
In this article, I am going to talk about using regular expressions in a Postgres database. Regular Expressions, also known as RegEx are pattern matching criteria that can filter data based on the pattern. It is heavily used to match string values to a specific pattern and then filter the results based on the condition. From a beginner’s perspective, these regular expressions can seem to be quite complex in the first, however, as you will start using these on a daily basis, you will come to the underlying logic, and then you can start writing your own RegEx statements.
What are Regular Expressions?
In computer theory, it is often the case that you might need to find some text from within your data that matches a fixed pattern. This pattern can be defined using a sequence of characters that can define a specific search expression. It is particularly used in text manipulations and selections. The most common implementation of these expressions in SQL is the LIKE operator, which uses wildcard values to match patterns. However, the LIKE operator has a few limitations and is out of scope for this article. This brings us to the more complex pattern matching operator called the TILDE “~” operator. In this article, we will explore each of the regular expressions that use the TILDE operators. Read more about the regular expressions from the official website.
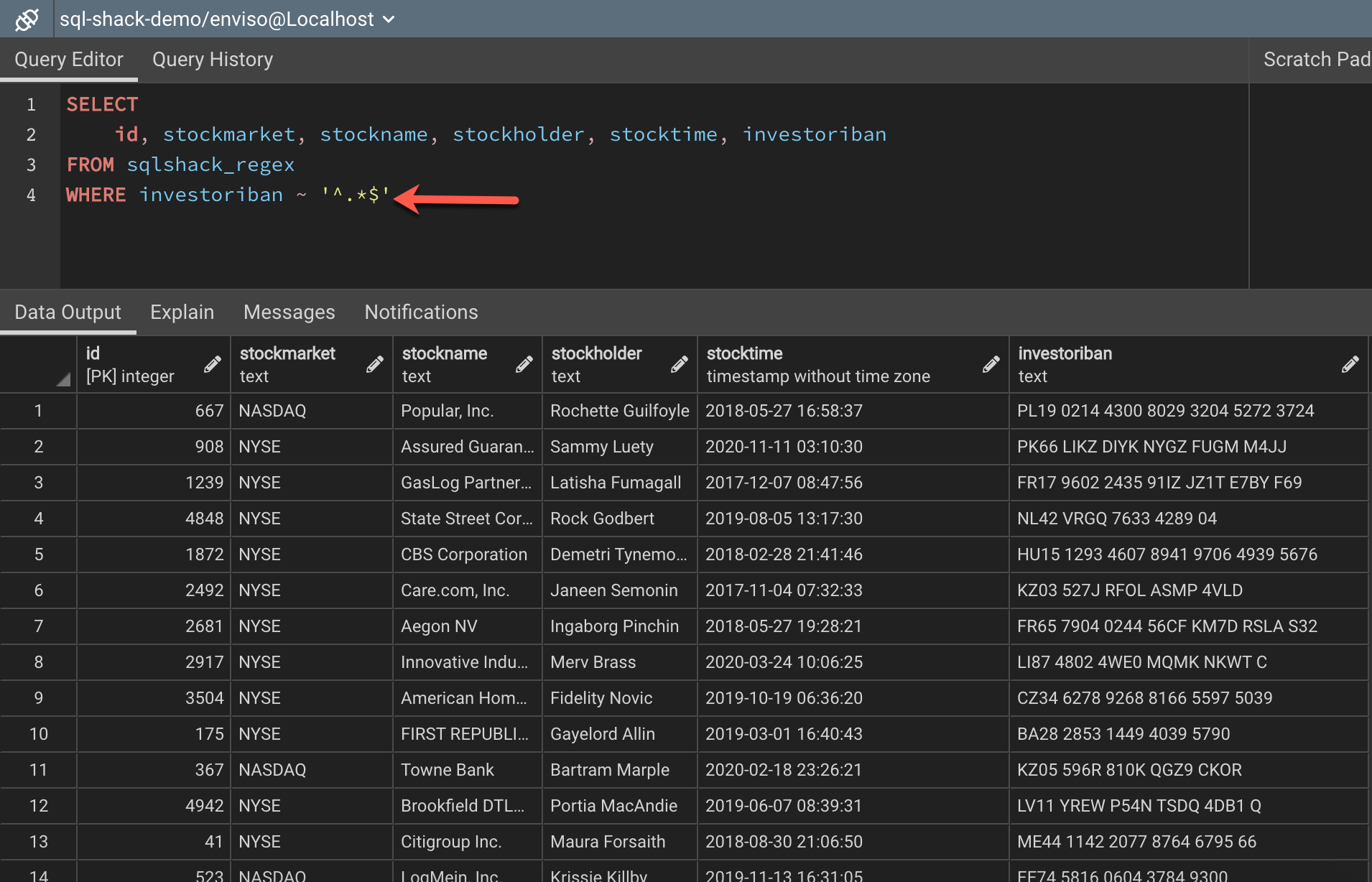
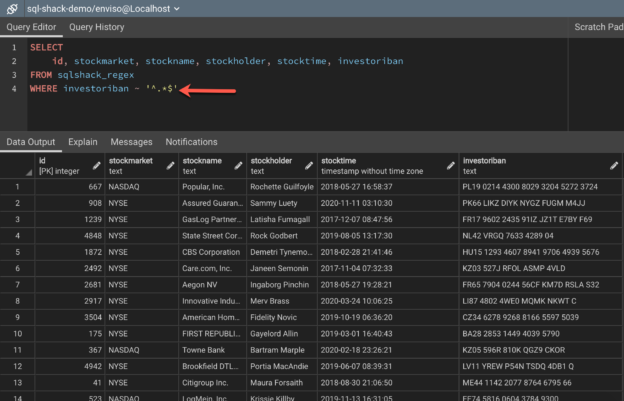
Figure 1 – A simple RegEx expression in PostgreSQL
As you can see in the figure above, the filter clause is extended using the “~” tilde operator and then a sequence of characters followed by it. Let us now learn in more detail how to write this expression.
Before moving forward, I would advise you to run the following SQL script on your Postgres database so that you can leverage the queries that we are going to follow in this article and walk along with me.
