SQL Server 2016 became publically available on the 1st of June 2016. Some might feel that a new SQL Server release every 2 years might be too frequent with many organization still lagging behind by running SQL Server 2012 or earlier.
So what is the fuss all about? Microsoft proudly mentions the following 5 topics as the pinnacle of SQL Server 2016’s offerings.
OLTP with increased performance, scalability and high availability
Enhanced data security with Always Encrypted
Mobile Business intelligence
Advanced analytics with R Services
Consistency between your database servers and your database as a service (Azure)
So what’s new? In this article I will do a quick summary of the new or improved features which will certainly open up a whole new world of excitement for the data professional.
Faster results
 No one likes to wait for query results. We want it to be instantaneous. SQL Server 2016 gets closer than ever to delivering this with significant enhancements to In-memory OLTP, in-memory analytics and improvements to Analysis services.
No one likes to wait for query results. We want it to be instantaneous. SQL Server 2016 gets closer than ever to delivering this with significant enhancements to In-memory OLTP, in-memory analytics and improvements to Analysis services.
In-memory OLTP
Memory optimized tables can now have foreign keys, check and unique constraints, triggers (WITH NATIVE_COMPILATION), large object type columns and can use any collation. Statistics for memory-optimized tables are now also auto updated.
A couple of enhancements were also made to indexes from memory-optimized tables which now allows Unique indexes, columns using any collation and Nullable index key columns.
In-memory analytics
Column store indexes can be added to memory-optimized OLTP tables which allows real time analytics to be performed on your OLTP database without the risk of resource contention between your OLTP workload and your analytics workload. In order to minimize the overhead caused by maintaining clustered column store indexes, filtered column store indexes can be used.
Analysis Services
Analysis Services continues to offer 2 modes of data storage both of which have been optimized for performance in 2016.
Multi-dimensional mode
The multi-dimensional engine has been improved to return data faster, these enhancements do not need any configuration in order to be taken advantage of but will only really be evident if you compare the baseline of your current server to that of SQL Server Analysis Services 2016.
Tabular mode
Tabular mode which is based on the same technology as column store indexes has been improved by enhancements to DAX, storage engine caching and T-SQL generation of DirectQuery mode.
Database engine enhancements
TempDB
 TempDB has been improved with performance in mind. You no longer have to determine how many TempDB files you have to add for yourself. Instead SQL server 2016 decides on a default to use by taking into account the number of logical processors on the server. This circumvents the latch contention issue caused by having only 1 TempDB file, (as was the default in previous versions). This is of course still configurable, but now you can do this during your SQL Server install.
TempDB has been improved with performance in mind. You no longer have to determine how many TempDB files you have to add for yourself. Instead SQL server 2016 decides on a default to use by taking into account the number of logical processors on the server. This circumvents the latch contention issue caused by having only 1 TempDB file, (as was the default in previous versions). This is of course still configurable, but now you can do this during your SQL Server install.
Trace flags for improved performance
Trace flags 1117 and 1118 which had to be enabled specifically in the past, has now been included in the database engine and has such no longer need to be activated manually.
The Query Store
The Query Store is a completely new feature which will help DBA’s to troubleshoot performance issues resulting from changes in the query plan. Historical data is captured to allow for comparisons to be made between queries, plans and statistics. They Query Store is not enabled by default, so in order to use it you can enable it with this command:
|
1 2 3 |
ALTER DATABASE AdventureWorks SET QUERY_STORE = ON; |
Once enabled the following 4 dashboards are immediately available:
Regressed Queries
Overall Resource Consumption
Top Resource Consuming Queries
Tracked Queries
All of which will allow you to see the data captured in the Query Store.
Stretch Database
The purpose of the new Stretch Database feature is to essentially split hot, warm and cold data and seamlessly move the warm data to Azure, thereby improving the performance of your hot data, reduces your on-site hardware requirements while at the same time allowing you to keep all of your data indefinitely.
Data access still occurs through your on-site database, and no changes to applications are required and the security model of the tables involved remains the same.
Stretch Database supports Transparent Data Encryption which can be enabled to address any concerns about the security of the data in the remote data center as well as data in transit between the local and the remote data centers.
Increased security
There are 3 new security features introduces in SQL Server 2016.
Always Encrypted
With Always Encrypted, the data is, well… always encrypted. The encryption takes place on the client side when it is written, and requires a special driver and an encryption key in order to be able to read the encrypted data.
