
Introduction
Context
Back in my days at school, I followed a course entitled “Object-Oriented Software Engineering” where I learned some “design patterns” like Singleton and Factory. If you are not familiar with this expression, here is a definition of a design pattern from Wikipedia:
“In software engineering, a software design pattern is a general reusable solution to a commonly occurring problem within a given context in software design. It is not a finished design that can be transformed directly into source or machine code. It is a description or template for how to solve a problem that can be used in many different situations. Design patterns are formalized best practices that the programmer can use to solve common problems when designing an application or system.”
Well, as stated above, these design patterns are not a finished design, in and of itself, and must be written in the programming language of our choice. Transact SQL is also a programming language and we could also imagine the implementation of those design patterns for data generation. Actually, the subject of this article can be seen as a specialized version of the Command design pattern.
The particular design pattern this article is about can be used in multiple situations and we will review it in details in a few seconds.
In following sections, we will focus on the problem that we want to solve and on the general solution to that problem. This solution constitutes therefore a design pattern for the solution. Once we know this design pattern, we can specialize it to fulfill the needs of a particular situation and that’s what we’ll do in last section.
Design pattern definition
The problem
Now, it’s time to talk a little bit about the problem we want to solve in this article. I’ve been confronted to it more than once and I’m pretty sure that you’re are not stranger to it neither.
Let’s say we want to develop an application running T-SQL commands that will insert new records into a set of tables. This application can be a script generator, a monitoring or reporting tool or anything else you could imagine. We would like to be able to get back all data related to a particular execution of this application. Why would we do that? There can be multiple answers:
- To limit computation costs and just keep results of a treatment for further review
- To take these data as input of another process which would transform it to something else, in short to log steps in a data transformation process.
- Or anything else you might think of
With this approach, we can divide complex code into smaller pieces in which the business logic is less complex and easier to manage. As we divide these pieces of code, we could also run the processing asynchronously.
The following shows an example process in which we could eventually use the solution defined in this article. Green arrows mean that source process has to succeed for destination process to run. The arrow itself means that data generated from source process is used as input (or loaded) by destination process.
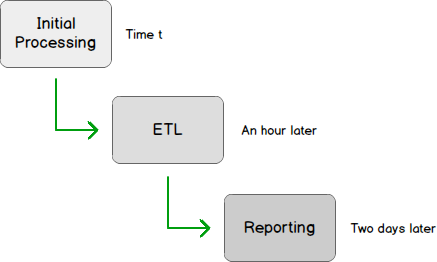
Our application can be written in another language but the solution to the problem has to be written in T-SQL because the application can be composed of multiple executables and we don’t want to write custom libraries to include in each individual executable.
The solution
Now, let’s discuss some points that will lead us towards the entire solution for purpose better understanding. We will segment this solution into two distinct parts: the “what” and the “how”. The “what” consists in the objects we need while the “how” is the way we will use these objects. Using both together constitutes the actual solution to the presented problem.
What do we need?
The biggest need that we can understand from problem explanation is that we need to uniquely identify an execution of the application. So, we need to assign a unique identifier during execution. In terms of implementation. This unique identifier can be either:
- A value generated using a Sequence object and NEXT VALUE FOR statement
- A value generated using the IDENTITY function or data type
- A value generated using UNIQUEIDENTIFIER data type and NEWID() function.
- A value based on datetime or timestamp of execution (be aware of the limitations of DATETIME data type and prefer DATETIME2 if milliseconds matter)
- A random but not already used value following a design pattern
As we need to be able to refer to an execution of the application and get back the results of that execution, this unique identifier must be stored in a table. We’ll refer to that table as the “execution log”.
But we can’t only log unique identifiers into that table because we might need to read other information to know which one we should use for further processing. You will find below a list of information I tend to keep in order to get back to a particular execution of an applications. This list is not static and you can either remove or add one or more items to it.