https://gist.github.com/aveek22/70df045bd987d58f5e6ff984d43cee87
This script will install the GreaterManchesterCrime dataset on your database.
Writing the RegEx characters – Selecting all records
As you might be already aware, using the tilde operator marks the beginning of the regular expression statement. Since these expressions are used on character or string fields, we must put the expression inside single quotes. The beginning of the expression is marked with a “^” operator and the end is marked with a “$” dollar sign. These two characters help us understand the start and the end of the expression. Apart from these two, the other important characters are the “.*” combination. This combination is a wildcard that tells the SQL engine to return anything that matches. Basically, a “.*” combination will return all the rows from the database table. So, as you can see in figure 1, the expression is initiated with the tilde “~” operator, followed by the expression enclosed within single quotes, and the expression is written as “^.*$“.
Figure 2 – Selecting all data using the Regex functions
Selecting strings that start with characters or digits
In most cases, the regex is used to select or match patterns from textual or alphanumeric fields. Often, there comes a requirement where you need to find patterns within your dataset that start with a character or a digit. There are specific ways that define this requirement in a regex. Let us understand both of these in detail.
- Characters are classified into lowercase and uppercase, and hence, can be represented as “[a-z]” or “[A-Z]“, depending on the type of character that you would like to start with
- For digits, you can use either “[0-9]” or “\d” to match the patterns. Here, the “\d” represents digits
Let us now see how we can use this practically.
