
In this article, we will explore Web Scraping using R Scripts for SQL Machine Learning.
What is the Web Scraping?
The web is a significant source of data in the digital era. All required information is available on the websites. For example, users can browse SQLShack for all useful SQL Server related articles. In the Power BI Desktop articles, we explored the way to fetch data directly from the URL.
Web Scraping is a process to extract the data from the websites and save it locally for further analysis. You can extract the information in a table, spreadsheet, CSV, JSON.
You can manually copy data from a website; however, if you regularly use it for your analysis, it requires automation. For this automation, usually, we depend on the developers to read the data from the website and insert it into SQL tables.
SQL Machine Learning language helps you in web scrapping with a small piece of code. In the previous articles for SQL Server R scripts, we explored the useful open-source libraries for adding new functionality in R.
Import RVest library for SQL Server R scripts
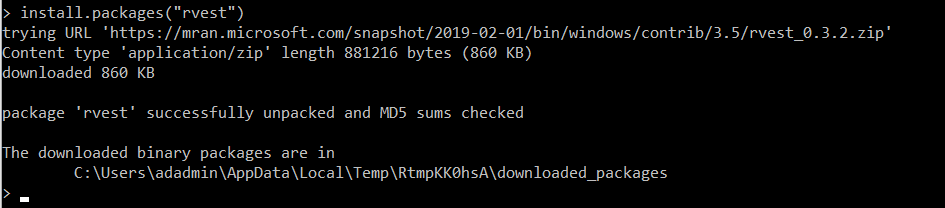
In this article, we use the rvest library for web scrapping. First, we need to install it using the Microsoft R client.
Navigate to the bin folder (C:\Program Files\Microsoft SQL Server\MSSQL15.INST1\R_SERVICES\bin) in your SQL instance and run the following command.
install.packages(“rvest”)
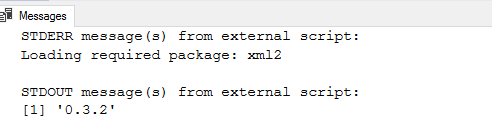
Once you installed the external library, you should use the sp_execute_external_script stored procedure and check its version.
|
1 2 3 4 5 6 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(rvest) print (packageVersion("rvest")) ' |
As shown below, its version is 0.3.2 for my SQL instance.
A quick overview of HTML and CSS
It is necessary to understand the HTML and CSS used for a web page. It is not mandatory; however, if you have the necessary knowledge, it would help you to scrape data from a web page.
HTML: Hypertext Markup Language:
HTML is a markup language to define the content and structure of a web page. In the HTML, we use different tags and add the values inside it. In the below script, we have two tags – <head> and <body>. There are some predefined tags in HTML such as <p>. It is used to specify a paragraph in HTML.
- <head>
- </head>
- <body>
- <p>
- Welcome!!
- </p>
- <p>
- To SQLShack
- </p>
- </body>
- </html>
CSS: Cascading Style Sheets
CSS provides style sheets for a HTML document display. For example, in the below code, we use the style to define the color of the texts. Here, we apply the style CSS for the p tags in HTML.
- <p style=”color:blue >Welcome</p>
- <p style=”color:blue >SQLShack</p>
In CSS, we can also define the classes. Suppose you use the font colors in many places on your web page. If you need to change the color from blue to red or add additional styles, you need to modify it at each place. Instead of doing it, you can define a class and define styles in a separate class.
- <p class=”myfont” >Welcome</p>
- <p class=”myfont” >SQLShack</p></p>
In the below code, you can view the myfont class in CSS.
|
1 2 3 |
.myfont { color : blue; } |
SQL Server R scripts for web scraping
For the demonstration purpose, I opened the following SQLShack page for my articles.