- A name for the treatment performed by the application
-
Some information about caller:
- The name of the login (can be extended with the name of his database user both can be different in your environment)
- The IP Address
- The name of the computer
- The name of the executable
- The Time when the execution began
- The Time when the execution completed
- The List of values used for parameters of that execution
- The outcome of the execution (“SUCCESS” or “ERROR” or NULL)
- The error message that lead to a non-successful outcome
You can look at following T-SQL statement that corresponds to the creation statement for the ExecutionLog table using previous list.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE [ExecutionLog] ( [ExecutionId] <DATATYPE_TO_BE_DEFINED> NOT NULL, [ExecutionName] VARCHAR(512) NOT NULL, [SQLLogin] VARCHAR(512) NOT NULL, [ClientNetAddress] VARCHAR(128) NOT NULL, [ClientHostName] VARCHAR(128) NOT NULL, [ClientProgramName] VARCHAR(256) NOT NULL, [StartTime] DATETIME2 NOT NULL, [EndTime] DATETIME2 NULL, [ExecutionParams] VARCHAR(MAX) NULL, [Outcome] VARCHAR(64) NULL, [ErrorDetails] VARCHAR(MAX) NULL ) |
With this information, we really can present, to a user, a subset of the entire execution log with only its own actions. We can also stop a cascading process by checking the execution success information: if the execution was not successful and we needed the results of this execution to perform an additional treatment on this, then it’s of no use to carry on…
How will we do it?
At this point, we’ve answered the “what” question: we exactly know what we need to address the challenge defined in this article. Now, let’s talk about the “how”: how will we make it happen?
We could write a set of T-SQL queries inside the application that will use the execution log, but this means that if we want to change a piece of code in these queries, we need to change it in every executable that works with this design pattern. There is, to me, a better solution to that problem.
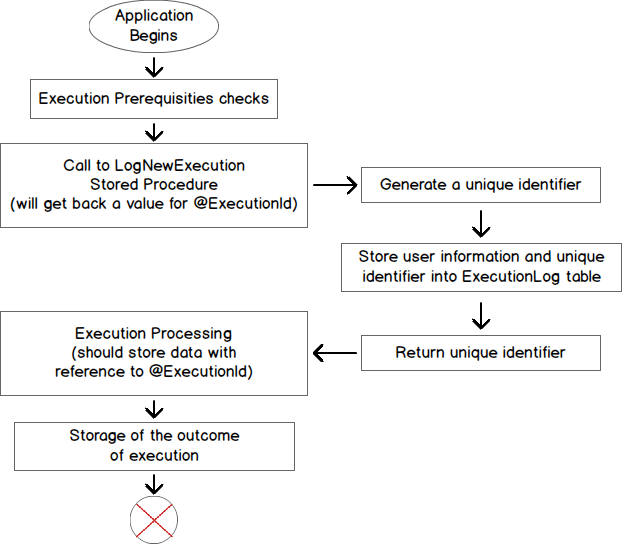
Instead, we should create a stored procedure that will generate the unique identifier and store the information discussed above. We will call this stored procedure “LogNewExecution“. Here is the interface for such a function. Again, this can be customized to your needs.
|
1 2 3 4 5 6 7 8 9 10 |
PROCEDURE [LogNewExecution] ( @ExecutionName VARCHAR(512), @StartTime DATETIME2, @ExecutionId <DATA_TYPE> OUTPUT, @Debug BIT = 0 -- I always add @Debug parameter to my procedures -- to get extended information at execution ) |
When the application runs, it will call that stored procedure and the application will get back the unique identifier of its execution thanks to the @ExecutionId parameter.
The body of this procedure should contain a modified version of following query. This query essentially gets back information about caller and inserts it in conjunction with the value of @ExecutionName and @StartTime parameters.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
INSERT into [ExecutionLog] ( ExecutionName, SQLLogin, ClientNetAddress, ClientHostName, ClientProgramName, StartTime ) SELECT @ExecutionName, s.login_name, c.client_net_address, s.[host_name], s.program_name, ISNULL(@StartTime,SYSDATETIME()) from sys.dm_exec_sessions s left join sys.dm_exec_connections c on s.session_id = c.session_id WHERE s.session_id = @@spid ; |
As you can see in sample code above, there is no value inserted for ExecutionParams column of ExecutionLog table. Actually, we could consider that an update should be run in application as we could log execution even before parameter validation. If it might not happen, you should add a @ExecutionParams parameter to LogNewExecution stored procedure.