Suppose we would like to return all those crime details from the table for which the CrimeID field starts with an upper case character. This statement can be written in SQL as follows.
https://gist.github.com/aveek22/af550dddd988cc2e5e5a694a7dbe1fea
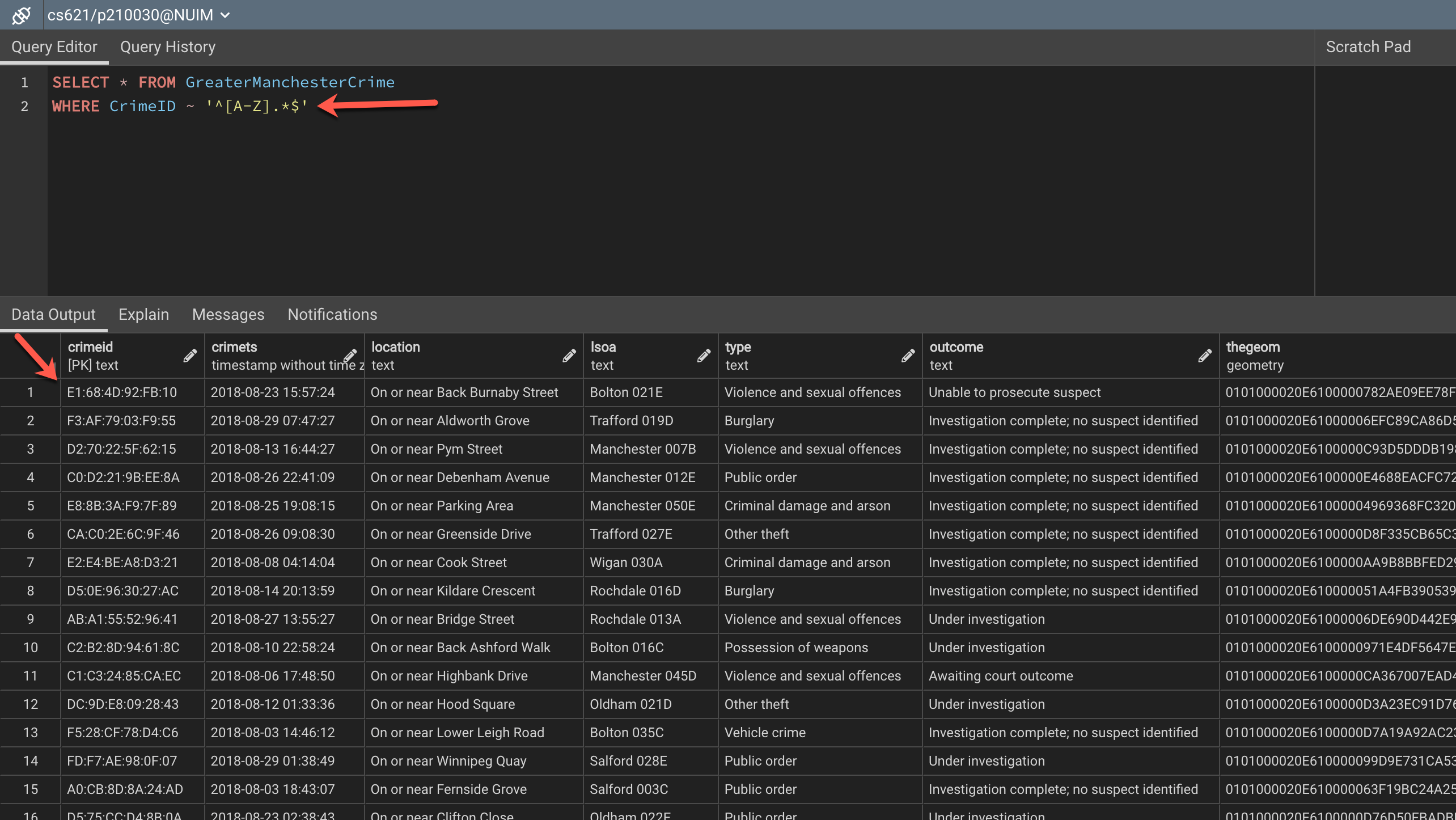
Figure 3 – Selecting uppercase matched patterns
As you can see in the figure above, all the rows for which the CrimeID field starts with an uppercase alphabet are being returned. Notice, how we have used the “[A-Z]” followed by a “.*” to select all the rows beginning with an uppercase letter and then followed by anything.