Row Level Security
 Row level security allows you to restrict the rows that a user is able to see, allowing them only to see rows which are relevant to their function. Row level security is implemented by creating inline table functions. This allows a lot of flexibility in terms of what criteria could be used to determine a user’s access but could also have a performance impact if not handled with care.
Row level security allows you to restrict the rows that a user is able to see, allowing them only to see rows which are relevant to their function. Row level security is implemented by creating inline table functions. This allows a lot of flexibility in terms of what criteria could be used to determine a user’s access but could also have a performance impact if not handled with care.
Dynamic Data Masking
SQL Server 2016 contains 4 new masking functions which can prevent users from viewing sensitive data unless they have been explicitly granted permission to view it. The masking is applied to the query results and as such do not require any changes to existing applications. A DBA running a query in SSMS for instance will also only see the obfuscated data.
Better High Availability
AlwaysOn availability groups
Although not new to SQL Server 2016 there has been some significant improvements to availability groups in this version.
AlwaysOn Basic Availability Groups
This is similar to database mirroring and will be available in the SQL Server 2016 standard. Just like mirroring this is configured on the database level, and only one secondary is allowed which is not readable.
Group Managed Service Accounts
The purpose of this is to facilitate the management of service accounts in large organizations. This has actually been around since SQL 2012, but in SQL Server 2016 gMSAs can be used with availability groups and failover clusters.
Database failure failover
In previous versions a failover of an Availability group was only triggered if the sp_server_diagnostics procedure returned and error, the SQL Server service has stopped or if the instance is not responsive. I did not take into account the state of any database. Enabling the Database Level Health Detection option allows for the availability group to also trigger a failover in case a database becomes inaccessible for whatever reason.
Distributed Transaction Coordinator (DTC) support
DTC is now supported for AlwaysOn Availability groups provided that you are running either Windows 2016 or Windows 2012 R2 with KB3090973 and that your Availability Groups have been created with the WITH DTC_SUPPORT = PER_DB option.
Load balancing for readable secondary replicas
In previous version read traffic always got directed to the first readable replica. In SQL Server 2016 multiple replicas can be specified in the READ_ONLY_ROUTING_LIST and grouped for load balancing using parenthesis. Such as :
123READ_ONLY_ROUTING_LIST = (('SVR1','SVR2','SVR3'),'SVR4')In this instance SVR1, SVR2 and SVR3 will be accessed as a load balanced set and SVR4 will only be accessed if none of the servers in the load balanced set is accessible.
Multiple automatic failover targets
In SQL Server 2016 you can now specify up to 3 automatic failover targets , as long as one of the targets are in sync failover can occur automatically with no data loss.
Improved log transport performance
The log-capture step on the primary server and the redo step on the secondary used to be single threaded in previous versions of SQL. In SQL Server 2016 these two steps are multi-threaded which significantly increases performance.
Seamless Data Integration
SQL Server 2016 introduces some useful features which facilitates access to different types of data, including integration between relational data, unstructured and semi-structured data.
Temporal data
SQL Server 2016 introduces temporal tables for keeping track of the state of data at any specific point in time. Temporal tables actually consists out of 2 tables. The current or temporal table and the historical table which uses page compression for space considerations. As changes occur on the temporal table a copy of the data is stored in the historical table.

JSON
The addition JavaScript Object Notation support in SQL Server 2016 allows you to import and export data to and from JSON format into your relational database. This means that both relational and non-relational data structures can live together in one environment.
PolyBase
SQL Server 2016 improves the 2014 implementation of PolyBase by now allowing you to directly query data in Hadoop or Azure blob storage, and have the computation performed on Hadoop for optimized performance. You can use transact SQL to communicate between the non-relational databases such as Hadoop or Azure blob storage and the relational SQL Server database.
Reporting Services Enhancements
There are 3 key things to mentions when it comes to the enhancements to SQL Server Reporting Services. 2016 has a better development environment with more data visualizations and new report content types. Mobile access to reports are now possible and a new development environment to support those mobile reports.
Deeper Analysis
A vast array of improvements have been made to improve the analytics capabilities of SQL Server 2016.
R
SQL Server 2016 no has R Services which allows statisticians, analysts and scientists to execute R code directly on their SQL Server database. The Enterprise Edition of R Services support high speed computations by using multi processors, multicores and multithreading.
Tabular improvements
Access data using DirectQuery mode
More data sources are now supported for Direct Query. These are:
SQL Server 2008 or later, Azure, Analytics Platoform System, Oracle 9i and higher and Teradata V2R6, V2All data is no longer required when modeling with a DirectQuery source
You now have the option to choose to model with no data, a subset of data or all data as in previous version.