When application execution completes, no matter the outcome, the application will simply run an update against the ExecutionLog table to set values to the appropriate columns regarding the outcome.
Following diagram summarizes what we discussed so far.
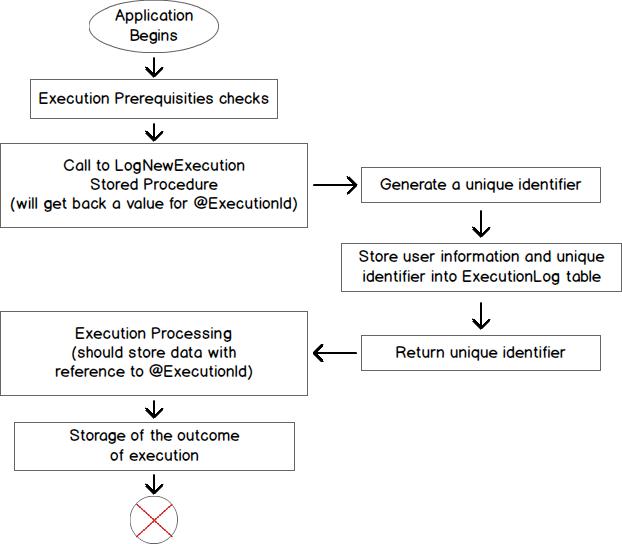
Design pattern implementation examples
We will now review two implementations of that design pattern that I use very often. As you will see, each implementation is specialized to the situation it covers. Let’s just say for now that the first implementation is designed to be used in the context of reporting and the second in the context of script generation. We could also imagine other use cases like a monitoring and alerting tool, for example.
Implementation I: Generic Reporting Execution Log
Before getting into the details of the design pattern implementation, let’s review what needs it will cover.
A while ago, I implemented an extended deadlock monitoring process that gets back deadlock XML graphs from Extended Events, stores it into a table and parses the XML to store extended details into another table. As soon as this process ends, we can run various reports as the occurrences by date or the most commonly implied application and so on. But we need to record these reports because we can’t keep all the collected deadlock XML graphs for obvious space consumption considerations.
But we could plan other kinds of reports than just deadlock reports, so let’s review some general facts about reporting:
- Reports can be stored either in a specialized table or in files on file system.
- Files can be based on structured formats like XML or HTML. It can also simply be a flat file or a CSV file.
- The output target of a given reporting process can change from execution to execution.
This implies that output type and output path information have to be kept somewhere so that we are able to actually retrieve reports contents and process it.
Based on the description above, I specialized the design pattern presented in this article as follows.
Firstly, I extended the ExecutionLog table to add a ReportClass column so that I can filter records to only get reports related to deadlocks or whatever. I also added an OutputType and an OutputPath column. Here are two example usages of those two columns:
- OutputType is FILE/HTML and OutputPath is “C:\Public\report.html”
- OutputType is TABLE and OutputPath is DBA.dbo.DeadlockReport
In addition to those changes, I needed to define the way to uniquely identify a report. To do so, I simply used an IDENTITY column. I used BIGINT data type just in case I would use it a lot in future days.
As I don’t think extended explanations on those columns are necessary, you will find below the T-SQL statement to create the actual ExecutionLog table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE TABLE [Reporting].[ExecutionLog] ( [ReportId] BIGINT NOT NULL IDENTITY(1,1), [ReportClass] VARCHAR(512) NULL, [ReportName] VARCHAR(512) NOT NULL, [SQLLogin] VARCHAR(512) NOT NULL, [ClientNetAddress] VARCHAR(128) NOT NULL, [ClientHostName] VARCHAR(128) NOT NULL, [ClientProgramName] VARCHAR(256) NOT NULL, [StartTime] DATETIME2 NOT NULL, [EndTime] DATETIME2 NULL, [OutputType] VARCHAR(32) NULL, -- TABLE / FILE / NONE [OutputPath] VARCHAR(MAX) NULL, [ReportParams] VARCHAR(MAX) NULL, [Outcome] VARCHAR(64) NULL, [ErrorDetails] VARCHAR(MAX) NULL ) |
I also changed a little bit the LogNewExection procedure so that it takes the three new columns (ReportClass, OutputType and OutputPath).