Similarly, we can change the filter criteria to select records that start with a digit, instead of a character. In order to do that there are two ways. Let us explore each of that one by one.
https://gist.github.com/aveek22/e5200e8e98754aa6a3f533546e7f9296
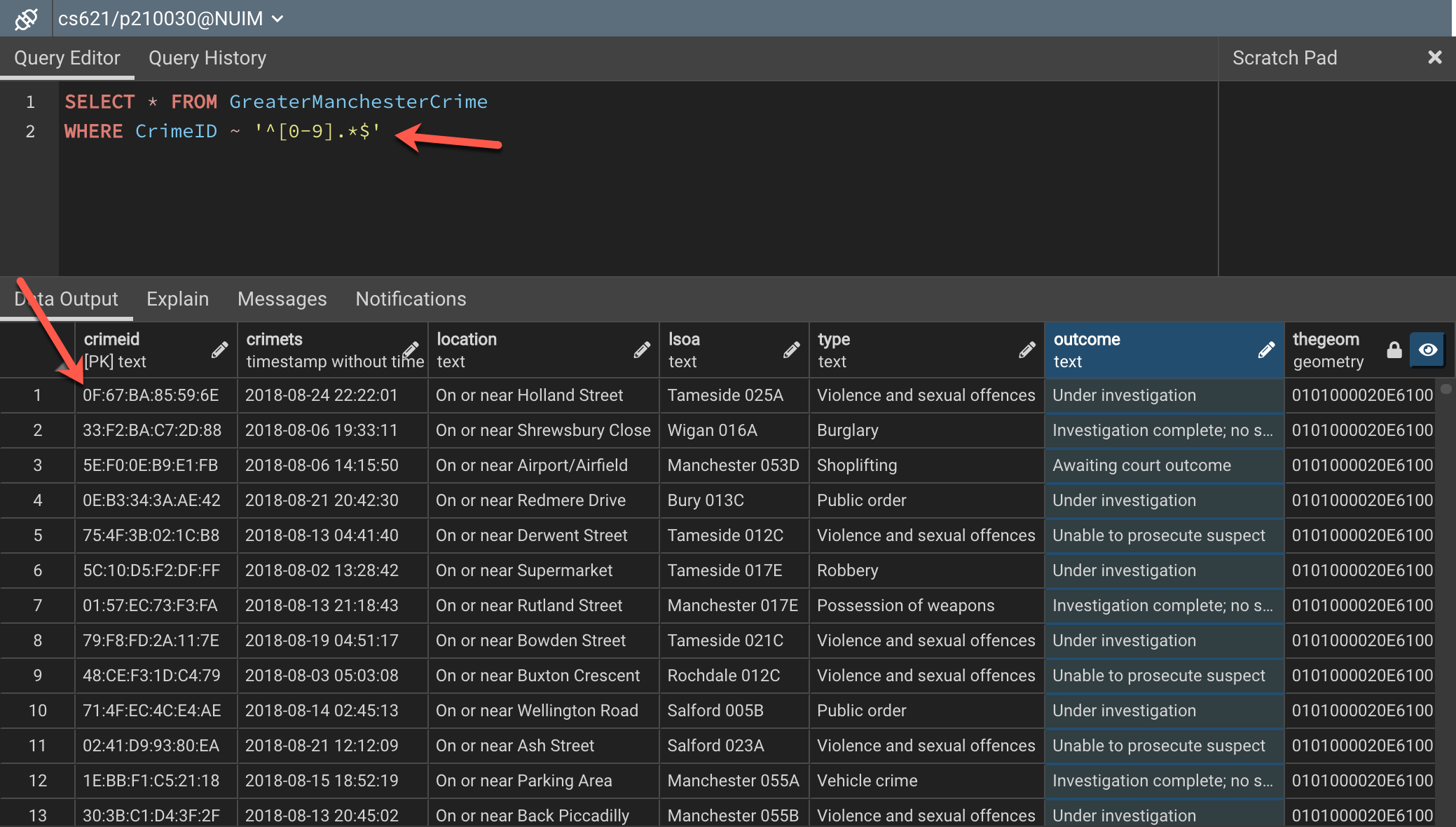
Figure 4 – Selecting CrimeID that starts with a digit
As you can see in the figure above, we have used the “[0-9]” instead of the character as in the previous case and this returns us all the records that start with a digit. Another alternative approach to this can be written by using the “\d” character set. Here, “d” also represents digits and hence can be used to filter records that begin with a digit. You can use the following query for this.