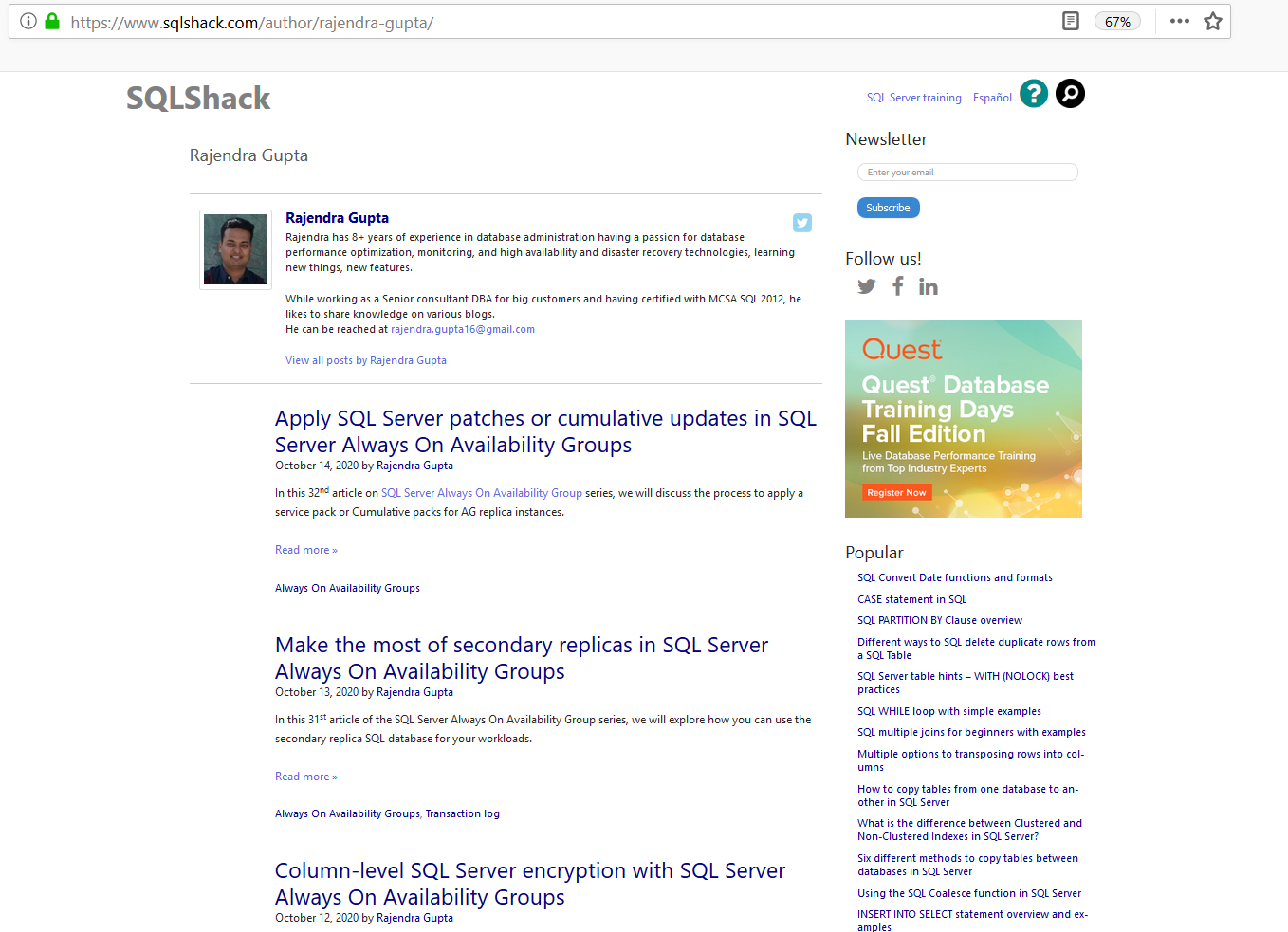
You can call the web page directly from the SQL Machine learning R script or save the web page in a local directory in case you do not have internet connectivity.
Look at the below screenshot, and it fetches some data from the specified web page.
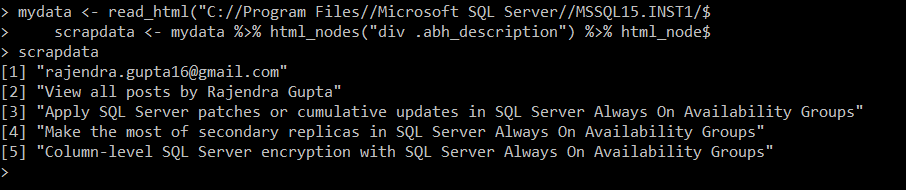
To understand the script and scrapped data, right-click on the HTML page and click on View Source. I copied the generated HTML in the Visual Studio Code for better formatting and analysis.