|
1 2 3 4 5 6 7 8 9 10 11 |
ALTER PROCEDURE [Reporting].[LogNewExecution] ( @ReportClass VARCHAR(512) = NULL, @ReportName VARCHAR(512), @StartTime DATETIME2 = NULL, @OutputType VARCHAR(32), @OutputPath VARCHAR(MAX) = NULL, @ReportId BIGINT OUTPUT, @Debug BIT = 0 ) |
You will find attached to this article the script to create the schema, table and stored procedure presented in this section. You can run it against a test/dev database and test if it actually works as expected using following script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
-- simulate application start DECLARE @ReportId BIGINT; DECLARE @ProcSuccess BIT = 0; DECLARE @LineFeed CHAR(2) = CHAR(13) + CHAR(10); DECLARE @LogMsg VARCHAR(MAX); DECLARE @ProcParams VARCHAR(MAX); EXEC [Reporting].[LogNewExecution] @ReportName = 'TEST - Execution', @ReportClass = NULL, @ReportId = @ReportId OUTPUT, @OutputType = 'TABLE', @OutputPath = '[master].[dbo].[ThisIsATestTbl]', @Debug = 1 ; -- For testing purpose : SELECT * FROM Reporting.ExecutionLog ; -- Business logic code : parameters validation -- Could set @ProcParams value on the fly SET @ProcParams = '...' ; -- update ExecutionLog with process parameters -- I didn't add this to LogNewExecution stored procedure as -- this could be run before the end of parameter validation UPDATE Reporting.ExecutionLog SET ReportParams = @ProcParams WHERE ReportId = @ReportId ; -- For testing purpose: SELECT * FROM Reporting.ExecutionLog ; BEGIN TRY -- Procedure actual action (stores in report target) -- ... SET @ProcSuccess = 1; END TRY BEGIN CATCH SELECT @LogMsg = '/* ----------------------------- ( Details of the error caught during execution ) -----------------------------*/' + @LineFeed + 'Error #' + CONVERT(VARCHAR(10),ERROR_NUMBER()) + ' with Severity ' + CONVERT(VARCHAR(10),ERROR_SEVERITY()) + ', State ' + CONVERT(VARCHAR(10),ERROR_STATE()) + @LineFeed + 'in stored procedure ' + ISNULL(ERROR_PROCEDURE(),ISNULL(OBJECT_SCHEMA_NAME(@@PROCID) + '.' + OBJECT_NAME(@@PROCID),'N/A')) + @LineFeed + 'Message:' + @LineFeed + ISNULL(ERROR_MESSAGE(),'N/A') + @LineFeed + '/* -------------------------- ( End of Details of the error caught during execution ) --------------------------*/' + @LineFeed ; RAISERROR(@LogMsg,10,1); END CATCH UPDATE Reporting.ExecutionLog SET Outcome = CASE WHEN @ProcSuccess = 1 THEN 'SUCCESS' ELSE 'ERROR' END, ErrorDetails = @LogMsg, EndTime = SYSDATETIME() WHERE ReportId = @ReportId ; -- For testing purpose: SELECT * FROM Reporting.ExecutionLog ; |
Here are the contents of the ExecutionLog table after execution began:

Here are the contents of the ExecutionLog table after a failed execution:

Finally, the contents of the ExecutionLog table after a successful execution:

If we want to check what would happen if an error occurred, we can change following line:
|
1 2 3 |
SET @ProcSuccess = 1; |
By
|
1 2 3 |
RAISERROR('Test Error',12,1) ; |
And we will get following view (that I split for better reading)

As we can see, the outcome is set to ERROR for second report. If we look at the ErrorDetails column, we see following message:

Implementation II: Generic script Generation Execution Log
Here, the aim is little different. I designed this execution log when I had to migrate databases from onr server to another for multiple SQL Server instances. The aim was initially to upgrade to a newer version of both Microsoft Windows Server and Microsoft SQL Server. Based on the criticality of machine and SQL Server edition, I could migrate via backup-restore, detach-attach or by setting up a database mirroring between source and destination then failover. Other migration solutions might come up in the future.