https://gist.github.com/aveek22/8f9cafb61819f3d7ff42bcee30a06de0
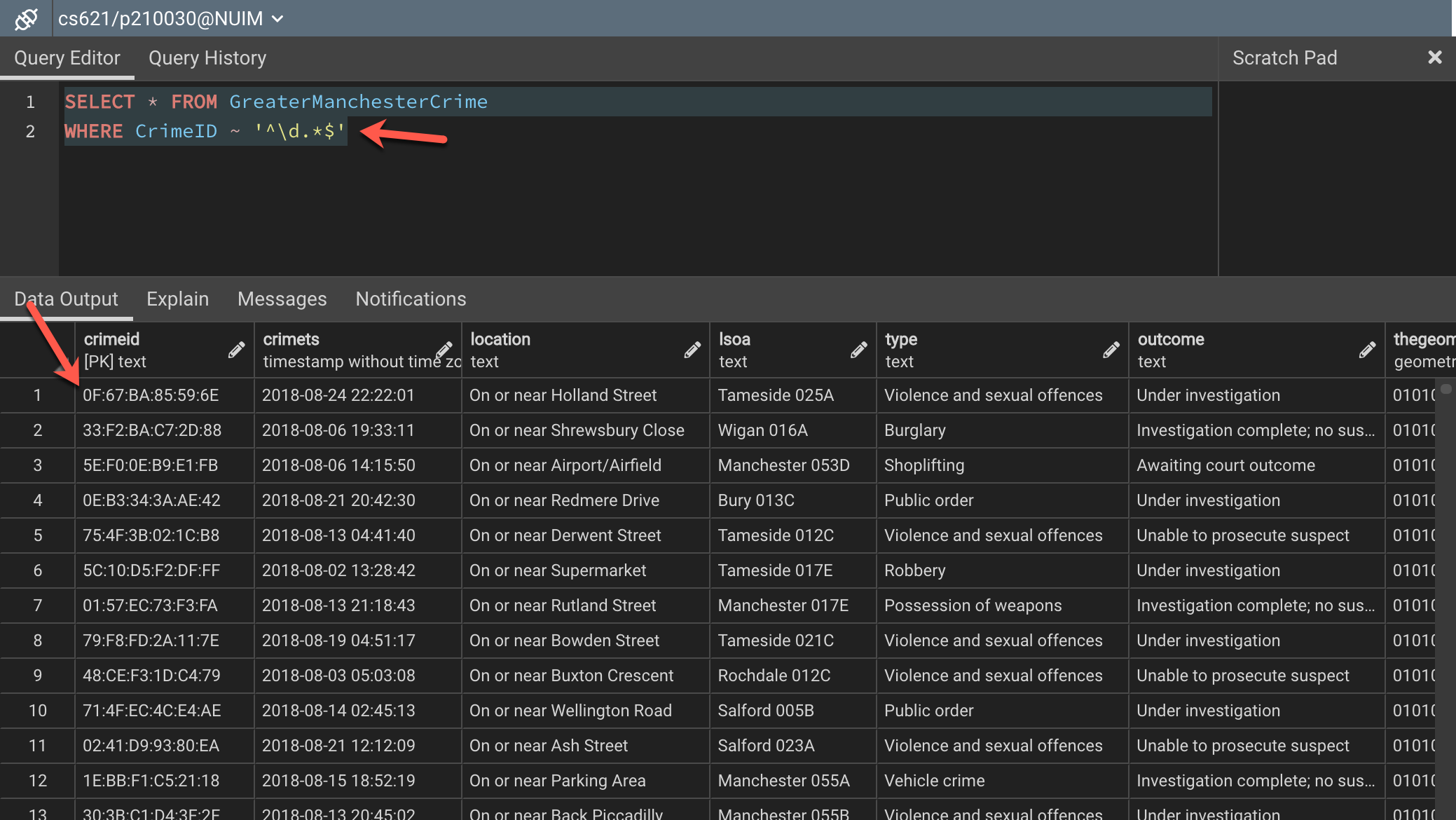
Figure 5 – Alternate approach to filter data beginning with a digit
Selecting strings that start with two characters or digits
Now that we know how to select strings that start with a character or a digit, we can extend the same to write more complex SQL queries that will select records that start with two characters or digits. These are valid requirements and can often be combined with other unique pairs. In this section, we are going to write queries for the following three scenarios.