In the first line, we use the read_html() function and reads the data from the HTML web page. The read_html() function accepts both web pages and HTML pages saved in the local directory. It converts the HTML into the XML. Later, we assign the extracted data into the mydata variable.
Next, we use html_nodes() function to search for the div and abh_description strings in the HTML.
|
1 2 |
scrapdata <- mydata %>% html_nodes("div .abh_description") %>% html_nodes("a") %>% html_text() |
Now, if you look at the VS Code for HTML file, it looks for both strings and fetches the data with its corresponding node tag a.
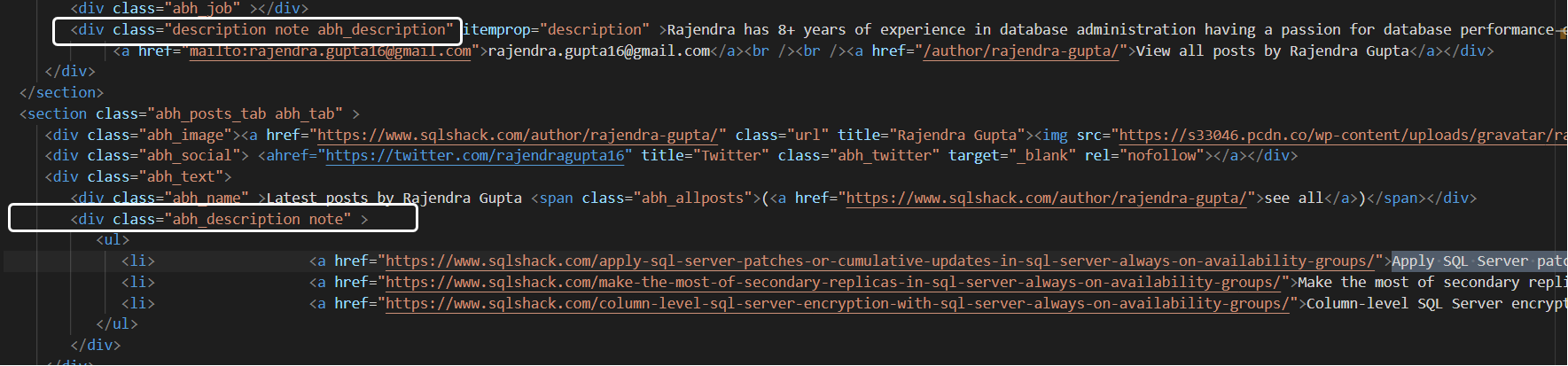
Let’s convert the code into the SQL Machine learning R scripts and fetch more data.
|
1 2 3 4 5 6 7 8 9 |
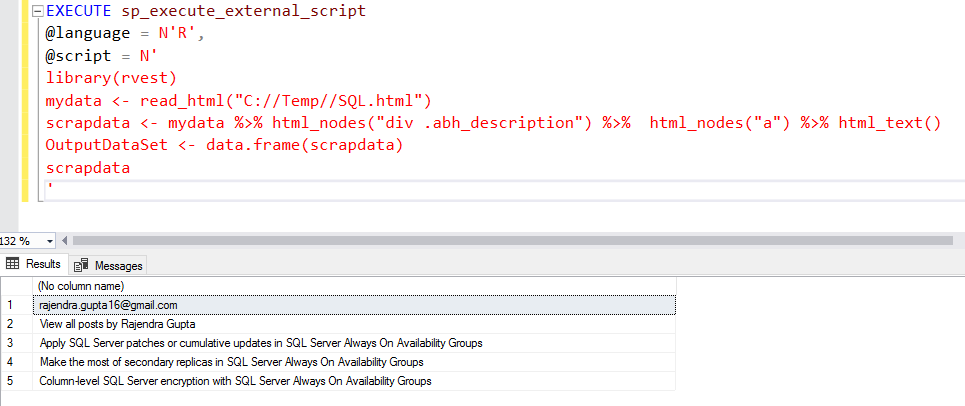
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(rvest) mydata <- read_html("C://Program Files//Microsoft SQL Server//MSSQL15.INST1//R_SERVICES//bin//SQL.html") scrapdata <- mydata %>% html_nodes("div .abh_description") %>% html_nodes("a") %>% html_text() OutputDataSet <- data.frame(scrapdata) scrapdata ' |
The SQL R script returns the same result as we saw earlier in the R client console.
