports and archiving many years of data.
His work and interest revolves around Database-Centric Architectures and his expertise include database and reports design, development, testing, implementation and migration along with Database Life Cycle Management (DLM).
He has also received passing grade to earn DevOps for Databases verified certificate, an area in which he finds particular interest and potential.
View all posts by Haroon Ashraf
- How to create and query the Python PostgreSQL database - August 15, 2024
- SQL Machine Learning in simple words - May 15, 2023
- MySQL Cluster in simple words - February 23, 2023