- Return records that start with two character values
- Return records that start with two-digit values
- Return records that start with one character and one digit
Let us now see how this can be practically implemented in PostgreSQL. In order to select records that begin with two characters, there are again two regex approaches as follows.
- ‘^[A-Z][A-Z].*$’
- ‘^[A-Z]{2}.*$’
As you can see in the patterns above, you can repeat the “[A-Z]” pattern twice, or instead can also set the number of times to repeat in curly braces. The second approach is much more dynamic and can be used for any number of repetitions required. Let us try this in practice now.
https://gist.github.com/aveek22/f0afad231632e30dec97dd209233f30e
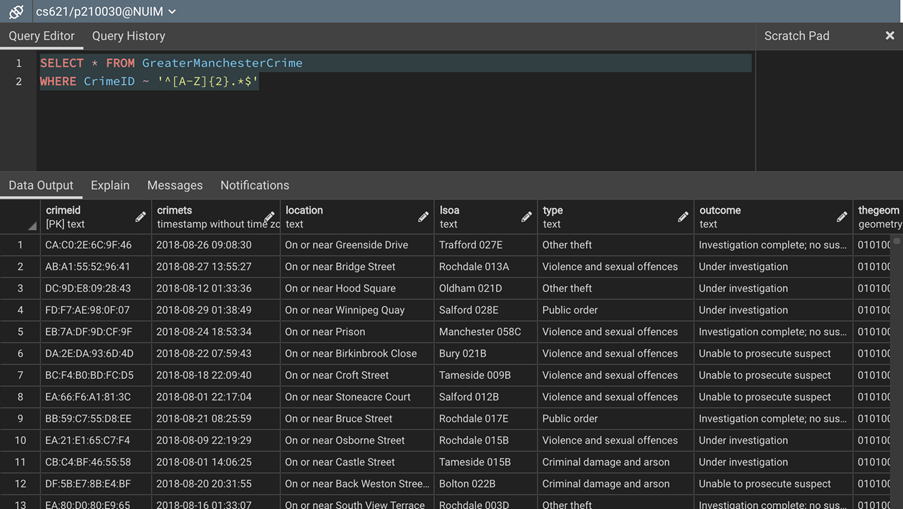
Figure 6 – Selecting records that start with two characters
As you can see in the figure above, all the CrimeID fields start with two characters. You can also try the alternate approach to receive similar results.
Let us now do the same but we will filter the records that start with two digits instead. In this case, as well, we will be using the same approach as in the previous. We will mention the number of times to repeat the digit inside curly braces. You can use the following query.