In the above section, we read a particular portion or tag from the SQLShack HTML page. Suppose, I want to fetch the titles of my articles on the current page. SQLShack displays 25 articles titles on a page; therefore, my output should also return 25 titles of articles.
Here, I modified the search pattern to div and entry-title.
|
1 2 3 4 5 6 7 8 9 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(rvest) mydata <- read_html("C://Temp//SQL.html") scrapdata <- mydata %>% html_nodes("div .entry-title") %>% html_nodes("a") %>% html_text() OutputDataSet <- data.frame(scrapdata) scrapdata ' |
It returns the 25 articles lists on the current page as shown below.
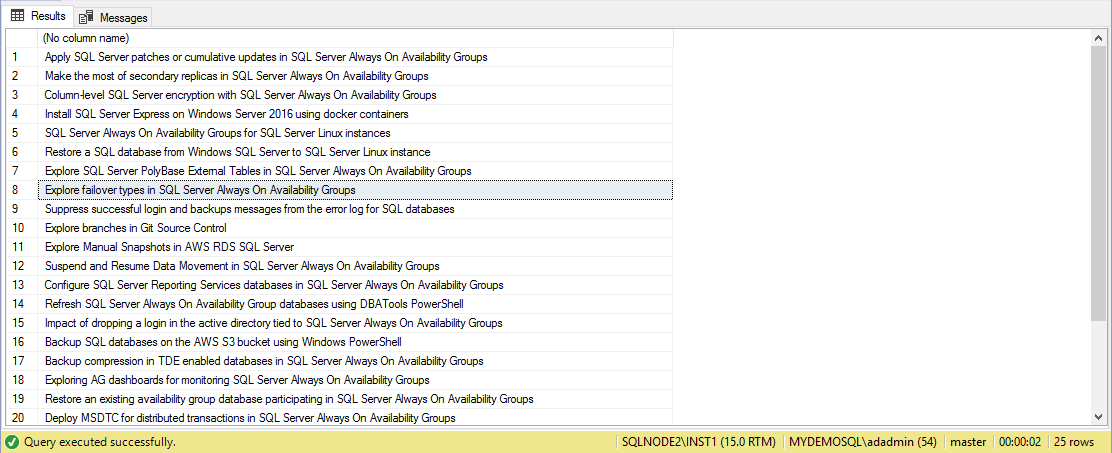
You can verify that article titles are in the entry_title tag; therefore, it reads the whole HTML document and returns the relevant information.

Now, I am interested in analyzing the category tags. Each article on the homepage comprises of following:
- Article title with hyperlink
- Article Published date and author name
- Brief description
- Categories in which articles fit property
For example, in the below image, we have the article category – Azure Data Studio.

To fetch this information from the web page using the SQL Machine Learning R scripts, locate the category tag and its corresponding div class. Here, you can note that the article category comes under the entry-meta.

Execute the following R script, and you get all categories in the specified HTML web page.
|
1 2 3 4 5 6 7 8 9 |
EXECUTE sp_execute_external_script @language = N'R', @script = N' library(rvest) mydata <- read_html("C://Temp//SQL.html") scrapdata <- mydata %>% html_nodes("div .entry-meta" ) %>% html_nodes("a") %>% html_text() OutputDataSet <- data.frame(scrapdata) scrapdata ' |
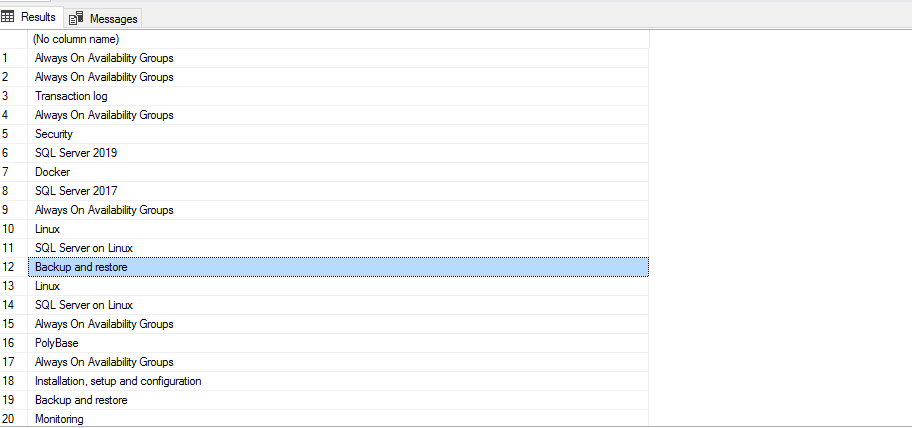
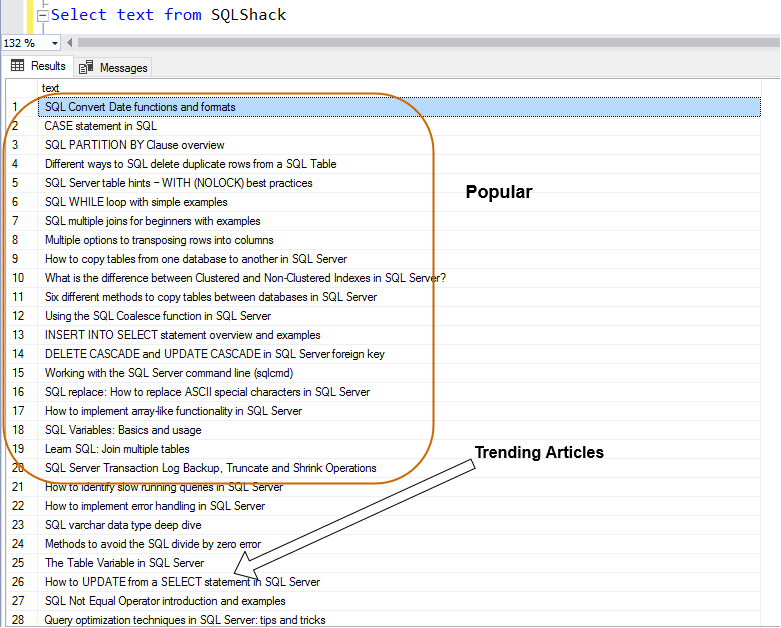
SQLShack page contains the following useful information on the right-hand side of the page.