Calculated Tables
Calculated tables can be built with DAX in models that are not using DirectQuery mode, which will allow you to combine columns from different tables, apply logic to filter the data or apply calculations.
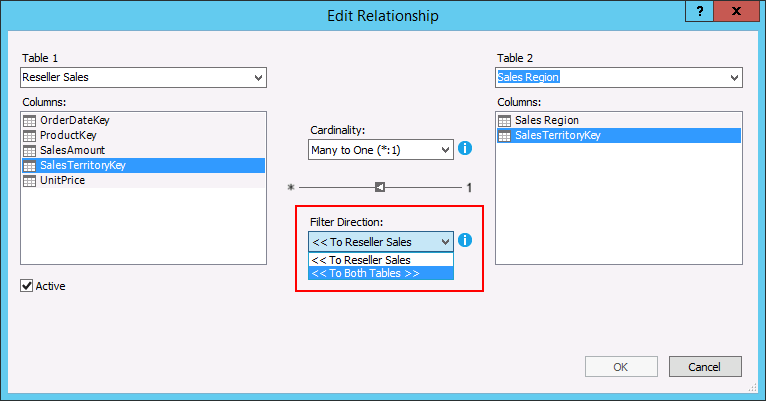
Bi-directional cross-filtering
You are now able to choose the filter direction of your table relationships. Previously filters could only be applied in one direction which required complex DAX queries in order to avoid duplicates. A relationship can now be filtered in two ways, either single like before or both directions with.
Enhancements to DAX
The formula bar has been improved to facilitate the writing of DAX formulas. Many new DAX functions have been added and variables can now be used in DAX expressions.
SQL Server Azure
Initially Azure only offered a subset of the features which are available in a regular SQL Server database engine. Most of the limitations of the initial Azure SQL Database has now been overcome leaving SQL Database close to par with on-premises servers. Size limitations has been increased, additional security has been added and many database features included. All Azure SQL Databases come standard with high availability, and a minimum of 3 replicas exist which can be promoted to primary in the event of a hardware failure.
SQL Database Security
Azure security has been enhanced built to be trustworthy with advanced strategies and policies to ensure that only authorized users are able to access your data. The policies are regularly audited by accredited third-parties.
SQL Database Auditing
Auditing is included in Azure and logs are written to Azure storage. The following events can be audited.
T-SQL whether plain or parametrized
Schema modifications
Data modifications
Stored procedures
Logins
Transaction management
Data Protection
SQL Database has various features implemented to help protect your data, some I’ve already mentioned in the on-site SQL Server 2016 version. These include:
Transparent Data Encryption
TDE takes place on file level. The data in the tables are not encrypted. This prevents unauthorized use of database files and backups, but does not prevent users who have access to the data from viewing it.
Cell Level Encryption
The purpose of CLE is to hide certain sensitive data such as social security numbers by encrypting a column of data.
Always Encrypted
Row level security
Dynamic Data Masking
Elastic databases
The elastic database feature is a cost saving mechanism to prevent over provisioning of resources which is common if resources are estimated on a per database basis. Instead Azure allows you to group databases into an Elastic Database Pool and provision resources for the pool instead of for each database individually. When databases are in a pool they can automatically adjust to utilize the amount of eDTU (Database Transaction Units) as required. Sometimes some databases will use less and sometime some databases will use more. So any surplus can be used by other databases in the pool when they encounter a heavier load.
Azure Data Warehouse
Azure data warehouse is basically the APS (Analytics Platform System) in the cloud. The aim is to provide a massively parallel computing capabilities to everyone. The SQL Data Warehouse is targeted at databases which encompass at least a Terabyte of data. It includes quite a few optimizations to increase the performance of data warehouse queries, such as a distributed query optimizer and clustered column store indexes.
Wrapping it up
This was a quick summary of the new features available in SQL Server 2016 and Azure. Please check out the references below for more in-depth details of each topic.
Minette Steynberg has over 15 years’ experience in working with data in different IT roles including SQL developer and SQL Server DBA to name but a few. Minette enjoys being an active member of the SQL Server community by writing articles and the occasional talk at SQL user groups.
Minette currently works as a Data Platform Solution Architect at Microsoft South Africa.
View all posts by Minette SteynbergLatest posts by Minette Steynberg (see all)- The end is nigh! (For SQL Server 2008 and SQL Server 2008 R2) - April 4, 2018
- 8 things to know about Azure Cosmos DB (formerly DocumentDB) - September 4, 2017
- Introduction to Azure SQL Data Warehouse - August 29, 2017