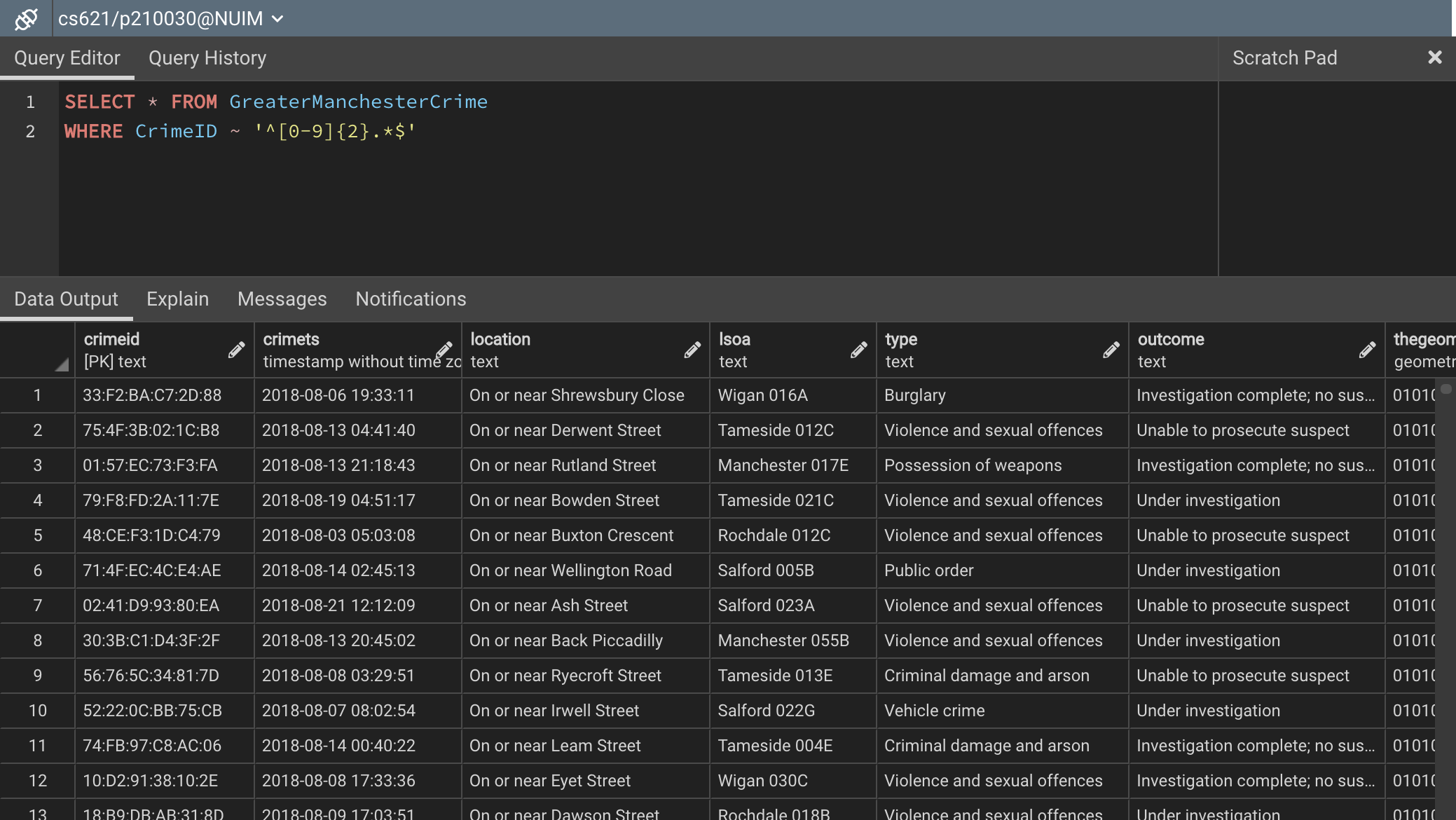
Figure 7 – Selecting records that start with two digits
In the above figure, you can see that all the CrimeID fields begin with two digits. Alternatively, you can also use the “\d” to represent the digits here.
Finally, let us explore how to select records for which the CrimeID starts with a character and a digit. For this, we can simply append the digit identifier after the character identifier in the regex expression. You can use the following query for this.