Popular: It shows the popular articles on SQLShack

Trending: Here, we get current trending articles on SQLShack, as shown below
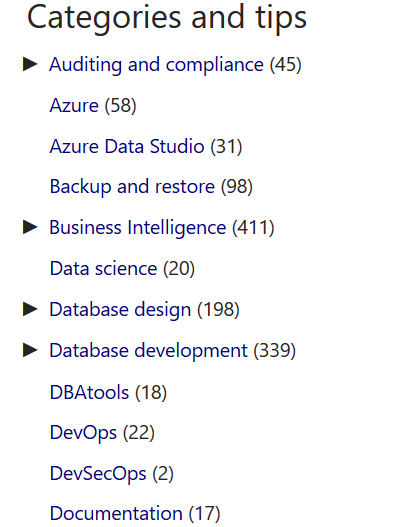
Solutions: In this section, it lists out the useful solutions for the SQLShack and SQL Community readers
Categories and tips: In this section, we get the articles categories and the number of articles in each category. Suppose you want to read backup-related articles so that you can click on the backup category and it lists all articles belongs to the specified category



Now, suppose we want to fetch all this information in a SQL table. It is not possible to copy the information manually and then insert it into the SQL table.
First, create a SQL table in which we insert the data using the SQL R script.
|
1 2 3 4 |
Create Table SQLShack( ID int identity(1,1) primary key clustered, [text] varchar(200) ) |
In the below R script, we insert the output into the SQLShack table. We modified the filters, and it now looks for the div and widget.
|
1 2 3 4 5 6 7 8 9 |
Insert into SQLShack EXECUTE sp_execute_external_script @language = N'R', @script = N' library(rvest) mydata <- read_html("C://Temp//SQL.html") scrapdata <- mydata %>% html_nodes("div .widget" ) %>% html_nodes("a") %>% html_text() OutputDataSet <- data.frame(scrapdata) ' |
You can verify it through the HTML file of the web page.
The script did not display the output on the SSMS screen. It inserted data into the specified table, therefore, execute a select statement on [SQLShack] table and view the output.
In the following screenshots, we can verify each category texts inserted into the SQL table.

Conclusion
In this article, we explored the useful web scraping using SQL Machine Learning R scripts. You use this R for fetching data from web pages and insert into the SQL table and perform further analysis on the extracted data.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023