While I could have written a bunch of scripts that I just call to run a particular aspect of migration, I wanted to keep control over what is done during migration and also to limit the possibilities if somebody eventually takes the scripts and runs it on a wrong server, some time after the original migration happened. So, I preferred to create a script generator. I divided the process into three steps:
- Migration parameters definition (which databases have to be migrated, from and to which server, which SQL Agent Jobs have to be migrated and so on). No logging needed.
- Generation of business logic for steps in migration process. This process will store in a table all the operations that need to be performed for actual migration. In this step, we focus on actual operations execution. There is no check for success of previous operation. So, we need to use a unique identifier for the execution.
- Generation of actual scripts for migration, which is based on the identifier of previous step, takes back the operations and generates either a T-SQL or PowerShell script with error handling between generated operations. This generation will look at the outcome of execution and will also check that it’s still relevant to generate scripts.
Based on the explanations above, we can quickly identify columns that have to be added to the ExecutionLog table presented as design pattern. There is actually only one column: ValidForNbDays. While this value can be seen as another parameter and could be put into the ExecutionParams column, it’s actually relevant to add this column as we want to easily check if the generated scripts would still be valid.
You will find below the table that I use for this.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE [SQLGeneration].[ExecutionLog] ( [GenerationId] BIGINT IDENTITY(1,1), [PurposeName] [VARCHAR](512) NOT NULL, [SQLLogin] [VARCHAR](512) NOT NULL, [ClientNetAddress] [VARCHAR](128) NOT NULL, [ClientHostName] [VARCHAR](128) NOT NULL, [ClientProgramName] [VARCHAR](256) NOT NULL, [StartTime] [DATETIME] NOT NULL, [EndTime] [DATETIME] NULL, [ValidForNbDays] INT NULL, [GenerationParams] [VARCHAR](MAX) NULL, [Outcome] [VARCHAR](64) NULL, [ErrorDetails] [VARCHAR](MAX) NULL ) |
I also added a @NbDaysOfValidity to LogNewExecution stored procedure.
We could review a testing batch like we did for previous example, but we won’t as it’s trivial to adapt this code to current implementation.
There are a lot of use cases that come to my mind in the field of generation that could use this table:
- Entire database objects scripts (for database versioning)
- Database security export
- Particular database management tasks that could be automated like creating a test/dev instance, setting up database mirroring or Availability groups, etc
Conclusion
In this article, we’ve seen a standardized way to log execution of our processes. We’ve seen with two examples that it can be specialized to multiple fields and used in various situations.
Downloads
- Procedure Reporting LogNewExecution
- Procedure SQLGeneration LogNewExecution
- Schema Reporting
- Schema SQLGeneration
- Table Reporting ExecutionLog
- Table SQLGeneration ExecutionLog

I'm one of the rare guys out there who started to work as a DBA immediately after his graduation. So, I work at the university hospital of Liege since 2011. Initially involved in Oracle Database administration (which are still under my charge), I had the opportunity to learn and manage SQL Server instances in 2013. Since 2013, I've learned a lot about SQL Server in administration and development.
I like the job of DBA because you need to have a general knowledge in every field of IT. That's the reason why I won't stop learning (and share) the products of my learnings.
View all posts by Jefferson Elias
- How to perform a performance test against a SQL Server instance - September 14, 2018
- Concurrency problems – theory and experimentation in SQL Server - July 24, 2018
- How to link two SQL Server instances with Kerberos - July 5, 2018