https://gist.github.com/aveek22/99e83baba72992ab3eebdd33e0dbe063
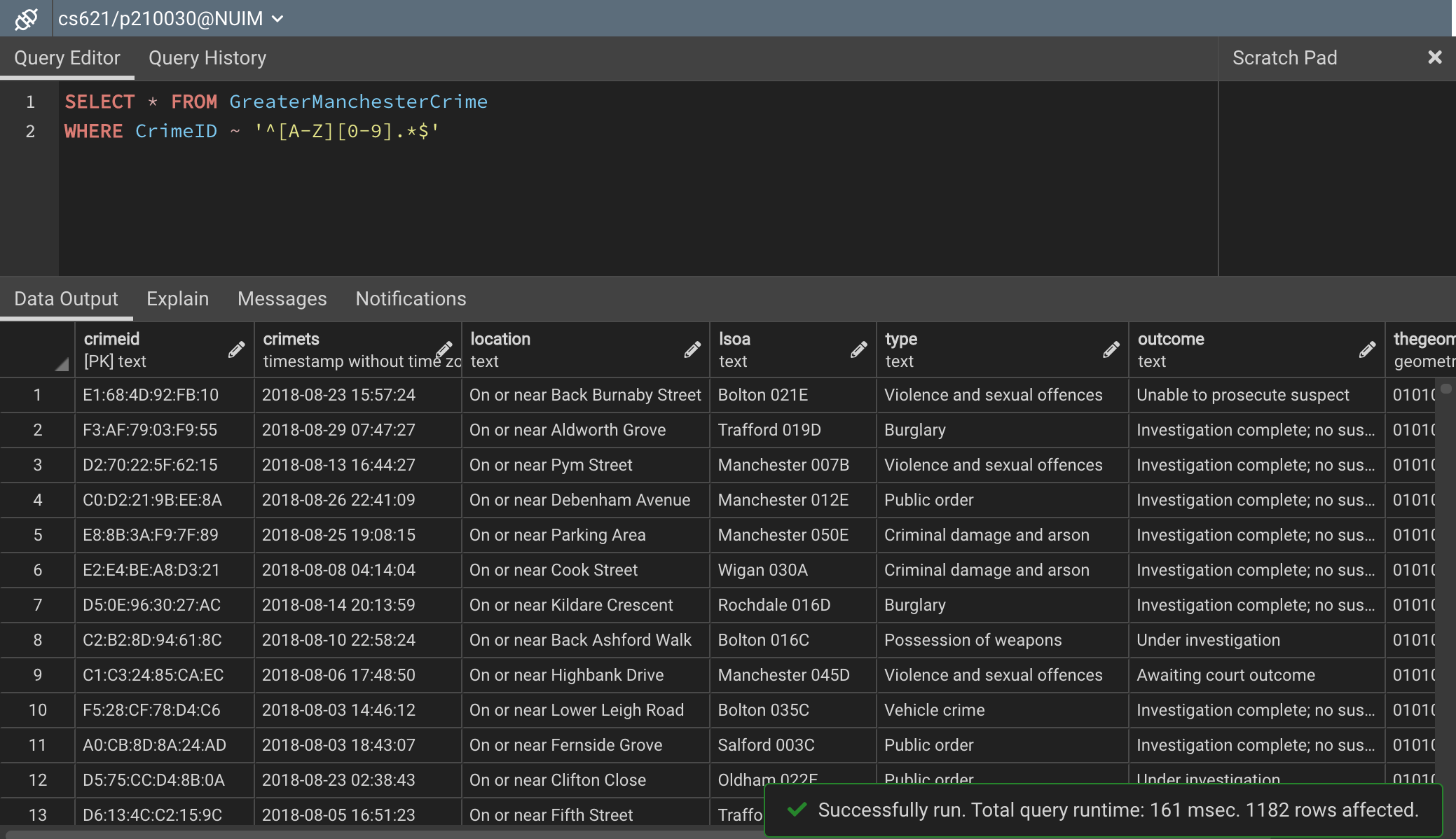
Figure 8 – Selecting records with one character and one digit
Conclusion
In this article, we have explored regular expressions in-depth in the PostgreSQL database. We have understood how to match different types of patterns, including characters, digits, and special characters. You can use these in combination to build a customized pattern that you can look for within the data. Apart from using these RegEx patterns, Postgres also supports the use of wildcard operators using the LIKE operator. However, the LIKE operator offers very basic functionality and can be used only to support minimal requirements. In case the data needs to be matched with a more complex pattern, then using the regular expressions is perfect.

He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021